Recognition: unknown
TimeSeriesExamAgent: Creating Time Series Reasoning Benchmarks at Scale
Pith reviewed 2026-05-10 15:21 UTC · model grok-4.3
The pith
LLM agents can generate diverse time series reasoning benchmarks from real data, but models still perform poorly on them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining fixed templates with LLM agents, comprehensive time series reasoning benchmarks can be produced at scale from real-world datasets while preserving quality and diversity; when evaluated on these benchmarks, current LLMs exhibit limited performance in abstract reasoning categories and in domain-specific applications.
What carries the argument
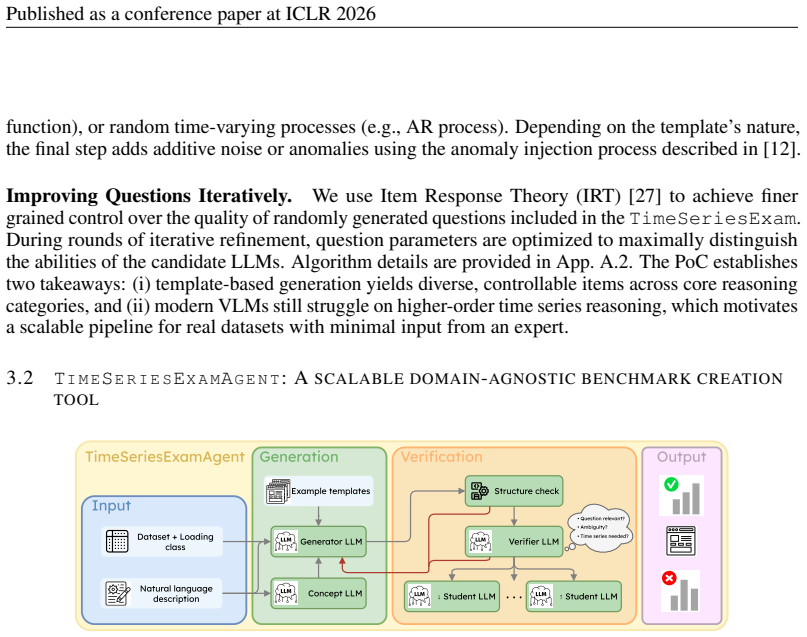
TimeSeriesExamAgent, the LLM-driven pipeline that extracts and formats reasoning questions from raw time series records while enforcing coverage across the five categories and filtering for validity.
If this is right
- Evaluations of LLMs on time series tasks can now be repeated across many domains without repeated manual curation.
- Specific weaknesses in categories such as causality and anomaly detection become easier to measure and target for improvement.
- Benchmark creation pipelines can be reused to expand coverage to additional domains beyond healthcare, finance, and weather.
- Model developers gain concrete signals on where architectural or training changes are still needed for temporal data.
Where Pith is reading between the lines
- The same agent-based generation approach could be adapted to create reasoning benchmarks for other sequential data types such as event logs or sensor streams.
- Persistent low performance across models suggests that simply scaling data or parameters may not suffice without explicit mechanisms for temporal structure.
- If the benchmarks hold up, they could serve as a standard testbed for hybrid systems that combine LLMs with dedicated time series modules.
Load-bearing premise
That questions produced by LLM agents from real datasets accurately capture genuine time series reasoning without adding artifacts, biases, or questions that do not test the intended skill.
What would settle it
A controlled study in which domain experts label a random sample of generated questions as invalid or off-target for the claimed reasoning category at a rate high enough to undermine benchmark reliability.
