Recognition: unknown
Tessera: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation
Pith reviewed 2026-05-10 15:47 UTC · model grok-4.3
The pith
Tessera disaggregates large-model inference at the kernel level to match heterogeneous GPU strengths more effectively than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tessera performs the first kernel-granularity disaggregation for large-model inference across heterogeneous GPUs. Offline PTX analysis yields precise inter-kernel dependencies that guarantee correctness; a pipelined execution model overlaps data movement with kernel execution; and a workload-aware scheduler with lightweight adaptation chooses which GPU type runs each kernel at each step. Across evaluated configurations the approach improves serving throughput by up to 2.3 times and cost efficiency by up to 1.6 times relative to existing disaggregation baselines, generalizes to model families unsupported by prior work, and allows certain heterogeneous GPU pairs to surpass the throughput of a
What carries the argument
Kernel-granularity disaggregation driven by PTX-derived dependency graphs, pipelined cross-GPU execution, and adaptive workload scheduling.
If this is right
- Certain mixed-GPU pairs under Tessera exceed the throughput of two identical high-end GPUs while using cheaper hardware.
- The technique applies to model architectures that previous disaggregation systems cannot support.
- Serving throughput rises by up to 2.3 times and cost efficiency by up to 1.6 times versus existing disaggregation methods.
- The same mechanisms scale to clusters containing up to 16 GPUs drawn from five distinct GPU models.
Where Pith is reading between the lines
- Data-center operators could deliberately purchase more varied GPU mixes if software reliably maps kernels across them, potentially lowering total acquisition cost.
- The PTX-analysis step suggests analogous low-level dependency extraction could be applied to other accelerator instruction sets for portable heterogeneous scheduling.
- Training workloads might benefit from the same kernel-level split if dependency graphs can be maintained across gradient and optimizer steps.
Load-bearing premise
Kernels inside one application have sufficiently varied resource demands that splitting at this level aligns work with different GPU types, and PTX analysis can recover the necessary dependencies accurately enough for safe pipelining without prohibitive overhead.
What would settle it
