Recognition: unknown
A3-FPN: Asymptotic Content-Aware Pyramid Attention Network for Dense Visual Prediction
Pith reviewed 2026-05-10 16:55 UTC · model grok-4.3
The pith
A3-FPN augments feature pyramids with an asymptotically disentangled column network and content-aware attention to capture more discriminative multi-scale features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
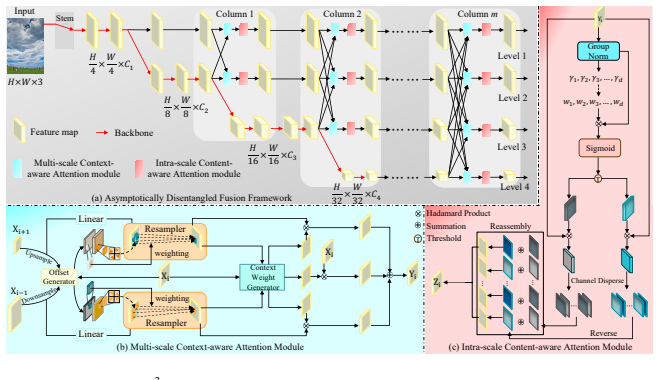
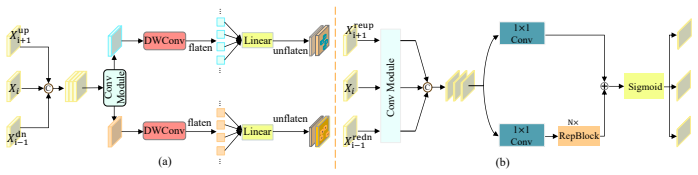
We propose A3-FPN to augment multi-scale feature representation via the asymptotically disentangled framework and content-aware attention modules. Specifically, A3-FPN employs a horizontally-spread column network that enables asymptotically global feature interaction and disentangles each level from all hierarchical representations. In feature fusion, it collects supplementary content from the adjacent level to generate position-wise offsets and weights for context-aware resampling, and learns deep context reweights to improve intra-category similarity. In feature reassembly, it further strengthens intra-scale discriminative feature learning and reassembles redundant features based on the信息,
What carries the argument
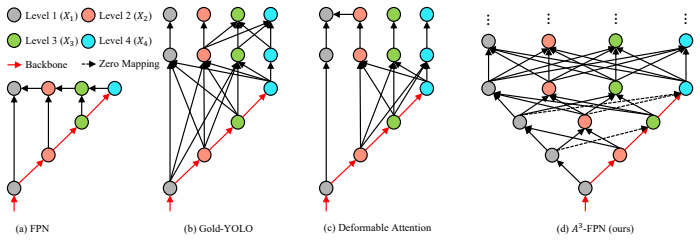
The horizontally-spread column network for asymptotic global interaction and level disentanglement, together with content-aware attention modules that generate offsets, weights, and reweights during feature fusion and reassembly.
If this is right
- A3-FPN integrates directly into existing CNN and transformer architectures for dense prediction tasks.
- It delivers measurable gains on MS COCO, VisDrone2019-DET, and Cityscapes.
- Paired with OneFormer and Swin-L it reaches 49.6 mask AP on MS COCO.
- The same pairing reaches 85.6 mIoU on Cityscapes.
Where Pith is reading between the lines
- The reassembly step that prunes features by information content could reduce memory use when scaling the same idea to higher-resolution inputs.
- The horizontal column structure may transfer to video or 3D dense prediction where scale varies over time or depth.
- If the disentanglement step proves essential, future work could isolate its contribution by ablating only that component across more backbones.
Load-bearing premise
The asymptotic disentanglement and content-aware modules truly improve feature discriminability across scales rather than merely adding parameters that fit the training distributions of the tested benchmarks.
What would settle it
Inserting A3-FPN into a standard backbone on a fresh dense-prediction dataset and measuring no accuracy gain or a drop relative to the original feature pyramid network would show the claimed benefits do not generalize.
