Recognition: unknown
Wolkowicz-Styan Upper Bound on the Hessian Eigenspectrum for Cross-Entropy Loss in Nonlinear Smooth Neural Networks
Pith reviewed 2026-05-10 16:09 UTC · model grok-4.3
The pith
A closed-form upper bound exists on the largest Hessian eigenvalue of cross-entropy loss in smooth nonlinear multilayer neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
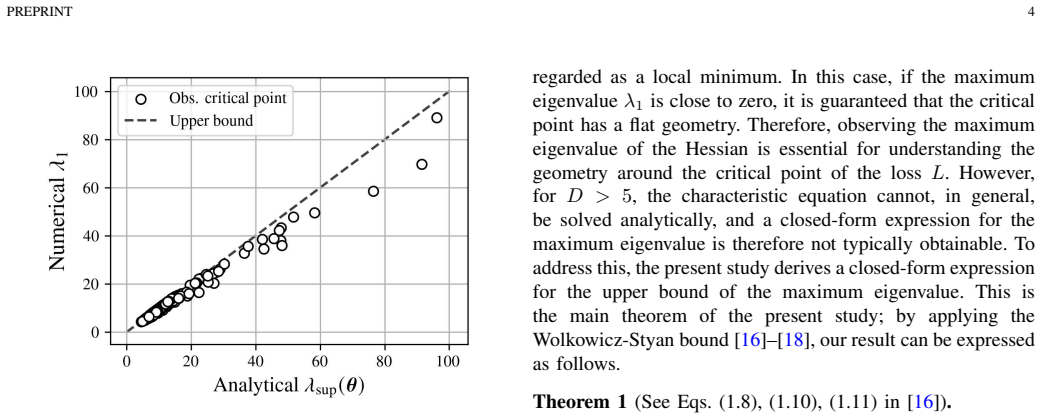
The authors demonstrate that the Wolkowicz-Styan bound yields a closed-form upper bound on the largest eigenvalue of the Hessian of the cross-entropy loss for nonlinear smooth multilayer neural networks. This bound is a function of the affine transformation parameters, the hidden layer dimensions, and the degree of orthogonality among the training samples. The result supplies an analytical characterization of loss sharpness at critical points without explicit numerical computation of the eigenspectrum.
What carries the argument
The Wolkowicz-Styan bound, an inequality that upper-bounds the largest eigenvalue of a matrix, applied directly to the Hessian of the cross-entropy loss.
Load-bearing premise
The Wolkowicz-Styan bound applies directly to the Hessian of the cross-entropy loss under the stated smoothness and multilayer architecture assumptions.
What would settle it
Numerically compute the true maximum eigenvalue of the Hessian for a small smooth nonlinear network such as a two-layer sigmoid model trained on a few samples, then check whether this value is always at most the closed-form bound given by the paper for the same parameters and orthogonality measure.
Figures








read the original abstract
Neural networks (NNs) are central to modern machine learning and achieve state-of-the-art results in many applications. However, the relationship between loss geometry and generalization is still not well understood. The local geometry of the loss function near a critical point is well-approximated by its quadratic form, obtained through a second-order Taylor expansion. The coefficients of the quadratic term correspond to the Hessian matrix, whose eigenspectrum allows us to evaluate the sharpness of the loss at the critical point. Extensive research suggests flat critical points generalize better, while sharp ones lead to higher generalization error. However, sharpness requires the Hessian eigenspectrum, but general matrix characteristic equations have no closed-form solution. Therefore, most existing studies on evaluating loss sharpness rely on numerical approximation methods. Existing closed-form analyses of the eigenspectrum are primarily limited to simplified architectures, such as linear or ReLU-activated networks; consequently, theoretical analysis of smooth nonlinear multilayer neural networks remains limited. Against this background, this study focuses on nonlinear, smooth multilayer neural networks and derives a closed-form upper bound for the maximum eigenvalue of the Hessian with respect to the cross-entropy loss by leveraging the Wolkowicz-Styan bound. Specifically, the derived upper bound is expressed as a function of the affine transformation parameters, hidden layer dimensions, and the degree of orthogonality among the training samples. The primary contribution of this paper is an analytical characterization of loss sharpness in smooth nonlinear multilayer neural networks via a closed-form expression, avoiding explicit numerical eigenspectrum computation. We hope that this work provides a small yet meaningful step toward unraveling the mysteries of deep learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a closed-form upper bound on the largest eigenvalue of the Hessian of the cross-entropy loss for smooth nonlinear multilayer neural networks by applying the Wolkowicz-Styan matrix inequality. The resulting expression depends on the affine transformation parameters, hidden-layer dimensions, and a measure of orthogonality among the training samples. The central claim is that this provides an analytical characterization of loss sharpness that avoids numerical eigenspectrum computation, extending beyond the linear or ReLU cases treated in prior work.
