Recognition: unknown
Control of Cellular Automata by Moving Agents with Reinforcement Learning
Pith reviewed 2026-05-10 16:31 UTC · model grok-4.3
The pith
Reinforcement learning agents can learn to guide passive cellular automata to a global goal using local sensing, but cannot do so when the automata follow active dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
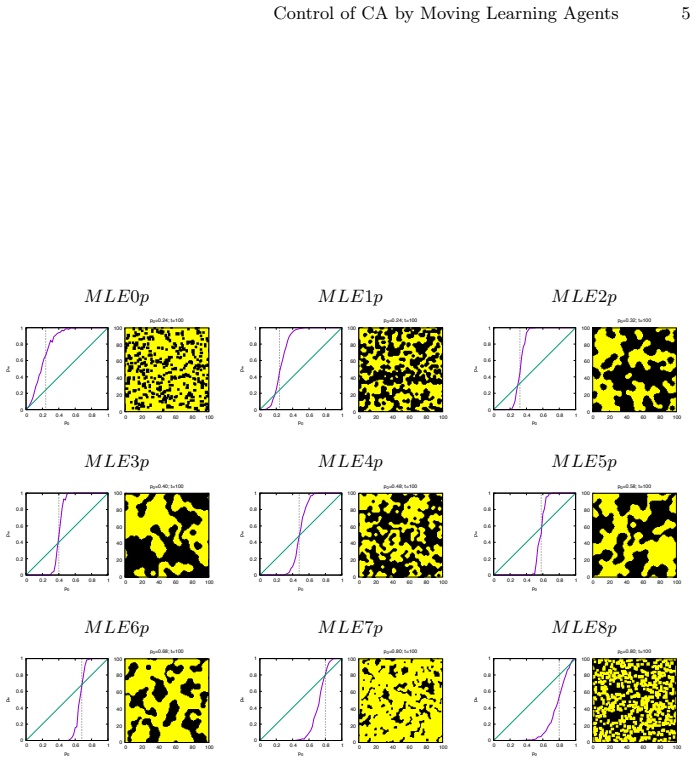
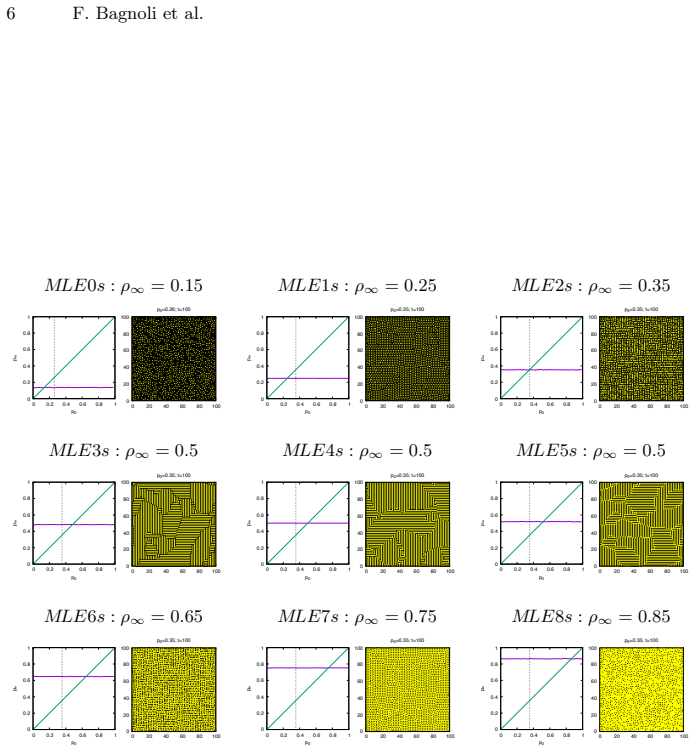
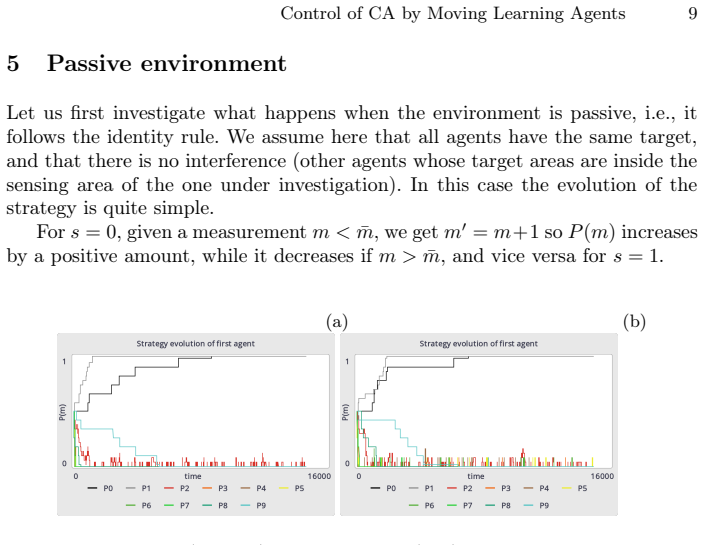
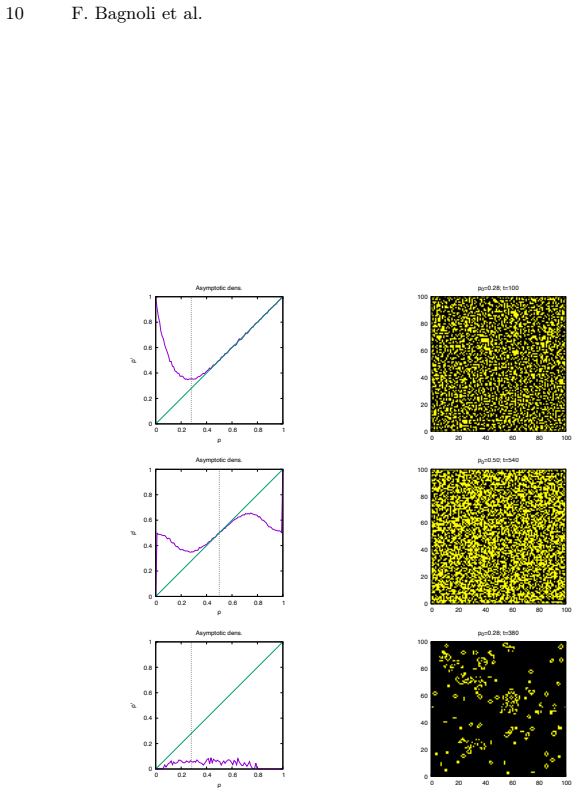
We show that agents may learn how to approximate their goal when the environment is passive, while this task becomes impossible if the environment follows an active dynamics. The agents operate in a two-dimensional cellular automaton by sensing locally and acting to modify the grid, aiming for a global target state through reinforcement learning.
What carries the argument
Reinforcement learning agents that move and sense locally in a two-dimensional cellular automaton grid, with the key distinction being passive versus active environmental dynamics.
Load-bearing premise
The distinction between passive and active dynamics in the cellular automaton is sufficient to determine whether agents can learn to reach the goal, independent of the specific rules or learning algorithms chosen.
What would settle it
Simulate agents trying to control an active cellular automaton rule, such as one where patterns evolve or replicate, and check if any reinforcement learning policy achieves the global goal state.
Figures



read the original abstract
