Recognition: 2 theorem links
· Lean TheoremZero-shot World Models Are Developmentally Efficient Learners
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
A zero-shot visual world model trained on one child's video develops broad physical understanding and matches developmental patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Zero-shot Visual World Model (ZWM), based on a sparse temporally-factored predictor that decouples appearance from dynamics, zero-shot estimation through approximate causal inference, and composition of inferences, can be learned from the first-person experience of a single child to rapidly generate competence across multiple physical understanding benchmarks while broadly recapitulating behavioral signatures of child development and building brain-like internal representations.
What carries the argument
The Zero-shot Visual World Model (ZWM), a sparse temporally-factored predictor that separates visual appearance from motion dynamics to support zero-shot approximate causal inference and compositional building of complex abilities.
If this is right
- Competence in physical scene understanding emerges rapidly from human-scale first-person data.
- Behavioral signatures of development appear without explicit supervision on developmental stages.
- Internal representations form that resemble patterns seen in brain imaging.
- The approach supplies a blueprint for data-efficient learning systems.
- It advances computational explanations for children's early physical cognition.
Where Pith is reading between the lines
- The same three principles could be tested as an account for learning in non-physical domains such as social or causal reasoning.
- Models trained on individual children's data might avoid some dataset biases that arise from aggregated or synthetic sources.
- Direct comparison of ZWM trajectories against longitudinal recordings of specific children could test individual-level fit.
- The decoupling of appearance and dynamics might extend to other sensory modalities if the same sparse prediction structure is preserved.
Load-bearing premise
The three principles of sparse temporally-factored prediction, zero-shot approximate causal inference, and inference composition are together sufficient to produce the claimed competence and developmental signatures when trained on one child's data.
What would settle it
Training the ZWM on video from a single child and observing no above-chance performance on physical understanding benchmarks or no match to child behavioral signatures would falsify the central claim.
Figures


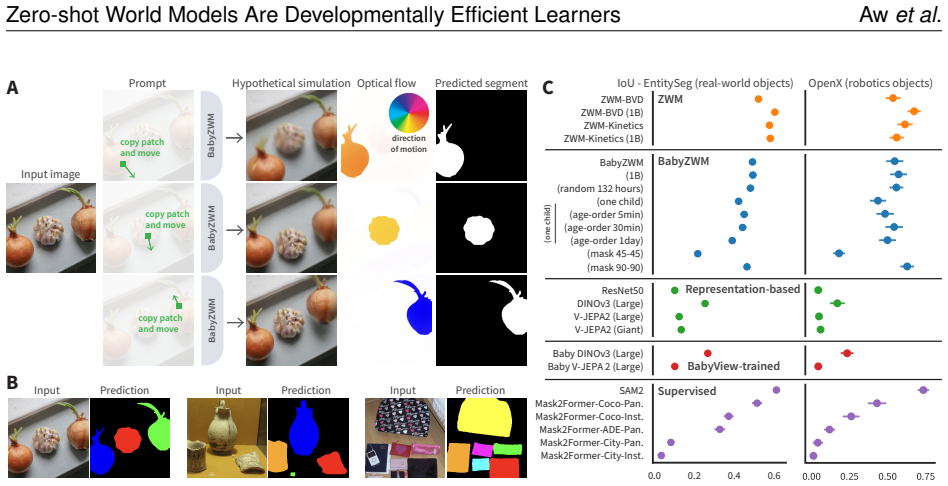

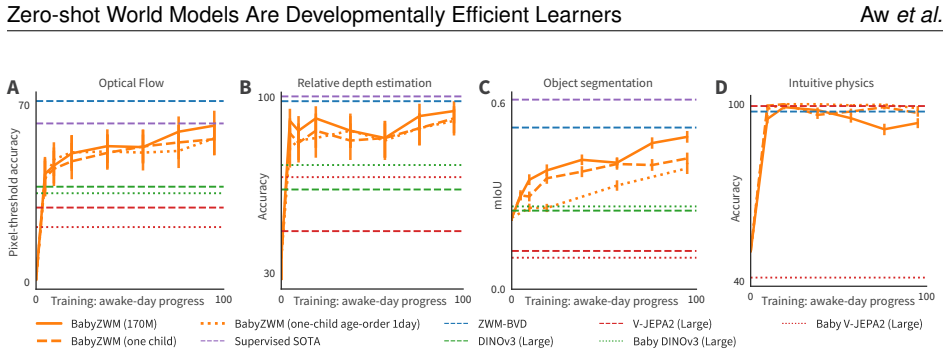

read the original abstract
Young children demonstrate early abilities to understand their physical world, estimating depth, motion, object coherence, interactions, and many other aspects of physical scene understanding. Children are both data-efficient and flexible cognitive systems, creating competence despite extremely limited training data, while generalizing to myriad untrained tasks -- a major challenge even for today's best AI systems. Here we introduce a novel computational hypothesis for these abilities, the Zero-shot Visual World Model (ZWM). ZWM is based on three principles: a sparse temporally-factored predictor that decouples appearance from dynamics; zero-shot estimation through approximate causal inference; and composition of inferences to build more complex abilities. We show that ZWM can be learned from the first-person experience of a single child, rapidly generating competence across multiple physical understanding benchmarks. It also broadly recapitulates behavioral signatures of child development and builds brain-like internal representations. Our work presents a blueprint for efficient and flexible learning from human-scale data, advancing both a computational