Recognition: unknown
CoSToM:Causal-oriented Steering for Intrinsic Theory-of-Mind Alignment in Large Language Models
Pith reviewed 2026-05-10 16:36 UTC · model grok-4.3
The pith
Causal tracing locates ToM layers in LLMs so that targeted activation steering produces stable intrinsic social reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
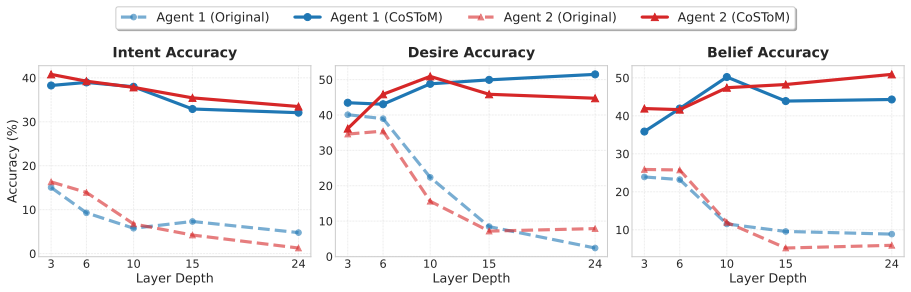
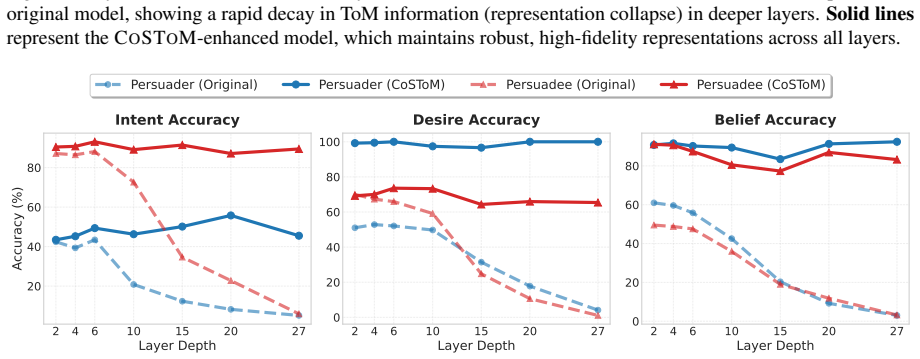
CoSToM first applies causal tracing to map how theory-of-mind features are distributed across the internal layers of large language models, identifying the layers that encode core ToM semantics. It then performs lightweight activation steering within those layers to align the model's internal state with desired social reasoning, moving from passive interpretation to active intervention that improves performance on complex ToM tasks and raises the quality of generated dialogues.
What carries the argument
CoSToM, the framework that uses causal tracing to locate ToM-critical layers followed by targeted activation steering to enforce intrinsic alignment.
If this is right
- Models demonstrate improved generalization on task-specific ToM scenarios that previously required heavy prompt support.
- Downstream dialogue quality increases because social reasoning becomes more consistent and human-like.
- The alignment operates intrinsically, allowing the model to externalize its own knowledge without continued external guidance.
- The same tracing-plus-steering process can be applied to other internal capabilities beyond ToM.
Where Pith is reading between the lines
- The technique could reduce dependence on detailed system prompts in conversational agents and social simulation tools.
- Similar tracing and steering might be tested on other forms of internal reasoning such as causal inference or planning.
- Long-term stability of the steered behavior could be checked after further training or model scaling.
Load-bearing premise
Causal tracing correctly identifies layers that hold fundamental ToM semantics and steering those layers creates stable internal alignment rather than prompt-dependent mimicry.
What would settle it
A controlled test in which steered models lose ToM performance on complex scenarios once all scaffolding prompts are removed or replaced with neutral phrasing, while unsteered baselines show no such change.