Figures






read the original abstract
Learning multi-scale representations is the common strategy to tackle object scale variation in dense prediction tasks. Although existing feature pyramid networks have greatly advanced visual recognition, inherent design defects inhibit them from capturing discriminative features and recognizing small objects. In this work, we propose Asymptotic Content-Aware Pyramid Attention Network (A3-FPN), to augment multi-scale feature representation via the asymptotically disentangled framework and content-aware attention modules. Specifically, A3-FPN employs a horizontally-spread column network that enables asymptotically global feature interaction and disentangles each level from all hierarchical representations. In feature fusion, it collects supplementary content from the adjacent level to generate position-wise offsets and weights for context-aware resampling, and learns deep context reweights to improve intra-category similarity. In feature reassembly, it further strengthens intra-scale discriminative feature learning and reassembles redundant features based on information content and spatial variation of feature maps. Extensive experiments on MS COCO, VisDrone2019-DET and Cityscapes demonstrate that A3-FPN can be easily integrated into state-of-the-art CNN and Transformer-based architectures, yielding remarkable performance gains. Notably, when paired with OneFormer and Swin-L backbone, A3-FPN achieves 49.6 mask AP on MS COCO and 85.6 mIoU on Cityscapes. Codes are available at https://github.com/mason-ching/A3-FPN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Asymptotic Content-Aware Pyramid Attention Network (A3-FPN) to improve multi-scale feature representation in dense visual prediction tasks. It introduces a horizontally-spread column network for asymptotically global feature interaction and disentanglement, along with content-aware attention modules for position-wise resampling using offsets and weights, and deep context reweights for intra-category similarity in fusion, plus reassembly based on information content. The paper claims easy integration into CNN and Transformer architectures, with significant performance improvements on MS COCO, VisDrone2019-DET, and Cityscapes, including 49.6 mask AP and 85.6 mIoU when combined with OneFormer and Swin-L.
Significance. Should the empirical gains prove robust and attributable to the proposed mechanisms, A3-FPN would represent a meaningful advance in feature pyramid designs for handling scale variations and small objects in detection and segmentation. The public availability of the code at the provided GitHub link is a notable strength that facilitates verification and extension by the community.
major comments (3)
- The reported benchmark results, such as the 49.6 mask AP on MS COCO, do not include ablation studies that hold parameter count, FLOPs, and training schedule fixed while isolating the contributions of the asymptotically disentangled column network and the content-aware resampling/reweighting modules. This is load-bearing for the central claim that these components yield genuine improvements in discriminative feature capture.
- The description of the content-aware attention modules in feature fusion and reassembly lacks analysis of the computational overhead introduced by generating position-wise offsets, weights, and intra-category reweights, which is necessary to evaluate whether the 'remarkable performance gains' come at an acceptable cost compared to standard FPNs.
- No error bars, results from multiple random seeds, or statistical tests are provided for the performance numbers on the three datasets, reducing confidence that the gains over baselines are statistically significant rather than due to variance or post-hoc tuning.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important aspects of empirical validation that will strengthen the paper. We provide point-by-point responses below and commit to revisions that address the concerns while preserving the core contributions of A3-FPN.
read point-by-point responses
-
Referee: The reported benchmark results, such as the 49.6 mask AP on MS COCO, do not include ablation studies that hold parameter count, FLOPs, and training schedule fixed while isolating the contributions of the asymptotically disentangled column network and the content-aware resampling/reweighting modules. This is load-bearing for the central claim that these components yield genuine improvements in discriminative feature capture.