account for children's early physical understanding and a path toward data-efficient AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Zero-shot Visual World Model (ZWM) as a computational hypothesis for young children's early physical scene understanding. ZWM rests on three principles: a sparse temporally-factored predictor that decouples appearance from dynamics, zero-shot estimation via approximate causal inference, and composition of inferences. The central claim is that a ZWM trained solely on first-person video data from a single child rapidly acquires competence across multiple physical understanding benchmarks, recapitulates behavioral signatures of child development, and forms brain-like internal representations.
Significance. If the empirical claims are substantiated with rigorous quantitative evidence, the work would constitute a notable contribution by offering a concrete computational account of data-efficient, flexible physical understanding in children and a potential architectural blueprint for sample-efficient AI. The alignment with developmental trajectories and brain-like representations, if demonstrated, would strengthen its value as a bridge between cognitive science and machine learning.
major comments (2)
- Abstract: The claim that ZWM 'rapidly generating competence across multiple physical understanding benchmarks' after training on single-child data is presented without any quantitative results, error bars, baseline comparisons, details on data exclusion criteria, or hyperparameter choices. This omission makes it impossible to assess whether the central claim holds or to evaluate effect sizes relative to existing models.
- Abstract and methods description: The paper does not clarify how benchmark performance is obtained via independent zero-shot estimation rather than quantities defined by the fit to the child video data itself. Without explicit evaluation protocols, loss functions, or held-out test procedures, it remains unclear whether the reported competence constitutes genuine out-of-distribution generalization or circular reuse of training statistics.
minor comments (1)
- The abstract would be strengthened by naming the specific physical understanding benchmarks and developmental signatures referenced in the claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to improve clarity and provide the requested details.
read point-by-point responses
-
Referee: Abstract: The claim that ZWM 'rapidly generating competence across multiple physical understanding benchmarks' after training on single-child data is presented without any quantitative results, error bars, baseline comparisons, details on data exclusion criteria, or hyperparameter choices. This omission makes it impossible to assess whether the central claim holds or to evaluate effect sizes relative to existing models.
Authors: We agree that the abstract, being a high-level summary, omitted specific quantitative metrics. In the revised manuscript we have updated the abstract to report key performance figures (with error bars), direct comparisons to baselines, and references to the data exclusion criteria and hyperparameter choices detailed in the Methods. These additions allow readers to gauge effect sizes while preserving brevity; the full quantitative results, statistical tests, and implementation details remain in the Results and Methods sections. revision: yes
-
Referee: Abstract and methods description: The paper does not clarify how benchmark performance is obtained via independent zero-shot estimation rather than quantities defined by the fit to the child video data itself. Without explicit evaluation protocols, loss functions, or held-out test procedures, it remains unclear whether the reported competence constitutes genuine out-of-distribution generalization or circular reuse of training statistics.