Figures






read the original abstract
Large Language Models (LLMs) have shown promising performance in time series modeling tasks, but do they truly understand time series data? While multiple benchmarks have been proposed to answer this fundamental question, most are manually curated and focus on narrow domains or specific skill sets. To address this limitation, we propose scalable methods for creating comprehensive time series reasoning benchmarks that combine the flexibility of templates with the creativity of LLM agents. We first develop TimeSeriesExam, a multiple-choice benchmark using synthetic time series to evaluate LLMs across five core reasoning categories: pattern recognitionnoise understandingsimilarity analysisanomaly detection, and causality. Then, with TimeSeriesExamAgent, we scale our approach by automatically generating benchmarks from real-world datasets spanning healthcare, finance and weather domains. Through multi-dimensional quality evaluation, we demonstrate that our automatically generated benchmarks achieve diversity comparable to manually curated alternatives. However, our experiments reveal that LLM performance remains limited in both abstract time series reasoning and domain-specific applications, highlighting ongoing challenges in enabling effective time series understanding in these models. TimeSeriesExamAgent is available at https://github.com/magwiazda/TimeSeriesExamAgent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TimeSeriesExam, a multiple-choice benchmark using synthetic time series data to evaluate LLMs on five core reasoning categories (pattern recognition, noise understanding, similarity analysis, anomaly detection, and causality), and TimeSeriesExamAgent, an LLM-agent system to automatically generate analogous benchmarks from real-world datasets in healthcare, finance, and weather. It reports that multi-dimensional quality evaluation shows the auto-generated benchmarks achieve diversity comparable to manually curated ones, yet experiments demonstrate limited LLM performance on both abstract and domain-specific time series reasoning tasks.
Significance. If the generated benchmarks prove valid and free of artifacts, the work is significant for providing a scalable, template-plus-LLM-agent approach to benchmark creation that could reduce reliance on manual curation in time series reasoning evaluation. The public release of TimeSeriesExamAgent on GitHub supports reproducibility, and the finding of persistent LLM limitations could usefully direct research toward better temporal understanding in models applied to critical domains.
major comments (2)
- [Abstract and §4] Abstract and §4 (TimeSeriesExamAgent): The central claim that auto-generated benchmarks are high-quality rests on a 'multi-dimensional quality evaluation' showing diversity comparable to manual curation, but no concrete metrics (e.g., diversity scores, inter-annotator agreement, percentage of factually invalid or ambiguous questions, or human validation rates) are reported. Without these, it is impossible to rule out generation artifacts that could inflate or deflate the reported LLM performance ceilings.
- [§5] §5 (Experiments): The conclusion that 'LLM performance remains limited' is based on accuracy numbers from the generated benchmarks, yet the manuscript provides no error analysis, breakdown by reasoning category, or controls for whether low performance stems from genuine reasoning deficits versus malformed questions or surface cues. This leaves the interpretation of ongoing challenges in time series understanding only partially supported.
minor comments (2)
- [Abstract] Abstract: The category list contains a clear formatting error ('pattern recognitionnoise understandingsimilarity analysisanomaly detection') that should be corrected for readability.
- The manuscript would benefit from an explicit table or appendix listing example generated questions with their intended reasoning category and any human validation notes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important opportunities to strengthen the presentation of our quality evaluation and experimental results. We address each major comment below and will revise the manuscript accordingly to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (TimeSeriesExamAgent): The central claim that auto-generated benchmarks are high-quality rests on a 'multi-dimensional quality evaluation' showing diversity comparable to manual curation, but no concrete metrics (e.g., diversity scores, inter-annotator agreement, percentage of factually invalid or ambiguous questions, or human validation rates) are reported. Without these, it is impossible to rule out generation artifacts that could inflate or deflate the reported LLM performance ceilings.
Authors: We agree that the manuscript would benefit from more explicit quantitative details on the multi-dimensional quality evaluation. In the revised version, we will report concrete metrics including diversity scores (e.g., lexical and semantic diversity measures), any inter-annotator agreement statistics from human reviews, and human validation rates on samples of generated questions to assess factual validity and ambiguity. This will provide stronger evidence against potential generation artifacts and allow direct comparison to manual curation. revision: yes
-
Referee: [§5] §5 (Experiments): The conclusion that 'LLM performance remains limited' is based on accuracy numbers from the generated benchmarks, yet the manuscript provides no error analysis, breakdown by reasoning category, or controls for whether low performance stems from genuine reasoning deficits versus malformed questions or surface cues. This leaves the interpretation of ongoing challenges in time series understanding only partially supported.
