Recognition: unknown
A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics
Pith reviewed 2026-05-10 16:33 UTC · model grok-4.3
The pith
Stop-gradient enables non-collapsed fixed points and stabilizes finite class separation in a minimal embedding model even with frustrated samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
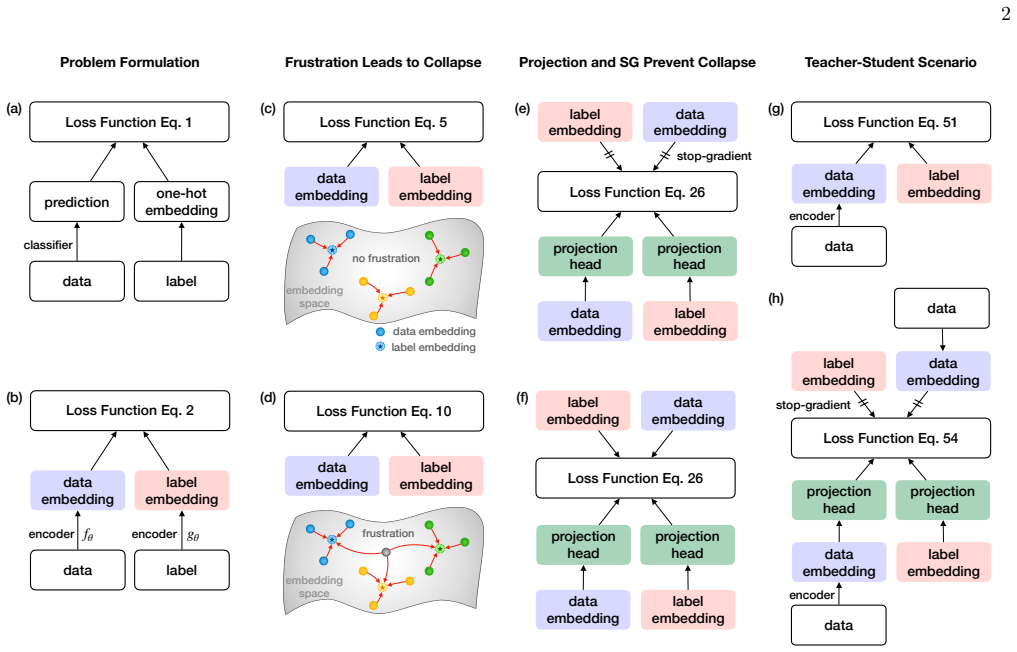
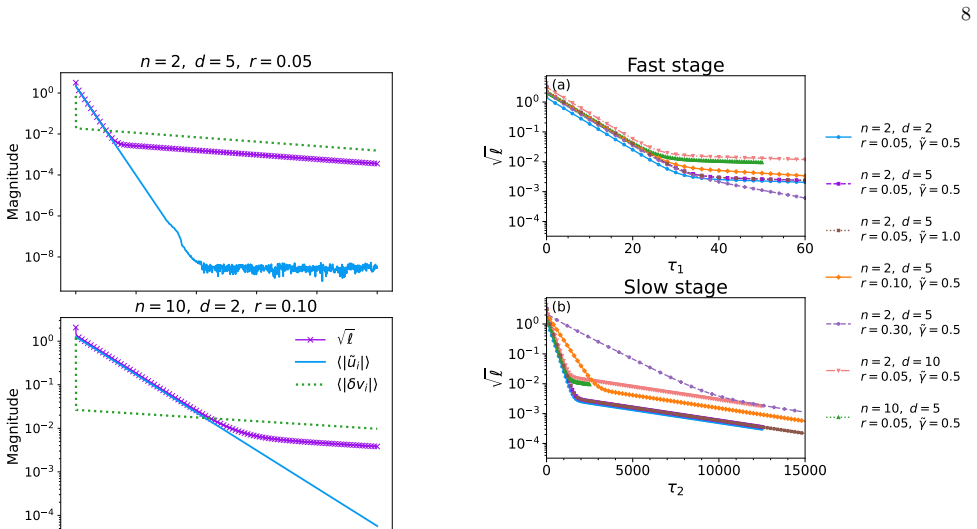
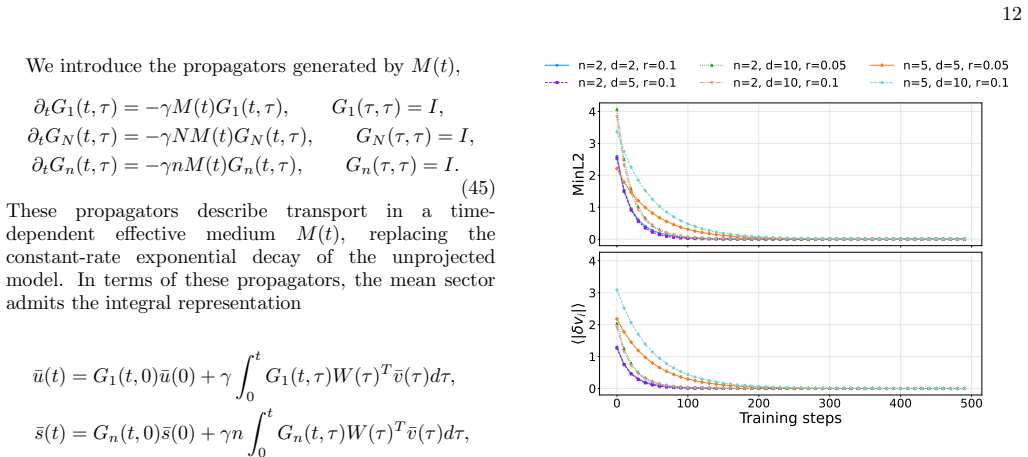
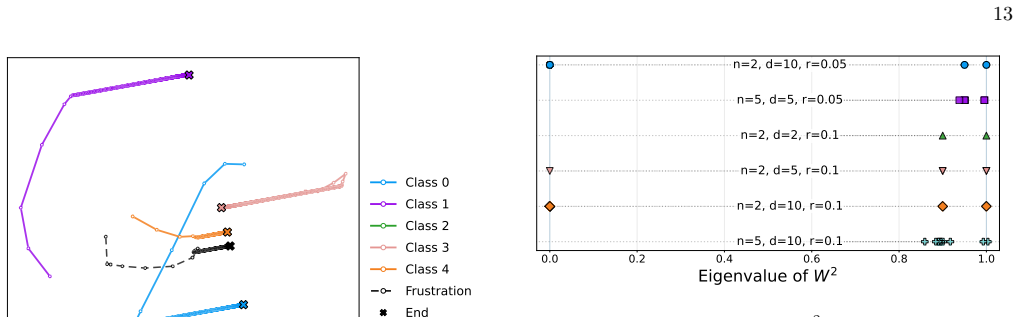
In the embedding-only model, data without frustration converges to non-collapsed fixed points, whereas frustrated samples drive collapse via a slow mode following early gains. Stop-gradient at the projection head enables non-collapsed solutions and stabilizes finite class separation under frustration, as shown by fixed-point analysis and dynamical mean-field self-consistency, with matching dynamics verified in a linear teacher-student model.
What carries the argument
Stop-gradient applied to the shared projection head within the gradient-flow dynamics, which changes the fixed-point structure to allow separated embeddings despite frustration.
If this is right
- Perfectly classifiable data produces non-collapsed representations without extra mechanisms.
- A small fraction of frustrated samples triggers collapse after an initial performance gain through a slow additional timescale.
- Stop-gradient combined with a projection head produces stable fixed points that preserve finite class separation under frustration.
- The same non-collapse and stabilization effects appear in a linear teacher-student model.
