Recognition: unknown
CodaRAG: Connecting the Dots with Associativity Inspired by Complementary Learning
Pith reviewed 2026-05-10 16:17 UTC · model grok-4.3
The pith
CodaRAG recovers dispersed evidence chains by consolidating knowledge, traversing multi-dimensional associative pathways, and pruning interference to improve RAG performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CodaRAG evolves retrieval from passive lookup into active associative discovery. It does so by first consolidating fragmented extractions into a unified memory substrate, then traversing the resulting graph along semantic, contextualized, and functional pathways to reconstruct dispersed evidence chains, and finally eliminating interference that would otherwise introduce noise. This three-stage process yields higher recall of relevant facts and higher accuracy in downstream generation on knowledge-intensive benchmarks.
What carries the argument
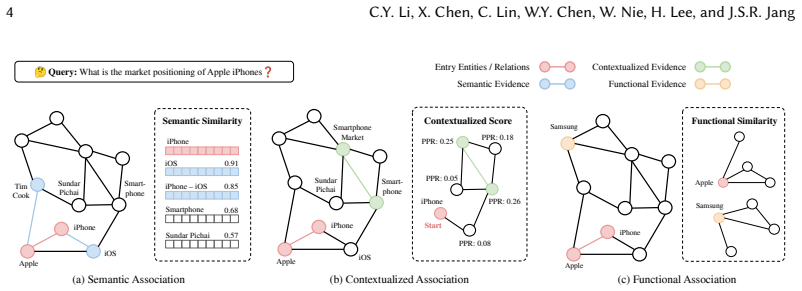
The three-stage pipeline of knowledge consolidation, associative navigation across semantic-contextual-functional pathways, and interference elimination.
If this is right
- Recovered evidence chains produce measurably higher retrieval recall for tasks that require connecting facts across documents.
- Pruning hyper-associative noise yields higher generation accuracy by supplying only coherent context.
- The same pipeline applies across factual, reasoning, and creative question types without task-specific redesign.
- Treating evidence as graph pathways rather than isolated units systematically reduces the fragmentation that causes hallucinations.
Where Pith is reading between the lines
- The same consolidation-plus-navigation structure could be layered on top of existing vector or graph retrievers without replacing their core indexes.
- Extending the multi-dimensional pathways to include temporal or causal dimensions would test whether the method scales to narrative or scientific reasoning tasks.
- If the interference-elimination step can be made differentiable, the entire pipeline might be trained end-to-end rather than staged.
Load-bearing premise
The three-stage pipeline recovers dispersed logical evidence chains without introducing new distortions or missing critical connections.
What would settle it
A controlled test on GraphRAG-Bench or an equivalent multi-hop retrieval benchmark in which CodaRAG produces no gain or a loss in recall and accuracy relative to standard RAG baselines, or in which human inspection of output contexts reveals omitted or fabricated links between facts.
Figures


read the original abstract
Large Language Models (LLMs) struggle with knowledge-intensive tasks due to hallucinations and fragmented reasoning over dispersed information. While Retrieval-Augmented Generation (RAG) grounds generation in external sources, existing methods often treat evidence as isolated units, failing to reconstruct the logical chains that connect these dots. Inspired by Complementary Learning Systems (CLS), we propose CodaRAG, a framework that evolves retrieval from passive lookup into active associative discovery. CodaRAG operates via a three-stage pipeline: (1) Knowledge Consolidation to unify fragmented extractions into a stable memory substrate; (2) Associative Navigation to traverse the graph via multi-dimensional pathways-semantic, contextualized, and functional-explicitly recovering dispersed evidence chains; and (3) Interference Elimination to prune hyper-associative noise, ensuring a coherent, high-precision reasoning context. On GraphRAG-Bench, CodaRAG achieves absolute gains of 7-10% in retrieval recall and 3-11% in generation accuracy. These results demonstrate CodaRAG's superior ability to systematically robustify associative evidence retrieval for factual, reasoning, and creative tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodaRAG, a RAG framework inspired by Complementary Learning Systems (CLS) theory. It proposes a three-stage pipeline—knowledge consolidation to unify fragmented extractions into a stable memory substrate, associative navigation via multi-dimensional (semantic, contextual, functional) pathways to recover dispersed evidence chains, and interference elimination to prune hyper-associative noise—for improving retrieval and generation over isolated evidence units. On GraphRAG-Bench the method reports absolute gains of 7-10% retrieval recall and 3-11% generation accuracy, claiming superior systematic robustification of associative evidence retrieval for factual, reasoning, and creative tasks.
