Recognition: unknown
FashionMV: Product-Level Composed Image Retrieval with Multi-View Fashion Data
Pith reviewed 2026-05-10 15:54 UTC · model grok-4.3
The pith
A small multimodal model trained on multi-view product data outperforms general-purpose models ten times its size on composed image retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
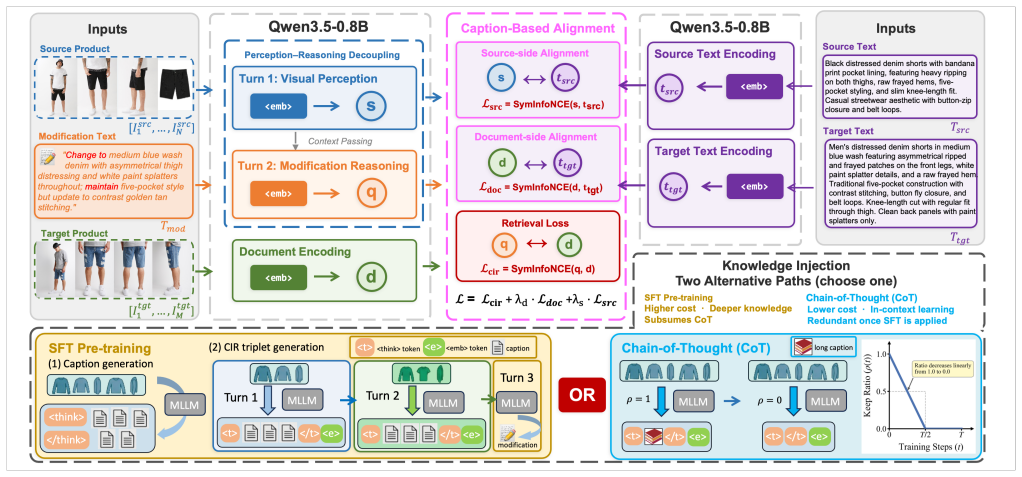
Product-level Composed Image Retrieval generalizes standard CIR by taking multiple views of a reference product plus modification text and returning the matching target product. FashionMV supplies the first large-scale support for this task through an automated pipeline that produces 220K triplets and multi-view alignments. ProCIR realizes the task in a multimodal LLM by running two-stage dialogue, caption-based alignment, and chain-of-thought guidance, optionally after supervised fine-tuning to inject structured product knowledge. Systematic tests across sixteen configurations confirm that alignment is the single most critical mechanism, that two-stage dialogue is required for alignment to
What carries the argument
The ProCIR framework, which integrates two-stage dialogue, caption-based alignment, and chain-of-thought guidance inside a multimodal large language model to process multi-view product inputs for composed retrieval.
If this is right
- Alignment is the single most critical mechanism for handling multi-view inputs.
- The two-stage dialogue architecture is a prerequisite for effective alignment.
- SFT and chain-of-thought serve as partially redundant knowledge injection paths.
- Compact domain-specific models can exceed the performance of much larger general-purpose embedding models on this retrieval task.
Where Pith is reading between the lines
- The automated data-generation pipeline could be reused to build multi-view datasets for non-fashion categories such as furniture or electronics.
- Performance gains may partly reflect fashion-specific knowledge already latent in the base multimodal model rather than the new mechanisms alone.
- E-commerce interfaces that let users select multiple reference views would directly exploit the product-level formulation.
- Extending the approach to video-derived multi-view sequences could further increase retrieval robustness.
Load-bearing premise
The fully automated pipeline that uses large multimodal models to generate the 220K CIR triplets and multi-view alignments produces data of sufficient quality and consistency for training and evaluation.
What would settle it
Retraining ProCIR on a human-annotated subset of the same products and measuring whether the performance margin over baselines remains intact.