Where Pith is reading between the lines
- The slow collapse timescale could be searched for in training curves of larger self-supervised models to check consistency with the minimal case.
- Other prevention techniques such as different loss terms could be inserted into the same fixed-point framework to compare their stabilizing power.
- The result suggests testing whether stop-gradient remains effective when the model is extended beyond linear embeddings to include nonlinear layers.
Load-bearing premise
The minimal embedding-only model with its gradient-flow dynamics and fixed-point analysis captures the essential mechanisms driving representation collapse and its prevention in more complex self-supervised learning systems.
What would settle it
Running the model with a controlled fraction of frustrated samples and measuring whether class separation remains finite when stop-gradient is active but collapses when it is removed would directly test the stabilization claim.
Figures




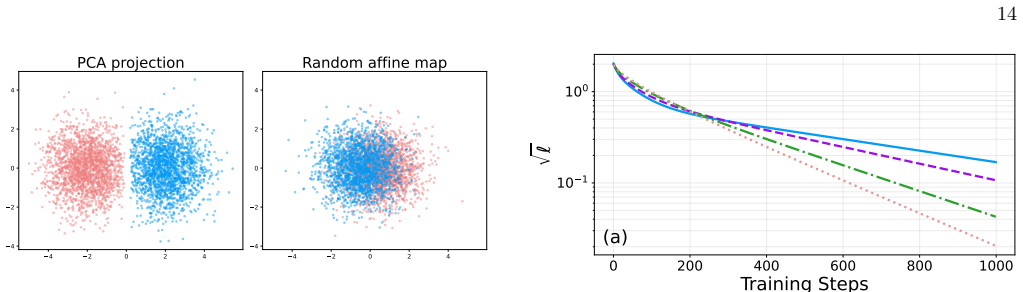
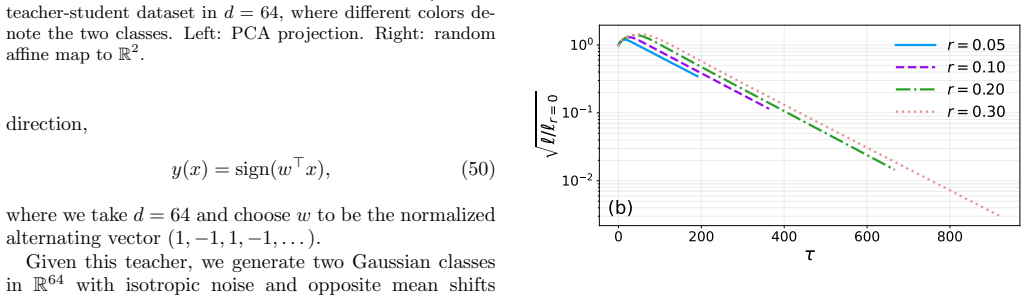

read the original abstract
Self-supervised representation learning is central to modern machine learning because it extracts structured latent features from unlabeled data and enables robust transfer across tasks and domains. However, it can suffer from representation collapse, a widely observed failure mode in which embeddings lose discriminative structure and distinct inputs become indistinguishable. To understand the mechanisms that drive collapse and the ingredients that prevent it, we introduce a minimal embedding-only model whose gradient-flow dynamics and fixed points can be analyzed in closed form, using a classification-representation setting as a concrete playground where collapse is directly quantified through the contraction of label-embedding geometry. We illustrate that the model does not collapse when the data are perfectly classifiable, while a small fraction of frustrated samples that cannot be classified consistently induces collapse through an additional slow time scale that follows the early performance gain. Within the same framework, we examine collapse prevention by adding a shared projection head and applying stop-gradient at the level of the training dynamics. We analyze the resulting fixed points and develop a dynamical mean-field style self-consistency description, showing that stop-gradient enables non-collapsed solutions and stabilizes finite class separation under frustration. We further verify empirically that the same qualitative dynamics and collapse-prevention effects appear in a linear teacher-student model, indicating that the minimal theory captures features that persist beyond the pure embedding setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a minimal embedding-only model whose gradient-flow dynamics and fixed points admit closed-form analysis in a classification-representation setting. It claims that perfectly classifiable data avoids collapse, while a small fraction of frustrated samples induces collapse through an additional slow timescale following early performance gains; stop-gradient applied with a shared projection head enables non-collapsed fixed points and stabilizes finite class separation under frustration. These effects are verified empirically in a linear teacher-student model, indicating persistence beyond the pure embedding setting.