Significance. If the derivation is complete and the bound holds under the stated assumptions, the result would be a modest but useful contribution to the theoretical analysis of loss landscapes. Closed-form bounds on Hessian eigenvalues for general smooth activations are rare, and an explicit dependence on architecture and data orthogonality could support future work on sharpness and generalization. The approach of invoking a known trace/Frobenius-based inequality is appropriate in principle, though its practical value rests on whether the multilayer chain-rule structure can be controlled without extra assumptions.
major comments (2)
- [§3] §3 (main derivation): The application of the Wolkowicz-Styan bound to the full Hessian requires explicit intermediate steps showing that all cross-layer terms arising from the chain rule (Jacobians of activations and second-derivative blocks) are dominated by a matrix whose spectrum depends only on the claimed quantities. No such domination argument is supplied, leaving open whether the bound remains free of dependence on activation derivatives evaluated at the critical point.
- [Assumptions paragraph preceding Eq. (bound)] Assumptions paragraph preceding Eq. (bound): The smoothness and multilayer architecture assumptions are listed, but it is not shown that the Wolkowicz-Styan inequality applies directly to the composite Hessian without additional restrictions (e.g., bounded activation Hessians or a neighborhood around the critical point). This is load-bearing for the closed-form claim.
minor comments (2)
- [Notation section] The precise definition of the 'degree of orthogonality' among samples should be given as an explicit equation or norm rather than left as a descriptive phrase.
- [Introduction] A brief comparison table or remark contrasting the new bound with existing closed-form results for linear networks would improve context.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address the major comments point by point below, indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3] §3 (main derivation): The application of the Wolkowicz-Styan bound to the full Hessian requires explicit intermediate steps showing that all cross-layer terms arising from the chain rule (Jacobians of activations and second-derivative blocks) are dominated by a matrix whose spectrum depends only on the claimed quantities. No such domination argument is supplied, leaving open whether the bound remains free of dependence on activation derivatives evaluated at the critical point.
Authors: We agree that the original derivation in Section 3 would be strengthened by additional explicit steps. In the revised manuscript we will insert a detailed expansion of the chain-rule expansion of the Hessian, followed by term-by-term application of the smoothness assumptions to bound the cross-layer Jacobians and second-derivative blocks. Each bound will be shown to be dominated by a matrix whose eigenvalues depend only on the affine parameters, hidden-layer dimensions, and the training-sample orthogonality measure, thereby removing any residual dependence on the pointwise values of the activation derivatives. revision: yes
-
Referee: [Assumptions paragraph preceding Eq. (bound)] Assumptions paragraph preceding Eq. (bound): The smoothness and multilayer architecture assumptions are listed, but it is not shown that the Wolkowicz-Styan inequality applies directly to the composite Hessian without additional restrictions (e.g., bounded activation Hessians or a neighborhood around the critical point). This is load-bearing for the closed-form claim.
