Recognition: unknown
Point2Pose: Occlusion-Recovering 6D Pose Tracking and 3D Reconstruction for Multiple Unknown Objects Via 2D Point Trackers
Pith reviewed 2026-05-10 16:06 UTC · model grok-4.3
The pith
Point2Pose tracks 6D poses of multiple unknown rigid objects from RGB-D video by using 2D point trackers to recover from complete occlusions while building live 3D models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
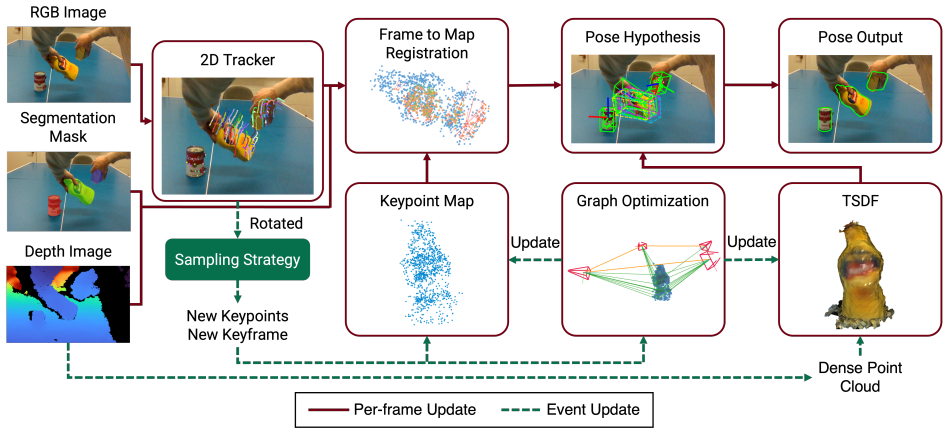
Point2Pose performs causal 6D pose tracking and incremental TSDF reconstruction for multiple previously unseen rigid objects by feeding long-range correspondences from a 2D point tracker into an optimization that aligns the online surface model to the current depth observations, allowing immediate recovery after full occlusions without CAD models or category priors.
What carries the argument
The coupling of a 2D point tracker that maintains long-range correspondences across occlusions with an online TSDF volume that is updated and aligned to current depth data for multi-object pose optimization.
If this is right
- Multiple objects can be tracked at once within a single monocular RGB-D sequence.
- Tracking resumes instantly when a fully occluded object becomes visible again.
- Performance on severe-occlusion benchmarks matches prior single-object methods while adding multi-object and recovery features.
- 3D surface models are built incrementally without any pre-existing object meshes.
Where Pith is reading between the lines
- Further improvements in the underlying point tracker could extend reliable tracking to longer occlusions or faster object motions.
- The live TSDF volumes could feed directly into robotic manipulation planners for grasping previously unknown items.
- The same correspondence-driven pipeline might adapt to moving cameras if the point tracker is made invariant to ego-motion.
Load-bearing premise
The 2D point tracker must continue to supply reliable long-range point matches even after complete object occlusion, and every tracked object must stay rigid.
What would settle it
A video sequence in which an object is fully occluded for many frames and the 2D point tracker supplies no valid correspondences upon reappearance, causing the pose estimate to lose lock.
Figures



read the original abstract
We present Point2Pose, a model-free method for causal 6D pose tracking of multiple rigid objects from monocular RGB-D video. Initialized only from sparse image points on the objects to be tracked, our approach tracks multiple unseen objects without requiring object CAD models or category priors. Point2Pose leverages a 2D point tracker to obtain long-range correspondences, enabling instant recovery after complete occlusion. Simultaneously, the system incrementally reconstructs an online Truncated Signed Distance Function (TSDF) representation of the tracked targets. Alongside the method, we introduce a new multi-object tracking dataset comprising both simulation and real-world sequences, with motion-capture ground truth for evaluation. Experiments show that Point2Pose achieves performance comparable to the state-of-the-art methods on a severe-occlusion benchmark, while additionally supporting multi-object tracking and recovery from complete occlusion, capabilities that are not supported by previous model-free tracking approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Point2Pose, a model-free system for causal 6D pose tracking and online 3D reconstruction of multiple unknown rigid objects from monocular RGB-D sequences. It relies on 2D point trackers to provide long-range point correspondences that enable recovery from complete occlusions, while fusing an incremental TSDF volume for each object. The authors also contribute a new multi-object dataset with simulation and real-world sequences annotated with motion-capture ground truth. Experiments are said to demonstrate performance comparable to existing state-of-the-art methods on severe-occlusion benchmarks, with the added benefits of multi-object support and occlusion recovery not available in prior model-free trackers.