Authors: We acknowledge that additional analysis is needed to better substantiate the interpretation of LLM limitations. In the revision, we will add a per-category accuracy breakdown across the five reasoning types, a qualitative error analysis on sampled incorrect responses to identify patterns (e.g., confusion with noise vs. true anomalies), and discussion of controls such as surface cue checks. These additions will help distinguish reasoning deficits from other factors. revision: yes
Circularity Check
No circularity in benchmark construction or performance claims
full rationale
The paper introduces new template-based and LLM-agent-generated benchmarks (TimeSeriesExam and TimeSeriesExamAgent) from real-world datasets, then measures LLM accuracy on them while reporting a multi-dimensional quality evaluation for diversity. No equations, fitted parameters, or derivations are presented that reduce the reported LLM limitations or benchmark quality to self-defined inputs by construction. Claims rest on external comparisons to manual curation and empirical test results rather than self-referential loops, self-citation chains, or renamed known results. This is a standard empirical benchmark paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Synthetic time series can validly probe core reasoning categories such as pattern recognition, noise understanding, similarity analysis, anomaly detection, and causality.
- ad hoc to paper LLM agents can produce high-quality, diverse multiple-choice questions from real-world time series datasets without significant artifacts or biases.
Reference graph
Works this paper leans on
-
[2]
Chronos: Learning the Language of Time Series
Afshin Ansari, Amol Bhattacharya, Abhijit Kulkarni, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Peters, and Arman Cohan
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer, 2020
2020
-
[5]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[6]
Benchagents: Automated benchmark creation with agent interaction, 2024
Natasha Butt, Varun Chandrasekaran, Neel Joshi, Besmira Nushi, and Vidhisha Balachan- dran. Benchagents: Automated benchmark creation with agent interaction.arXiv preprint arXiv:2410.22584, 2024
-
[7]
Timeseriesgym: A scalable benchmark for (time series) machine learning engineering agents
Yifu Cai, Xinyu Li, Mononito Goswami, Michał Wili´nski, Gus Welter, and Artur Dubrawski. Timeseriesgym: A scalable benchmark for (time series) machine learning engineering agents. arXiv preprint arXiv:2505.13291, 2025
-
[8]
Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, and Yan Liu. Tempo: Prompt-based generative pre-trained transformer for time series forecasting.arXiv preprint arXiv:2310.04948, 2023
-
[9]
Jialin Chen, Aosong Feng, Ziyu Zhao, Juan Garza, Gaukhar Nurbek, Cheng Qin, Ali Maatouk, Leandros Tassiulas, Yifeng Gao, and Rex Ying. Mtbench: A multimodal time series benchmark for temporal reasoning and question answering.arXiv preprint arXiv:2503.16858, 2025
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 10 Published as a conference paper ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024
2024
-
[12]
Unsuper- vised model selection for time-series anomaly detection.arXiv preprint arXiv:2210.01078,
Mononito Goswami, Cristian Challu, Laurent Callot, Lenon Minorics, and Andrey Kan. Unsu- pervised model selection for time-series anomaly detection.arXiv preprint arXiv:2210.01078, 2022
-
[13]
Moment: A family of open time-series foundation models
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885, 2024
-
[14]
Investigating causal relations by econometric models and cross-spectral methods.Econometrica: journal of the Econometric Society, pages 424–438, 1969
Clive WJ Granger. Investigating causal relations by econometric models and cross-spectral methods.Econometrica: journal of the Econometric Society, pages 424–438, 1969