Significance. If the central empirical claims hold under rigorous validation, the work could advance RAG research by shifting from passive lookup to active associative discovery grounded in CLS principles. The multi-dimensional navigation and targeted pruning address a recognized limitation in current systems (fragmented reasoning over dispersed knowledge), and the reported gains suggest practical utility for complex LLM tasks. No machine-checked proofs or parameter-free derivations are present, but the explicit pipeline design offers a falsifiable structure that could be tested further.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): the reported 7-10% recall and 3-11% accuracy gains are aggregate only, with no stage-wise ablations, chain-level precision/recall metrics, or qualitative inspection of pruned vs. retained connections. This directly undermines verification that the three-stage pipeline recovers logical evidence chains without distortion or that gains arise from faithful associativity rather than broader retrieval volume, which is load-bearing for the central claim.
- [§3] §3 (Method, Interference Elimination): the description of pruning 'hyper-associative noise' lacks any quantitative criterion, threshold, or example showing that valid logical links are preserved while invalid ones are removed. Without such evidence the assertion that the stage 'ensures a coherent, high-precision reasoning context' remains untested and is central to the pipeline's claimed advantage over baselines.
minor comments (2)
- [Abstract] Abstract: the baselines, dataset details, and statistical significance of the reported gains are not specified, making it impossible for readers to assess the magnitude of improvement.
- [Abstract and §2] Notation: 'multi-dimensional pathways' and 'hyper-associative noise' are introduced without formal definitions or references to prior CLS literature, which reduces clarity for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that will strengthen the empirical support for our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the reported 7-10% recall and 3-11% accuracy gains are aggregate only, with no stage-wise ablations, chain-level precision/recall metrics, or qualitative inspection of pruned vs. retained connections. This directly undermines verification that the three-stage pipeline recovers logical evidence chains without distortion or that gains arise from faithful associativity rather than broader retrieval volume, which is load-bearing for the central claim.
Authors: We agree that aggregate metrics alone limit the ability to attribute gains specifically to the associative mechanisms. In the revised manuscript we will add stage-wise ablation results on GraphRAG-Bench, reporting the incremental contribution of knowledge consolidation, multi-dimensional navigation, and interference elimination. We will also include chain-level precision/recall on a sampled subset of queries and qualitative examples contrasting pruned versus retained connections, allowing readers to verify that improvements arise from recovered logical chains rather than increased retrieval volume. revision: yes
-
Referee: [§3] §3 (Method, Interference Elimination): the description of pruning 'hyper-associative noise' lacks any quantitative criterion, threshold, or example showing that valid logical links are preserved while invalid ones are removed. Without such evidence the assertion that the stage 'ensures a coherent, high-precision reasoning context' remains untested and is central to the pipeline's claimed advantage over baselines.