Significance. Should the quantitative claims be substantiated, the work would represent a meaningful advance in model-free 6D object tracking by solving the occlusion recovery problem through off-the-shelf 2D trackers combined with TSDF fusion. The new dataset is a clear positive contribution that could facilitate future research. The approach is pragmatic in leveraging existing components rather than proposing entirely new modules.
major comments (2)
- Experiments section: The claim that Point2Pose 'achieves performance comparable to the state-of-the-art methods on a severe-occlusion benchmark' supplies no numerical results, error bars, ablation studies, or evaluation protocol details, so the data-to-claim link for the central performance assertion cannot be assessed.
- Method section: The occlusion-recovery claim depends on the 2D point tracker supplying reliable long-range correspondences after complete occlusion without drift or identity switches. No isolated evaluation or ablation of this precondition is reported, which is load-bearing for the recovery and multi-object claims.
minor comments (2)
- Abstract: The statement of 'comparable performance' would benefit from naming the specific baselines and metrics used, even at a high level.
- The rigidity assumption for TSDF fusion is stated but its impact on non-rigid motion sequences is not discussed; a brief note on failure modes would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to strengthen the presentation of results and supporting analyses.
read point-by-point responses
-
Referee: Experiments section: The claim that Point2Pose 'achieves performance comparable to the state-of-the-art methods on a severe-occlusion benchmark' supplies no numerical results, error bars, ablation studies, or evaluation protocol details, so the data-to-claim link for the central performance assertion cannot be assessed.
Authors: We agree that the experiments section requires additional quantitative detail to fully substantiate the performance claim. In the revised manuscript we will add explicit tables reporting mean and median 6D pose errors (with standard deviations) against the cited state-of-the-art baselines on the severe-occlusion sequences, together with a clear statement of the evaluation protocol, metrics, and any error bars. We will also include a brief ablation on key design choices to make the data-to-claim connection transparent. revision: yes
-
Referee: Method section: The occlusion-recovery claim depends on the 2D point tracker supplying reliable long-range correspondences after complete occlusion without drift or identity switches. No isolated evaluation or ablation of this precondition is reported, which is load-bearing for the recovery and multi-object claims.
Authors: The referee correctly notes that the 2D tracker’s long-range correspondence quality is a critical precondition. While the tracker is an off-the-shelf component whose general performance is documented in the literature, we acknowledge that an isolated evaluation on our occlusion scenarios would strengthen the paper. In revision we will add a targeted analysis (including qualitative examples and quantitative tracking-success rates before/after full occlusions) drawn from the new dataset to demonstrate that the tracker supplies sufficiently reliable correspondences for our pipeline. We will also discuss observed failure modes and their impact on the overall system. revision: yes
Circularity Check
No circularity: systems integration of external trackers and TSDF without self-referential derivations
full rationale
The paper describes a pipeline that initializes from sparse points, uses an off-the-shelf 2D point tracker for long-range correspondences, and incrementally builds a TSDF volume for pose estimation and reconstruction. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs. Claims of occlusion recovery and multi-object tracking are supported by experimental results on a new dataset with motion-capture ground truth, not by any internal derivation that assumes its own outputs. The rigidity assumption and tracker reliability are stated as preconditions but are not derived within the paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tracked objects are rigid bodies
- domain assumption The 2D point tracker produces accurate long-range correspondences after occlusion
Forward citations
Cited by 1 Pith paper
-
Learning Reactive Dexterous Grasping via Hierarchical Task-Space RL Planning and Joint-Space QP Control
A multi-agent RL high-level planner outputs task-space velocities that a GPU-parallel QP low-level controller converts to joint velocities while enforcing limits and collisions, yielding robust sim-to-real dexterous g...