1969
-
[15]
Gauthier Guinet, Behrooz Omidvar-Tehrani, Anoop Deoras, and Laurent Callot. Automated evaluation of retrieval-augmented language models with task-specific exam generation.arXiv preprint arXiv:2405.13622, 2024
-
[16]
Tabpfn: A transformer that solves small tabular classification problems in a second.Advances in Neural Information Processing Systems (NeurIPS), 2023
Noah Hollmann, Samuel Müller, Johannes Haug, Patrick Schramowski, and Kristian Kersting. Tabpfn: A transformer that solves small tabular classification problems in a second.Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Bench- marking deep learning interpretability in time series predictions.Advances in neural information processing systems, 33:6441–6452, 2020
Aya Abdelsalam Ismail, Mohamed Gunady, Hector Corrada Bravo, and Soheil Feizi. Bench- marking deep learning interpretability in time series predictions.Advances in neural information processing systems, 33:6441–6452, 2020
2020
-
[19]
Haoxin Liu, Shangqing Xu, Zhiyuan Zhao, Lingkai Kong, Harshavardhan Kamarthi, Aditya B
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728, 2023
-
[20]
Expertise reversal effect and its implications for learner-tailored instruction
Slava Kalyuga. Expertise reversal effect and its implications for learner-tailored instruction. Educational psychology review, 19(4):509–539, 2007
2007
-
[21]
Time-mqa: Time series multi-task question answering with context enhancement,
Yaxuan Kong, Yiyuan Yang, Yoontae Hwang, Wenjie Du, Stefan Zohren, Zhangyang Wang, Ming Jin, and Qingsong Wen. Time-mqa: Time series multi-task question answering with context enhancement.arXiv preprint arXiv:2503.01875, 2025
-
[22]
py-irt: A scalable item response theory library for python.INFORMS Journal on Computing, 35(1):5–13, 2023
John Patrick Lalor and Pedro Rodriguez. py-irt: A scalable item response theory library for python.INFORMS Journal on Computing, 35(1):5–13, 2023
2023
-
[23]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[24]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks.arXiv preprint arXiv:2005.11401, 2020
work page internal anchor Pith review arXiv 2005
-
[25]
Time-mmd: Multi-domain multimodal dataset for time series analysis.Advances in Neural Information Processing Systems, 37:77888–77933, 2024
Haoxin Liu, Shangqing Xu, Zhiyuan Zhao, Lingkai Kong, Harshavardhan Prabhakar Kamarthi, Aditya Sasanur, Megha Sharma, Jiaming Cui, Qingsong Wen, Chao Zhang, et al. Time-mmd: Multi-domain multimodal dataset for time series analysis.Advances in Neural Information Processing Systems, 37:77888–77933, 2024
2024
-
[26]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment.arXiv preprint arXiv:2303.16634, 2023. 11 Published as a conference paper at ICLR 2026
work page internal anchor Pith review arXiv 2023
-
[27]
IAP, 2008
Frederic M Lord and Melvin R Novick.Statistical theories of mental test scores. IAP, 2008
2008
-
[28]
Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
2008
-
[29]
Mike A Merrill, Mingtian Tan, Vinayak Gupta, Tom Hartvigsen, and Tim Althoff. Language models still struggle to zero-shot reason about time series.arXiv preprint arXiv:2404.11757, 2024
-
[30]
Mimic-iv waveform database.PhysioNet, 2022
Benjamin Moody, Shaoxiong Hao, Benjamin Gow, Tom Pollard, Weixuan Zong, and Roger Mark. Mimic-iv waveform database.PhysioNet, 2022
2022
-
[31]
The impact of the mit-bih arrhythmia database.IEEE engineering in medicine and biology magazine, 20(3):45–50, 2001
George B Moody and Roger G Mark. The impact of the mit-bih arrhythmia database.IEEE engineering in medicine and biology magazine, 20(3):45–50, 2001
2001
-
[32]
Learning to compress prompts with gist tokens, 2024
Jesse Mu, Xiang Lisa Li, and Noah Goodman. Learning to compress prompts with gist tokens, 2024
