Recognition: unknown
Device-Conditioned Neural Architecture Search for Efficient Robotic Manipulation
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
A single supernet trained once lets users find efficient quantized policies for robotic manipulation on any new hardware via quick search instead of retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
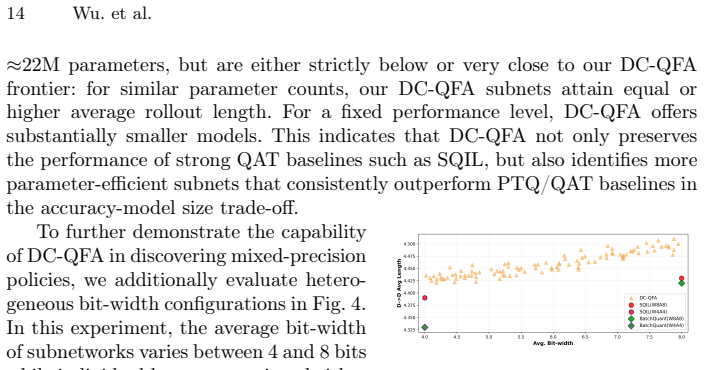
We propose DC-QFA, a unified framework for device-conditioned quantization-aware training and hardware-constrained architecture search. A single supernet spans network architectures and mixed-precision bit-widths and is optimized with latency- and memory-aware regularization guided by per-device lookup tables. This supernet supports once-for-all lightweight search to select an optimal subnet for each target platform without any per-device re-optimization. Multi-step on-policy distillation further improves long-horizon stability under low precision. Experiments across DiffusionPolicy-T, MDT-V, and OpenVLA-OFT backbones show 2-3× acceleration on edge, consumer GPU, and cloud platforms with no,
What carries the argument
The device-conditioned supernet that jointly spans architectures and bit-widths while incorporating per-device latency and memory constraints during training.
If this is right
- Policies can be adapted to new robotic hardware in minutes rather than requiring full per-device optimization cycles.
- The same trained supernet supports edge devices, consumer GPUs, and cloud platforms with 2-3× speedups and nearly unchanged task success.
- Multi-step distillation keeps low-precision policies stable during long closed-loop manipulation sequences.
- The approach works across multiple policy backbones including diffusion, transformer, and vision-language models.
- Real-robot tests confirm stable contact-rich behavior on force/torque equipped arms under severe quantization.
Where Pith is reading between the lines
- This amortizes the cost of efficient-model design so that robot developers could iterate hardware choices more freely without repeating model work each time.
- The method may extend naturally to other sequential decision tasks where hardware constraints vary, such as autonomous driving or drone control.
- If the supernet generalizes well, it could reduce the total compute spent on model optimization across an entire fleet of heterogeneous robots.
Load-bearing premise
A single supernet trained with device-guided regularization will contain high-performing subnets for every target hardware without needing separate retraining or search per device.
What would settle it
Running the once-for-all search on an unseen hardware platform and finding that the selected subnet has substantially lower task success rate than a model retrained specifically for that platform.
