Recognition: unknown
FREE-Switch: Frequency-based Dynamic LoRA Switch for Style Transfer
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
A frequency-based dynamic switch for LoRA adapters merges pretrained style and object models in diffusion generation without retraining or detail loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
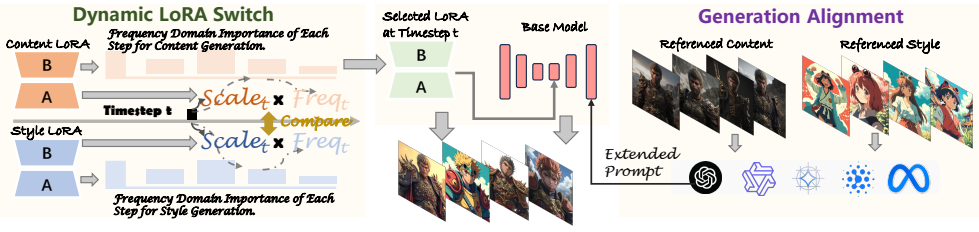
The central claim is that because each adapter contributes most strongly at different frequencies and timesteps, a dynamic switch driven by per-step frequency importance, together with semantic-level alignment of generation goals, produces merged outputs that preserve object identity and style fidelity better than fixed fusion or sequential application, all without additional training.
What carries the argument
Frequency-domain importance-driven dynamic LoRA switch, which scores each adapter's contribution at every diffusion step and activates the strongest one, paired with the automatic Generation Alignment mechanism that enforces semantic consistency across adapters.
If this is right
- Multiple open-source adapters can be combined for new object-style combinations without training a fresh model.
- Training cost for high-quality customized diffusion outputs drops because only the switch logic runs at inference time.
- Detail loss that occurs in uniform merging strategies is reduced by selecting adapters according to their actual per-step relevance.
- The method remains training-free and therefore suitable for resource-constrained or edge deployment scenarios.
- Semantic alignment prevents the generation intent from drifting when adapters are swapped mid-process.
Where Pith is reading between the lines
- The same frequency-driven selection idea could be tested on other iterative generative processes such as video or 3D synthesis.
- Frequency analysis might serve as a diagnostic tool to quantify how specialized any fine-tuned adapter has become.
- Deployment on mobile hardware would allow rapid user-driven mixing of community adapters without cloud retraining.
- Extending the switch to handle more than two adapters at once could enable richer compositional image creation.
Load-bearing premise
Different adapters are specialized enough for distinct content types that frequency importance can reliably guide switching without accumulating errors or losing fine details.
What would settle it
Run the switch on a pair of adapters with deliberately conflicting styles on the same prompt and inspect whether the generated images contain visible artifacts, object distortions, or style bleed that do not appear when each adapter is used alone.
Figures











read the original abstract
With the growing availability of open-sourced adapters trained on the same diffusion backbone for diverse scenes and objects, combining these pretrained weights enables low-cost customized generation. However, most existing model merging methods are designed for classification or text generation, and when applied to image generation, they suffer from content drift due to error accumulation across multiple diffusion steps. For image-oriented methods, training-based approaches are computationally expensive and unsuitable for edge deployment, while training-free ones use uniform fusion strategies that ignore inter-adapter differences, leading to detail degradation. We find that since different adapters are specialized for generating different types of content, the contribution of each diffusion step carries different significance for each adapter. Accordingly, we propose a frequency-domain importance-driven dynamic LoRA switch method. Furthermore, we observe that maintaining semantic consistency across adapters effectively mitigates detail loss; thus, we design an automatic Generation Alignment mechanism to align generation intents at the semantic level. Experiments demonstrate that our FREE-Switch (Frequency-based Efficient and Dynamic LoRA Switch) framework efficiently combines adapters for different objects and styles, substantially reducing the training cost of high-quality customized generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FREE-Switch, a frequency-domain importance-driven dynamic LoRA switching method for combining pretrained adapters in diffusion models, paired with an automatic Generation Alignment mechanism to preserve semantic consistency. The central claim is that this approach enables efficient, training-free merging of adapters specialized for different objects and styles, substantially reducing content drift from error accumulation and lowering the computational cost of high-quality customized generation compared to uniform fusion or training-based merging.