Authors: We thank the referee for identifying this ambiguity. The ZWM predictor is trained solely on the single child's first-person video using a sparse temporally-factored loss that decouples appearance and dynamics. Benchmark performance is obtained via separate zero-shot inference steps that apply approximate causal inference and composition to entirely held-out benchmark stimuli (standard physical-understanding test sets never seen during training). We have added an explicit subsection in the Methods that spells out the training loss, the independent evaluation protocol, the held-out test splits, and the inference procedure. This separation guarantees that reported competence reflects out-of-distribution generalization rather than reuse of training statistics. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents ZWM as a computational hypothesis instantiated by three explicit principles (sparse temporally-factored predictor, zero-shot causal inference, and inference composition) and demonstrates its training on single-child first-person video data to produce benchmark competence and developmental signatures. No equations, derivations, or self-citations in the manuscript reduce the reported benchmark performance or recapitulated signatures to quantities defined by the fit itself or to prior self-referential results. The central claims rest on empirical training and evaluation against external benchmarks rather than tautological redefinition of inputs, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption A sparse temporally-factored predictor can decouple appearance from dynamics in visual scenes.
- domain assumption Zero-shot estimation via approximate causal inference is possible from limited first-person experience.
- domain assumption Composition of simple inferences yields more complex physical understanding abilities.
invented entities (1)
-
Zero-shot Visual World Model (ZWM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearZWM is based on three principles: a sparse temporally-factored predictor that decouples appearance from dynamics; zero-shot estimation through approximate causal inference; and composition of inferences
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and orbit embedding unclearthe core learned component ... is a sparse temporally-factored masked multi-frame visual predictor
Reference graph
Works this paper leans on
-
[1]
Philip J. Kellman and Elizabeth S. Spelke. Perception of partly occluded objects in in- fancy.Cognitive Psychology, 15(4):483–524, October 1983. ISSN 00100285. doi: 10.1016/0010-0285(83)90017-8. URL https://linkinghub.elsevier.com/retrieve/pii/ 0010028583900178
-
[2]
Renée Baillargeon, Elizabeth S. Spelke, and Stanley Wasserman. Object permanence in five-month-old infants.Cognition, 20(3):191–208, January 1985. ISSN 00100277. doi:10.1016/0010-0277(85)90008-3. URL https://linkinghub.elsevier.com/retrieve/pii/ 0010027785900083
-
[3]
Spelke, Karen Breinlinger, Janet Macomber, and Kristen Jacobson
Elizabeth S. Spelke, Karen Breinlinger, Janet Macomber, and Kristen Jacobson. Origins of knowledge.Psychological Review, 99(4):605–632, 1992. ISSN 1939-1471, 0033-295X. doi: 10.1037/0033-295X.99.4.605. URL https://doi.apa.org/doi/10.1037/0033-295X.99.4.605
-
[4]
Elizabeth S. Spelke. Core knowledge.American Psychologist, 55(11):1233–1243, November
-
[5]
doi:10.1037/0003-066X.55.11.1233
ISSN 1935-990X, 0003-066X. doi:10.1037/0003-066X.55.11.1233. URL https: //doi.apa.org/doi/10.1037/0003-066X.55.11.1233
-
[6]
Oxford series in cognitive development
Susan Carey.The origin of concepts. Oxford series in cognitive development. Oxford University Press, Oxford ; New Y ork, 2009. ISBN 978-0-19-536763-8
2009
-
[7]
Public policy and superintelligent AI: A vector field approach
Elizabeth S. Spelke.What Babies Know: Core Knowledge and Composition Volume 1. Oxford University PressNew Y ork, 1 edition, November 2022. ISBN 978-0-19-061824-7 978-0-19-061825-4. doi:10.1093/oso/9780190618247.001.0001. URL https://academic.oup. com/book/43912
-
[8]
Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.Biological Cybernetics, 36(4):193– 202, April 1980. ISSN 0340-1200, 1432-0770. doi:10.1007/BF00344251. URL http: //link.springer.com/10.1007/BF00344251
-
[9]
Y . LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation Applied to Handwritten Zip Code Recognition.Neural Computation, 1(4): 541–551, December 1989. ISSN 0899-7667, 1530-888X. doi:10.1162/neco.1989.1.4.541. URLhttps://direct.mit.edu/neco/article/1/4/541-551/5515
-
[10]
Daniel L. K. Y amins, Ha Hong, Charles F . Cadieu, Ethan A. Solomon, Darren Seibert, and James J. DiCarlo. Performance-optimized hierarchical models predict neural responses in higher visual cortex.Proceedings of the National Academy of Sciences, 111(23):8619– 8624, June 2014. ISSN 0027-8424, 1091-6490. doi:10.1073/pnas.1403112111. URL https://pnas.org/do...