Figures



read the original abstract
The growing complexity of visuomotor policies poses significant challenges for deployment with heterogeneous robotic hardware constraints. However, most existing model-efficient approaches for robotic manipulation are device- and model-specific, lack generalizability, and require time-consuming per-device optimization during the adaptation process. In this work, we propose a unified framework named \textbf{D}evice-\textbf{C}onditioned \textbf{Q}uantization-\textbf{F}or-\textbf{A}ll (DC-QFA) which amortizes deployment effort with the device-conditioned quantization-aware training and hardware-constrained architecture search. Specifically, we introduce a single supernet that spans a rich design space over network architectures and mixed-precision bit-widths. It is optimized with latency- and memory-aware regularization, guided by per-device lookup tables. With this supernet, for each target platform, we can perform a once-for-all lightweight search to select an optimal subnet without any per-device re-optimization, which enables more generalizable deployment across heterogeneous hardware, and substantially reduces deployment time. To improve long-horizon stability under low precision, we further introduce multi-step on-policy distillation to mitigate error accumulation during closed-loop execution. Extensive experiments on three representative policy backbones, such as DiffusionPolicy-T, MDT-V, and OpenVLA-OFT, demonstrate that our DC-QFA achieves $2\text{-}3\times$ acceleration on edge devices, consumer-grade GPUs, and cloud platforms, with negligible performance drop in task success. Real-world evaluations on an Inovo robot equipped with a force/torque sensor further validates that our low-bit DC-QFA policies maintain stable, contact-rich manipulation even under severe quantization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Device-Conditioned Quantization-For-All (DC-QFA) framework for efficient deployment of visuomotor policies on heterogeneous robotic hardware. It trains a single supernet spanning network architectures and mixed-precision bit-widths, optimized with latency- and memory-aware regularization guided by per-device lookup tables. This enables a once-for-all lightweight search to extract optimal subnets per target platform without per-device re-optimization or retraining. Multi-step on-policy distillation is added to mitigate error accumulation under low precision. Experiments on three policy backbones (DiffusionPolicy-T, MDT-V, OpenVLA-OFT) report 2-3× acceleration on edge devices, GPUs, and cloud platforms with negligible task-success drop, with additional real-world validation on an Inovo robot.
Significance. If the empirical claims hold under detailed scrutiny, the work would be significant for robotics by amortizing deployment costs for complex visuomotor policies across heterogeneous hardware. The supernet-plus-lightweight-search paradigm and distillation technique directly target practical deployment bottlenecks, potentially enabling more generalizable efficient policies if the single-supernet assumption is substantiated.
major comments (1)
- [Experimental Evaluation] The central performance claims (2-3× acceleration with negligible success-rate drop across three backbones and real-robot validation) are stated at a high level in the abstract and experimental summary without quantitative tables, per-device/per-backbone metrics, error bars, or ablation studies on the regularization coefficients and distillation steps. This is load-bearing for the weakest assumption that one supernet trained with device-specific lookup-table regularization contains near-optimal subnets for every target platform without re-optimization.
minor comments (1)
- [Abstract] The three policy backbones are named (DiffusionPolicy-T, MDT-V, OpenVLA-OFT) but receive no brief architectural descriptions or references to their original papers, which would aid readers in interpreting the generality of the results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that strengthening the experimental presentation is important and will revise the manuscript to include the requested quantitative details and ablations while preserving the core technical contributions.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central performance claims (2-3× acceleration with negligible success-rate drop across three backbones and real-robot validation) are stated at a high level in the abstract and experimental summary without quantitative tables, per-device/per-backbone metrics, error bars, or ablation studies on the regularization coefficients and distillation steps. This is load-bearing for the weakest assumption that one supernet trained with device-specific lookup-table regularization contains near-optimal subnets for every target platform without re-optimization.
Authors: We agree that more granular quantitative results are needed to substantiate the claims. In the revised manuscript we will add comprehensive tables reporting per-device and per-backbone success rates, latency, and memory usage together with standard deviations computed over multiple evaluation seeds. We will also include ablation studies on the latency/memory regularization coefficients and on the number of distillation steps, showing their effect on final task performance. To address the core assumption, we will expand the analysis in Sections 3 and 4 with additional comparisons between the device-conditioned search results and randomly sampled subnets from the same supernet, demonstrating that the lookup-table-guided training indeed places near-optimal architectures within the searchable space for each target platform without requiring per-device retraining. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical supernet-based framework (DC-QFA) for device-conditioned quantization-aware training and hardware-constrained NAS. Its central claims of 2-3× acceleration with negligible task-success drop are supported by experiments across three policy backbones and real-robot validation on held-out tasks and hardware, without any equations, predictions, or derivations that reduce reported outcomes to fitted parameters or self-referential definitions by construction. No self-citation chains, uniqueness theorems, or ansatzes underpin the load-bearing steps; the approach is self-contained as a practical, externally validated method.
Axiom & Free-Parameter Ledger
free parameters (1)
- latency and memory regularization coefficients
axioms (1)
- domain assumption Quantization-aware training combined with architecture search produces subnets whose closed-loop behavior remains stable after multi-step distillation.