Figures









read the original abstract
Theory of Mind (ToM), the ability to attribute mental states to others, is a hallmark of social intelligence. While large language models (LLMs) demonstrate promising performance on standard ToM benchmarks, we observe that they often fail to generalize to complex task-specific scenarios, relying heavily on prompt scaffolding to mimic reasoning. The critical misalignment between the internal knowledge and external behavior raises a fundamental question: Do LLMs truly possess intrinsic cognition, and can they externalize this internal knowledge into stable, high-quality behaviors? To answer this, we introduce CoSToM (Causal-oriented Steering for ToM alignment), a framework that transitions from mechanistic interpretation to active intervention. First, we employ causal tracing to map the internal distribution of ToM features, empirically uncovering the internal layers' characteristics in encoding fundamental ToM semantics. Building on this insight, we implement a lightweight alignment framework via targeted activation steering within these ToM-critical layers. Experiments demonstrate that CoSToM significantly enhances human-like social reasoning capabilities and downstream dialogue quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoSToM, a framework that first applies causal tracing to identify layers in LLMs that encode Theory-of-Mind (ToM) semantics and then performs targeted activation steering in those layers to achieve intrinsic ToM alignment. It claims this yields significant improvements in human-like social reasoning on benchmarks and in downstream dialogue quality, addressing the gap between internal knowledge and prompt-dependent external behavior.
Significance. If the empirical claims hold with proper controls and generalization tests, the work would offer a lightweight, mechanistic alternative to fine-tuning for embedding stable social cognition in LLMs, with potential value for interpretability-driven alignment research.
major comments (2)
- [Abstract] Abstract: The central claim that 'Experiments demonstrate that CoSToM significantly enhances human-like social reasoning capabilities and downstream dialogue quality' is unsupported by any quantitative results, baselines, ablation studies, layer selections, steering magnitudes, or statistical details. This is load-bearing because the paper's contribution rests entirely on these unreported empirical outcomes.
- [Framework description] Framework description (causal tracing and steering steps): The assertion that causal tracing 'empirically uncover[s] the internal layers' characteristics in encoding fundamental ToM semantics' does not include controls such as randomizing the intervention, ablating the causal-tracing step while keeping layer selection fixed, or evaluating on out-of-distribution ToM scenarios. Without these, it remains unclear whether steering produces stable intrinsic alignment or merely amplifies prompt-scaffolded patterns already present in the base model.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the empirical presentation and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experiments demonstrate that CoSToM significantly enhances human-like social reasoning capabilities and downstream dialogue quality' is unsupported by any quantitative results, baselines, ablation studies, layer selections, steering magnitudes, or statistical details. This is load-bearing because the paper's contribution rests entirely on these unreported empirical outcomes.
Authors: We agree that the abstract, being a concise summary, does not embed the specific quantitative details. The full manuscript reports these results in Sections 4 and 5, including baseline comparisons, ablation studies on layer selection and steering magnitudes, and statistical significance tests. To address the concern directly, we will revise the abstract to include key quantitative highlights (e.g., percentage gains on ToM benchmarks and dialogue quality metrics) with pointers to the relevant tables and figures. This change will make the central claim self-supporting while preserving the manuscript's focus. revision: yes
-
Referee: [Framework description] Framework description (causal tracing and steering steps): The assertion that causal tracing 'empirically uncover[s] the internal layers' characteristics in encoding fundamental ToM semantics' does not include controls such as randomizing the intervention, ablating the causal-tracing step while keeping layer selection fixed, or evaluating on out-of-distribution ToM scenarios. Without these, it remains unclear whether steering produces stable intrinsic alignment or merely amplifies prompt-scaffolded patterns already present in the base model.
Authors: We acknowledge that stronger controls are needed to substantiate the causal claims. In the revised manuscript we will add: (1) randomization of intervention locations to non-ToM layers, showing that performance gains are specific to the traced layers; (2) an ablation that retains the same layer set but omits the causal-tracing step, demonstrating the necessity of the tracing procedure; and (3) evaluation on out-of-distribution ToM scenarios to test whether alignment generalizes beyond prompt-scaffolded behavior. These additions will clarify that the observed improvements reflect stable intrinsic alignment rather than amplification of existing patterns. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's chain proceeds from an established causal-tracing procedure (an external interpretability method) to layer identification, followed by activation steering and experimental evaluation on benchmarks. No equations or self-citations are presented that reduce the reported gains to fitted inputs by construction, nor does any step redefine a quantity in terms of itself or import uniqueness solely from prior author work. The framework remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- ToM-critical layer selection
- Activation steering magnitude
axioms (1)
- domain assumption Causal tracing correctly identifies layers that encode fundamental ToM semantics
Reference graph
Works this paper leans on
-
[1]
Trace: Training and inference-time inter- pretability analysis for language models. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstra- tions, pages 806–820. Amos Azaria and Tom M. Mitchell. 2023. The internal state of an LLM knows when it’s lying. InFind- ings of the Association for Computational ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 38, pages 17853–17861
Cooper: Coordinating specialized agents to- wards a complex dialogue goal. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 38, pages 17853–17861. Jia Deng, Tianyi Tang, Yanbin Yin, Wenhao Yang, Xin Zhao, and Ji-Rong Wen. 2025. Neuron based per- sonality trait induction in large language models. In The Thirteenth International Con...