Authors: We agree that controlled ablations with matched parameter counts, FLOPs, and training schedules are essential to isolate the contributions of the horizontally-spread column network and the content-aware modules. Our existing ablations demonstrate component-wise gains but do not enforce strict budget matching. In the revised manuscript we will add new ablation tables that scale baseline FPN variants (e.g., by adjusting channel widths) to match the exact parameter and FLOP counts of each A3-FPN configuration while keeping the training schedule identical. These results will be reported alongside the original numbers to directly support the claim of genuine improvements. revision: yes
-
Referee: The description of the content-aware attention modules in feature fusion and reassembly lacks analysis of the computational overhead introduced by generating position-wise offsets, weights, and intra-category reweights, which is necessary to evaluate whether the 'remarkable performance gains' come at an acceptable cost compared to standard FPNs.
Authors: We acknowledge the need for explicit overhead analysis. The current manuscript reports overall model FLOPs but does not break down the incremental cost of the offset/weight generation and reweighting operations. In the revision we will add a dedicated table and accompanying text that quantifies the additional parameters and FLOPs attributable to each content-aware module (resampling, reweighting, and reassembly) relative to a standard FPN. We will also compare these costs against recent pyramid variants (e.g., BiFPN, CARAFE) to demonstrate that the observed gains remain favorable on a performance-per-FLOP basis. revision: yes
-
Referee: No error bars, results from multiple random seeds, or statistical tests are provided for the performance numbers on the three datasets, reducing confidence that the gains over baselines are statistically significant rather than due to variance or post-hoc tuning.
Authors: We recognize that reporting variability across random seeds strengthens confidence in the results. Our experiments used a fixed seed for reproducibility, consistent with common practice in the field, but did not include multi-seed statistics. In the revised manuscript we will rerun the primary experiments (COCO detection/segmentation, Cityscapes, VisDrone) with at least three independent random seeds, reporting mean and standard deviation for all key metrics. We will also note that the consistent gains across three distinct datasets and multiple backbone architectures already provide supporting evidence, but the added statistics will allow formal assessment of significance. revision: yes
Circularity Check
No circularity: empirical architecture proposal with benchmark validation
full rationale
The paper proposes an empirical neural architecture (A3-FPN) consisting of a horizontally-spread column network and content-aware attention modules for multi-scale feature fusion and reassembly. It describes the design choices in prose and reports performance on MS COCO, VisDrone2019-DET, and Cityscapes when integrated with existing backbones. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior work by the same authors are invoked to justify the core mechanisms. The central claims rest on empirical gains rather than any closed-loop mathematical reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- position-wise offsets and weights in content-aware resampling
- deep context reweights
axioms (1)
- domain assumption Multi-scale representations are the common strategy to tackle object scale variation in dense prediction tasks
invented entities (2)
-
Asymptotically disentangled framework with horizontally-spread column network
no independent evidence
-
Content-aware attention modules for resampling and reassembly
no independent evidence
Forward citations
Cited by 1 Pith paper
-
StomaD2: An All-in-One System for Intelligent Stomatal Phenotype Analysis via Diffusion-Based Restoration Detection Network
StomaD2 integrates diffusion-based image restoration with a specialized rotated detection network to achieve high-accuracy stomatal phenotyping across more than 130 plant species.