Figures




read the original abstract
Composed Image Retrieval (CIR) retrieves target images using a reference image paired with modification text. Despite rapid advances, all existing methods and datasets operate at the image level -- a single reference image plus modification text in, a single target image out -- while real e-commerce users reason about products shown from multiple viewpoints. We term this mismatch View Incompleteness and formally define a new Multi-View CIR task that generalizes standard CIR from image-level to product-level retrieval. To support this task, we construct FashionMV, the first large-scale multi-view fashion dataset for product-level CIR, comprising 127K products, 472K multi-view images, and over 220K CIR triplets, built through a fully automated pipeline leveraging large multimodal models. We further propose ProCIR (Product-level Composed Image Retrieval), a modeling framework built upon a multimodal large language model that employs three complementary mechanisms -- two-stage dialogue, caption-based alignment, and chain-of-thought guidance -- together with an optional supervised fine-tuning (SFT) stage that injects structured product knowledge prior to contrastive training. Systematic ablation across 16 configurations on three fashion benchmarks reveals that: (1) alignment is the single most critical mechanism; (2) the two-stage dialogue architecture is a prerequisite for effective alignment; and (3) SFT and chain-of-thought serve as partially redundant knowledge injection paths. Our best 0.8B-parameter model outperforms all baselines, including general-purpose embedding models 10x its size. The dataset, model, and code are publicly available at https://github.com/yuandaxia2001/FashionMV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Multi-View Composed Image Retrieval (MV-CIR) as a product-level generalization of standard image-level CIR, constructs the FashionMV dataset (127K products, 472K images, 220K triplets) via a fully automated large-multimodal-model pipeline, and proposes the ProCIR framework (MLLM with two-stage dialogue, caption-based alignment, chain-of-thought, and optional SFT). Systematic ablations across 16 configurations on three fashion benchmarks indicate that alignment is the most critical mechanism, two-stage dialogue is a prerequisite, SFT and CoT are partially redundant, and the best 0.8B model outperforms all baselines including general-purpose models 10x larger. Dataset, model, and code are released publicly.
Significance. If the dataset quality and experimental claims hold, the work meaningfully extends CIR to realistic multi-view product reasoning in e-commerce and supplies a large public resource. The systematic 16-configuration ablation and explicit public release of data/code are strengths that support reproducibility and further research.
major comments (2)
- [Abstract (dataset construction)] Abstract (dataset construction paragraph): the 220K CIR triplets and multi-view alignments are generated entirely by an automated pipeline with large multimodal models, yet no human validation, inter-annotator agreement, or error-rate statistics on any held-out sample are reported. Because training and evaluation both depend on the correctness of modification texts and view groupings, this omission directly affects the reliability of the outperformance claim for the 0.8B ProCIR model.
- [Abstract (experimental results)] Abstract (experimental results paragraph): the claim that the 0.8B model outperforms baselines including 8B+ general embedding models is presented without any numerical metrics, tables, error bars, or statistical tests in the provided text. Load-bearing quantitative evidence is therefore missing for the central performance assertion.
minor comments (2)
- Clarify whether the three benchmarks are evaluated under identical multi-view conditions or retain their original single-view protocols.
- The description of the two-stage dialogue and caption-alignment mechanisms would benefit from a concise algorithmic outline or pseudocode.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive feedback and recommendation for major revision. We address each major comment point by point below, agreeing that the concerns are valid and outlining specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract (dataset construction)] Abstract (dataset construction paragraph): the 220K CIR triplets and multi-view alignments are generated entirely by an automated pipeline with large multimodal models, yet no human validation, inter-annotator agreement, or error-rate statistics on any held-out sample are reported. Because training and evaluation both depend on the correctness of modification texts and view groupings, this omission directly affects the reliability of the outperformance claim for the 0.8B ProCIR model.
Authors: We acknowledge that the abstract does not report human validation, inter-annotator agreement, or error-rate statistics for the automated pipeline. The full manuscript describes the LMM-based construction process in Section 3, but we agree this is a substantive gap that affects perceived reliability. In the revised version, we will add a new subsection on dataset validation. This will include results from manual inspection of a held-out sample of triplets and view groupings, reporting inter-annotator agreement rates and a categorized error analysis. These additions will directly support the dataset's suitability for training and evaluation. revision: yes
-
Referee: [Abstract (experimental results)] Abstract (experimental results paragraph): the claim that the 0.8B model outperforms baselines including 8B+ general embedding models is presented without any numerical metrics, tables, error bars, or statistical tests in the provided text. Load-bearing quantitative evidence is therefore missing for the central performance assertion.