Significance. If the closed-form analysis and dynamical mean-field self-consistency hold, the work supplies a transparent theoretical account of collapse mechanisms and their prevention, with the linear teacher-student verification providing an independent check that qualitative features survive outside the minimal model. This is a strength for guiding SSL algorithm design.
major comments (2)
- [dynamical mean-field self-consistency description] The central claim that stop-gradient stabilizes finite class separation under frustration rests on the dynamical mean-field self-consistency description; the derivation should explicitly show how the stop-gradient breaks the slow timescale induced by frustration (as opposed to merely shifting the fixed-point location), since this is load-bearing for the prevention result.
- [linear teacher-student verification] In the linear teacher-student verification, the qualitative persistence of collapse-prevention effects is asserted, but the section should report the precise metrics used for class separation, any data exclusion rules, and error analysis to confirm that the verification is not sensitive to post-hoc modeling choices.
minor comments (2)
- [model definition] Clarify the parameterization of the fraction of frustrated samples and how it enters the gradient-flow equations, to make the slow-timescale emergence fully reproducible from the stated axioms.
- [fixed-point analysis] In the fixed-point analysis, ensure that the notation for embedding geometry contraction is consistent between the perfectly classifiable case and the frustrated case.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation of minor revision, and the constructive comments that will help clarify key aspects of the analysis. We address each major comment below and will incorporate the requested clarifications and details into the revised manuscript.
read point-by-point responses
-
Referee: [dynamical mean-field self-consistency description] The central claim that stop-gradient stabilizes finite class separation under frustration rests on the dynamical mean-field self-consistency description; the derivation should explicitly show how the stop-gradient breaks the slow timescale induced by frustration (as opposed to merely shifting the fixed-point location), since this is load-bearing for the prevention result.
Authors: We agree that explicitly demonstrating the breaking of the slow timescale is important for the prevention claim. The current manuscript derives the fixed points via the dynamical mean-field self-consistency and shows that stop-gradient permits non-collapsed equilibria under frustration. In the revision we will add an explicit analysis of the linearized dynamics around these fixed points (or the associated effective equations) to show how stop-gradient eliminates the slow mode generated by frustrated samples, rather than merely relocating the equilibrium. This will be presented as an additional paragraph or subsection following the fixed-point derivation. revision: yes
-
Referee: [linear teacher-student verification] In the linear teacher-student verification, the qualitative persistence of collapse-prevention effects is asserted, but the section should report the precise metrics used for class separation, any data exclusion rules, and error analysis to confirm that the verification is not sensitive to post-hoc modeling choices.
Authors: We will revise the linear teacher-student section to include the requested details. We will state the precise class-separation metric (the average Euclidean distance between class centroids in embedding space), confirm that no samples were excluded from the reported runs, and add error analysis consisting of means and standard deviations computed over 10 independent random seeds. These additions will demonstrate that the qualitative persistence of the collapse-prevention effect is robust to the reported choices. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper constructs a minimal embedding-only model from first principles, derives its gradient-flow dynamics and fixed points in closed form, and analyzes collapse under frustration plus prevention via stop-gradient using internal dynamical mean-field self-consistency. All load-bearing steps (fixed-point solutions, slow timescale emergence, stabilization conditions) follow directly from the model's stated assumptions and equations without reduction to fitted inputs, self-definitional loops, or load-bearing self-citations. The linear teacher-student verification supplies an independent empirical check outside the pure embedding setting. This is the normal case of a self-contained theoretical construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
middle ground
We will not discuss that case further here, as our goal is to isolate the intrinsic collapse dynamics without introducing an additional decay time scale. A. Mode collapse Since the label representationsg θ(y) are not fixed in the representation space, there is a natural global min- imum of Eq. (2), achieved whenf θ(x) =C=g θ(y) for 4 allxandy, whereCis a ...