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Banerjee, P., Shkodrani, S., Moulon, P., Hampali, S., Han, S., Zhang, F., Zhang, L., Fountain, J., Miller, E., Basol, S., et al.: Hot3d: Hand and object tracking in 3d from egocentric multi- view videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7061–7071 (2025)
2025
-
[2]
In: 2015 international conference on advanced robotics (ICAR)
Calli, B., Singh, A., Walsman, A., Srinivasa, S., Abbeel, P., Dollar, A.M.: The ycb object and model set: Towards common benchmarks for manipulation research. In: 2015 international conference on advanced robotics (ICAR). pp. 510–517. IEEE (2015)
2015
-
[3]
In: Proceedingsofthe23rdannualconferenceonComputergraphicsandinteractivetechniques
Curless, B., Levoy, M.: A volumetric method for building complex models from range images. In: Proceedingsofthe23rdannualconferenceonComputergraphicsandinteractivetechniques. pp. 303–312 (1996)
1996
-
[4]
Dellaert, F., Contributors, G.: borglab/gtsam (May 2022). https://doi.org/10.5281/zenodo.5794541,https://github.com/borglab/gtsam)
-
[5]
Foundations and Trends in Robotics, Vol
Dellaert, F., Kaess, M.: Factor Graphs for Robot Perception. Foundations and Trends in Robotics, Vol. 6 (2017),http://www.cs.cmu.edu/~kaess/pub/Dellaert17fnt.pdf
2017
-
[6]
IEEE Transactions on Robotics37(5), 1328–1342 (2021)
Deng, X., Mousavian, A., Xiang, Y., Xia, F., Bretl, T., Fox, D.: Poserbpf: A rao–blackwellized particle filter for 6-d object pose tracking. IEEE Transactions on Robotics37(5), 1328–1342 (2021)
2021
-
[7]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detec- tion and description. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 224–236 (2018)
2018
-
[8]
Asian Conference on Computer Vision (2024)
Doersch, C., Luc, P., Yang, Y., Gokay, D., Koppula, S., Gupta, A., Heyward, J., Rocco, I., Goroshin, R., Carreira, J., Zisserman, A.: BootsTAP: Bootstrapped training for tracking-any- point. Asian Conference on Computer Vision (2024)
2024
-
[9]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Doersch, C., Yang, Y., Vecerik, M., Gokay, D., Gupta, A., Aytar, Y., Carreira, J., Zisserman, A.: TAPIR: Tracking any point with per-frame initialization and temporal refinement. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10061–10072 (2023)
2023
-
[10]
In: CVPR (2020)
Hampali, S., Rad, M., Oberweger, M., Lepetit, V.: Honnotate: A method for 3d annotation of hand and object poses. In: CVPR (2020)
2020
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, Y., Sun, W., Huang, H., Liu, J., Fan, H., Sun, J.: Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11632–11641 (2020)
2020
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, Y., Wang, Y., Fan, H., Sun, J., Chen, Q.: Fs6d: Few-shot 6d pose estimation of novel ob- jects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6814–6824 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, T., Liu, S., Chen, Y., Shen, T., Jia, J.: Efficientnerf efficient neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12902–12911 (2022) 13
2022
-
[14]
In: Breakthroughs in statistics: Methodology and distribution, pp
Huber, P.J.: Robust estimation of a location parameter. In: Breakthroughs in statistics: Methodology and distribution, pp. 492–518. Springer (1992)
1992
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jin, Y., Prasad, V., Jauhri, S., Franzius, M., Chalvatzaki, G.: 6dope-gs: Online 6d object pose estimation using gaussian splatting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8032–8043 (2025)
2025
-
[16]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Karaev, N., Makarov, I., Wang, J., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In: Proc. arXiv:2410.11831 (2024)
-
[17]
In: Proc
Karaev, N., Rocco, I., Graham, B., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker: It is better to track together. In: Proc. ECCV (2024)
2024
-
[18]
In: European conference on computer vision
Labbé, Y., Carpentier, J., Aubry, M., Sivic, J.: Cosypose: Consistent multi-view multi-object 6d pose estimation. In: European conference on computer vision. pp. 574–591. Springer (2020)
2020
-
[19]
In: Conference on Robot Learning
Labbé, Y., Manuelli, L., Mousavian, A., Tyree, S., Birchfield, S., Tremblay, J., Carpentier, J., Aubry, M., Fox, D., Sivic, J.: Megapose: 6d pose estimation of novel objects via render & compare. In: Conference on Robot Learning. pp. 715–725. PMLR (2023)
2023
-
[20]
Quarterly of applied mathematics2(2), 164–168 (1944)
Levenberg, K.: A method for the solution of certain non-linear problems in least squares. Quarterly of applied mathematics2(2), 164–168 (1944)
1944
-
[21]
In: Seminal graphics: pioneering efforts that shaped the field, pp
