Recognition: unknown
MoRI: Mixture of RL and IL Experts for Long-Horizon Manipulation Tasks
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
Dynamically switching between imitation and reinforcement learning experts by action variance achieves 97.5 percent success on complex robotic manipulation tasks with far less human intervention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
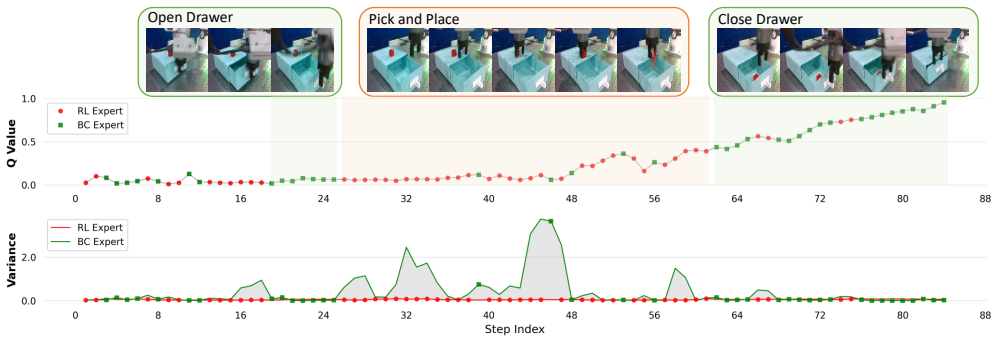
MoRI pre-trains an imitation expert and a reinforcement learning expert offline, then in online fine-tuning switches between them according to the variance in their action outputs to manage coarse and fine movements, while regularizing the RL policy with the IL one to maintain safe exploration, leading to high success rates on real-world tasks.
What carries the argument
The variance between actions from the IL and RL experts, which determines dynamic switching between the experts during task execution.
Load-bearing premise
The difference in action variance between the two experts is a dependable way to choose between imitation for rough motions and reinforcement for detailed ones, and the four tasks cover the typical challenges in long-horizon manipulation.
What would settle it
Evaluating the system on a fifth long-horizon task where switching based on variance does not improve success rates or reduce interventions compared to using only RL or only IL.
Figures




read the original abstract
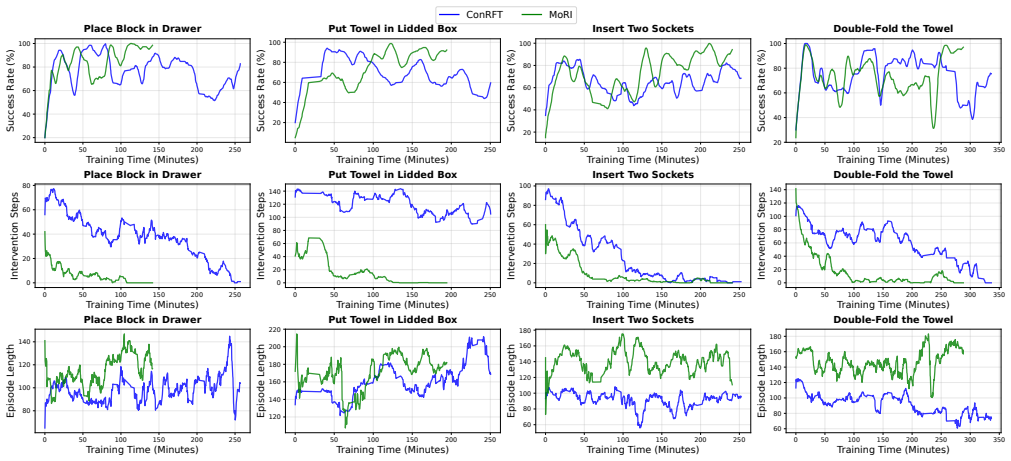
Reinforcement Learning (RL) and Imitation Learning (IL) are the standard frameworks for policy acquisition in manipulation. While IL offers efficient policy derivation, it suffers from compounding errors and distribution shift. Conversely, RL facilitates autonomous exploration but is frequently hindered by low sample efficiency and the high cost of trial and error. Since existing hybrid methods often struggle with complex tasks, we introduce Mixture of RL and IL Experts (MoRI). This system dynamically switches between IL and RL experts based on the variance of expert actions to handle coarse movements and fine-grained manipulations. MoRI employs an offline pre-training stage followed by online fine-tuning to accelerate convergence. To maintain exploration safety and minimize human intervention, the system applies IL-based regularization to the RL component. Evaluation across four complex real-world tasks shows that MoRI achieves an average success rate of 97.5% within 2 to 5 hours of fine-tuning. Compared to baseline RL algorithms, MoRI reduces human intervention by 85.8% and shortens convergence time by 21%, demonstrating its capability in robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MoRI, a hybrid Mixture of RL and IL Experts system for long-horizon robotic manipulation tasks. It dynamically switches between IL and RL experts using the variance of their actions to manage coarse movements versus fine-grained control, incorporates offline pre-training followed by online fine-tuning, and applies IL-based regularization to the RL component for exploration safety. Evaluations on four complex real-world tasks report an average 97.5% success rate within 2-5 hours of fine-tuning, an 85.8% reduction in human intervention, and 21% shorter convergence time relative to baseline RL algorithms.
