Recognition: unknown
I Walk the Line: Examining the Role of Gestalt Continuity in Object Binding for Vision Transformers
Pith reviewed 2026-05-10 16:49 UTC · model grok-4.3
The pith
Vision transformers rely on specific attention heads sensitive to Gestalt continuity to perform object binding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
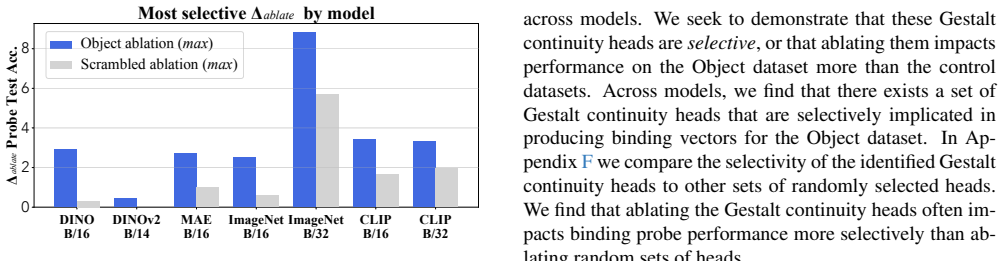
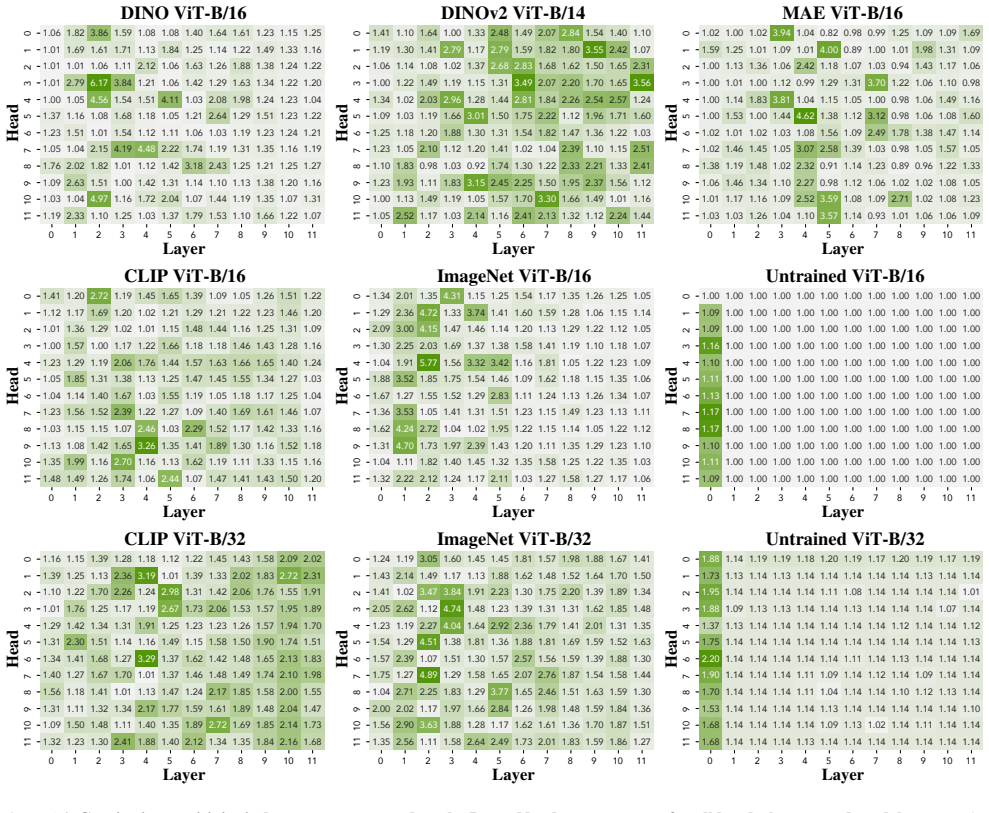
Using synthetic datasets, we demonstrate that binding probes are sensitive to continuity across a wide range of pretrained vision transformers. Next, we uncover particular attention heads that track continuity, and show that these heads generalize across datasets. Finally, we ablate these attention heads, and show that they often contribute to producing representations that encode object binding.