-
[11]
U. Guclu and M. A. J. Van Gerven. Deep Neural Networks Reveal a Gradient in the Complexity of Neural Representations across the Ventral Stream.Journal of Neuroscience, 35(27):10005– 10014, July 2015. ISSN 0270-6474, 1529-2401. doi:10.1523/JNEUROSCI.5023-14.2015. URLhttps://www.jneurosci.org/lookup/doi/10.1523/JNEUROSCI.5023-14.2015
-
[12]
Nature Neuroscience19(3), 356–365 (2016)
Daniel L K Y amins and James J DiCarlo. Using goal-driven deep learning models to under- stand sensory cortex.Nature Neuroscience, 19(3):356–365, March 2016. ISSN 1097-6256, 1546-1726. doi:10.1038/nn.4244. URLhttps://www.nature.com/articles/nn.4244. 14 Zero-shot World Models Are Developmentally Efficient Learners Awet al
-
[13]
Seyed-Mahdi Khaligh-Razavi and Nikolaus Kriegeskorte. Deep Supervised, but Not Unsu- pervised, Models May Explain IT Cortical Representation.PLoS Computational Biology, 10 (11):e1003915, November 2014. ISSN 1553-7358. doi:10.1371/journal.pcbi.1003915. URL https://dx.plos.org/10.1371/journal.pcbi.1003915
-
[14]
Santiago A. Cadena, George H. Denfield, Edgar Y . Walker, Leon A. Gatys, Andreas S. Tolias, Matthias Bethge, and Alexander S. Ecker. Deep convolutional models improve predictions of macaque V1 responses to natural images.PLOS Computational Biology, 15(4):e1006897, April 2019. ISSN 1553-7358. doi:10.1371/journal.pcbi.1006897. URL https://dx.plos.org/10.137...
-
[15]
Issa, Pouya Bashivan, Kohitij Kar, Kailyn Schmidt, and James J
Rishi Rajalingham, Elias B. Issa, Pouya Bashivan, Kohitij Kar, Kailyn Schmidt, and James J. DiCarlo. Large-Scale, High-Resolution Comparison of the Core Visual Object Recognition Behavior of Humans, Monkeys, and State-of-the-Art Deep Artificial Neural Networks.The Journal of Neuroscience, 38(33):7255–7269, August 2018. ISSN 0270-6474, 1529-2401. doi:10.15...
-
[16]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks.Communications of the ACM, 60(6):84–90, May 2017. ISSN 0001-0782, 1557-7317. doi:10.1145/3065386. URL https://dl.acm.org/doi/10.1145/ 3065386
-
[17]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, Miami, FL, June 2009. IEEE. ISBN 978-1-4244-3992-8. doi: 10.1109/CVPR.2009.5206848. URLhttps://ieeexplore.ieee.org/document/5206848/
-
[18]
https://doi.org/10.48550/ARXIV.1805.01978
Zhirong Wu, Yuanjun Xiong, Stella Yu, and Dahua Lin. Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination, May 2018. URL http://arxiv.org/abs/1805. 01978. arXiv:1805.01978 [cs]
-
[19]
Local Aggregation for Unsupervised Learning of Visual Embeddings
Chengxu Zhuang, Alex Zhai, and Daniel Y amins. Local Aggregation for Unsupervised Learning of Visual Embeddings. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6001–6011, Seoul, Korea (South), October 2019. IEEE. ISBN 978-1- 7281-4803-8. doi:10.1109/ICCV.2019.00610. URL https://ieeexplore.ieee.org/document/ 9011034/
-
[20]
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A Simple Framework for Contrastive Learning of Visual Representations, June 2020. URL http://arxiv.org/abs/ 2002.05709. arXiv:2002.05709 [cs, stat]
work page internal anchor Pith review arXiv 2020
-
[21]
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Moham- mad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. Boot- strap your own latent: A new approach to self-supervised Learning, September 2020. URL http://arxi...