Reference graph
Works this paper leans on
-
[1]
M. Chen, L. Zhang, R. Feng, X. Xue, J. Feng, Rethinking local and global feature repre- sentation for dense prediction, Pattern Recognition 135 (2023) 109168
2023
-
[2]
Zhang, Z
G. Zhang, Z. Li, C. Tang, J. Li, X. Hu, Cednet: A cascade encoder–decoder network for dense prediction, Pattern Recognition 158 (2025) 111072
2025
-
[3]
Y . Chen, Z. Zhang, Y . Cao, L. Wang, S. Lin, H. Hu, Reppoints v2: Verification meets regression for object detection, in: Advances in Neural Information Processing Systems, V ol. 33, 2020, pp. 5621–5631
2020
-
[4]
X. Ding, R. Zhang, Q. Liu, Y . Yang, Real-time small object detection using adaptive weighted fusion of efficient positional features, Pattern Recognition 167 (2025) 111717
2025
-
[5]
K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask r-cnn, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 2961–2969
2017
-
[6]
R. Li, C. He, S. Li, Y . Zhang, L. Zhang, Dynamask: dynamic mask selection for instance segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2023, pp. 11279–11288
2023
-
[7]
J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3431–3440
2015
-
[8]
F. Li, H. Zhang, H. Xu, S. Liu, L. Zhang, L. M. Ni, H.-Y . Shum, Mask dino: Towards a unified transformer-based framework for object detection and segmentation, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3041–3050
2023
-
[9]
T.-Y . Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyramid net- works for object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2117–2125. 28
2017
-
[10]
S. Liu, L. Qi, H. Qin, J. Shi, J. Jia, Path aggregation network for instance segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8759–8768
2018
-
[11]
M. Tan, R. Pang, Q. V . Le, Efficientdet: Scalable and efficient object detection, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10781–10790
2020
-
[12]
W. Liu, H. Lu, H. Fu, Z. Cao, Learning to upsample by learning to sample, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2023, pp. 6027–6037
2023
-
[13]
J. Wang, K. Chen, R. Xu, Z. Liu, C. C. Loy, D. Lin, Carafe++: Unified content-aware reassembly of features, IEEE Transactions on Pattern Analysis and Machine Intelligence 44 (9) (2022) 4674–4687
2022
-
[14]
Huang, Z
S. Huang, Z. Lu, R. Cheng, C. He, Fapn: Feature-aligned pyramid network for dense image prediction, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2021, pp. 864–873
2021
-
[15]
G. Yang, J. Lei, H. Tian, Z. Feng, R. Liang, Asymptotic feature pyramid network for label- ing pixels and regions, IEEE Transactions on Circuits and Systems for Video Technology 34 (9) (2024) 7820–7829
2024
-
[16]
L. Chen, Y . Fu, L. Gu, C. Yan, T. Harada, G. Huang, Frequency-aware feature fusion for dense image prediction, IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[17]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: Proceedings of the European Conference on Computer Vision, Springer, 2014, pp. 740–755
2014
-
[18]
Cordts, M
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, B. Schiele, The cityscapes dataset for semantic urban scene understanding, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3213–3223
2016
-
[19]
H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2881–2890. 29
2017
-
[20]
H. Zhao, Y . Zhang, S. Liu, J. Shi, C. C. Loy, D. Lin, J. Jia, Psanet: Point-wise spatial atten- tion network for scene parsing, in: Proceedings of the European Conference on Computer Vision, 2018, pp. 267–283
2018
-
[21]
T. Xiao, Y . Liu, B. Zhou, Y . Jiang, J. Sun, Unified perceptual parsing for scene understand- ing, in: Proceedings of the European Conference on Computer Vision, 2018, pp. 418–434
2018
-
[22]
Kirillov, Y
A. Kirillov, Y . Wu, K. He, R. Girshick, Pointrend: Image segmentation as rendering, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9799–9808
2020
-
[23]
Guo, C.-Z
M.-H. Guo, C.-Z. Lu, Q. Hou, Z. Liu, M.-M. Cheng, S.-M. Hu, Segnext: Rethinking con- volutional attention design for semantic segmentation, in: Advances in Neural Information Processing Systems, V ol. 35, 2022, pp. 1140–1156
2022
-
[24]
Zheng, J
S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y . Wang, Y . Fu, J. Feng, T. Xiang, P. H. Torr, et al., Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2021, pp. 6881–6890
2021