2024
-
[33]
Ecg-qa: A comprehensive question answering dataset combined with electrocardiogram.Advances in Neural Information Processing Systems, 36:66277–66288, 2023
Jungwoo Oh, Gyubok Lee, Seongsu Bae, Joon-myoung Kwon, and Edward Choi. Ecg-qa: A comprehensive question answering dataset combined with electrocardiogram.Advances in Neural Information Processing Systems, 36:66277–66288, 2023
2023
-
[34]
Ecg-qa: A comprehensive question answering dataset combined with electrocardiogram.Advances in Neural Information Processing Systems, 36, 2024
Jungwoo Oh, Gyubok Lee, Seongsu Bae, Joon-myoung Kwon, and Edward Choi. Ecg-qa: A comprehensive question answering dataset combined with electrocardiogram.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[35]
Openai o3-mini system card
OpenAI. Openai o3-mini system card. https://openai.com/index/ o3-mini-system-card/, January 2025. Accessed: 2025-08-22
2025
-
[36]
Weatherbench 2: A benchmark for the next generation of data-driven global weather models, 2023
Stephan Rasp, Stephan Hoyer, Alexander Merose, Ian Langmore, Peter Battaglia, Tyler Russel, Alvaro Sanchez-Gonzalez, Vivian Yang, Rob Carver, Shreya Agrawal, Matthew Chantry, Zied Ben Bouallegue, Peter Dueben, Carla Bromberg, Jared Sisk, Luke Barrington, Aaron Bell, and Fei Sha. Weatherbench 2: A benchmark for the next generation of data-driven global wea...
2023
-
[37]
yfinance: Yahoo! finance market data downloader
Ranan Roussi. yfinance: Yahoo! finance market data downloader. https://github.com/ ranaroussi/yfinance, 2017. Accessed: 2025-08-22
2017
-
[38]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating llm generations with a panel of diverse models.arXiv preprint arXiv:2404.18796, 2024
-
[40]
Ptb-xl, a large publicly available electrocardiography dataset.Scientific data, 7(1):1–15, 2020
Patrick Wagner, Nils Strodthoff, Ralf-Dieter Bousseljot, Dieter Kreiseler, Fatima I Lunze, Wojciech Samek, and Tobias Schaeffter. Ptb-xl, a large publicly available electrocardiography dataset.Scientific data, 7(1):1–15, 2020
2020
-
[41]
Recursively summarizing enables long-term dialogue memory in large language models, 2025
Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding. Recursively summarizing enables long-term dialogue memory in large language models, 2025
2025
-
[42]
Wanying Wang, Zeyu Ma, Pengfei Liu, and Mingang Chen. Testagent: A framework for domain- adaptive evaluation of llms via dynamic benchmark construction and exploratory interaction. arXiv preprint arXiv:2410.11507, 2024
-
[43]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024. 12 Published as a conference paper at ICLR 2026
work page internal anchor Pith review arXiv 2024
-
[44]
Xu Wang, Jiaju Kang, Puyu Han, Yubao Zhao, Qian Liu, Liwenfei He, Lingqiong Zhang, Lingyun Dai, Yongcheng Wang, and Jie Tao. Ecg-expert-qa: A benchmark for evaluating medical large language models in heart disease diagnosis.arXiv preprint arXiv:2502.17475, 2025
-
[45]
Yilin Wang, Peixuan Lei, Jie Song, Yuzhe Hao, Tao Chen, Yuxuan Zhang, Lei Jia, Yuanxiang Li, and Zhongyu Wei. Itformer: Bridging time series and natural language for multi-modal qa with large-scale multitask dataset.arXiv preprint arXiv:2506.20093, 2025
-
[46]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[47]
Context is key: A benchmark for forecasting with essential textual information
Andrew Robert Williams, Arjun Ashok, Étienne Marcotte, Valentina Zantedeschi, Jithendaraa Subramanian, Roland Riachi, James Requeima, Alexandre Lacoste, Irina Rish, Nicolas Cha- pados, et al. Context is key: A benchmark for forecasting with essential textual information. arXiv preprint arXiv:2410.18959, 2024
-
[48]