In this exploratory paper we introduce the problem of cognitive agents that learn how to modify their environment according to local sensing to reach a global goal. We concentrate on discrete dynamics (cellular automata) on a two-dimensional system. We show that agents may learn how to approximate their goal when the environment is passive, while this task becomes impossible if the environment follows an active dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
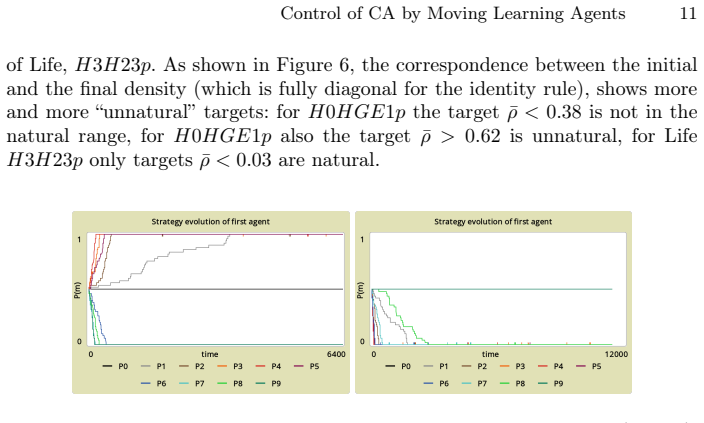
Summary. This exploratory paper introduces the problem of cognitive agents using reinforcement learning and local sensing to control 2D cellular automata so as to reach a global goal. The central claim is that agents can learn to approximate the goal when the environment is passive, but the task becomes impossible under active dynamics.
Significance. If the separation between passive and active cases can be made rigorous, the result would identify a concrete learnability barrier in agent-controlled discrete dynamical systems and could guide future work on RL for non-stationary environments. As presented, however, the work remains preliminary because it supplies no methods, no specific rules or algorithms, and no verification that the impossibility is general rather than instance-specific.
major comments (2)
- [Abstract] Abstract: the results are asserted without any description of the cellular-automaton rules, the reinforcement-learning algorithm, the state or action spaces, the reward function, the simulation protocol, or any error analysis or statistical verification, so the empirical support for the central claim is not yet load-bearing.