Significance. If the empirical results hold under detailed scrutiny and the variance-based switching mechanism generalizes beyond the four evaluated tasks, MoRI could offer a practical advance in hybrid RL-IL methods by improving sample efficiency, reducing reliance on human oversight, and enabling safer autonomous exploration in complex manipulation. The reported reductions in intervention time and faster convergence would be notable strengths for real-world robotics applications.
major comments (3)
- [Abstract] Abstract: The central performance claims (97.5% average success rate, 85.8% reduction in human intervention, 21% shorter convergence) are stated without any description of the four tasks, the specific baseline RL algorithms, number of trials, variance across runs, or statistical tests. This absence prevents verification of whether the gains are attributable to the proposed method or to unstated factors such as task selection or expert pre-training quality.
- [Method] Method section (variance-based switching): The dynamic expert selection relies on action variance between the RL and IL experts as the signal for favoring coarse IL versus fine RL. No ablation is described that isolates this signal against fixed-ratio mixing, random switching, or variance-agnostic baselines, leaving open the possibility that reported gains stem primarily from pre-training and regularization rather than the variance mechanism itself.
- [Evaluation] Evaluation: The claim that MoRI reduces human intervention by 85.8% and converges 21% faster is load-bearing for the paper's contribution, yet the text supplies no implementation details, hyperparameter settings, or analysis showing that the variance signal correlates reliably with task requirements across long-horizon scenarios rather than being an artifact of the specific expert training.
minor comments (2)
- [Abstract] Abstract: The phrase 'baseline RL algorithms' is used without naming the specific methods (e.g., SAC, TD3, or PPO), which is needed for reproducibility and fair comparison.
- [Method] The manuscript would benefit from a clear pseudocode or diagram illustrating the exact variance computation and switching threshold logic.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments below and have prepared revisions to strengthen the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (97.5% average success rate, 85.8% reduction in human intervention, 21% shorter convergence) are stated without any description of the four tasks, the specific baseline RL algorithms, number of trials, variance across runs, or statistical tests. This absence prevents verification of whether the gains are attributable to the proposed method or to unstated factors such as task selection or expert pre-training quality.
Authors: We agree with the referee that the abstract would be more informative with additional context. In the revised manuscript, we will expand the abstract to include brief descriptions of the four tasks, the specific baseline RL algorithms used, the number of trials conducted, the variance across runs, and any statistical tests performed. This will allow readers to better evaluate the claims. revision: yes
-
Referee: [Method] Method section (variance-based switching): The dynamic expert selection relies on action variance between the RL and IL experts as the signal for favoring coarse IL versus fine RL. No ablation is described that isolates this signal against fixed-ratio mixing, random switching, or variance-agnostic baselines, leaving open the possibility that reported gains stem primarily from pre-training and regularization rather than the variance mechanism itself.
Authors: The variance-based switching mechanism is central to MoRI's ability to handle long-horizon tasks by adapting to the uncertainty in expert actions. While the original submission focused on the overall system performance, we recognize the value of isolating this component. We will add an ablation study in the revised paper comparing the variance-based approach to fixed-ratio mixing, random switching, and variance-agnostic baselines. This will demonstrate the contribution of the dynamic variance signal. revision: yes
-
Referee: [Evaluation] Evaluation: The claim that MoRI reduces human intervention by 85.8% and converges 21% faster is load-bearing for the paper's contribution, yet the text supplies no implementation details, hyperparameter settings, or analysis showing that the variance signal correlates reliably with task requirements across long-horizon scenarios rather than being an artifact of the specific expert training.