Authors: The referee correctly identifies that the direct applicability of the Wolkowicz-Styan inequality to the composite Hessian needs explicit justification. We will revise the assumptions paragraph to include a short lemma establishing that, under the stated smoothness and multilayer architecture conditions, the Hessian admits a decomposition to which the inequality applies globally; no auxiliary bounds on activation Hessians or localization to a neighborhood are required beyond the smoothness already assumed. revision: yes
Circularity Check
No circularity: external Wolkowicz-Styan bound applied to explicitly constructed Hessian
full rationale
The paper constructs the Hessian of cross-entropy loss via the chain rule for a smooth nonlinear multilayer network, then applies the known Wolkowicz-Styan matrix inequality (an external result from 1979) to bound its largest eigenvalue. The resulting closed-form expression depends on affine parameters, layer dimensions, and sample orthogonality because those quantities appear in the explicit Hessian blocks; this dependence is not smuggled in by definition or by renaming a fitted quantity. No self-citation is load-bearing for the central step, no ansatz is adopted via prior work of the same authors, and no prediction reduces to a fitted input by construction. The derivation remains self-contained against the external bound and the standard chain-rule expansion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
E. O. Arkhangelskaya, S. I. Nikolenko, Deep Learning for Natural Language Processing: A Survey, Journal of Mathematical Sciences 273 (4) (2023) 533–582.doi:10.1007/s10958-023-06519-6
-
[3]
A. Mehrish, N. Majumder, R. Bharadwaj, R. Mihalcea, S. Poria, A re- view of deep learning techniques for speech processing, Information Fu- sion 99 (2023) 101869.doi:10.1016/j.inffus.2023.101869
- [4]
-
[5]
X. Yue, M. Nouiehed, R. A. Kontar, SALR: Sharpness-aware Learning Rate Scheduler for Improved Generalization, IEEE Transactions on Neural Networks and Learning Systems 35 (9) (2024) 12518–12527. arXiv:2011.05348,doi:10.1109/TNNLS.2023.3263393
-
[6]
S. Hochreiter, J. Schmidhuber, Flat minima, Neural Computation 9 (1) (1997) 1–42.doi:10.1162/neco.1997.9.1.1
-
[7]
Y . Liu, S. Yu, T. Lin, Hessian regularization of deep neural networks: A novel approach based on stochastic estimators of Hessian trace, Neurocomputing 536 (2023) 13–20.doi:10.1016/j.neucom. 2023.03.017
-
[8]
S. Arora, Z. Li, A. Panigrahi, Understanding Gradient Descent on Edge of Stability in Deep Learning (2022).arXiv:2205.09745,doi: 10.48550/arXiv.2205.09745
-
[9]
K. Lyu, Z. Li, S. Arora, Understanding the Generalization Benefit of Normalization Layers: Sharpness Reduction (2023).arXiv:2206. 07085,doi:10.48550/arXiv.2206.07085
-
[10]
C. Lanczos, An iteration method for the solution of the eigenvalue problem of linear differential and integral operators, Journal of Research of the National Bureau of Standards 45 (4) (1950) 255–282
1950
-
[11]
M. Hutchinson, A Stochastic Estimator of the Trace of the Influence Matrix for Laplacian Smoothing Splines, Communications in Statistics - Simulation and Computation 18 (3) (1989) 1059–1076.doi:10. 1080/03610918908812806
1989
- [12]
-
[13]
Ghorbani, S
B. Ghorbani, S. Krishnan, Y . Xiao, An Investigation into Neural Net Optimization via Hessian Eigenvalue Density, Proceedings of the 36th International Conference on Machine Learning (2019) 2232–2241
2019
-
[14]
Z. Dong, Z. Yao, D. Arfeen, A. Gholami, M. W. Mahoney, K. Keutzer, HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Net- works, Advances in Neural Information Processing Systems 33 (2020) 18518–18529