2000
-
[2]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y. Huang, S.-W. Li, I. Misra, M. Rabbat, V. Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, Transactions on Machine Learning Research (2024), feat...
2024
-
[3]
O. Sim´ eoni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa,et al., arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022) pp. 10684–10695
2022
-
[5]
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong,et al., arXiv preprint arXiv:2512.02556 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi,et al., arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv,et al., arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
H. Wei, Y. Sun, and Y. Li, arXiv preprint arXiv:2510.18234 (2025)
work page internal anchor Pith review arXiv 2025
-
[9]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen,et al., arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Jumper, R
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Fig- urnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. ˇZ´ ıdek, A. Potapenko,et al., nature596, 583 (2021)
2021
-
[11]
Acharya, D
R. Acharya, D. A. Abanin, L. Aghababaie-Beni,et al., Nature638, 920 (2025)
2025
-
[12]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
A. Novikov, N. V˜ u, M. Eisenberger, E. Dupont, P.- S. Huang, A. Z. Wagner, S. Shirobokov, B. Ko- zlovskii, F. J. Ruiz, A. Mehrabian,et al., arXiv preprint arXiv:2506.13131 (2025)
work page internal anchor Pith review arXiv 2025
-
[13]
S. Liu, W. Du, H. Xu, Y. Li, Z. Li, V. Bhethanabotla, D. Yan, C. Borgs, A. Anandkumar, H. Guo,et al., Nature Communications (2025)
2025
-
[14]
Avsec, N
ˇZ. Avsec, N. Latysheva, J. Cheng, G. Novati, K. R. Tay- lor, T. Ward, C. Bycroft, L. Nicolaisen, E. Arvaniti, J. Pan,et al., bioRxiv , 2025 (2025)
2025
-
[15]
P. W. Anderson, Science177, 393 (1972)
1972
-
[16]
Feng and Y
Y. Feng and Y. Tu, Proceedings of the National Academy of Sciences118, e2015617118 (2021)
2021
- [17]
-
[18]
Sompolinsky, A
H. Sompolinsky, A. Crisanti, and H.-J. Sommers, Physi- cal review letters61, 259 (1988)
1988
-
[19]
Cowsik, T
A. Cowsik, T. Nebabu, X. Qi, and S. Ganguli, Physical Review E112, 055301 (2025)
2025
-
[20]
Epping, A
B. Epping, A. Ren´ e, M. Helias, and M. T. Schaub, Ad- vances in Neural Information Processing Systems37, 48164 (2024)
2024
-
[21]
M. Kamb and S. Ganguli, arXiv preprint arXiv:2412.20292 (2024)
-
[22]
Sheshmani, Y.-Z
A. Sheshmani, Y.-Z. You, B. Buyukates, A. Ziasha- habi, and S. Avestimehr, Physical Review E111, 015304 (2025)
2025
- [23]
-
[24]
Y. Li, R. Bai, and H. Huang, Physical Review E112, L013301 (2025)
2025
- [25]
-
[26]
Sohl-Dickstein, E
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, inInternational conference on machine learn- ing(pmlr, 2015) pp. 2256–2265
2015
-
[27]
Equilibrium matching: Generative modeling with implicit energy-based models, 2025
R. Wang and Y. Du, arXiv preprint arXiv:2510.02300 (2025)
- [28]
-
[29]
Yaguchi, K
M. Yaguchi, K. Sakamoto, R. Sakamoto, M. Tanabe, M. Akagawa, Y. Hayashi, M. Suzuki, and Y. Matsuo, Transactions on Machine Learning Research (2025), fea- tured Certification