Authors: We appreciate this point and will enhance the evaluation section in the revision. We will provide detailed implementation specifics on how human interventions are measured and counted, the hyperparameter settings for the variance threshold, and additional analysis demonstrating the correlation of the variance signal with task requirements in long-horizon scenarios. This will help confirm the reliability of the mechanism. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical system (MoRI) with a design choice for dynamic switching based on action variance, followed by offline pre-training and online fine-tuning. No equations, derivations, or mathematical reductions are present. Results are reported as experimental outcomes on four tasks rather than self-referential fits or predictions forced by construction. No self-citation load-bearing steps or uniqueness theorems are invoked in the provided text. The central claims rest on empirical evaluation, which is independent of the method description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” 2023. [Online]. Available: https://arxiv.org/abs/2304.13705
work page internal anchor Pith review arXiv 2023
-
[2]
Waypoint- based imitation learning for robotic manipulation,
L. X. Shi, A. Sharma, T. Z. Zhao, and C. Finn, “Waypoint- based imitation learning for robotic manipulation,” 2023. [Online]. Available: https://arxiv.org/abs/2307.14326
-
[3]
E. Welte and R. Rayyes, “Interactive imitation learning for dexterous robotic manipulation: Challenges and perspectivesa survey,”Frontiers in Robotics and AI, vol. V olume 12 - 2025, 2025. [Online]. Available: https://www.frontiersin.org/journals/ robotics-and-ai/articles/10.3389/frobt.2025.1682437
-
[4]
The pitfalls of imitation learning when actions are continuous,
M. Simchowitz, D. Pfrommer, and A. Jadbabaie, “The pitfalls of imitation learning when actions are continuous,” 2025. [Online]. Available: https://arxiv.org/abs/2503.09722
-
[5]
Serl: A software suite for sample- efficient robotic reinforcement learning,
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine, “Serl: A software suite for sample- efficient robotic reinforcement learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 16 961– 16 969
2024
-
[6]
Arraybot: Reinforcement learning for generalizable distributed manipulation through touch,
Z. Xue, H. Zhang, J. Cheng, Z. He, Y . Ju, C. Lin, G. Zhang, and H. Xu, “Arraybot: Reinforcement learning for generalizable distributed manipulation through touch,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 16 744–16 751
2024
-
[7]
Q. Xu, J. Liu, R. Zhou, S. Shi, N. Han, Z. Liu, C. Gu, S. Gu, Y . Yue, G. Huang, W. Zheng, S. Han, P. Jia, and S. Zhang, “Twinrl-vla: Digital twin-driven reinforcement learning for real-world robotic manipulation,” 2026. [Online]. Available: https://arxiv.org/abs/2602.09023
-
[8]
Collaborative motion planning for multi-manipulator systems through reinforcement learning and dy- namic movement primitives,
S. Singh, T. Xu, and Q. Chang, “Collaborative motion planning for multi-manipulator systems through reinforcement learning and dy- namic movement primitives,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 3369–3375
2025
-
[9]
Rl-100: Performant robotic ma- nipulation with real-world reinforcement learning,
K. Lei, H. Li, D. Yu, Z. Wei, L. Guo, Z. Jiang, Z. Wang, S. Liang, and H. Xu, “Rl-100: Performant robotic manipulation with real-world reinforcement learning,” 2026. [Online]. Available: https://arxiv.org/abs/2510.14830
-
[10]
Hg-dagger: Interactive imitation learning with human experts,
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer, “Hg-dagger: Interactive imitation learning with human experts,” in 2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 8077–8083
2019
-
[11]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,
J. Luo, C. Xu, J. Wu, and S. Levine, “Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,”Science Robotics, vol. 10, no. 105, p. eads5033, 2025. [Online]. Available: https://www.science.org/doi/abs/10.1126/scirobotics.ads5033
-
[12]
Conrft: A reinforced fine-tuning method for vla models via consistency policy,
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao, “Conrft: A reinforced fine-tuning method for vla models via consistency policy,”
-
[13]
[Online]. Available: https://arxiv.org/abs/2502.05450
-
[14]
Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang, “Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2505.18719
-
[15]
Reinforcement and imitation learning for diverse visuomotor skills,
Y . Zhu, Z. Wang, J. Merel, A. Rusu, T. Erez, S. Cabi, S. Tunyasuvunakool, J. Kramr, R. Hadsell, N. de Freitas, and N. Heess, “Reinforcement and imitation learning for diverse visuomotor skills,”
-
[16]
Rein- forcement and imitation learning for diverse visuomotor skills
[Online]. Available: https://arxiv.org/abs/1802.09564
-
[17]
Reinforcegen: Hybrid skill policies with automated data generation and reinforcement learning,