2020
-
[15]
S. P. Singh, W. Ormaniec, T. Hofmann, Cracking the Hessian: Closed- Form Hessian Spectra for Fundamental Neural Networks, OpenReview in ICLR2026 (2026)
2026
-
[16]
Wolkowicz, G
H. Wolkowicz, G. P. H. Styan, Bounds for eigenvalues using traces, Linear Algebra and its Applications 29 (1980) 471–506.doi:10. 1016/0024-3795(80)90258-X
1980
-
[17]
J. K. Merikoski, A. Virtanen, Bounds for eigenvalues using the trace and determinant, Linear Algebra and its Applications 264 (1997) 101–108. doi:10.1016/S0024-3795(97)00067-0. PREPRINT 19
-
[18]
J. K. Merikoski, A. Virtanen, Best possible bounds for ordered positive numbers using their sum and product, Mathematical Inequalities & Applications 4 (1) (2001) 67–84
2001
-
[19]
R. Sharma, R. Kumar, R. Saini, Note on Bounds for Eigenvalues us- ing Traces (2014).arXiv:1409.0096,doi:10.48550/arXiv. 1409.0096
work page internal anchor Pith review doi:10.48550/arxiv 2014
-
[20]
A. A. Minai, R. D. Williams, On the derivatives of the sigmoid, Neural Networks 6 (6) (1993) 845–853.doi:10.1016/S0893-6080(05) 80129-7
-
[21]
Goodfellow, Y
I. Goodfellow, Y . Bengio, A. Courville, Deep Learning, MIT Press (2016)
2016
-
[22]
Berzal, DL101 Neural Network Outputs and Loss Functions (2025)
F. Berzal, DL101 Neural Network Outputs and Loss Functions (2025). arXiv:2511.05131,doi:10.48550/arXiv.2511.05131
-
[23]
Gaussian Error Linear Units (GELUs)
D. Hendrycks, K. Gimpel, Gaussian Error Linear Units (GELUs) (2016). doi:10.48550/arXiv.1606.08415
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.08415 2016
-
[24]
H. Li, Z. Xu, G. Taylor, C. Studer, T. Goldstein, Visualizing the Loss Landscape of Neural Nets, Advances in Neural Information Processing Systems 31 (2018)
2018
-
[25]
M. Wei, D. J. Schwab, How noise affects the Hessian spectrum in overparameterized neural networks (2019).arXiv:1910.00195, doi:10.48550/arXiv.1910.00195
-
[26]
L. Wu, W. J. Su, The Implicit Regularization of Dynamical Stability in Stochastic Gradient Descent (2023).arXiv:2305.17490,doi: 10.48550/arXiv.2305.17490
-
[27]
P. Marion, L. Chizat, Deep linear networks for regression are implicitly regularized towards flat minima (2024).arXiv:2405.13456,doi: 10.48550/arXiv.2405.13456
-
[28]
Damian, T
A. Damian, T. Ma, J. D. Lee, Label Noise SGD Provably Prefers Flat Global Minimizers, in: Advances in Neural Information Processing Systems, V ol. 34, Curran Associates, Inc., 2021, pp. 27449–27461
2021
-
[29]
H. Liu, S. M. Xie, Z. Li, T. Ma, Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models, Proceedings of the 40th International Conference on Machine Learning (2023) 22188–22214
2023
-
[30]
A. R. Sankar, Y . Khasbage, R. Vigneswaran, V . N Balasubrama- nian, A Deeper Look at the Hessian Eigenspectrum of Deep Neural Networks and its Applications to Regularization, Proceedings of the AAAI Conference on Artificial Intelligence 35 (11) (2021) 9481–9488. doi:10.1609/aaai.v35i11.17142
-
[31]
M. Bolshim, A. Kugaevskikh, Local properties of neural networks through the lens of layer-wise Hessians (2025).arXiv:2510.17486, doi:10.48550/arXiv.2510.17486
-
[32]
H. R. Zhang, D. Li, H. Ju, Noise Stability Optimization for Finding Flat Minima: A Hessian-based Regularization Approach (2024).arXiv: 2306.08553,doi:10.48550/arXiv.2306.08553
-
[33]
Y . Zhou, Y . Li, L. Feng, S.-J. Huang, Improving generalization of deep neural networks by optimum shifting, Proceedings of the Thirty- Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence 39 (2025) 10...