Authors: We agree that the abstract, being concise by design, lacks the numerical metrics needed to substantiate the performance claim. The main paper already contains detailed tables, ablation results across 16 configurations, and comparisons to larger baselines. In the revision, we will update the abstract to include key quantitative results (e.g., Recall@10 improvements on the three benchmarks) and explicit references to the supporting tables and statistical comparisons in the body. This will make the central assertion self-contained while preserving brevity. revision: yes
Circularity Check
No circularity: empirical dataset construction and model evaluation are self-contained
full rationale
The paper defines a new Multi-View CIR task, builds FashionMV via an automated multimodal pipeline, introduces ProCIR with explicit mechanisms (two-stage dialogue, caption alignment, CoT, optional SFT), and reports ablation results plus benchmark comparisons. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes appear in the derivation. Performance claims rest on experimental outcomes against external baselines rather than any reduction to the paper's own inputs or prior self-referential results. This is standard empirical ML work whose central claims remain independently falsifiable on the released dataset and code.
Axiom & Free-Parameter Ledger
free parameters (1)
- Hyperparameters for SFT and contrastive training
axioms (1)
- domain assumption Large multimodal models can reliably produce captions, alignments, and triplets for fashion images without introducing systematic bias or noise
Reference graph
Works this paper leans on
-
[1]
Muhammad Umer Anwaar, Egor Labintcev, and Martin Kleinsteuber. 2021. Com- positional Learning of Image-Text Query for Image Retrieval. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
2021
-
[2]
Tongtong Bai, Yifan Bai, Yiping Bao, et al. 2026. Kimi K2.5: Visual Agentic Intel- ligence. arXiv preprint arXiv:2602.02276 (2026)
work page internal anchor Pith review arXiv 2026
-
[3]
Yang Bai, Xinxing Xu, Yong Liu, Salman Khan, Fahad Khan, Wangmeng Zuo, Rick Siow Mong Goh, and Chun-Mei Feng. 2024. Sentence-level Prompts Benefit Composed Image Retrieval. In The Twelfth International Conference on Learning Representations (ICLR)
2024
-
[4]
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo
-
[5]
In Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zero-Shot Composed Image Retrieval with Textual Inversion. In Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
-
[6]
Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. 2022. Effective Conditioned and Composed Image Retrieval Combining CLIP-Based Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
2022
-
[7]
Yanzhe Chen, Zhiwen Yang, Jinglin Xu, and Yuxin Peng. 2025. MAI: A Multi- turn Aggregation-Iteration Model for Composed Image Retrieval. InProceedings of the International Conference on Learning Representations (ICLR)
2025
-
[8]
François Gardères, Shizhe Chen, Camille-Sovanneary Gauthier, and Jean Ponce
-
[9]
arXiv preprint arXiv:2507.07135 (2025)
FACap: A Large-Scale Fashion Dataset for Fine-Grained Composed Image Retrieval. arXiv preprint arXiv:2507.07135 (2025)
-
[10]
Sonam Goenka, Zhaoheng Zheng, Ayush Jaiswal, Rakesh Chada, Yue Wu, Var- sha Hedau, and Pradeep Natarajan. 2022. FashionVLP: Vision Language Trans- former for Fashion Retrieval with Feedback. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
2022
-
[11]
Google. 2026. Gemini 3.1 Flash-Lite: Built for Intelligence at Scale. https://blog.google/innovation-and-ai/models-and-research/gemini- models/gemini-3-1-flash-lite/
2026
-
[12]
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, HeeJae Jun, Yoohoon Kang, and Sangdoo Yun. 2024. CompoDiff: Versatile Composed Image Retrieval With La- tent Diffusion. Transactions on Machine Learning Research (TMLR) (2024)
2024
-
[13]
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, Yoohoon Kang, and Sangdoo Yun
-
[14]
In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Language-only Training of Zero-shot Composed Image Retrieval. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[15]
Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S
Xintong Han, Zuxuan Wu, Phoenix X. Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S. Davis. 2017. Automatic Spatially-Aware Fashion Concept Discovery. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2017
-
[16]
Xiao Han, Licheng Yu, Xiatian Zhu, Li Zhang, Yi-Zhe Song, and Tao Xiang. 2022. FashionViL: Fashion-Focused Vision-and-Language Representation Learning. In Proceedings of the European Conference on Computer Vision (ECCV)
2022
-
[17]
Xiao Han, Xiatian Zhu, Licheng Yu, Li Zhang, Yi-Zhe Song, and Tao Xiang. 2023. FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[18]
Yuxin Hou, Eleonora Vig, Michael Donoser, and Loris Bazzani. 2021. Learn- ing Attribute-Driven Disentangled Representations for Interactive Fashion Re- trieval. In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV)