Significance. If the frequency-based per-step specialization and drift reduction hold under rigorous testing, the work could meaningfully advance practical deployment of open-source LoRA adapters for style transfer and multi-concept generation in diffusion models, particularly for edge devices where retraining is prohibitive. The dynamic switching idea directly targets a known limitation of static merging in generative tasks.
major comments (3)
- [Abstract] Abstract: The statement that 'Experiments demonstrate that our FREE-Switch framework efficiently combines adapters... substantially reducing the training cost' provides no quantitative metrics, baselines, ablation studies, or error analysis, rendering it impossible to evaluate whether the frequency-driven switch actually mitigates drift or outperforms uniform merging.
- [Abstract] Abstract: The load-bearing assumption that 'different adapters are specialized for generating different types of content' such that 'the contribution of each diffusion step carries different significance for each adapter' is asserted without derivation, correlation analysis, or ablation showing that the frequency importance metric tracks content type rather than step index or noise statistics; if the metric is generic, the claimed advantage over uniform fusion does not follow.
- [Method] The manuscript provides no equations, pseudocode, or implementation details for computing frequency-domain importance per step or executing the dynamic switch, which is required to assess whether the method avoids error accumulation or introduces new artifacts.
minor comments (1)
- [Abstract] The acronym expansion for FREE-Switch appears only after its first use; introducing it on first mention would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to provide the requested quantitative highlights, additional justification, and implementation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'Experiments demonstrate that our FREE-Switch framework efficiently combines adapters... substantially reducing the training cost' provides no quantitative metrics, baselines, ablation studies, or error analysis, rendering it impossible to evaluate whether the frequency-driven switch actually mitigates drift or outperforms uniform merging.
Authors: We agree that the abstract would be strengthened by referencing concrete outcomes. In the revised version we have added a sentence summarizing key experimental findings (reduced drift relative to uniform fusion, lower cost than training-based merging) with explicit pointers to the baselines, ablations, and error analysis now highlighted in Section 4. revision: yes
-
Referee: [Abstract] Abstract: The load-bearing assumption that 'different adapters are specialized for generating different types of content' such that 'the contribution of each diffusion step carries different significance for each adapter' is asserted without derivation, correlation analysis, or ablation showing that the frequency importance metric tracks content type rather than step index or noise statistics; if the metric is generic, the claimed advantage over uniform fusion does not follow.
Authors: The assumption is grounded in the distinct frequency responses we observed for style- versus object-specialized adapters. We have added a short derivation and supporting analysis in Section 3.1 together with a correlation study and an ablation that replaces frequency importance with step index; the latter yields measurably worse results, confirming the metric's specificity. revision: yes
-
Referee: [Method] The manuscript provides no equations, pseudocode, or implementation details for computing frequency-domain importance per step or executing the dynamic switch, which is required to assess whether the method avoids error accumulation or introduces new artifacts.
Authors: We have expanded Section 3.2 with the explicit frequency-importance formula (weighted FFT magnitude per adapter) and inserted Algorithm 1 containing the per-step switching logic and Generation Alignment procedure. These additions clarify how specialization at high-importance steps reduces cumulative drift. revision: yes
Circularity Check
No circularity: proposal derives from stated empirical observation without reduction to inputs
full rationale
The paper states an observation ('different adapters are specialized for generating different types of content') and directly proposes a frequency-domain switch plus alignment mechanism to address drift in merging. No equations, fitted parameters, or self-citations are shown that would make any 'prediction' equivalent to the input by construction. The derivation chain remains independent of its own outputs and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A neural space-time representation for text- to-image personalization.ACM Transactions on Graphics (TOG), 42(6):1–10, 2023
Yuval Alaluf, Elad Richardson, Gal Metzer, and Daniel Cohen-Or. A neural space-time representation for text- to-image personalization.ACM Transactions on Graphics (TOG), 42(6):1–10, 2023. 3
2023
-
[2]