Measure end-to-end serving throughput and cost on the same heterogeneous GPU pairs when the system is forced to fall back to model-level or layer-level assignment; if the gains disappear or reverse, the kernel-granularity premise does not hold.
Figures






read the original abstract
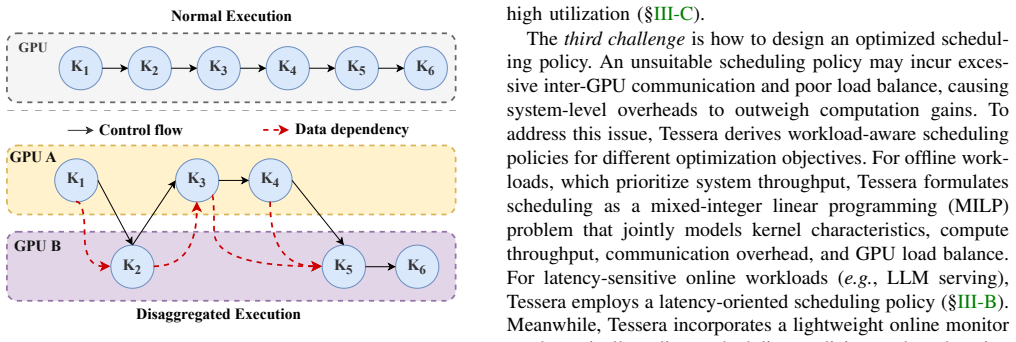
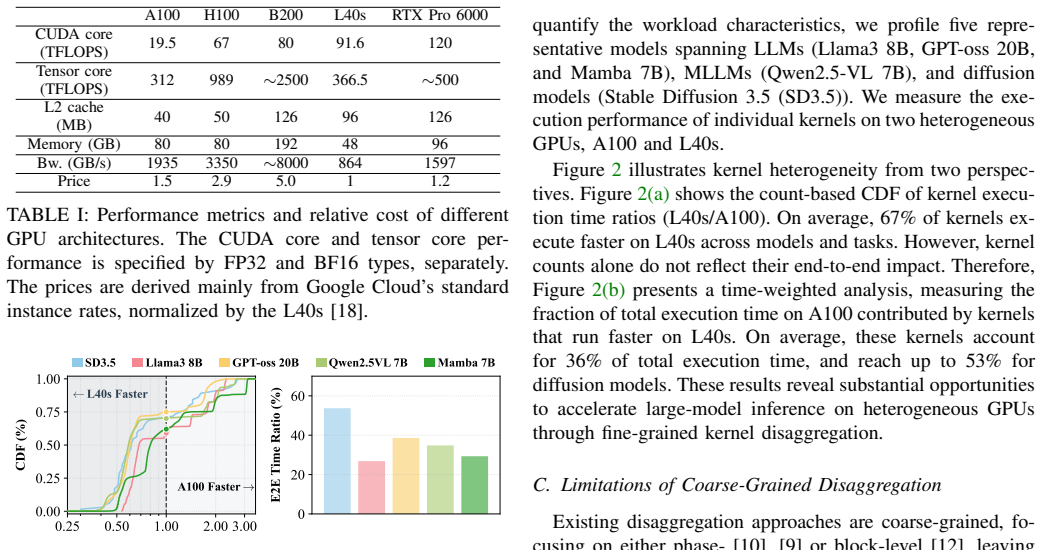
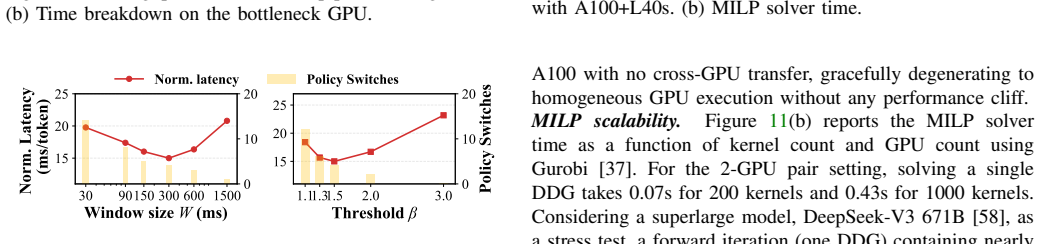
Disaggregation maps parts of an AI workload to different types of GPUs, offering a path to utilize modern heterogeneous GPU clusters. However, existing solutions operate at a coarse granularity and are tightly coupled to specific model architectures, leaving much room for performance improvement. This paper presents Tessera, the first kernel disaggregation system to improve performance and cost efficiency on heterogeneous GPUs for large model inference. Our key insight is that kernels within a single application exhibit diverse resource demands, making them the most suitable granularity for aligning computation with hardware capabilities. Tessera integrates offline analysis with online adaptation by extracting precise inter-kernel dependencies from PTX to ensure correctness, overlapping communication with computation through a pipelined execution model, and employing workload-aware scheduling with lightweight runtime adaptation. Extensive evaluations across five heterogeneous GPUs and four model architectures, scaling up to 16 GPUs, show that Tessera improves serving throughput and cost efficiency by up to 2.3x and 1.6x, respectively, compared to existing disaggregation methods, while generalizing to model architectures where prior approaches do not apply. Surprisingly, a heterogeneous GPU pair under Tessera can even exceed the throughput of two homogeneous high-end GPUs at a lower cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. Tessera is a kernel-granularity disaggregation system for large-model inference on heterogeneous GPU clusters. It performs offline PTX analysis to extract inter-kernel dependencies, employs a pipelined execution model that overlaps communication with computation, and uses workload-aware scheduling with lightweight runtime adaptation. The system is evaluated on up to 16 GPUs across five heterogeneous GPU types and four model architectures, reporting up to 2.3× serving throughput and 1.6× cost-efficiency gains over existing disaggregation methods while generalizing to architectures unsupported by prior work; a heterogeneous GPU pair can even exceed the throughput of two homogeneous high-end GPUs at lower cost.