Reference graph
Works this paper leans on
-
[1]
In: Conf
Arachchige, N.R., Chen, Z., Jung, W., Shin, W.C., Bansal, R., Barroso, P., He, Y.H., Lin, Y.C., Joffe, B., Kousik, S., et al.: Sail: Faster-than-demonstration exe- cution of imitation learning policies. In: Conf. Robot. Learn. pp. 721–749. PMLR (2025)
2025
-
[2]
Ashkboos, S., Mohtashami, A., Croci, M.L., Li, B., Cameron, P., Jaggi, M., Alis- tarh, D., Hoefler, T., Hensman, J.: Quarot: Outlier-free 4-bit inference in rotated llms. Adv. Neural Inform. Process. Syst.37, 100213–100240 (2024)
2024
-
[3]
Bai, H., Cao, M., Huang, P., Shan, J.: Batchquant: Quantized-for-all architecture search with robust quantizer. In: Adv. Neural Inform. Process. Syst. vol. 34, pp. 1074–1085 (2021)
2021
-
[4]
In: Robotics Science and Systems (2024)
Belkhale, S., Ding, T., Xiao, T., Sermanet, P., Vuong, Q., Tompson, J., Chebotar, Y., Dwibedi, D., Sadigh, D.: Rt-h: Action hierarchies using language. In: Robotics Science and Systems (2024)
2024
-
[5]
In: Conf
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Galliker, M.Y., Ghosh, D., Groom, L., Hausman, K., ichter, b., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A.Z., Shi, L.X., Smith, L., Springen- berg, J.T., Stachowicz, K., Tanne...
2025
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
In: NeurIPS (2025),https://openreview.net/forum?id=UkR2zO5uww
Black, K., Galliker, M.Y., Levine, S.: Real-time execution of action chunking flow policies. In: NeurIPS (2025),https://openreview.net/forum?id=UkR2zO5uww
2025
-
[8]
Black, K., Ren, A.Z., Equi, M., Levine, S.: Training-time action conditioning for efficient real-time chunking. arXiv preprint arXiv:2512.05964 (2025) 16 Wu. et al
-
[9]
Robotics Science and Systems (2023)
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. Robotics Science and Systems (2023)
2023
-
[10]
In: Conf
Brohan, A., Chebotar, Y., Finn, C., Hausman, K., Herzog, A., Ho, D., Ibarz, J., Irpan, A., Jang, E., Julian, R., et al.: Do as i can, not as i say: Grounding language in robotic affordances. In: Conf. Robot. Learn. pp. 287–318. PMLR (2023)
2023
-
[11]
Cai, H., Gan, C., Wang, T., Zhang, Z., Han, S.: Once-for-all: Train one network and specialize it for efficient deployment. In: Int. Conf. Learn. Represent. (2019)
2019
-
[12]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Cheang, C.L., Chen, G., Jing, Y., Kong, T., Li, H., Li, Y., Liu, Y., Wu, H., Xu, J., Yang, Y., et al.: Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158 (2024)
work page internal anchor Pith review arXiv 2024
- [13]
-
[14]
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. Int. J. Robot. Res.44(10-11), 1684–1704 (2025)
2025
-
[15]
In: IEEE Conf
Gao, T., Guo, L., Zhao, S., Xu, P., Yang, Y., Liu, X., Wang, S., Zhu, S., Zhou, D.: Quantnas: quantization-aware neural architecture search for efficient deployment on mobile device. In: IEEE Conf. Comput. Vis. Pattern Recog. Worksh. pp. 1704– 1713 (2024)
2024
-
[16]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. arXiv preprint arXiv:2502.19645 (2025)
work page internal anchor Pith review arXiv 2025
-
[17]
In: Conf
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., et al.: Openvla: An open-source vision-language-action model. In: Conf. Robot. Learn. pp. 2679–2713. PMLR (2025)
2025
-
[18]
In: Proceedings of machine learning and systems
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.M., Wang, W.C., Xiao, G., Dang, X., Gan, C., Han, S.: Awq: Activation-aware weight quantization for on-device llm compression and acceleration. In: Proceedings of machine learning and systems. vol. 6, pp. 87–100 (2024)
2024
-
[19]