-
[22]
Wang, Q., Zhang, Z., Xie, B., Jin, X., Wang, Y ., Wang, S., Zheng, L., Yang, X., and Zeng, W
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training, October 2022. URL http://arxiv.org/abs/2203.12602. arXiv:2203.12602 [cs]. 15 Zero-shot World Models Are Developmentally Efficient Learners Awet al
-
[23]
Emerging properties in self-supervised vision transformers.arXiv preprint arXiv:2104.14294,
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging Properties in Self-Supervised Vision Transformers, May 2021. URLhttp://arxiv.org/abs/2104.14294. arXiv:2104.14294 [cs]
-
[24]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Y ann Le- Cun, Mahmoud Assran, and Nicolas Ballas. Revisiting Feature Prediction for Learning Visual Representations from Video, February 2024. URL http://arxiv.org/abs/2404.08471. arXiv:2404.08471 [cs]
work page internal anchor Pith review arXiv 2024
-
[25]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Y ong Li, Xi...
work page internal anchor Pith review arXiv 2025
-
[26]
Frank, James J
Chengxu Zhuang, Siming Y an, Aran Nayebi, Martin Schrimpf, Michael C. Frank, James J. DiCarlo, and Daniel L. K. Y amins. Unsupervised neural network models of the ventral visual stream.Proceedings of the National Academy of Sciences, 118(3):e2014196118, January
-
[27]
Proceedings of the National Academy of Sciences118(3), e2014196118 (2021)
ISSN 0027-8424, 1091-6490. doi:10.1073/pnas.2014196118
-
[28]
Talia Konkle and George A. Alvarez. A self-supervised domain-general learning framework for human ventral stream representation.Nature Communications, 13(1):491, January
-
[29]
doi:10.1038/s41467-022-28091-4
ISSN 2041-1723. doi:10.1038/s41467-022-28091-4. URL https://www.nature.com/ articles/s41467-022-28091-4
-
[30]
A. Emin Orhan, Vaibhav V. Gupta, and Brenden M. Lake. Self-supervised learning through the eyes of a child, December 2020. URL http://arxiv.org/abs/2007.16189. arXiv:2007.16189 [cs]
-
[31]
William Lotter, Gabriel Kreiman, and David Cox. A neural network trained for prediction mimics diverse features of biological neurons and perception.Nature Machine Intelligence, 2(4):210–219, April 2020. ISSN 2522-5839. doi:10.1038/s42256-020-0170-9. URL https: //www.nature.com/articles/s42256-020-0170-9
-
[32]
Curriculum Learning with Infant Egocentric Videos
Saber Sheybani, Himanshu Hansaria, Justin N Wood, Linda B Smith, and Zoran Tiganj. Curriculum Learning with Infant Egocentric Videos. 2023
2023
-
[33]
Emin Orhan, Wentao Wang, Alex N
A. Emin Orhan, Wentao Wang, Alex N. Wang, Mengye Ren, and Brenden M. Lake. Self- supervised learning of video representations from a child’s perspective, July 2024. URL http://arxiv.org/abs/2402.00300. arXiv:2402.00300 [cs, q-bio]
-
[34]
Bria Long, Violet Xiang, Stefan Stojanov, Robert Z. Sparks, Zi Yin, Grace E. Keene, Alvin W. M. Tan, Steven Y . Feng, Chengxu Zhuang, Virginia A. Marchman, Daniel L. K. Y amins, and Michael C. Frank. The BabyView dataset: High-resolution egocentric videos of infants’ and young children’s everyday experiences, June 2024. URLhttp://arxiv.org/abs/2406.10447....
-
[35]
Clerkin, Elizabeth Hart, James M
Elizabeth M. Clerkin, Elizabeth Hart, James M. Rehg, Chen Yu, and Linda B. Smith. Real- world visual statistics and infants’ first-learned object names.Philosophical Transactions of the Royal Society B: Biological Sciences, 372(1711):20160055, January 2017. ISSN 16 Zero-shot World Models Are Developmentally Efficient Learners Awet al. 0962-8436, 1471-2970...