Z. Zhou, A. Garg, A. Mandlekar, and C. Garrett, “Reinforcegen: Hybrid skill policies with automated data generation and reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2512.16861
-
[18]
Offline Reinforcement Learning with Implicit Q-Learning
I. Kostrikov, A. Nair, and S. Levine, “Offline reinforcement learning with implicit q-learning,” 2021. [Online]. Available: https://arxiv.org/abs/2110.06169
work page internal anchor Pith review arXiv 2021
-
[19]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
A. Nair, A. Gupta, M. Dalal, and S. Levine, “Awac: Accelerating online reinforcement learning with offline datasets,” 2021. [Online]. Available: https://arxiv.org/abs/2006.09359
work page internal anchor Pith review arXiv 2021
-
[20]
Residual off-policy rl for finetuning behavior cloning policies,
L. Ankile, Z. Jiang, R. Duan, G. Shi, P. Abbeel, and A. Nagabandi, “Residual off-policy rl for finetuning behavior cloning policies,”
-
[21]
[Online]. Available: https://arxiv.org/abs/2509.19301
-
[22]
π RL: Online rl fine-tuning for flow-based vision-language-action models,
K. Chen, Z. Liu, T. Zhang, Z. Guo, S. Xu, H. Lin, H. Zang, X. Li, Q. Zhang, Z. Yu, G. Fan, T. Huang, Y . Wang, and C. Yu, “π RL: Online rl fine-tuning for flow-based vision-language-action models,”
-
[23]
[Online]. Available: https://arxiv.org/abs/2510.25889
-
[24]
A survey on reinforcement learning of vision-language-action models for robotic manipulation,
H. Deng, Z. Wu, H. Liu, W. Guo, Y . Xue, Z. Shan, C. Zhang, B. Jia, Y . Ling, G. Lu, and Z. Wang, “A survey on reinforcement learning of vision-language-action models for robotic manipulation,”TechRxiv, vol. 2025, no. 1209, 2025. [Online]. Available: https://www.techrxiv. org/doi/abs/10.36227/techrxiv.176531955.54563920/v1
-
[25]
Guided cost learning: Deep inverse optimal control via policy optimization,
C. Finn, S. Levine, and P. Abbeel, “Guided cost learning: Deep inverse optimal control via policy optimization,” inProceedings of The 33rd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. F. Balcan and K. Q. Weinberger, Eds., vol. 48. New York, New York, USA: PMLR, 20–22 Jun 2016, pp. 49–58. [Online]. Availab...
2016
-
[26]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” 2017. [Online]. Available: https://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Germ: A generalist robotic model with mixture-of-experts for quadruped robot,
W. Song, H. Zhao, P. Ding, C. Cui, S. Lyu, Y . Fan, and D. Wang, “Germ: A generalist robotic model with mixture-of-experts for quadruped robot,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 11 879–11 886
2024
-
[28]
Moe-loco: Mixture of experts for multitask locomotion,
R. Huang, S. Zhu, Y . Du, and H. Zhao, “Moe-loco: Mixture of experts for multitask locomotion,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 14 218–14 225
2025
-
[29]
K. Guo, H. Liu, Y . Sun, R. Zhao, J. Zhou, and J. Ma, “Moe-act: Scaling multi-task bimanual manipulation with sparse language-conditioned mixture-of-experts transformers,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.15265
-
[30]
B. Cheng, T. Liang, S. Huang, M. Shao, F. Zhang, B. Xu, Z. Xue, and H. Xu, “Moe-dp: An moe-enhanced diffusion policy for robust long- horizon robotic manipulation with skill decomposition and failure recovery,” 2025. [Online]. Available: https://arxiv.org/abs/2511.05007
-
[31]
Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation,
J. Yu, H. Liu, Q. Yu, J. Ren, C. Hao, H. Ding, G. Huang, G. Huang, Y . Song, P. Cai, C. Lu, and W. Zhang, “Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2505.22159
-
[32]
π0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π0: A vision-language-action flow model for general robot control,”
-
[33]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
[Online]. Available: https://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning,
X. B. Peng, A. Kumar, G. Zhang, and S. Levine, “Advantage-weighted regression: Simple and scalable off-policy reinforcement learning,”
-
[35]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
[Online]. Available: https://arxiv.org/abs/1910.00177
work page internal anchor Pith review arXiv 1910
-
[36]
J. Siekmann, K. Green, J. Warila, A. Fern, and J. Hurst, “Blind bipedal stair traversal via sim-to-real reinforcement learning,” 2021. [Online]. Available: https://arxiv.org/abs/2105.08328
-
[37]
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
J. Tan, T. Zhang, E. Coumans, A. Iscen, Y . Bai, D. Hafner, S. Bohez, and V . Vanhoucke, “Sim-to-real: Learning agile locomotion for quadruped robots,” 2018. [Online]. Available: https://arxiv.org/abs/ 1804.10332
work page Pith review arXiv 2018
-
[38]
Ensem- bledagger: A bayesian approach to safe imitation learning,
K. Menda, K. Driggs-Campbell, and M. J. Kochenderfer, “Ensem- bledagger: A bayesian approach to safe imitation learning,” in2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 5041–5048
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.