Significance. If the PTX-based dependency model and pipelined scheduling deliver the claimed correctness and overlap, Tessera would meaningfully advance utilization of heterogeneous GPU hardware for inference workloads, with broad applicability beyond architecture-specific prior art. The scale of the evaluation (multiple GPU types, model families, and cluster sizes) and the counter-intuitive result that heterogeneous pairs can outperform homogeneous high-end pairs constitute concrete strengths that would be valuable to the systems community.
major comments (2)
- [§4.2] §4.2 (PTX Dependency Extraction): The central correctness and performance argument rests on the claim that static PTX analysis produces a precise inter-kernel dependency graph sufficient for safe pipelined disaggregation. The manuscript does not describe how the analysis handles dynamic allocations, CUDA runtime decisions, or calls into vendor libraries (cuBLAS, cuDNN), which are common sources of hidden dependencies. If the graph is incomplete, the runtime must either insert extra synchronizations (reducing overlap and undermining the 2.3× throughput numbers) or risk incorrect execution.
- [§5] §5 (Evaluation Methodology): The reported 2.3× throughput and 1.6× cost gains are load-bearing for the paper’s contribution, yet the evaluation section provides insufficient detail on baseline implementations, whether they were re-tuned for the heterogeneous setting, and the presence of error bars or statistical significance across runs. Without these, it is impossible to determine whether the gains are attributable to kernel-granularity disaggregation or to differences in experimental setup.
minor comments (2)
- [Abstract] The abstract states that Tessera “ensures correctness,” but the manuscript should explicitly list the assumptions under which the PTX analysis is sound (e.g., absence of certain CUDA features) so readers can assess the scope of the guarantee.
- [Figures 6–9] Figure captions and axis labels in the performance plots should include the exact GPU models and batch sizes used for each data point to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [§4.2] §4.2 (PTX Dependency Extraction): The central correctness and performance argument rests on the claim that static PTX analysis produces a precise inter-kernel dependency graph sufficient for safe pipelined disaggregation. The manuscript does not describe how the analysis handles dynamic allocations, CUDA runtime decisions, or calls into vendor libraries (cuBLAS, cuDNN), which are common sources of hidden dependencies. If the graph is incomplete, the runtime must either insert extra synchronizations (reducing overlap and undermining the 2.3× throughput numbers) or risk incorrect execution.
Authors: We agree that §4.2 would benefit from explicit discussion of these cases to strengthen the correctness argument. The offline PTX analysis constructs the dependency graph from kernel launches, memory operations, and control flow, with conservative edges added for uncertain cases. We will revise the section to describe how dynamic allocations are handled via over-approximation of subsequent accesses, how CUDA runtime decisions are approximated statically, and how vendor library calls (cuBLAS, cuDNN) are modeled as atomic units using their API tensor signatures. The runtime adaptation layer includes lightweight verification to insert minimal barriers only when needed. These additions will clarify that the reported overlap and throughput gains remain valid under the extended handling. revision: yes
-
Referee: [§5] §5 (Evaluation Methodology): The reported 2.3× throughput and 1.6× cost gains are load-bearing for the paper’s contribution, yet the evaluation section provides insufficient detail on baseline implementations, whether they were re-tuned for the heterogeneous setting, and the presence of error bars or statistical significance across runs. Without these, it is impossible to determine whether the gains are attributable to kernel-granularity disaggregation or to differences in experimental setup.