Gerald Woo, Chenghao Liu, Doyen Sahoo, Akshat Kumar, and Steven Hoi. Cost: Contrastive learning of disentangled seasonal-trend representations for time series forecasting.arXiv preprint arXiv:2202.01575, 2022
-
[49]
TS-Reasoner: Domain-Oriented Time Series Inference Agents for Reasoning and Automated Analysis
Wen Ye, Wei Yang, Defu Cao, Yizhou Zhang, Lumingyuan Tang, Jie Cai, and Yan Liu. Domain- oriented time series inference agents for reasoning and automated analysis.arXiv preprint arXiv:2410.04047, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
One fits all: Power general time series analysis by pretrained lm.Advances in neural information processing systems, 36:43322–43355, 2023
Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, et al. One fits all: Power general time series analysis by pretrained lm.Advances in neural information processing systems, 36:43322–43355, 2023
2023
-
[51]
Towards long-context time series foundation models
Nina ˙Zukowska, Mononito Goswami, Michał Wili´nski, Willa Potosnak, and Artur Dubrawski. Towards long-context time series foundation models.arXiv preprint arXiv:2409.13530, 2024. 13 Published as a conference paper at ICLR 2026 A TIMESERIESEXAM DETAILS Table 7: TimeSeriesExam meta-information breakdown for each category. Each question is associated with a ...
-
[52]
LLM generation: User guidelines and dataset descriptions are provided as input to an LLM, which proposes the concepts
-
[53]
Web Search: We provide the option for generator LLM obtain concepts through web search
-
[54]
Yes, there is a linear trend
Retrieval Augmented Generation: As an option, the user could also provide a relevant file from which the LLM reads and generates concepts[23]. Template generationAs input to our generator, the following components are provided: • User-provided guidelines: a document containing the user’s goal or specific requirements, • Dataset description: a list of colu...
2026
-
[55]
Is the question relevant to {exam_type} time series analysis?
-
[56]
Would you need the time series itself to answer the question?
-
[57]
If the answer to either is NO, return your objections
Are there no ambiguity in the question or its answer? If the answer to all is YES or MOSTLY YES, return only the number 1. If the answer to either is NO, return your objections. Return 1 (do not include any additional text then) or describe your objections. 19 Published as a conference paper at ICLR 2026 B.5 FRAMEWORKHYPERPARAMETERS In this section, we li...
2026
-
[58]
We used claude-sonnet-4-20250514 (initial generation with reasoning_effort="medium")
Generator LLM: the LLM used to generate concepts and the correspond- ing template. We used claude-sonnet-4-20250514 (initial generation with reasoning_effort="medium"). As a result, models developed by Anthropic are excluded from subsequent evaluations
-
[59]
We used gpt-4o-2024-08-06
Concept LLM: the LLM used to generate concepts. We used gpt-4o-2024-08-06
2024
-
[60]
Potential syntax errors, incorrect dataset querying, and bad output structure is detected, ensuring compatibility with the rest of the pipeline
Structure verification: Each template is sampled k= 3 time to create k exam questions. Potential syntax errors, incorrect dataset querying, and bad output structure is detected, ensuring compatibility with the rest of the pipeline
-
[61]
We used gpt-4o-2024-08-06
Verifier LLM: the LLM used to verify templates. We used gpt-4o-2024-08-06
2024
-
[62]
Currently we have two student LLMs: stronger: gpt-4o-2024-08-06 and weaker: gpt-4o-mini
Student LLMs: the student LLMs we use to check the exam differentiability. Currently we have two student LLMs: stronger: gpt-4o-2024-08-06 and weaker: gpt-4o-mini. The strength of a model is determined based on the OpenVLM leaderboard. Moreover, family of student models was unified to minimize architectural variations while providing wide enough capabilit...