2025
-
[30]
Raya and L
G. Raya and L. Ambrogioni, inThirty-seventh Confer- ence on Neural Information Processing Systems(2023)
2023
- [31]
-
[32]
Miyato, S
T. Miyato, S. L¨ owe, A. Geiger, and M. Welling, inThe Thirteenth International Conference on Learning Repre- sentations(2025)
2025
-
[33]
Balestriero and Y
R. Balestriero and Y. LeCun, inNeurIPS 2024 Work- shop: Self-Supervised Learning - Theory and Practice (2024)
2024
-
[34]
Shwartz Ziv and Y
R. Shwartz Ziv and Y. LeCun, Entropy26, 252 (2024)
2024
-
[35]
LeCun and I
Y. LeCun and I. Misra, Self-supervised learning: The dark matter of intelligence, Meta AI Blog (2021)
2021
-
[36]
Chopra, R
S. Chopra, R. Hadsell, and Y. LeCun, in2005 IEEE com- puter society conference on computer vision and pattern recognition (CVPR’05), Vol. 1 (IEEE, 2005) pp. 539–546
2005
-
[37]
A. v. d. Oord, Y. Li, and O. Vinyals, arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, in Proceedings of the 37th International Conference on Ma- chine Learning(2020) pp. 1597–1607
2020
-
[39]
Assran, Q
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vin- cent, M. Rabbat, Y. LeCun, and N. Ballas, inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2023) pp. 15619–15629
2023
-
[40]
Grill, F
J.-B. Grill, F. Strub, F. Altch´ e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar, B. Piot, k. kavukcuoglu, R. Munos, and M. Valko, inAdvances in Neural Information Pro- cessing Systems, Vol. 33 (2020) pp. 21271–21284
2020
-
[41]
Chen and K
X. Chen and K. He, inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2021) pp. 15750–15758
2021
-
[42]
X. Wang, H. Fan, Y. Tian, D. Kihara, and X. Chen, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition(2022) pp. 16570–16579
2022
- [43]
-
[44]
Y. Tian, X. Chen, and S. Ganguli, inProceedings of the 38th International Conference on Machine Learning, Vol. 139 (2021) pp. 10268–10278. 18
2021
-
[45]
Zhang, K
C. Zhang, K. Zhang, C. Zhang, T. X. Pham, C. D. Yoo, and I. S. Kweon, inInternational Conference on Learning Representations(2022)
2022
-
[46]
Maggioni, S
M. Maggioni, S. Minsker, and N. Strawn, The Journal of Machine Learning Research17, 43 (2016)
2016
-
[47]
Kalimuthu, D
M. Kalimuthu, D. Holzm¨ uller, and M. Niepert, inICLR 2025 Workshop on Machine Learning Multiscale Pro- cesses(2025)
2025
-
[48]
Parsan, D
N. Parsan, D. J. Yang, and J. J. Yang, inICLR 2025 Workshop on Machine Learning Multiscale Processes (2025)
2025
-
[49]
LeCun, Open Review62, 1 (2022)
Y. LeCun, Open Review62, 1 (2022)
2022
-
[50]
LeCun, L
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, Pro- ceedings of the IEEE86, 2278 (2002)
2002
-
[51]
Krizhevsky, G
A. Krizhevsky, G. Hinton,et al., Learning multiple layers of features from tiny images. (2009)
2009
-
[52]
K. He, X. Zhang, S. Ren, and J. Sun, inProceedings of the IEEE conference on computer vision and pattern recognition(2016)
2016
-
[53]
While ensemble methods such as bagging are common in traditional machine learning, they are rarely applied in neural network training due to computational cost