-
[25]
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, P. Luo, Segformer: Simple and efficient design for semantic segmentation with transformers, in: Advances in Neural In- formation Processing Systems, V ol. 34, 2021, pp. 12077–12090
2021
-
[26]
S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: towards real-time object detection with region proposal networks, in: Advances in Neural Information Processing Systems, 2015, p. 91–99
2015
-
[27]
Z. Cai, N. Vasconcelos, Cascade r-cnn: Delving into high quality object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6154–6162
2018
-
[28]
A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, et al., Yolov10: Real-time end-to- end object detection, in: Advances in Neural Information Processing Systems, 2024, pp. 107984–108011. 30
2024
-
[29]
Carion, F
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, S. Zagoruyko, End-to-end object detection with transformers, in: Proceedings of the European Conference on Computer Vision, Springer, 2020, pp. 213–229
2020
-
[30]
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, J. Chen, Detrs beat yolos on real- time object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16965–16974
2024
-
[31]
Cheng, I
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, R. Girdhar, Masked-attention mask trans- former for universal image segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1280–1289
2022
-
[32]
J. Jain, J. Li, M. T. Chiu, A. Hassani, N. Orlov, H. Shi, Oneformer: One transformer to rule universal image segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2989–2998
2023
-
[33]
C. Wang, W. He, Y . Nie, J. Guo, C. Liu, Y . Wang, K. Han, Gold-yolo: Efficient object de- tector via gather-and-distribute mechanism, in: Advances in Neural Information Processing Systems, V ol. 36, 2023, pp. 51094–51112
2023
-
[34]
Ghiasi, T.-Y
G. Ghiasi, T.-Y . Lin, Q. V . Le, Nas-fpn: Learning scalable feature pyramid architecture for object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7036–7045
2019
-
[35]
W. Weng, M. Wei, J. Ren, F. Shen, Enhancing aerial object detection with selective fre- quency interaction network, IEEE Transactions on Artificial Intelligence 5 (12) (2024) 6109–6120
2024
-
[36]
H. Li, R. Zhang, Y . Pan, J. Ren, F. Shen, Lr-fpn: Enhancing remote sensing object detection with location refined feature pyramid network, in: 2024 International Joint Conference on Neural Networks (IJCNN), 2024, pp. 1–8
2024
-
[37]
G. Zhao, W. Ge, Y . Yu, Graphfpn: Graph feature pyramid network for object detection, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2021, pp. 2763–2772. 31
2021
-
[38]
M. Hu, Y . Li, L. Fang, S. Wang, A2-fpn: Attention aggregation based feature pyramid network for instance segmentation, in: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2021, pp. 15343–15352
2021
-
[39]
D. Liu, J. Liang, T. Geng, A. Loui, T. Zhou, Tripartite feature enhanced pyramid network for dense prediction, IEEE Transactions on Image Processing 32 (2023) 2678–2692
2023
-
[40]
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable detr: Deformable transformers for end-to-end object detection, in: International Conference on Learning Representations, 2021
2021
-
[41]
J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y . Zhao, D. Liu, Y . Mu, M. Tan, X. Wang, W. Liu, B. Xiao, Deep high-resolution representation learning for visual recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 43 (10) (2021) 3349–3364
2021
-
[42]
Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of control, signals and systems 2 (4) (1989) 303–314
G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of control, signals and systems 2 (4) (1989) 303–314
1989
-
[43]
Z. Lu, H. Pu, F. Wang, Z. Hu, L. Wang, The expressive power of neural networks: A view from the width, in: Advances in neural information processing systems, 2017, p. 6232–6240
2017
-
[44]
Xiong, Z
Y . Xiong, Z. Li, Y . Chen, F. Wang, X. Zhu, J. Luo, W. Wang, T. Lu, H. Li, Y . Qiao, et al., Efficient deformable convnets: Rethinking dynamic and sparse operator for vision applications, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5652–5661
2024
-
[45]
Y . Wu, K. He, Group normalization, in: Proceedings of the European Conference on Com- puter Vision, 2018, pp. 3–19