2024
-
[63]
ecg", "medicine
Exam type: We are generating the data connected to specific domain. We used "ecg", "medicine", "finance", "weather" and "mechanical"
-
[64]
For each generation, 3 templates were randomly selected and included in the prompt as few-shot examples
Few-shot examples: 9 templates prepared beforehand were used to present the desired structure to the generator LLM. For each generation, 3 templates were randomly selected and included in the prompt as few-shot examples. This introduces variability into the generation process, enhancing diversity
-
[65]
min_trend_days
Regeneration patience: Templates requiring multiple regeneration cycles were generally of lower quality. In our experiments, we set a maximum of 3 regeneration attempts. B.6 EXAMPLE OFNATURALLANGUAGEDESCRIPTION I want to create time series exam testing model understanding of finance time series data. To load the data, use the provided ‘‘‘user_dataset‘‘‘ o...
2026
-
[66]
The questions normally come together with relevant time series data, which should be analized to answer the question correctly
SPECIFICITY You are an expert judge evaluating the specificity of ECG multiple-choice questions. The questions normally come together with relevant time series data, which should be analized to answer the question correctly. It is not includded in currently evaluated samples. Evaluate the specificity of the generated ECG multiple-choice question. A good q...
-
[68]
Determine if the question targets a single, clearly defined ECG finding or clinical interpretation
-
[69]
Assess the ratio of unique medical terms to general words
-
[70]
Is this ECG normal?
Penalize if: - The question is overly broad or open-ended (e.g., "Is this ECG normal?"). - The wording leaves diagnostic interpretation unclear. - The question covers multiple unrelated phenomena. Score highest if the question has one precise focus (e.g., "Is there ST elevation in lead V3 ?"). Score from 1-10 where: - 10: Excellent specificity with clear,...
-
[71]
The questions normally come together with relevant time series data, which should be analized to answer the question correctly
UNAMBIGUITY You are an expert judge evaluating the unambiguity of ECG multiple-choice questions. The questions normally come together with relevant time series data, which should be analized to answer the question correctly. It is not included in currently evaluated samples. Task: Evaluate if the question and answers can be objectively assessed without mu...
-
[73]
Determine if the question can be objectively assessed
-
[74]
Check if the answers are clear and unambiguous
-
[75]
Does this look strange?
Penalize if: - The question uses subjective terms (e.g., "Does this look strange?"). - The answers are open to multiple interpretations. - The question cannot be objectively answered. A good question should be clear and objective (e.g., "Is there tachycardia?"). Score from 1-10 where: - 10: Completely unambiguous and objective with crystal clear question ...
-
[76]
The questions normally come together with relevant time series data, which should be analized to answer the question correctly
DOMAIN RELEVANCE You are an expert judge evaluating the domain relevance of ECG multiple-choice questions. The questions normally come together with relevant time series data, which should be analized to answer the question correctly. It is not includded in currently evaluated samples. Task: Evaluate if the question actually pertains to ECGs and medicine....
-
[77]
Does the question contain medical and ECG-specific terminology?
-
[78]
Is the question relevant to ECG interpretation and medical diagnosis?
-
[79]
Is the question related to ECG interpretation?
-
[80]
QRS," "arrhythmia,
Does the question have proper medical context? 26 Published as a conference paper at ICLR 2026 A good question should contain relevant medical terms (e.g., "QRS," "arrhythmia," "P wave") and pertain to ECG interpretation. Score from 1-10 where: - 10: Highly relevant to ECG domain with extensive proper medical terminology - 7-9: Good domain relevance with ...
2026
-
[81]
The questions normally come together with relevant time series data, which should be analized to answer the question correctly
ANSWERABILITY You are an expert judge evaluating the answerability of ECG multiple-choice questions. The questions normally come together with relevant time series data, which should be analized to answer the question correctly. It is not includded in currently evaluated samples. Task: Evaluate if the question can be answered based on ECG data analysis. E...
-
[82]
Read the question and all answer options
-
[83]
Determine if the question can be answered by analyzing ECG waveform data
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.