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Bench- marking knowledge transfer for lifelong robot learning. In: Adv. Neural Inform. Process. Syst. vol. 36, pp. 44776–44791 (2023)
2023
-
[20]
Liu, Z., Zhao, C., Huang, H., Chen, S., Zhang, J., Zhao, J., Roy, S., Jin, L., Xiong, Y., Shi, Y., et al.: Paretoq: Scaling laws in extremely low-bit llm quantization. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[21]
IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
Mees, O., Hermann, L., Rosete-Beas, E., Burgard, W.: Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
2022
-
[22]
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learn- ing datasets and rt-x models: Open x-embodiment collaboration 0. In: Int. Conf. Robot. Autom. pp. 6892–6903. IEEE (2024)
2024
-
[23]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Trans. Machine Learning Research J. (2024)
2024
-
[24]
Park, S., Kim, H., Kim, S., Jeon, W., Yang, J., Jeon, B., Oh, Y., Choi, J.: Saliency- aware quantized imitation learning for efficient robotic control. In: Int. Conf. Com- put. Vis. pp. 13140–13150 (2025) Device-Conditioned NAS for Efficient Robotic Manipulation 17
2025
-
[25]
In: Robotics Science and Systems (2024)
Reuss, M., Yağmurlu, Ö.E., Wenzel, F., Lioutikov, R.: Multimodal diffusion trans- former: Learning versatile behavior from multimodal goals. In: Robotics Science and Systems (2024)
2024
-
[26]
Shen, M., Liang, F., Gong, R., Li, Y., Li, C., Lin, C., Yu, F., Yan, J., Ouyang, W.: Once quantization-aware training: High performance extremely low-bit archi- tecture search. In: Int. Conf. Comput. Vis. pp. 5340–5349 (2021)
2021
-
[27]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zoui- tine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., et al.: Smolvla: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv:2506.01844 (2025)
work page internal anchor Pith review arXiv 2025
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
In: IEEE Conf
Wang, K., Liu, Z., Lin, Y., Lin, J., Han, S.: Haq: Hardware-aware automated quantization with mixed precision. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 8612–8620 (2019)
2019
-
[30]
Wu, H., Jing, Y., Cheang, C., Chen, G., Xu, J., Li, X., Liu, M., Li, H., Kong, T.: Unleashing large-scale video generative pre-training for visual robot manipulation. In: Int. Conf. Learn. Represent. (2024)
2024
-
[31]
Wu, Y., Wang, H., Chen, Z., Pang, J., Xu, D.: On-device diffusion transformer policy for efficient robot manipulation. In: Int. Conf. Comput. Vis. pp. 14073– 14083 (2025)
2025
-
[32]
Xiao,G.,Lin,J.,Seznec,M.,Wu,H.,Demouth,J.,Han,S.:Smoothquant:Accurate and efficient post-training quantization for large language models. In: Int. Conf. Machine Learning. pp. 38087–38099. PMLR (2023)
2023
-
[33]
In: Robotics Science and Systems
Xue, H., Ren, J., Chen, W., Zhang, G., Fang, Y., Gu, G., Xu, H., Lu, C.: Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipula- tion. In: Robotics Science and Systems. Robotics: Science and Systems Foundation (2025)
2025
-
[34]
In: Annual Meeting Assoc
Yi, K., Xu, Y., Chang, H., Meng, Y., Zhang, T., Li, J.: One quantllm for all: Fine- tuning quantized llms once for efficient deployments. In: Annual Meeting Assoc. Comput. Linguistics. pp. 23057–23066 (2025)
2025
-
[35]
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. In: Int. Conf. Comput. Vis. pp. 11975–11986 (2023)
2023
-
[36]
In: Conf
Zitkovich,B.,Yu,T.,Xu,S.,Xu,P.,Xiao,T.,Xia,F.,Wu,J.,Wohlhart,P.,Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conf. Robot. Learn. pp. 2165–2183. PMLR (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.