Authors: We acknowledge the need for greater specificity. Section 3 will be expanded to define the exact quantitative scoring function and threshold used to detect hyper-associative noise. The revision will include concrete examples drawn from the benchmark, together with before-and-after precision metrics, demonstrating that valid logical links are retained while spurious associations are removed. These additions will provide direct evidence supporting the stage's contribution to coherent reasoning contexts. revision: yes
Circularity Check
No circularity: empirical framework with external benchmark evaluation
full rationale
The paper describes a three-stage pipeline (knowledge consolidation, associative navigation via multi-dimensional pathways, and interference elimination) inspired by Complementary Learning Systems, then reports absolute gains on the external GraphRAG-Bench. No equations, derivations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear. Claims rest on reported empirical outcomes rather than any reduction of predictions or results to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Complementary Learning Systems theory can be effectively translated into a computational framework for associative evidence retrieval in LLMs
Reference graph
Works this paper leans on
-
[1]
Haochen Chen, Syed Fahad Sultan, Yingtao Tian, Muhao Chen, and Steven Skiena. 2019. Fast and Accurate Network Embeddings via Very Sparse Random Projection. InProceedings of the 28th ACM international conference on information and knowledge management. 399–408
2019
-
[2]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson
-
[3]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization.arXiv preprint arXiv:2404.16130 (2024)
work page internal anchor Pith review arXiv 2024
-
[4]
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. 2024. RAGAs: Automated Evaluation of Re- trieval Augmented Generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. 150–158
2024
-
[5]
Oren Etzioni, Michele Banko, Stephen Soderland, and Daniel S Weld. 2008. Open information extraction from the web. Commun. ACM51, 12 (2008), 68–74
2008
-
[6]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2024. LightRAG: Simple and Fast Retrieval-Augmented Generation.arXiv preprint arXiv:2410.05779(2024). 12 C.Y. Li, X. Chen, C. Lin, W.Y. Chen, W. Nie, H. Lee, and J.S.R. Jang
work page internal anchor Pith review arXiv 2024
-
[8]
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models.Advances in Neural Information Processing Systems37 (2024), 59532–59569
2024
-
[9]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. 2025. From RAG to Memory: Non-Parametric Continual Learning for Large Language Models. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025
2025
-
[10]
Haveliwala
Taher H. Haveliwala. 2002. Topic-sensitive PageRank. InProceedings of the 11th international conference on World Wide Web. 517–526
2002
-
[11]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics. 6609–6625
2020
-
[12]
Rashid, Anisa Rula, Lukas Schmelzeisen, Juan F
Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia d’Amato, Gerard de Melo, Claudio Gutierrez, José Emilio Labra Gayo, Sabrina Kirrane, Sebastian Neumaier, Axel Polleres, Roberto Navigli, Axel-Cyrille Ngonga Ngomo, Sabbir M. Rashid, Anisa Rula, Lukas Schmelzeisen, Juan F. Sequeda, Steffen Staab, and Antoine Zimmermann. 2021. Knowledge Graphs.ACM Computin...
2021
-
[13]
Gautier Izacard, Patrick Lewis, et al. 2023. Atlas: Few-shot Learning with Retrieval Augmented Language Models. Journal of Machine Learning Research24, 251 (2023), 1–43
2023
-
[14]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.ACM computing surveys55, 12 (2023), 1–38
2023
-
[15]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large Language Models are Zero-Shot Reasoners.Advances in neural information processing systems35 (2022), 22199–22213
2022
-
[16]
Dharshan Kumaran, Demis Hassabis, and James Mcclelland. 2016. What Learning Systems do Intelligent Agents Need? Complementary Learning Systems Theory Updated.Trends in Cognitive Sciences20 (07 2016), 512–534
2016
-
[17]
Dharshan Kumaran and James L McClelland. 2012. Generalization through the recurrent interaction of episodic memories: a model of the hippocampal system.Psychological review119, 3 (2012), 573
2012
-
[18]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
- [19]
-
[20]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[21]
Hao Liu, Zhengren Wang, Xi Chen, Zhiyu Li, Feiyu Xiong, Qinhan Yu, and Wentao Zhang. 2025. HopRAG: Multi- Hop Reasoning for Logic-Aware Retrieval-Augmented Generation. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar...