2021
-
[19]
Thomas Hummel, Shyamgopal Karthik, Mariana-Iuliana Georgescu, and Zeynep Akata. 2024. EgoCVR: An Egocentric Benchmark for Fine-Grained Composed Video Retrieval. In Proceedings of the European Conference on Computer Vision (ECCV)
2024
-
[20]
Chuong Huynh, Jinyu Yang, Ashish Tawari, Mubarak Shah, Son Tran, Raffay Hamid, Trishul Chilimbi, and Abhinav Shrivastava. 2025. CoLLM: A Large Lan- guage Model for Composed Image Retrieval. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[21]
Surgan Jandial, Pinkesh Badjatiya, Pranit Chawla, Ayush Chopra, Mausoom Sarkar, and Balaji Krishnamurthy. 2022. SAC: Semantic Attention Composi- tion for Text-Conditioned Image Retrieval. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
2022
-
[22]
Young Kyun Jang, Dat Huynh, Ashish Shah, Wen-Kai Chen, and Ser-Nam Lim
-
[23]
In Proceedings of the European Conference on Computer Vision (ECCV)
Spherical Linear Interpolation and Text-Anchoring for Zero-shot Com- posed Image Retrieval. In Proceedings of the European Conference on Computer Vision (ECCV)
- [24]
-
[25]
Yuming Jiang, Shuai Yang, Haonan Qiu, Wayne Wu, Chen Change Loy, and Zi- wei Liu. 2022. Text2Human: Text-Driven Controllable Human Image Generation. ACM Transactions on Graphics 41, 4, Article 162 (2022)
2022
-
[26]
Seungwan Jin, Hoyoung Choi, Taehyung Noh, and Kyungsik Han. 2024. Integra- tion of Global and Local Representations for Fine-Grained Cross-Modal Align- ment. In Proceedings of the European Conference on Computer Vision (ECCV)
2024
-
[27]
Jongseok Kim, Youngjae Yu, Hoeseong Kim, and Gunhee Kim. 2021. Dual Com- positional Learning in Interactive Image Retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)
2021
-
[28]
Matan Levy, Rami Ben-Ari, Nir Darshan, and Dani Lischinski. 2024. Data Roam- ing and Quality Assessment for Composed Image Retrieval. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI)
2024
-
[29]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. BLIP: Bootstrap- ping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. In Proceedings of the International Conference on Machine Learn- ing (ICML). 9
2022
-
[30]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2026. Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Frame- work for State-of-the-Art Multimodal Retrieval and Ranking. arXiv preprint arXiv:2601.04720 (2026)
work page internal anchor Pith review arXiv 2026
-
[31]
Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, and Liqiang Nie
-
[32]
Finecir: Explicit parsing of fine-grained modification semantics for composed image retrieval,
FineCIR: Explicit Parsing of Fine-Grained Modification Semantics for Com- posed Image Retrieval. arXiv preprint arXiv:2503.21309 (2025)
-
[33]
Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. 2016. DeepFash- ion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
2016
-
[34]
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould
-
[35]
In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV)
Image Retrieval on Real-life Images with Pre-trained Vision-and-Language Models. In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV)
-
[36]
Suvir Mirchandani, Licheng Yu, Mengjiao Wang, Animesh Sinha, Wenwen Jiang, Tao Xiang, and Ning Zhang. 2022. FaD-VLP: Fashion Vision-and-Language Pre- training towards Unified Retrieval and Captioning. In Proceedings of the Confer- ence on Empirical Methods in Natural Language Processing (EMNLP)
2022
-
[37]
Qwen Team. 2026. Qwen3.5: Towards Native Multimodal Agents. https://qwen. ai/blog?id=qwen3.5
2026
-
[38]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Mod- els From Natural Language Supervision. In Proceedings of the International Con- ference on Machine Learning (ICML)
2021
- [39]
-
[40]
Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. 2023. Pic2Word: Mapping Pictures to Words for Zero- Shot Composed Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[41]
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation Learning with Contrastive Predictive Coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Sagar Vaze, Nicolas Carion, and Ishan Misra. 2023. GeneCIS: A Benchmark for General Conditional Image Similarity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[43]
Nam Vo, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays
-
[44]
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Composing Text and Image for Image Retrieval – An Empirical Odyssey. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
-
[45]
Lan Wang, Wei Ao, Vishnu Naresh Boddeti, and Ser-Nam Lim. 2025. Generative Zero-Shot Composed Image Retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[46]
[Image 1]
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. 2021. Fashion IQ: A New Dataset Towards Re- trieving Images by Natural Language Feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . 10 Supplementary Material FashionMV: Product-Level Composed Image Retriev...