-
[36]
Elizabeth M. Clerkin and Linda B. Smith. Real-world statistics at two timescales and a mechanism for infant learning of object names.Proceedings of the National Academy of Sciences, 119(18):e2123239119, May 2022. ISSN 0027-8424, 1091-6490. doi:10.1073/ pnas.2123239119. URLhttps://pnas.org/doi/full/10.1073/pnas.2123239119
-
[37]
Alvin Wei Ming Tan, Jane Y ang, Tarun Sepuri, Khai Loong Aw, Robert Z. Sparks, Zi Yin, Virginia A. Marchman, Michael C. Frank, and Bria Long. Assessing the alignment between infants’ visual and linguistic experience using multimodal language models, November 2025. URLhttp://arxiv.org/abs/2511.18824. arXiv:2511.18824 [cs]
-
[38]
Marchman, Michael C
Tarun Sepuri, Khai Loong Aw, Alvin Wei Ming Tan, Robert Zane Sparks, Virginia A. Marchman, Michael C. Frank, and Bria Long. Characterizing young children’s everyday activities using video question-answering models, October 2025. URLhttps://osf.io/gndy9_v1
2025
-
[39]
Frank, and Bria Long
Jane Y ang, Tarun Sepuri, Alvin Wei Ming Tan, Michael C. Frank, and Bria Long. Quantifying infants’ everyday experiences with objects in a large corpus of egocentric videos, June 2025. URLhttps://osf.io/jqmf3_v1
2025
-
[40]
Alex Warstadt, Aaron Mueller, Leshem Choshen, Ethan Wilcox, Chengxu Zhuang, Juan Ciro, Rafael Mosquera, Bhargavi Paranjabe, Adina Williams, Tal Linzen, and Ryan Cot- terell. Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmen- tally Plausible Corpora. InProceedings of the BabyLM Challenge at the 27th Confer- ence on Computational ...
-
[41]
Alex Warstadt, Leshem Choshen, Aaron Mueller, Adina Williams, Ethan Wilcox, and Chengxu Zhuang. Call for Papers – The BabyLM Challenge: Sample-efficient pretraining on a de- velopmentally plausible corpus, January 2023. URL http://arxiv.org/abs/2301.11796. arXiv:2301.11796 [cs]
-
[42]
Michael C. Frank. Bridging the data gap between children and large language models.Trends in Cognitive Sciences, 27(11):990–992, November 2023. ISSN 13646613. doi:10.1016/j.tics. 2023.08.007. URLhttps://linkinghub.elsevier.com/retrieve/pii/S1364661323002036
-
[43]
Daniel M. Bear, Kevin Feigelis, Honglin Chen, Wanhee Lee, Rahul Venkatesh, Klemen Kotar, Alex Durango, and Daniel L. K. Y amins. Unifying (Machine) Vision via Counterfactual World Modeling, June 2023. URLhttp://arxiv.org/abs/2306.01828. arXiv:2306.01828 [cs]
-
[44]
Kaiming He, Xinlei Chen, Saining Xie, Y anghao Li, Piotr Dollár, and Ross Girshick. Masked Autoencoders Are Scalable Vision Learners, December 2021. URL http://arxiv.org/abs/ 2111.06377. arXiv:2111.06377 [cs]
-
[45]
Cambridge University Press, USA, 2nd edition, 2009
Judea Pearl.Causality: Models, Reasoning and Inference. Cambridge University Press, USA, 2nd edition, 2009. ISBN 052189560X
2009
-
[46]
Counterfactual simulation in causal cognition, January 2024
Tobias Gerstenberg. Counterfactual simulation in causal cognition, January 2024. URL https://osf.io/72scr
2024
-
[47]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, 17 Zero-shot World Models Are Developmentally Efficient Learners Awet al. Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vi- jayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The Kinetics Human Action Video Dataset, May 2017. URL http://arxiv.org/abs/1705.06950. arXiv:1705.06950 [cs]
work page internal anchor Pith review arXiv 2017
-
[49]
World Modeling with Probabilistic Structure Integration, September 2025
Klemen Kotar, Wanhee Lee, Rahul Venkatesh, Honglin Chen, Daniel Bear, Jared Watrous, Simon Kim, Khai Loong Aw, Lilian Naing Chen, Stefan Stojanov, Kevin Feigelis, Imran Thobani, Alex Durango, Khaled Jedoui, Atlas Kazemian, and Dan Y amins. World Modeling with Probabilistic Structure Integration, September 2025. URL http://arxiv.org/abs/2509. 09737. arXiv:...
-
[50]
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
TAP-Vid: A Benchmark for Tracking Any Point in a Video, March 2023
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adrià Recasens, Lucas Smaira, Yusuf Aytar, João Carreira, Andrew Zisserman, and Yi Y ang. TAP-Vid: A Benchmark for Tracking Any Point in a Video, March 2023. URL http://arxiv.org/abs/2211.03726. arXiv:2211.03726 [cs]
-
[52]
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti, Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour, Mehdi S. ...