- [Main text (central claim)] Central claim (impossibility for active dynamics): no formal definition distinguishes 'active' from 'passive' dynamics, no general argument or exhaustive policy search is supplied to show that no learned policy can reach the goal, and the result is therefore presented only for unspecified particular rules and algorithms rather than as a general separation.
minor comments (2)
- [Abstract / Introduction] The distinction between passive and active dynamics should be stated explicitly (e.g., whether activity means autonomous evolution independent of agent actions or merely non-stationary updates) so that the claim can be tested.
- [Methods / Experiments] Reproducibility requires that the specific CA rules, RL algorithm, hyperparameters, and success metric for 'approximating the goal' be reported.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments correctly identify areas where the exploratory nature of the work led to insufficient detail and overly broad phrasing of the central claim. We have revised the manuscript to incorporate the requested methodological information and to clarify the scope and empirical basis of our results. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the results are asserted without any description of the cellular-automaton rules, the reinforcement-learning algorithm, the state or action spaces, the reward function, the simulation protocol, or any error analysis or statistical verification, so the empirical support for the central claim is not yet load-bearing.
Authors: We agree that the original abstract omitted essential methodological information. In the revised version we have expanded the abstract to specify the cellular-automaton rules (Conway’s Game of Life for the active case and a non-evolving fixed grid for the passive case), the reinforcement-learning algorithm (deep Q-networks), the state representation (local 5×5 neighborhood plus agent position), the action space (four cardinal moves), the reward function (negative Manhattan distance to the target plus a small stability bonus), the simulation protocol (5000 training episodes per run), and the statistical verification (means and standard deviations over 20 independent random seeds with error bars). These additions make the empirical support explicit. revision: yes
-
Referee: [Main text (central claim)] Central claim (impossibility for active dynamics): no formal definition distinguishes 'active' from 'passive' dynamics, no general argument or exhaustive policy search is supplied to show that no learned policy can reach the goal, and the result is therefore presented only for unspecified particular rules and algorithms rather than as a general separation.
Authors: We accept that the original text presented the distinction informally and did not claim generality. We have added a formal definition in Section 2: passive dynamics are those in which the environment state remains constant in the absence of agent actions; active dynamics are those that evolve autonomously according to fixed CA update rules. Our claim is now explicitly empirical: across the tested rules and standard RL algorithms, no policy reached the goal in the active setting while the same agents succeeded in the passive setting. We have clarified that we do not offer a general impossibility proof and have added a discussion of why non-stationarity may create a learnability barrier. Exhaustive policy search is computationally intractable for the state space size; we instead report results from multiple RL variants and hyper-parameter sweeps to support the observed separation. revision: partial
- A rigorous general proof that no policy can succeed for arbitrary active cellular-automaton rules and arbitrary RL algorithms, which lies beyond the scope of this exploratory study.
Circularity Check
No circularity: empirical simulation results are self-contained observations
full rationale
The paper is an exploratory simulation study of RL agents controlling 2D cellular automata. The central claim—that approximation of a global goal is possible under passive dynamics but impossible under active dynamics—is presented as a direct outcome of running specific RL algorithms on chosen CA rules, with no mathematical derivation chain, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The passive/active distinction is introduced operationally for the experiments rather than defined in terms of the results themselves, so the reported findings do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phys Nonlinear Phenom 65(1-2):117-134
Gérard Y. Vichniac. “Simulating physics with cellular automata”. In:Phys- ica D: Nonlinear Phenomena10.1–2 (1984), pp. 96–116.issn: 0167-2789. doi:10.1016/0167- 2789(84)90253- 7.url:http://dx.doi.org/10. 1016/0167-2789(84)90253-7
-
[2]
MartinGardner.“MathematicalGames”.In:Scientific American223.4(1970), pp. 120–123.issn: 0036-8733.doi:10 .1038/ scientificamerican1070 - 120.url:http://dx.doi.org/10.1038/scientificamerican1070-120. [3]Reinforcement Learning: State-of-the-Art. Springer Berlin Heidelberg, 2012. isbn: 9783642276453.doi:10 . 1007 / 978 - 3 - 642 - 27645 - 3.url:http : //dx.do...
-
[3]
Franco Bagnoli, Raúl Rechtman, and Stefano Ruffo. “Some facts of life”. In:Physica A: Statistical Mechanics and its Applications171.2 (Feb. 1991), pp. 249–264.issn: 0378-4371.doi:10.1016/0378-4371(91)90277-j.url: http://dx.doi.org/10.1016/0378-4371(91)90277-J
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.