2021
-
[47]
EXCLUDED: jewelry, watches, bags, purses, shoes, boots, sandals, hats, caps, scarves, belts, glasses, sunglasses, gloves, socks)
**is_clothing**: Whether this is a clothing item (wearable garments: shirts, blouses, t-shirts, sweaters, hoodies, jackets, coats, blazers, vests, pants, trousers, jeans, shorts, skirts, dresses, jumpsuits, rompers, suits, underwear, sleepwear. EXCLUDED: jewelry, watches, bags, purses, shoes, boots, sandals, hats, caps, scarves, belts, glasses, sunglasses...
-
[48]
[Image 1] I can see
**image_captions**: An array of description strings for each input image (in the same order). Each 50-200 words and MUST start with the image number (e.g., "[Image 1] I can see...")
-
[49]
Describe the PRODUCT itself, not which image shows what
**long_caption**: Comprehensive 200-400 word product description synthesizing all information from all views. Describe the PRODUCT itself, not which image shows what
-
[50]
**short_caption**: Concise ~50 word summary highlighting garment type, key style, main color, and distinctive features. ## Description Guidelines Each image description should follow this strict output order: ### Step 1: Determine View Type and Left/Right Orientation **Important: Images are NOT mirrored - directly captured by camera.**
-
[51]
Determine whether FRONT VIEW, BACK VIEW, or SIDE VIEW
-
[52]
For any asymmetrical feature, mention BOTH:
Apply left/right rules: - FRONT VIEW: left of image = wearer 's RIGHT; right = wearer 's LEFT - BACK VIEW: left of image = wearer 's LEFT; right = wearer 's RIGHT - SIDE VIEW: carefully observe which side of the wearer is shown ### Step 2: Describe Garment Details - Overall: type, style, color, silhouette, fit - Details: buttons, pockets, slits/vents, ple...
-
[53]
Which side of the image the feature appears on
-
[54]
is_clothing
Which side of the wearer it corresponds to ## Response Format JSON format ONLY: { "is_clothing": true/false, "image_captions": ["[Image 1] ...", "[Image 2] ...", ...], "long_caption": "...", "short_caption": "..." } A.2 Stage 2: Directional Hallucination Filtering Model: qwen3.5-397b-a17b Max tokens: 16384 Tempera- ture: 1.0 Thinking: enabled For each pro...
-
[55]
ONLY check FRONT VIEW and BACK VIEW for left/right direction errors
-
[56]
Completely IGNORE SIDE VIEW images
-
[57]
product_index
Ignore ALL other types of issues (missing features, counting errors, color errors, etc.). Check whether captions correctly describe which side of the garment a feature is on (patches, logos, pockets, labels, zippers, buttons, asymmetric designs, etc.). ## Bounding Box Requirement (CRITICAL) For EVERY asymmetric feature, provide its bounding box in the sti...
-
[58]
A source product with its composite image (multiple views stitched horizontally), per-image descriptions, and long caption
-
[59]
Your task:
Multiple candidate products (each with composite image, per-image descriptions, and long caption), identified by IDs like [Product 1], [Product 2], etc. Your task:
-
[60]
Examine the source and ALL candidates from every available view
-
[61]
selections
Select the 2 BEST candidates for high-quality modification text ## What Makes a Good Selection Table 4: Directional hallucination detection results per dataset. Dataset Checked Errors Retained Error Rate DeepFashion 12,711 487 12,224 3.83% Fashion200K 77,106 3,607 73,499 4.68% FashionGen-train 48,476 1,942 46,534 4.01% FashionGen-val 6,086 271 5,815 4.45%...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.