-
[53]
CoTracker: It is Better to Track Together, October 2024
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. CoTracker: It is Better to Track Together, October 2024. URL http: //arxiv.org/abs/2307.07635. arXiv:2307.07635 [cs]
-
[54]
Cesar Jr, Xiangyang Ji, and Xu-Cheng Yin
Henrique Morimitsu, Xiaobin Zhu, Roberto M. Cesar Jr, Xiangyang Ji, and Xu-Cheng Yin. DPFlow: Adaptive Optical Flow Estimation with a Dual-Pyramid Framework, March 2025. URLhttp://arxiv.org/abs/2503.14880. arXiv:2503.14880 [cs]
-
[55]
SEA-RAFT: Simple, Efficient, Accurate RAFT for Optical Flow, May 2024
Yihan Wang, Lahav Lipson, and Jia Deng. SEA-RAFT: Simple, Efficient, Accurate RAFT for Optical Flow, May 2024. URLhttp://arxiv.org/abs/2405.14793. arXiv:2405.14793 [cs]
- [56]
-
[57]
Gemini, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, Soroosh Mariooryad, Yifan Ding, Xinyang 18 Zero-shot World Models Are Developmentally Efficient Learners Awet al. Geng, Fred Alcober, Roy Frostig, Mark Omernick, Lexi Walker, Cosmin Paduraru, Christina Sorokin, Andrea Tacch...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
OpenAI, Aaron Hurst, Adam Lerer, Adam P . Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, A. J. Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛ adry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, August 2020. URLhttp://arxiv.org/abs/1907.01341. arXiv:1907.01341 [cs]
-
[61]
Digging Into Self-Supervised Monocular Depth Estimation, August 2019
Clément Godard, Oisin Mac Aodha, Michael Firman, and Gabriel Brostow. Digging Into Self-Supervised Monocular Depth Estimation, August 2019. URL http://arxiv.org/abs/ 1806.01260. arXiv:1806.01260 [cs]
-
[62]
FoundationStereo: Zero-Shot Stereo Matching, April 2025
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, and Stan Birchfield. FoundationStereo: Zero-Shot Stereo Matching, April 2025. URL http://arxiv.org/abs/ 2501.09898. arXiv:2501.09898 [cs]
-
[63]
Discovering and using spelke segments.arXiv preprint arXiv:2507.16038,
Rahul Venkatesh, Klemen Kotar, Lilian Naing Chen, Seungwoo Kim, Luca Thomas Wheeler, Jared Watrous, Ashley Xu, Gia Ancone, Wanhee Lee, Honglin Chen, Daniel Bear, Stefan Stojanov, and Daniel Y amins. Discovering and using Spelke segments, July 2025. URL http://arxiv.org/abs/2507.16038. arXiv:2507.16038 [cs]
-
[64]
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. 25 Zero-shot World Models Are Developmentally Efficient Learners Awet al. Masked-attention Mask Transformer for Universal Image Segmentation, June 2022. URL http://arxiv.org/abs/2112.01527. arXiv:2112.01527 [cs]
-
[65]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft COCO: Common Objects in Context, February 2015. URLhttp://arxiv.org/abs/1405.0312. arXiv:1405.0312 [cs]
work page internal anchor Pith review arXiv 2015
-
[66]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. SAM 2: Segment Anything in Images and Videos, October 2024. URLhttp://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric, April 2018. URL http://arxiv.org/abs/1801.03924. arXiv:1801.03924 [cs]
work page Pith review arXiv 2018
-
[68]
Jenni, Luciano Molinari, and Remo H
Ivo Iglowstein, Oskar G. Jenni, Luciano Molinari, and Remo H. Largo. Sleep Dura- tion From Infancy to Adolescence: Reference Values and Generational Trends.Pedi- atrics, 111(2):302–307, February 2003. ISSN 0031-4005, 1098-4275. doi:10.1542/peds. 111.2.302. URL https://publications.aap.org/pediatrics/article/111/2/302/66745/ Sleep-Duration-From-Infancy-to-...