Authors: We concur that more methodological transparency is required. We will expand §5 with a dedicated subsection detailing each baseline implementation, including how prior disaggregation methods were re-implemented and tuned specifically for heterogeneous GPU configurations (e.g., adjusting placement and communication parameters). We will also report all throughput and cost results with error bars derived from multiple independent runs and include statistical significance testing to confirm that the observed improvements are attributable to Tessera’s kernel-granularity approach rather than setup variations. revision: yes
Circularity Check
No circularity: empirical systems implementation and evaluation
full rationale
This is an empirical systems paper describing an implemented kernel-disaggregation runtime with offline PTX analysis, pipelined execution, and workload-aware scheduling. All performance claims (2.3x throughput, 1.6x cost efficiency) are grounded in direct measurements across five GPU types, four model architectures, and up to 16 GPUs. No equations, fitted parameters, uniqueness theorems, or self-citations are used to derive results; the central argument is that the described mechanisms produce the observed speedups, which are independently verifiable by re-running the experiments. No step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Kernels within a single application exhibit diverse resource demands making them the most suitable granularity for aligning computation with hardware capabilities
- domain assumption Precise inter-kernel dependencies can be extracted from PTX to ensure correctness
Reference graph
Works this paper leans on
-
[1]
Ppipe: efficient video analytics serving on heterogeneous GPU clusters via pool-based pipeline parallelism,
Z. J. Kong, Q. Xu, and Y . C. Hu, “Ppipe: efficient video analytics serving on heterogeneous GPU clusters via pool-based pipeline parallelism,” inProceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC 25). [Online]. Available: https://www.usenix.org/conference/atc25/presentation/kong
2025
-
[2]
Rearchitecting Datacenter Lifecycle for AI: A TCO-Driven Framework,
J. Stojkovic, C. Zhang, ´I. Goiri, and R. Bianchini, “Rearchitecting Datacenter Lifecycle for AI: A TCO-Driven Framework,”arXiv preprint arXiv:2509.26534, 20025. [Online]. Available: https://arxiv.org/abs/25 09.26534
-
[3]
Compute Engine,
“Compute Engine,” https://cloud.google.com/compute/docs/gpus, 2025
2025
-
[4]
How Amazon Achieved Rocketing Sales and Growth From AI,
K. Wheeler, “How Amazon Achieved Rocketing Sales and Growth From AI,” https://aimagazine.com/news/how-amazonachieved-rocketing-sales -and-growth-from-ai, 2025
2025
-
[5]
60+ ChatGPT Statistics And Facts You Need to Know in 2024,
L. Marina, “60+ ChatGPT Statistics And Facts You Need to Know in 2024,” https://invgate.com/blog/chatgpt-statistics/, 2024
2024
-
[6]
J. Kim, B. Shin, J. Chung, and M. Rhu, “The cost of dynamic reasoning: Demystifying ai agents and test-time scaling from an ai infrastructure perspective.” [Online]. Available: https://arxiv.org/abs/2506.04301
-
[7]
arXiv preprint arXiv:2502.13965 , year =
M. Luo, X. Shi, C. Cai, T. Zhang, J. Wong, Y . Wang, C. Wang, Y . Huang, Z. Chen, J. E. Gonzalez, and I. Stoica, “Autellix: An efficient serving engine for llm agents as general programs.” [Online]. Available: https://arxiv.org/abs/2502.13965
-
[8]
Cost-efficient large language model serving for multi-turn conversations with cachedattention,
B. Gao, Z. He, P. Sharma, Q. Kang, D. Jevdjic, J. Deng, X. Yang, Z. Yu, and P. Zuo, “Cost-efficient large language model serving for multi-turn conversations with cachedattention,” in Proceedings of the 2024 USENIX Conference on Usenix Annual Technical Conference (ATC 24), 2024. [Online]. Available: https: //www.usenix.org/conference/atc24/presentation/ga...
2024
-
[9]
Splitwise: Efficient generative llm inference using phase splitting
P. Patel, E. Choukse, C. Zhang, A. Shah, I. n. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative llm inference using phase splitting,” inProceedings of the 51st Annual International Symposium on Computer Architecture (ISCA 24). [Online]. Available: https://doi.org/10.1109/ISCA59077.2024.00019
-
[10]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). [Online]. Available: https://www.usenix.org/conference/osdi24/presentation/zhon g-yinmin
-
[11]
Cronus: Efficient LLM inference on Heterogeneous GPU Clusters via Partially Disaggregated Prefill,
Y . Liu, Q. Xu, and Y . C. Hu, “Cronus: Efficient LLM inference on Heterogeneous GPU Clusters via Partially Disaggregated Prefill,” arXiv preprint arXiv:2509.17357, 2025. [Online]. Available: https: //arxiv.org/abs/2509.17357
-
[12]
Megascale- Infer: Efficient Mixture-of-Experts Model Serving with Disaggregated Expert Parallelism,
R. Zhu, Z. Jiang, C. Jin, P. Wu, C. A. Stuardo, D. Wang, X. Zhang, H. Zhou, H. Wei, Y . Cheng, J. Xiao, X. Zhang, L. Liu, H. Lin, L.-W. Chang, J. Ye, X. Yu, X. Liu, X. Jin, and X. Liu, “Megascale- Infer: Efficient Mixture-of-Experts Model Serving with Disaggregated Expert Parallelism,” inProceedings of the 39th ACM Special Interest Group on Data Communica...