2018
-
[46]
X. Wang, S. Zhang, Z. Yu, L. Feng, W. Zhang, Scale-equalizing pyramid convolution for object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13359–13368
2020
-
[47]
C. Guo, B. Fan, Q. Zhang, S. Xiang, C. Pan, Augfpn: Improving multi-scale feature learn- ing for object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 12595–12604. 32
2020
-
[48]
Zhang, H
D. Zhang, H. Zhang, J. Tang, M. Wang, X. Hua, Q. Sun, Feature pyramid transformer, in: Proceedings of the European Conference on Computer Vision, Springer, 2020, pp. 323– 339
2020
-
[49]
Z. Zong, Q. Cao, B. Leng, Rcnet: Reverse feature pyramid and cross-scale shift network for object detection, in: Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 5637–5645
2021
-
[50]
Everingham, L
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, A. Zisserman, The pascal visual object classes (voc) challenge, International Journal of Computer Vision 88 (2010) 303– 338
2010
-
[51]
D. Du, P. Zhu, L. Wen, X. Bian, et al., Visdrone-det2019: The vision meets drone ob- ject detection in image challenge results, in: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 2019, pp. 213–226
2019
-
[52]
T.-Y . Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 2980–2988
2017
-
[53]
Z. Du, Z. Hu, G. Zhao, Y . Jin, H. Ma, Cross-layer feature pyramid transformer for small object detection in aerial images, IEEE Transactions on Geoscience and Remote Sensing 63 (2025) 1–14
2025
-
[54]
K. Chen, J. Wang, J. Pang, Y . Cao, Y . Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Xu, et al., Mmdetection: Open mmlab detection toolbox and benchmark, arXiv preprint arXiv:1906.07155 (2019)
work page Pith review arXiv 1906
-
[55]
Contributors, MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark,https://github.com/open-mmlab/mmsegmentation(2020)
M. Contributors, MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark,https://github.com/open-mmlab/mmsegmentation(2020)
2020
-
[56]
H. G. Ramaswamy, et al., Ablation-cam: Visual explanations for deep convolutional net- work via gradient-free localization, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 983–991
2020
-
[57]
Z. Tian, C. Shen, H. Chen, T. He, Fcos: Fully convolutional one-stage object detection, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 9627–9636. 33
2019
-
[58]
X. Li, W. Wang, X. Hu, J. Li, J. Tang, J. Yang, Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11632–11641
2021
-
[59]
Y . Peng, H. Li, P. Wu, Y . Zhang, X. Sun, F. Wu, D-FINE: Redefine regression task of DETRs as fine-grained distribution refinement, in: The Thirteenth International Conference on Learning Representations, 2025
2025
-
[60]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[61]
Strudel, R
R. Strudel, R. Garcia, I. Laptev, C. Schmid, Segmenter: Transformer for semantic segmen- tation, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2021, pp. 7262–7272
2021
-
[62]
W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, Z. Wang, Real-time single image and video super-resolution using an efficient sub-pixel convolu- tional neural network, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1874–1883
2016
-
[63]
Y . Dai, H. Lu, C. Shen, Learning affinity-aware upsampling for deep image matting, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6841–6850
2021
-
[64]
H. Lu, W. Liu, Z. Ye, H. Fu, Y . Liu, Z. Cao, Sapa: Similarity-aware point affiliation for feature upsampling, in: Advances in Neural Information Processing Systems, 2022, pp. 20889–20901
2022
-
[65]
H. Lu, W. Liu, H. Fu, Z. Cao, Fade: Fusing the assets of decoder and encoder for task- agnostic upsampling, in: Proceedings of the European Conference on Computer Vision, Springer, 2022, pp. 231–247
2022
-
[66]
#$%& !"'$() coordinate offset (∆#, ∆$)attention weight ∆% coordinate offset (∆#, ∆$)attention weight ∆% resampled feature map resampled feature map !! !
J. Wang, K. Chen, R. Xu, Z. Liu, C. C. Loy, D. Lin, Carafe: Content-aware reassembly of features, in: Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 3007–3016. 34 Appendix A. Algorithm Procedures ofA 3-FPN Algorithm 1:Bottom-up Asymptotic Content-Aware Pyramid Attention Network Input:nhierarchical features{X 1,X 2, . . . ,Xn}from the backbone, which...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.