What carries the argument
Particular attention heads that track continuity cues, which the experiments show contribute causally to the formation of object-binding representations.
If this is right
- Binding probes register continuity effects in many different pretrained vision transformer architectures.
- The continuity-sensitive heads maintain their behavior when tested on new synthetic datasets.
- Removing the continuity heads degrades the models' ability to produce representations that support object binding.
Where Pith is reading between the lines
- Models that lose these heads might still bind objects when continuity is absent but other cues like proximity or similarity remain strong.
- The same synthetic-dataset method could be used to test whether vision models also rely on additional Gestalt principles beyond continuity.
- Interventions that strengthen or suppress the continuity heads could be applied to control binding behavior in downstream vision tasks.
Load-bearing premise
The synthetic datasets must isolate continuity from all other Gestalt grouping cues and from unrelated image statistics so that measured effects can be attributed to continuity alone.
What would settle it
If ablating the identified continuity-tracking heads leaves binding-probe performance unchanged on the same synthetic test sets, the claim that those heads contribute to object binding would be refuted.
Figures



















read the original abstract
Object binding is a foundational process in visual cognition, during which low-level perceptual features are joined into object representations. Binding has been considered a fundamental challenge for neural networks, and a major milestone on the way to artificial models with flexible visual intelligence. Recently, several investigations have demonstrated evidence that binding mechanisms emerge in pretrained vision models, enabling them to associate portions of an image that contain an object. The question remains: how are these models binding objects together? In this work, we investigate whether vision models rely on the principle of Gestalt continuity to perform object binding, over and above other principles like similarity and proximity. Using synthetic datasets, we demonstrate that binding probes are sensitive to continuity across a wide range of pretrained vision transformers. Next, we uncover particular attention heads that track continuity, and show that these heads generalize across datasets. Finally, we ablate these attention heads, and show that they often contribute to producing representations that encode object binding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether pretrained vision transformers rely on the Gestalt principle of continuity for object binding, beyond similarity and proximity. Using synthetic datasets, it claims that binding probes are sensitive to continuity across a range of ViTs, identifies specific attention heads that track continuity and generalize across datasets, and shows via ablation that these heads contribute to representations encoding object binding.
Significance. If substantiated with rigorous controls, the work would offer mechanistic insight into object binding in ViTs by linking it to classical Gestalt principles, potentially guiding more interpretable vision architectures. The empirical probe-and-ablation approach on synthetic data is a positive aspect for testing specific hypotheses.
major comments (2)
- [§3] §3 (synthetic data pipeline): The construction varies line continuity while attempting to hold other factors fixed, yet local edge density, endpoint proximity, and collinearity statistics remain correlated with the continuity manipulation. Because binding probes and attention-head analyses are trained on these stimuli, any reported sensitivity or causal contribution could reflect those correlated statistics rather than continuity per se.
- [Abstract] Abstract and results (implied by claims of 'demonstrate', 'uncover', and 'show'): The central claims about probe sensitivity, head generalization, and ablation effects are stated without quantitative metrics, controls, statistical tests, or error analysis. This prevents evaluation of the strength of evidence supporting the binding-probe and causal-head conclusions.
minor comments (1)
- [Methods] Clarify the precise training procedure and evaluation metrics for the 'binding probes' early in the methods, as this is foundational to interpreting sensitivity results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential to provide mechanistic insight into object binding in ViTs. We address each major comment point-by-point below, proposing revisions that strengthen the manuscript without overstating our current results.
read point-by-point responses
-
Referee: [§3] §3 (synthetic data pipeline): The construction varies line continuity while attempting to hold other factors fixed, yet local edge density, endpoint proximity, and collinearity statistics remain correlated with the continuity manipulation. Because binding probes and attention-head analyses are trained on these stimuli, any reported sensitivity or causal contribution could reflect those correlated statistics rather than continuity per se.