-
[13]
B. Wang, B. Wang, C. Wan, G. Huang, H. Huet al., “Step-3 is large yet affordable: Model-system co-design for cost-effective decoding,”arXiv preprint arXiv:2507.19427, 2025. [Online]. Available: https://arxiv.org/abs/2507.19427
-
[15]
NVIDIA. Parallel thread execution isa version 9.00ptx,
“NVIDIA. Parallel thread execution isa version 9.00ptx,” https://docs.n vidia.com/cuda/parallel-thread-execution/index.html, 2025
2025
-
[16]
Efficient memory management for large language model serving with pagedattention
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles (SOSP 23), 2023. [Online]. Available: https://doi.org/10.1145/3600006.3613165
-
[17]
PyTorch,
“PyTorch,” https://github.com/pytorch/pytorch, 2026
2026
-
[18]
Google cloud. virtual machines pricing,
“Google cloud. virtual machines pricing,” https://cloud.google.com/pro ducts/compute/pricing/accelerator-optimized, 2026
2026
-
[19]
NVIDIA MGX,
“NVIDIA MGX,” https://www.nvidia.com/en-us/data-center/products/m gx/, 2026
2026
-
[20]
Supermicro MGX Systems,
“Supermicro MGX Systems,” https://www.supermicro.com/zh cn/acce lerators/nvidia/mgx, 2026
2026
-
[21]
GIGABYTE MGX Server,
“GIGABYTE MGX Server,” https://www.gigabyte.com/Enterprise/MG X-Server, 2026
2026
-
[22]
Open sycl on heterogeneous gpu systems: A case of study,
R. Carratal ´a-S´aez, F. J. and ´ujar, Y . Torres, A. Gonzalez-Escribano, and D. R. Llanos, “Open sycl on heterogeneous gpu systems: A case of study,”arXiv preprint arXiv:2310.06947, 2023. [Online]. Available: https://arxiv.org/abs/2310.06947
-
[23]
Beyond hardware: Building the software foundation for hetero- geneous gpu,
J. Liu, “Beyond hardware: Building the software foundation for hetero- geneous gpu,” Blog post, 2025, https://seclee.com/post/202510 hmc/
2025
-
[24]
Basic Linear Algebra on NVIDIA Gpus,
“Basic Linear Algebra on NVIDIA Gpus,” https://developer.nvidia.com /cublas, 2025
2025
-
[25]
Roofline: an insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: an insightful visual performance model for multicore architectures,”Commun. ACM,
-
[26]
Roofline: An in- sightful visual performance model for multicore architectures,
[Online]. Available: https://doi.org/10.1145/1498765.1498785
-
[27]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”arXiv preprint arXiv:2205.14135, 2022. [Online]. Available: https://doi.org/10.1145/ 1498765.1498785
work page internal anchor Pith review arXiv 2022
-
[28]
Aegaeon: Effective gpu pooling for concurrent llm serving on the market
W. Xingda, H. Zhuobin, S. Tianle, H. Yingyi, C. Rong, H. Mingcong, G. Jinyu, and C. Haibo, “Phoenixos: Concurrent OS-level gpu checkpoint and restore with validated speculation,” inProceedings of the ACM SIGOPS 31th Symposium on Operating Systems Principles (SOSP 25). [Online]. Available: https://doi.org/10.1145/3731569.3764813
-
[29]
PyTorch THCCachingAllocator,
“PyTorch THCCachingAllocator,” https://github.com/torch/cutorch/blo b/master/lib/THC/THCCachingAllocator.cpp, 2026
2026
-
[30]
Neutrino: fine-grained gpu kernel profiling via programmable probing,
S. Huang and C. Wu, “Neutrino: fine-grained gpu kernel profiling via programmable probing,” inProceedings of the 19th USENIX Conference on Operating Systems Design and Implementation (OSDI 25). [Online]. Available: https://www.usenix.org/conference/osdi25/pre sentation/huang-songlin
-
[31]
Extending applications safely and efficiently,