Lorensen, W.E., Cline, H.E.: Marching cubes: A high resolution 3d surface construction algo- rithm. In: Seminal graphics: pioneering efforts that shaped the field, pp. 347–353 (1998)
1998
-
[22]
Journal of the society for Industrial and Applied Mathematics11(2), 431–441 (1963)
Marquardt, D.W.: An algorithm for least-squares estimation of nonlinear parameters. Journal of the society for Industrial and Applied Mathematics11(2), 431–441 (1963)
1963
-
[23]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mittal, M., Roth, P., Tigue, J., Richard, A., Zhang, O., Du, P., Serrano-Muñoz, A., Yao, X., Zurbrügg, R., Rudin, N., et al.: Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning. arXiv preprint arXiv:2511.04831 (2025)
work page internal anchor Pith review arXiv 2025
-
[24]
In: 2011 10th IEEE international symposium on mixed and augmented reality
Newcombe, R.A., Izadi, S., Hilliges, O., Molyneaux, D., Kim, D., Davison, A.J., Kohi, P., Shotton, J., Hodges, S., Fitzgibbon, A.: Kinectfusion: Real-time dense surface mapping and tracking. In: 2011 10th IEEE international symposium on mixed and augmented reality. pp. 127–136. Ieee (2011)
2011
-
[25]
In: The Thirteenth International Conference on Learning Representations (2025)
Ponimatkin, G., Cífka, M., Soucek, T., Fourmy, M., Labbé, Y., Petrik, V., Sivic, J.: 6d object pose tracking in internet videos for robotic manipulation. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[26]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
In: 2016 IEEE/RSJ international conference on intelligent robots and systems (IROS)
Wang, J., Olson, E.: Apriltag 2: Efficient and robust fiducial detection. In: 2016 IEEE/RSJ international conference on intelligent robots and systems (IROS). pp. 4193–4198. IEEE (2016)
2016
-
[28]
In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Wen, B., Bekris, K.: Bundletrack: 6d pose tracking for novel objects without instance or category-level 3d models. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 8067–8074. IEEE (2021) 14
2021
-
[29]
LaNoising: A data-driven approach for 903nm ToF LiDAR performance modeling under fog,
Wen, B., Mitash, C., Ren, B., Bekris, K.E.: se(3)-tracknet: Data-driven 6d pose tracking by calibrating image residuals in synthetic domains. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Oct 2020). https://doi.org/10.1109/iros45743.2020.9341314,http://dx.doi.org/10.1109/IROS45743. 2020.9341314
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wen, B., Tremblay, J., Blukis, V., Tyree, S., Müller, T., Evans, A., Fox, D., Kautz, J., Birch- field, S.: Bundlesdf: Neural 6-dof tracking and 3d reconstruction of unknown objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 606–617 (2023)
2023
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wen, B., Yang, W., Kautz, J., Birchfield, S.: Foundationpose: Unified 6d pose estimation and tracking of novel objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17868–17879 (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Wu, Y.K., Shen, Y., Huang, T., Fang, I., Chen, J.C., et al.: Kmops: Keypoint-driven method for multi-object pose and metric size estimation from stereo images. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 7730–7739 (2026)
2026
-
[33]
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
Xiang, Y., Schmidt, T., Narayanan, V., Fox, D.: Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. arXiv preprint arXiv:1711.00199 (2017)
work page Pith review arXiv 2017
-
[34]
In: CVPR (2017) A Implementation Details Below we describe the implementation details of the proposed method
Zeng, A., Song, S., Nießner, M., Fisher, M., Xiao, J., Funkhouser, T.: 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In: CVPR (2017) A Implementation Details Below we describe the implementation details of the proposed method. Actual implementation, including code and parameters, will be available on the GitHub repository after...
2017
-
[35]
Pose Stability: The relative pose change between consecutive frames must be small (e.g., rotation<2 ◦ and translation<0.01m) to ensure observations are captured during reliable tracking phases
-
[36]
Track Quality: The 2D track remains visible, has a valid depth value, and its tracking uncer- tainty falls below a strict threshold (0.3)
-
[37]
Once the consecutive streak threshold is reached, the point undergoes a final geometric verification before promotion
Mask Consistency: The 2D projection of the track strictly lies within the current object segmentation mask. Once the consecutive streak threshold is reached, the point undergoes a final geometric verification before promotion. We evaluate the accumulated 3D observations of the pending point in the object coordinateframetoenforcespatialconsistency. Thepoin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.