-
[54]
Georges, G
A. Georges, G. Kotliar, W. Krauth, and M. J. Rozenberg, Reviews of modern physics68, 13 (1996)
1996
-
[55]
Bonnaire, R
T. Bonnaire, R. Urfin, G. Biroli, and M. Mezard, inThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2025)
2025
-
[56]
P. C. Martin, E. D. Siggia, and H. A. Rose, Physical Review A8, 423 (1973)
1973
-
[57]
de Dominicis, inJ
C. de Dominicis, inJ. Phys.(Paris), Colloq.;(France), Vol. 1 (1976)
1976
-
[58]
Janssen, Zeitschrift f¨ ur Physik B Condensed Mat- ter23, 377 (1976)
H.-K. Janssen, Zeitschrift f¨ ur Physik B Condensed Mat- ter23, 377 (1976)
1976
-
[59]
U. C. T¨ auber,Critical dynamics: a field theory ap- proach to equilibrium and non-equilibrium scaling behav- ior(Cambridge University Press, 2014). Appendix A: Dynamics of the Unfrustrated MSE Model In this appendix, we provide the detailed derivation of the gradient-flow dynamics and the fixed-point structure for the unfrustrated mean-squared-error (MSE...
2014
-
[60]
Similarly, define the shared-sample mean and fluctuations: ¯s≡ 1 rN rNX α=1 sα, δs α ≡s α −¯s,(B2) so thatP α δsα = 0
Decomposition ofu iα ands α into Means and Fluctuations Define the within-class mean and fluctuations of the non-shared samples: ¯ui ≡ 1 (1−r)N (1−r)NX α=1 uiα, δu iα ≡u iα −¯ui,(B1) so that P α δuiα = 0 for eachi. Similarly, define the shared-sample mean and fluctuations: ¯s≡ 1 rN rNX α=1 sα, δs α ≡s α −¯s,(B2) so thatP α δsα = 0. Averaging Eq. (11) over...
-
[61]
Equation (B7) implies that each independent compo- nent ofδs α decays with eigenvalue λs =−γn,(B9) with multiplicity (rN−1) (one constraint P α δsα = 0)
Eigenvalues of the Fluctuation Subspaces Equation (B6) implies that each independent compo- nent ofδu iα decays with eigenvalue λu =−γ.(B8) The multiplicity isn (1−r)N−1 (one constraintP α δuiα = 0 per class). Equation (B7) implies that each independent compo- nent ofδs α decays with eigenvalue λs =−γn,(B9) with multiplicity (rN−1) (one constraint P α δsα...
-
[62]
Define global means and deviations across classes: ¯u≡ 1 n nX i=1 ¯ui,¯v≡ 1 n nX i=1 vi,(B10) δui ≡¯ui −¯u, δv i ≡v i −¯v, nX i=1 δui = nX i=1 δvi = 0
Reduction of the Mean Dynamics into Deviation and Mean Sectors The remaining dynamics (B3)–(B5) live in the (2n+1)- dimensional space of (¯ui, vi,¯s). Define global means and deviations across classes: ¯u≡ 1 n nX i=1 ¯ui,¯v≡ 1 n nX i=1 vi,(B10) δui ≡¯ui −¯u, δv i ≡v i −¯v, nX i=1 δui = nX i=1 δvi = 0. (B11) Substituting into (B3)–(B5) yields two independe...
-
[63]
In particular, the inter-class contrastsv i −¯vlie en- tirely in the deviation sector and are governed only by λdev ±
F ull Spectrum and Multiplicities Collecting the invariant subspaces, the spectrum of the full linear system (11) consists of: •λ u =−γwith multiplicityn (1−r)N−1 (within- classufluctuations); •λ s =−γnwith multiplicity (rN−1) (within-shared sfluctuations); •λ dev ± from (B13), each with multiplicity (n−1) (inter-class deviation modes); •λ mean ± from (B1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.