Authors: We agree this is a valid concern and that residual correlations could affect interpretation. While §3 describes our efforts to vary continuity while minimizing other Gestalt factors, we acknowledge that complete isolation is challenging. In the revised manuscript we add explicit controls: (i) partial-correlation analyses between probe outputs and the listed statistics, and (ii) a new matched-stimulus subset in which edge density, endpoint proximity, and collinearity are equated across continuity conditions. These controls show that binding-probe sensitivity and the identified heads remain selective for continuity. We also expand the discussion in §3 to quantify the residual correlations and their impact. revision: yes
-
Referee: [Abstract] Abstract and results (implied by claims of 'demonstrate', 'uncover', and 'show'): The central claims about probe sensitivity, head generalization, and ablation effects are stated without quantitative metrics, controls, statistical tests, or error analysis. This prevents evaluation of the strength of evidence supporting the binding-probe and causal-head conclusions.
Authors: We accept that the abstract would benefit from explicit quantitative grounding. We have revised the abstract to report key metrics drawn from our existing experiments (probe accuracies, head-generalization rates, ablation-induced drops) together with references to the statistical tests, error bars, and control conditions already present in the results sections. These additions allow readers to assess the strength of evidence for probe sensitivity, head generalization, and causal contribution without altering the underlying claims. revision: yes
Circularity Check
No circularity: purely empirical probe-and-ablation study
full rationale
The paper reports an empirical investigation that constructs synthetic stimuli, trains binding probes on pretrained vision transformers, identifies continuity-tracking attention heads, and performs causal ablations. No mathematical derivations, parameter fits presented as predictions, or load-bearing self-citations appear in the central claims. All reported sensitivities and contributions are measured outcomes on held-out or external data rather than tautological restatements of inputs or prior author results. The work therefore contains no steps that reduce by construction to their own definitions or citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gestalt continuity is a relevant and isolable principle for object binding in neural networks
Reference graph
Works this paper leans on
-
[1]
Rim Assouel, Declan Campbell, Yoshua Bengio, and Tay- lor Webb. Visual symbolic mechanisms: Emergent sym- bol processing in vision language models.arXiv preprint arXiv:2506.15871, 2025. 1
-
[2]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 2
2021
-
[3]
MIT press, 2005
Peter Dayan and Laurence F Abbott.Theoretical neuro- science: computational and mathematical modeling of neu- ral systems. MIT press, 2005. 3
2005
-
[4]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 3
2009
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
How do language mod- els bind entities in context? InThe Twelfth International Conference on Learning Representations, 2023
Jiahai Feng and Jacob Steinhardt. How do language mod- els bind entities in context? InThe Twelfth International Conference on Learning Representations, 2023. 1
2023
-
[7]
Token erasure as a footprint of implicit vocabu- lary items in llms
Sheridan Feucht, David Atkinson, Byron C Wallace, and David Bau. Token erasure as a footprint of implicit vocabu- lary items in llms. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9727–9739, 2024. 4
2024
-
[8]
On the binding problem in artificial neural networks.arXiv preprint arXiv:2012.05208, 2020
Klaus Greff, Sjoerd Van Steenkiste, and J ¨urgen Schmidhu- ber. On the binding problem in artificial neural networks. arXiv preprint arXiv:2012.05208, 2020. 1
-
[9]
Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. Finding neurons in a haystack: Case studies with sparse probing.arXiv preprint arXiv:2305.01610, 2023. 4
-
[10]
Partimagenet: A large, high- quality dataset of parts