Y . Zheng, T. Yu, Y . Yang, Y . Hu, X. Lai, D. Williams, and A. Quinn, “Extending applications safely and efficiently,” inProceedings of the 19th USENIX Conference on Operating Systems Design and Implementation (OSDI 25). [Online]. Available: https://www.usenix.org /conference/osdi25/presentation/zheng-yusheng
-
[32]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,”arXiv preprint arXiv:1706.03762, 2023. [Online]. Available: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
NVIDIA tensorRT,
NVIDIA, “NVIDIA tensorRT,” https://developer.nvidia.com/tensorrt, 2025
2025
-
[34]
Graph Management,
“Graph Management,” https://docs.nvidia.com/cuda/cuda-runtime-api/g roup CUDART GRAPH.html, 2025
2025
-
[35]
CUDA Graph Best Practice for PyTorch,
“CUDA Graph Best Practice for PyTorch,” https://docs.nvidia.com/dl -cuda-graph/latest/torch-cuda-graph/handling-dynamic-patterns.html, 2026
2026
-
[36]
G. L. Nemhauser and L. A. Wolsey,Integer and combinatorial opti- mization. Wiley New York, 1988
1988
-
[37]
Pipedream: generalized pipeline parallelism for dnn training,
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia, “Pipedream: generalized pipeline parallelism for dnn training,” inProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP 19). [Online]. Available: https://doi.org/10.1145/3341301.3359646 11
-
[38]
Gurobi Optimizer,
“Gurobi Optimizer,” https://www.gurobi.com/, 2026
2026
-
[39]
Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect,
“Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect,” https://developer.nvidia .com/blog/improving-network-performance-of-hpc-systems-using-nvi dia-magnum-io-nvshmem-and-gpudirect-async/, 2022
2022
-
[40]
“NCCL,” https://github.com/NVIDIA/nccl, 2026
2026
-
[41]
CUDA Runtime API:GPU Stream Management,
“CUDA Runtime API:GPU Stream Management,” https://docs.nvidia. com/cuda/cuda-runtime-api/group CUDART STREAM.html#group CUDART STREAM, 2022
2022
-
[42]
NVIDIA PTXAS,
“NVIDIA PTXAS,” https://docs.nvidia.com/cuda/cuda-compiler-drive r-nvcc/, 2024
2024
-
[43]
Rodinia: A benchmark suite for heterogeneous computing
S. Che, M. Boyer, J. Meng, D. Tarjan, J. Sheaffer, S.-H. Lee, and K. Skadron, “Rodinia: A benchmark suite for heterogeneous computing.” [Online]. Available: https://doi.org/10.1109/IISWC.2009.5306797
-
[44]
CUDA Programming Guide CUDA Graphs,
“CUDA Programming Guide CUDA Graphs,” https://docs.nvidia.com/ cuda/cuda-programming-guide/04-special-topics/cuda-graphs.html#, 2025
2025
-
[45]
NCCL Communicator Quality of Service,
“NCCL Communicator Quality of Service,” https://docs.nvidia.com/de eplearning/nccl/user-guide/docs/usage/communicators.html, 2026
2026
-
[46]
Meta Llama 3,
“Meta Llama 3,” https://llama.meta.com/llama3, 2024
2024
-
[47]
gpt-oss-120b & gpt-oss-20b Model Card
O. . S. Agarwal, L. Ahmad, J. Ai, and e. Sam Altman, “gpt- oss-120b and gpt-oss-20b Model Card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Mamba-Codestral-7B-v0.1,
“Mamba-Codestral-7B-v0.1,” https://huggingface.co/mistralai/Mamba -Codestral-7B-v0.1, 2025
2025
-
[49]
Qwen2.5-VL,
Q. Team, “Qwen2.5-VL,” https://qwenlm.github.io/blog/qwen2.5-vl/, January 2025
2025
-
[50]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey, A. Goodwin, Y . Marek, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” 2024. [Online]. Available: https://arxiv.org/abs/2403.03206
work page internal anchor Pith review arXiv 2024
-
[51]
Stable diffusion 3.5 medium,
Stability AI, “Stable diffusion 3.5 medium,” https://huggingface.co/sta bilityai/stable-diffusion-3.5-medium, 2024
2024
-
[52]
Microsoft COCO Captions: Data Collection and Evaluation Server