2025
-
[3]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397–14413
Fantom: A benchmark for stress-testing ma- chine theory of mind in interactions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397–14413. Association for Computational Linguistics. Deuksin Kwon, Emily Weiss, Tara Kulshrestha, Kushal Chawla, Gale Lucas, and Jonathan Gratch. 2024. Are llms effective negoti...
2023
-
[4]
doi:10.48550/arXiv.2412.08686 , abstract =
Association for Computational Linguistics. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associa- tions in gpt.Advances in neural information process- ing systems, 35:17359–17372. Rui Miao, Zhengling Qi, and Xiaoke Zhang. 2022. Off-policy evaluation for episodic partially observ- able markov decision proces...
-
[5]
Language in a bottle: Language model guided concept bottlenecks for interpretable image classifi- cation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19187–19197. Fangxu Yu, Lai Jiang, Shenyi Huang, Zhen Wu, and Xinyu Dai. 2025a. Persuasivetom: A benchmark for evaluating machine theory of mind in persuasive d...
-
[6]
InFindings of the Association for Computational Linguistics: EACL 2024, pages 2019–
Let’s negotiate! A survey of negotiation di- alogue systems. InFindings of the Association for Computational Linguistics: EACL 2024, pages 2019–
2024
-
[7]
Tong Zhang, Chen Huang, Yang Deng, Hongru Liang, Jia Liu, Zujie Wen, Wenqiang Lei, and Tat-Seng Chua
Association for Computational Linguistics. Tong Zhang, Chen Huang, Yang Deng, Hongru Liang, Jia Liu, Zujie Wen, Wenqiang Lei, and Tat-Seng Chua. 2024. Strength lies in differences! improv- ing strategy planning for non-collaborative dialogues via diversified user simulation. InProceedings of the 2024 Conference on Empirical Methods in Natu- ral Language P...
-
[8]
You believe that
ToM Reasoning Quality: Is the agent’s understanding of the other’s mental states accurate and appropriately explicit? • 1.0: Highly accurate and explicit. Inference is fully grounded in the dialogue, and uses clear ToM language (e.g., "You believe that..."). • 0.8: Mostly accurate and implicit. Core inference is sound, with minor over-interpretation, and ...
-
[9]
Response is a logical continuation, and all proposals/reasons are directly supported by the dialogue history
Contextual Coherence: Is the response logically and topically aligned with the dialogue history, and are proposal- s/reasons grounded in the known facts? • 1.0: Fully coherent and grounded. Response is a logical continuation, and all proposals/reasons are directly supported by the dialogue history. • 0.8: Well-aligned. Response is logically sound but may ...
-
[10]
sounds fair
Negotiation Strategy Effectiveness: Does the response constructively advance the deal by offering balanced proposals, logical counter-arguments, or maintaining a cooperative frame? • 1.0: Highly effective. Proposes a new, **concrete, and balanced trade-off solution**, framed using highly cooperative language. • 0.8: Constructive response. Clearly accepts/...
2024
-
[11]
you believe
ToM Reasoning Quality: Accuracy of mental state inference • 1.0: Perfectly infers desire/belief/intent from dialogue; uses explicit ToM language ("you believe...", "your concern is...") • 0.8: Accurate inference, implicit phrasing ("I see you value..."), demonstrates social awareness without formalizing it • 0.5: the response identifies some mental states...
-
[12]
I understand you feel X, let’s do Y
Contextual Coherence: Discourse flow, factual grounding, and relevance. • 1.0: Seamless discourse integration, response is perfectly grounded in prior facts with natural flow and zero logical redundancy •0.8: Strong alignment, logically sound but contains minor repetitive phrasing or slight conversational fluff • 0.5: Surface-level coherence, follows basi...
-
[13]
foot-in-the-door,
Persuasion Strategy Effectiveness: move persuasion forward • 1.0: Proposes a highly compelling argument tailored to the partner’s specific concerns. Uses advanced techniques (e.g., "foot-in-the-door," emotional storytelling, or expert social proof) with high empathy • 0.8: Provides logical justifications or clear emotional appeals. Directly addresses the ...
1971
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.