Break-a-scene: Extracting multi- ple concepts from a single image
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen- Or, and Dani Lischinski. Break-a-scene: Extracting multi- ple concepts from a single image. InSIGGRAPH Asia 2023 Conference Papers, pages 1–12, 2023. 3
2023
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Style injec- tion in diffusion: A training-free approach for adapting large- scale diffusion models for style transfer
Jiwoo Chung, Sangeek Hyun, and Jae-Pil Heo. Style injec- tion in diffusion: A training-free approach for adapting large- scale diffusion models for style transfer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8795–8805, 2024. 3
2024
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
How to continually adapt text-to-image diffusion models for flexible customization?Advances in Neural In- formation Processing Systems, 37:130057–130083, 2024
Jiahua Dong, Wenqi Liang, Hongliu Li, Duzhen Zhang, Meng Cao, Henghui Ding, Salman H Khan, and Fahad Shah- baz Khan. How to continually adapt text-to-image diffusion models for flexible customization?Advances in Neural In- formation Processing Systems, 37:130057–130083, 2024. 3
2024
-
[7]
A fourier space perspective on diffusion models
Fabian Falck, Teodora Pandeva, Kiarash Zahirnia, Rachel Lawrence, Richard Turner, Edward Meeds, Javier Zazo, and Sushrut Karmalkar. A fourier space perspective on diffusion models.arXiv preprint arXiv:2505.11278, 2025. 3
-
[8]
Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.Journal of Machine Learning Re- search, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.Journal of Machine Learning Re- search, 23(120):1–39, 2022. 2, 3
2022
-
[9]
Implicit style-content separation using b-lora
Yarden Frenkel, Yael Vinker, Ariel Shamir, and Daniel Cohen-Or. Implicit style-content separation using b-lora. In European Conference on Computer Vision, pages 181–198. Springer, 2024. 1, 3
2024
-
[10]
Ensem- ble deep learning: A review.Engineering Applications of Artificial Intelligence, 115:105151, 2022
Mudasir A Ganaie, Minghui Hu, Ashwani Kumar Malik, Muhammad Tanveer, and Ponnuthurai N Suganthan. Ensem- ble deep learning: A review.Engineering Applications of Artificial Intelligence, 115:105151, 2022. 3
2022
-
[11]
Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models.Advances in Neural Information Processing Sys- tems, 36:15890–15902, 2023
Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yun- peng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, et al. Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models.Advances in Neural Information Processing Sys- tems, 36:15890–15902, 2023. 3
2023
-
[12]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1, 3
2020
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 1
2022
-
[14]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022. 2, 3
work page internal anchor Pith review arXiv 2022
-
[15]
Llm-blender: Ensembling large language models with pairwise ranking and generative fusion, 2023
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm- blender: Ensembling large language models with pair- wise ranking and generative fusion.arXiv preprint arXiv:2306.02561, 2023. 3
-
[16]
Rui Kong, Qiyang Li, Xinyu Fang, Qingtian Feng, Qingfeng He, Yazhu Dong, Weijun Wang, Yuanchun Li, Linghe Kong, and Yunxin Liu. Lora-switch: Boosting the efficiency of dy- namic llm adapters via system-algorithm co-design.arXiv preprint arXiv:2405.17741, 2024. 3
-
[17]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023. 3
1931
-
[18]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 1, 5
2024
-
[19]
K-lora: Unlocking training- free fusion of any subject and style loras,
Ziheng Ouyang, Zhen Li, and Qibin Hou. K-lora: Unlock- ing training-free fusion of any subject and style loras.arXiv preprint arXiv:2502.18461, 2025. 2, 3, 5
-
[20]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[21]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 1, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 5
2021
-
[23]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
2022
-
[24]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 2, 3
2023
-
[25]
Low-rank adaptation for fast text-to-image diffu- sion fine-tuning, 2022
Simo Ryu. Low-rank adaptation for fast text-to-image diffu- sion fine-tuning, 2022. 2
2022
-
[26]
Ziplora: Any subject in any style by effectively merging loras
Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svet- lana Lazebnik, Yuanzhen Li, and Varun Jampani. Ziplora: Any subject in any style by effectively merging loras. In European Conference on Computer Vision, pages 422–438. Springer, 2024. 2, 3, 5, 1
2024
-
[27]
In- stantbooth: Personalized text-to-image generation without test-time finetuning
Jing Shi, Wei Xiong, Zhe Lin, and Hyun Joon Jung. In- stantbooth: Personalized text-to-image generation without test-time finetuning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8543–8552, 2024. 3
2024
-
[28]
Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, et al. Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
-
[29]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[30]