Ju He, Shuo Yang, Shaokang Yang, Adam Kortylewski, Xi- aoding Yuan, Jie-Neng Chen, Shuai Liu, Cheng Yang, Qi- hang Yu, and Alan Yuille. Partimagenet: A large, high- quality dataset of parts. InEuropean Conference on Com- puter Vision, pages 128–145. Springer, 2022. 6
2022
-
[11]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 2
2022
-
[12]
Disentangling neural mechanisms for perceptual grouping
Junkyung Kim, Drew Linsley, Kalpit Thakkar, and Thomas Serre. Disentangling neural mechanisms for perceptual grouping. InInternational Conference on Learning Repre- sentations, 2019. 2
2019
-
[13]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
routledge,
Kurt Koffka.Principles of Gestalt psychology. routledge,
-
[15]
Beyond the doors of perception: Vision transformers represent relations be- tween objects.Advances in Neural Information Processing Systems, 37:131503–131544, 2024
Michael A Lepori, Alexa R Tartaglini, Wai K V ong, Thomas Serre, Brenden M Lake, and Ellie Pavlick. Beyond the doors of perception: Vision transformers represent relations be- tween objects.Advances in Neural Information Processing Systems, 37:131503–131544, 2024. 1
2024
-
[16]
Yihao Li, Saeed Salehi, Lyle Ungar, and Konrad P Kording. Does object binding naturally emerge in large pretrained vi- sion transformers?arXiv preprint arXiv:2510.24709, 2025. 1, 2
-
[17]
Learning long-range spatial de- pendencies with horizontal gated recurrent units.Advances in neural information processing systems, 31, 2018
Drew Linsley, Junkyung Kim, Vijay Veerabadran, Charles Windolf, and Thomas Serre. Learning long-range spatial de- pendencies with horizontal gated recurrent units.Advances in neural information processing systems, 31, 2018. 2
2018
-
[18]
Object- centric learning with slot attention.Advances in neural in- formation processing systems, 33:11525–11538, 2020
Francesco Locatello, Dirk Weissenborn, Thomas Un- terthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object- centric learning with slot attention.Advances in neural in- formation processing systems, 33:11525–11538, 2020. 1
2020
-
[19]
Dinov2: Learning robust visual features without supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal, 2024. 2
2024
-
[20]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[21]
Long range arena: A bench- mark for efficient transformers
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena: A bench- mark for efficient transformers. InInternational Conference on Learning Representations, 2020. 2
2020
-
[22]
The binding problem.Current opinion in neurobiology, 6(2):171–178, 1996
Anne Treisman. The binding problem.Current opinion in neurobiology, 6(2):171–178, 1996. 1
1996
-
[23]
Illusory conjunctions in the perception of objects.Cognitive psychology, 14(1): 107–141, 1982
Anne Treisman and Hilary Schmidt. Illusory conjunctions in the perception of objects.Cognitive psychology, 14(1): 107–141, 1982. 1
1982
-
[24]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 1
2017
-
[25]
The what and why of binding: the modeler’s perspective.Neuron, 24(1):95–104, 1999
Christoph V on der Malsburg. The what and why of binding: the modeler’s perspective.Neuron, 24(1):95–104, 1999. 1
1999
-
[26]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. In The Eleventh International Conference on Learning Repre- sentations, 2022. 4
2022
-
[27]
Object” version). Figure 6.Randomly selected stimuli from the Curves dataset (“Object
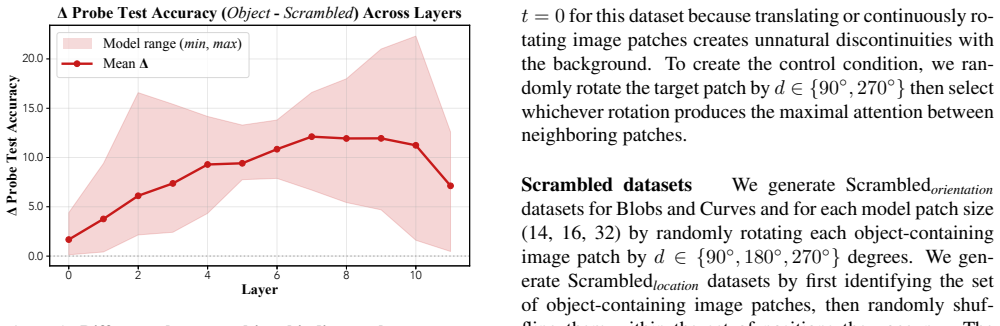
Max Wertheimer.Untersuchungen zur Lehre von der Gestalt. Springer, 1923. 1 5 0.0 5.0 10.0 15.0 20.0 0 2 4 6 8 10 Δ Probe Test Accuracy (Object - Scrambled) Across Layers Δ Probe Test Accuracy Layer Mean Δ Model range (min, max) Figure 4.Difference between object binding probe test accu- racy on Curves Object stimuli vs. Scrambled stimuli.These results fol...
1923
-
[28]
Note that our method for selecting Gestalt continuity heads to ablate is quite crude
We find that the Gestalt continuity head ablations are typically more selective than the control ablations, at least for 1 layer per model. Note that our method for selecting Gestalt continuity heads to ablate is quite crude. Many models have far more than 5 heads that could plausibly be called Gestalt conti- nuity heads, and so we expect that some contro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.