X. Chen, H. Fang, T.-Y . Lin, R. Vedantam, S. Gupta, P. Dollar, and C. L. Zitnick, “Microsoft coco captions: Data collection and evaluation server,” 2015. [Online]. Available: https://arxiv.org/abs/1504.00325
work page internal anchor Pith review arXiv 2015
-
[53]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
J. Yu, Y . Xu, J. Y . Koh, T. Luong, G. Baid, Z. Wang, V . Vasudevan, A. Ku, Y . Yang, B. K. Ayan, B. Hutchinson, W. Han, Z. Parekh, X. Li, H. Zhang, J. Baldridge, and Y . Wu, “Scaling autoregressive models for content-rich text-to-image generation,” 2022. [Online]. Available: https://arxiv.org/abs/2206.10789
work page internal anchor Pith review arXiv 2022
-
[54]
Nanoflow: towards optimal large language model serving throughput,
K. Zhu, Y . Gao, Y . Zhao, L. Zhao, G. Zuo, Y . Gu, D. Xie, T. Tang, Q. Xu, Z. Ye, K. Kamahori, C.-Y . Lin, Z. Wang, S. Wang, A. Krishnamurthy, and B. Kasikci, “Nanoflow: towards optimal large language model serving throughput,” inProceedings of the 19th USENIX Conference on Operating Systems Design and Implementation (OSDI 25). [Online]. Available: https...
-
[55]
Helix: Serving large language models over heterogeneous gpus and network via max-flow,
Y . Mei, Y . Zhuang, X. Miao, J. Yang, Z. Jia, and R. Vinayak, “Helix: Serving large language models over heterogeneous gpus and network via max-flow,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 25). [Online]. Available: https://doi.org/10.1145/3669940.3707215
-
[56]
Misa-akmc:achieve kinetic monte carlo simulation of 20 quadrillion atoms on gpu clusters,
Z. Mo, J. Liao, H. Xu, Z. Zhou, and C. Xu, “Hetis: Serving llms in heterogeneous gpu clusters with fine-grained and dynamic parallelism,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC 25). [Online]. Available: https://doi.org/10.1145/3712285.3759784
-
[57]
The impact of gpu dvfs on the energy and performance of deep learning: an empirical study,
Z. Tang, Y . Wang, Q. Wang, and X. Chu, “The impact of gpu dvfs on the energy and performance of deep learning: an empirical study,” inProceedings of the Tenth ACM International Conference on Future Energy Systems, 2019. [Online]. Available: https://doi.org/10.1145/3307772.3328315
-
[58]
A. Yanget al., “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
DeepSeek-AI and etc., “Deepseek-v3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Hexgen-2: Disaggregated generative inference of llms in heterogeneous environment,
Y . Jiang, R. Yan, and B. Yuan, “Hexgen-2: Disaggregated generative inference of llms in heterogeneous environment,” 2025. [Online]. Available: https://arxiv.org/abs/2502.07903
-
[61]
Sailor: Automating Distributed Training over Dynamic, Heterogeneous, and Geo-distributed Clusters,
F. Strati, Z. Zhang, G. Manos, I. S. P ´eriz, Q. Hu, T. Chen, B. Buzcu, S. Han, P. Delgado, and A. Klimovic, “Sailor: Automating Distributed Training over Dynamic, Heterogeneous, and Geo-distributed Clusters,” inProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles (SOSP 25). [Online]. Available: https://dl.acm.org/doi/10.1145/37315...
-
[62]
Metis: Fast Automatic Distributed Training on Heterogeneous GPUs,
T. Um, B. Oh, M. Kang, W.-Y . Lee, G. Kim, D. Kim, Y . Kim, M. Muzzammil, and M. Jeon, “Metis: Fast Automatic Distributed Training on Heterogeneous GPUs,” in2024 USENIX Annual Technical Conference (USENIX ATC 24). [Online]. Available: https: //www.usenix.org/conference/atc24/presentation/um 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.