P+: Extended textual conditioning in text-to-image generation.arXiv preprint arXiv:2303.09522, 2023
Andrey V oynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. p+: Extended textual conditioning in text-to- image generation.arXiv preprint arXiv:2303.09522, 2023. 3
-
[31]
Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025
Guangxuan Xiao, Tianwei Yin, William T Freeman, Fr ´edo Durand, and Song Han. Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025. 3
2025
-
[32]
Smartbrush: Text and shape guided object inpainting with diffusion model
Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang. Smartbrush: Text and shape guided object inpainting with diffusion model. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22428–22437, 2023
2023
-
[33]
Stylessp: Sampling startpoint enhancement for training-free diffusion-based method for style transfer
Ruojun Xu, Weijie Xi, XiaoDi Wang, Yongbo Mao, and Zach Cheng. Stylessp: Sampling startpoint enhancement for training-free diffusion-based method for style transfer. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18260–18269, 2025. 3
2025
-
[34]
Ties-merging: Resolving interference when merging models.Advances in Neural Information Pro- cessing Systems, 36:7093–7115, 2023
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raf- fel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in Neural Information Pro- cessing Systems, 36:7093–7115, 2023. 2
2023
-
[35]
Yang Yang, Wen Wang, Liang Peng, Chaotian Song, Yao Chen, Hengjia Li, Xiaolong Yang, Qinglin Lu, Deng Cai, Boxi Wu, et al. Lora-composer: Leveraging low-rank adap- tation for multi-concept customization in training-free diffu- sion models.arXiv preprint arXiv:2403.11627, 2024. 2, 3
-
[36]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review arXiv
-
[37]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 5
work page internal anchor Pith review arXiv 2022
-
[38]
Compos- ing parameter-efficient modules with arithmetic operation
Jinghan Zhang, Junteng Liu, Junxian He, et al. Compos- ing parameter-efficient modules with arithmetic operation. Advances in Neural Information Processing Systems, 36: 12589–12610, 2023. 3
2023
-
[39]
Inversion-based style transfer with diffusion models
Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. Inversion-based style transfer with diffusion models. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10146–10156, 2023. 3
2023
-
[40]
Free-merging: Fourier transform for efficient model merging
Shenghe Zheng and Hongzhi Wang. Free-merging: Fourier transform for efficient model merging. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 3863–3873, 2025. 2
2025
- [41]
-
[42]
Shenghe Zheng, Junpeng Jiang, and Wenbo Li. V-bridge: Bridging video generative priors to versatile few-shot image restoration.arXiv preprint arXiv:2603.13089, 2026. 1
-
[43]
Multi-lora composition for image generation,
Ming Zhong, Yelong Shen, Shuohang Wang, Yadong Lu, Yizhu Jiao, Siru Ouyang, Donghan Yu, Jiawei Han, and Weizhu Chen. Multi-lora composition for image generation. arXiv preprint arXiv:2402.16843, 2024. 2, 3
-
[44]
Cached multi-lora composition for multi- concept image generation.arXiv preprint arXiv:2502.04923,
Xiandong Zou, Mingzhu Shen, Christos-Savvas Bouganis, and Yiren Zhao. Cached multi-lora composition for multi- concept image generation.arXiv preprint arXiv:2502.04923,
-
[45]
Notations We first list the notations for key concepts in our paper
2, 3 FREE-Switch: Frequency-based Dynamic LoRA Switch for Style Transfer Supplementary Material A. Notations We first list the notations for key concepts in our paper. Table 2. Notations. Notations Descriptions fPre-trained diffusion model. θc Fine-tuning parameters for content. θs Fine-tuning parameters for style. ht The output oft-th diffuison step. f(h...
-
[46]
Identify the SHARED main subject (present in all images)
-
[47]
Extract 3+ key features that appear in ALL im- ages (ignore features unique to single images)
-
[48]
{Content Description} ({Content Trigger Words}), rendered in {Style Description} ({Style Trigger Words})
Describe them in the required format, excluding all style elements, background, and unique details. - The output must be STRICTLY ≤{concept token limit}tokens. - Prioritize retaining 3+ key features over redundant words if approaching the limit. Output ONLY the following line (no extra text): [shared subject] with [feature1], [feature2], [fea- ture3+] Box...
-
[49]
Identify the artistic medium (e.g., ’oil painting’, ’digital illustration’)
-
[50]
Extract 3+ pure visual style elements (focus on color, lighting, texture, mood — avoid any content)
-
[51]
in ab- stract rainbow colored flowing smoke wave design
Describe them in the required format, excluding all subject-related and non-style details. The output must be STRICTLY ≤{style token limit}tokens. Prioritize retaining 3+ key style elements over re- dundant words if approaching the limit. Use concrete, art-specific vocabulary (e.g., ’impasto texture’, ’muted complementary palette’, ’film- grain aesthetic’...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.