-
[34]
H. Luo, T. Truong, T. Pham, M. Harandi, D. Phung, T. Le, Explicit Eigenvalue Regularization Improves Sharpness-Aware Minimization (2025).arXiv:2501.12666,doi:10.48550/arXiv.2501. 12666
-
[35]
Bishop, Exact Calculation of the Hessian Matrix for the Multilayer Perceptron, Neural Computation 4 (4) (1992) 494–501.doi:10
C. Bishop, Exact Calculation of the Hessian Matrix for the Multilayer Perceptron, Neural Computation 4 (4) (1992) 494–501.doi:10. 1162/neco.1992.4.4.494
1992
-
[36]
P. Foret, A. Kleiner, H. Mobahi, B. Neyshabur, Sharpness-Aware Min- imization for Efficiently Improving Generalization (2021).arXiv: 2010.01412,doi:10.48550/arXiv.2010.01412
-
[37]
J. Kwon, J. Kim, H. Park, I. K. Choi, ASAM: Adaptive Sharpness-Aware Minimization for Scale-Invariant Learning of Deep Neural Networks, Proceedings of the 38th International Conference on Machine Learning (2021) 5905–5914
2021
-
[38]
Y . Zhou, Y . Qu, X. Xu, H. Shen, ImbSAM: A Closer Look at Sharpness- Aware Minimization in Class-Imbalanced Recognition, 2023 IEEE/CVF International Conference on Computer Vision (ICCV) (2023) 11311– 11321doi:10.1109/ICCV51070.2023.01042
-
[39]
Andriushchenko, N
M. Andriushchenko, N. Flammarion, Towards Understanding Sharpness- Aware Minimization, Proceedings of the 39th International Conference on Machine Learning (2022) 639–668
2022
-
[40]
X. Chen, C.-J. Hsieh, B. Gong, When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations (2022). arXiv:2106.01548,doi:10.48550/arXiv.2106.01548
-
[41]
W. Huang, X. Liu, X. Wang, J. Yamagishi, Y . Qian, From Sharpness to Better Generalization for Speech Deepfake Detection (2025).arXiv: 2506.11532,doi:10.48550/arXiv.2506.11532
-
[42]
S. P. Singh, G. Bachmann, T. Hofmann, Analytic Insights into Structure and Rank of Neural Network Hessian Maps (2021).arXiv:2106. 16225,doi:10.48550/arXiv.2106.16225
-
[43]
Suryadi, L. Y . Chew, Y .-S. Ong, Jacobian Granger causality for count and binary data with applications to causal network inference, Scientific Re- ports 16 (1) (2025) 3452.doi:10.1038/s41598-025-33385-w
-
[44]
J. S. Tyler, The Laguerre–Samuelson Inequality with Extensions and Ap- plications in Statistics and Matrix Theory, Department of Mathematics and Statistics, McGill University (1999)
1999
- [45]
-
[46]
Y . Wu, X. Zhu, C. Wu, A. Wang, R. Ge, Dissecting Hessian: Under- standing Common Structure of Hessian in Neural Networks (2022). arXiv:2010.04261,doi:10.48550/arXiv.2010.04261
-
[47]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
L. Sagun, L. Bottou, Y . LeCun, Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond (2017).arXiv:1611.07476, doi:10.48550/arXiv.1611.07476
-
[48]
On the power-law hessian spectrums in deep learning, 2022
Z. Xie, Q.-Y . Tang, Y . Cai, M. Sun, P. Li, On the Power-Law Hessian Spectrums in Deep Learning (2022).arXiv:2201.13011,doi: 10.48550/arXiv.2201.13011
-
[49]
Papyan, Traces of Class/Cross-Class Structure Pervade Deep Learning Spectra, Journal of Machine Learning Research 21 (2020)
V . Papyan, Traces of Class/Cross-Class Structure Pervade Deep Learning Spectra, Journal of Machine Learning Research 21 (2020)
2020
-
[50]
I. J. Goodfellow, O. Vinyals, A. M. Saxe, Qualitatively characterizing neural network optimization problems (2015).arXiv:1412.6544, doi:10.48550/arXiv.1412.6544
-
[51]
Abramowitz, I
M. Abramowitz, I. A. Stegun, Handbook of Mathematical Functions, Dover Publications (1965)
1965
-
[52]
K. B. Petersen, M. S. Pedersen, The Matrix Cookbook, Technical University of Denmark (2012)
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.