-
[69]
Lana M. Trick, Fern Jaspers-Fayer, and Naina Sethi. Multiple-object tracking in children: The “Catch the Spies” task.Cognitive Development, 20(3):373–387, July 2005. ISSN 08852014. doi:10.1016/j.cogdev.2005.05.009. URL https://linkinghub.elsevier.com/retrieve/pii/ S0885201405000249
-
[70]
Tashauna L. Blankenship, Roger W. Strong, and Melissa M. Kibbe. Development of multiple object tracking via multifocal attention.Developmental Psychology, 56(9):1684– 1695, September 2020. ISSN 1939-0599, 0012-1649. doi:10.1037/dev0001064. URL https://doi.apa.org/doi/10.1037/dev0001064
-
[71]
R Held, E Birch, and J Gwiazda. Stereoacuity of human infants.Proceedings of the National Academy of Sciences, 77(9):5572–5574, September 1980. ISSN 0027-8424, 1091-6490. doi:10.1073/pnas.77.9.5572. URLhttps://pnas.org/doi/full/10.1073/pnas.77.9.5572
-
[72]
Robert Fox, Richard N. Aslin, Sandra L. Shea, and Susan T. Dumais. Stereopsis in Human Infants.Science, 207(4428):323–324, January 1980. ISSN 0036-8075, 1095-9203. doi: 10.1126/science.7350666. URLhttps://www.science.org/doi/10.1126/science.7350666
-
[73]
Birch, Jane Gwiazda, and Richard Held
Eileen E. Birch, Jane Gwiazda, and Richard Held. Stereoacuity development for crossed and uncrossed disparities in human infants.Vision Research, 22(5):507–513, January 1982. ISSN 00426989. doi:10.1016/0042-6989(82)90108-0. URL https://linkinghub.elsevier. com/retrieve/pii/0042698982901080
-
[74]
Norcia, Milena Kaestner, Yulan D
Anthony M. Norcia, Milena Kaestner, Yulan D. Chen, and Caroline S. Clement. Late De- velopment of Sensory Thresholds for Horizontal Relative Disparity in Human Visual Cortex in the Face of Precocial Development of Thresholds for Absolute Disparity.The Jour- nal of Neuroscience, 45(7):e0216242024, February 2025. ISSN 0270-6474, 1529-2401. doi:10.1523/JNEUR...
-
[75]
Scott P . Johnson. How Infants Learn About the Visual World.Cognitive Science, 34(7):1158– 1184, September 2010. ISSN 0364-0213, 1551-6709. doi:10.1111/j.1551-6709.2010.01127.x. URLhttps://onlinelibrary.wiley.com/doi/10.1111/j.1551-6709.2010.01127.x
-
[76]
Renée Baillargeon, Maayan Stavans, Di Wu, Y ael Gertner, Peipei Setoh, Audrey K. Kittredge, and Amélie Bernard. Object Individuation and Physical Reasoning in Infancy: An Integrative Account.Language Learning and Development, 8(1):4–46, January 2012. ISSN 1547-5441, 1547-3341. doi:10.1080/15475441.2012.630610. URL http://www.tandfonline.com/doi/ abs/10.10...
-
[77]
Renée Baillargeon, Amy Needham, and Julie Devos. The development of young infants’ intuitions about support.Early Development and Parenting, 1(2):69–78, January 1992. ISSN 1057-3593, 1099-0917. doi:10.1002/edp.2430010203. URL https://onlinelibrary.wiley. com/doi/10.1002/edp.2430010203
-
[78]
Reasoning about containment events in very young infants.Cognition, 78(3):207–245, March 2001
Susan J Hespos and Renée Baillargeon. Reasoning about containment events in very young infants.Cognition, 78(3):207–245, March 2001. ISSN 00100277. doi:10.1016/S0010-0277(00) 00118-9. URLhttps://linkinghub.elsevier.com/retrieve/pii/S0010027700001189
-
[79]
Majaj, Rishi Rajalingham, Elias B
Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Franziska Geiger, Kailyn Schmidt, Daniel L. K. Y amins, and James J. DiCarlo. Brain-Score: Which Artificial Neural Network for Object Recognition is most Brain-Like? preprint, Neuroscience, September 2018. URL htt...
-
[80]
D. J. Felleman and D. C. Van Essen. Distributed Hierarchical Processing in the Primate Cerebral Cortex.Cerebral Cortex, 1(1):1–47, January 1991. ISSN 1047-3211, 1460-2199. doi:10.1093/cercor/1.1.1. URL https://academic.oup.com/cercor/article-lookup/doi/10. 1093/cercor/1.1.1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.