2025
-
[22]
Sean MacAvaney, Franco Maria Nardini, et al. 2020. Expansion via prediction of importance with contextualization. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 1573–1576
2020
-
[23]
James Mcclelland, Bruce Mcnaughton, and Randall O’Reilly. 1995. Why There Are Complementary Learning Systems in the Hippocampus and Neocortex: Insights From the Successes and Failures of Connectionist Models of Learning and Memory.Psychological Review102 (08 1995), 419–457
1995
-
[24]
James Mcclelland and Timothy Rogers. 2003. The parallel distributed processing approach to semantic cognition. Nature reviews neuroscience4, 4 (2003), 310–322
2003
-
[25]
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, et al. 2025. A survey of context engineering for large language models.arXiv preprint arXiv:2507.13334(2025)
work page internal anchor Pith review arXiv 2025
-
[26]
Earl Miller and Jonathan Cohen. 2001. An Integrative Theory of Prefrontal Cortex Function.Annual review of neuroscience24, 1 (2001), 167–202
2001
-
[27]
Mistral AI. 2025. Mistral Medium 3.1. https://mistral.ai/. Large language model
2025
-
[28]
OpenAI. 2024. Text Embedding Models. https://openai.com/. Text embedding model
2024
-
[29]
OpenAI. 2025. GPT-5 mini. https://openai.com/. Large language model
2025
-
[30]
Randall C O’Reilly, Rajan Bhattacharyya, Michael D Howard, and Nicholas Ketz. 2014. Complementary learning systems.Cognitive science38, 6 (2014), 1229–1248
2014
-
[31]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. 2025. Graph Retrieval-Augmented Generation: A Survey.ACM Transactions on Information Systems(2025). CodaRAG: Connecting the Dots with Associativity Inspired by Complementary Learning 13
2025
-
[32]
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-Context Retrieval-Augmented Language Models.Transactions of the Association for Computational Linguistics11 (2023), 1316–1331
2023
-
[33]
Lev Ratinov and Dan Roth. 2009. Design challenges and misconceptions in named entity recognition. InProceedings of the thirteenth conference on computational natural language learning (CoNLL-2009). 147–155
2009
-
[34]
Alireza Salemi and Hamed Zamani. 2024. Evaluating Retrieval Quality in Retrieval-Augmented Generation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2395–2400
2024
-
[35]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InThe Twelfth International Conference on Learning Representations
2024
-
[36]
Anna Schapiro, Nicholas Turk-Browne, Matthew Botvinick, and Kenneth Norman. 2017. Complementary learning systems within the hippocampus: A neural network modelling approach to reconciling episodic memory with statistical learning.Philosophical Transactions of The Royal Society B Biological Sciences372 (01 2017)
2017
-
[37]
Margaret Schlichting and Alison Preston. 2015. Memory integration: Neural mechanisms and implications for behavior. Current opinion in behavioral sciences1 (2015), 1–8
2015
-
[38]
Wei Shen, Jianyong Wang, and Jiawei Han. 2014. Entity linking with a knowledge base: Issues, techniques, and solutions.IEEE Transactions on Knowledge and Data Engineering27, 2 (2014), 443–460
2014
-
[39]
Weinan Sun, Madhu Advani, Nelson Spruston, Andrew Saxe, and James Fitzgerald. 2023. Organizing memories for generalization in complementary learning systems.Nature Neuroscience26 (07 2023), 1–11
2023
- [40]
- [41]
-
[42]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing. 2369–2380
2018
-
[43]
Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. 2024. Making Retrieval-Augmented Language Models Robust to Irrelevant Context. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. 14 C.Y. Li, X. Chen, C. Lin, W.Y. Chen, W. Nie, H. Lee, and J.S.R. Jang A Deep Dive Analysis into CodaRAG A.1 ...
-
[44]
Analyze document content, structural elements, and domain-specific patterns
-
[45]
Identify recurring entity categories, their contextual roles, and relationships
-
[46]
--- Type Refinement ---
Propose non-overlapping and domain-appropriate entity types that improve extraction coverage with concise explanations. --- Type Refinement ---
-
[47]
Identify duplicate or highly overlapping entity types based on semantic similarity
-
[48]
Consolidate redundant types while preserving meaningful domain-specific distinctions
-
[49]
H.1.2 Information Extraction.Following LightRAG [ 6], we adopt a structured prompt to extract entities and binary relationships from text
Produce a concise and well-balanced schema that reduces redundancy while maintaining coverage. H.1.2 Information Extraction.Following LightRAG [ 6], we adopt a structured prompt to extract entities and binary relationships from text
-
[50]
Identify entities from the text based on predefined entity types and assign consistent names and descriptions
-
[51]
Extract direct relationships among identified entities and decompose complex interactions into binary relations
-
[52]
H.1.3 Fragmented Entity Merging.We employ a pairwise evaluation to determine whether two entities refer to the same real-world entity
Produce structured outputs with entity and relation descriptions grounded strictly in the input text. H.1.3 Fragmented Entity Merging.We employ a pairwise evaluation to determine whether two entities refer to the same real-world entity. Candidate pairs are first filtered by embedding similarity, followed by LLM-based decisions
-
[53]
Compare entity identifiers and descriptions to assess semantic equivalence
-
[54]
Enforce strict matching criteria by prioritizing proper noun consistency and avoiding merges based on superficial similarity
-
[55]
H.2 Stage II Retrieval and Stage III Post-Retrieval H.2.1 Query-related Cues Generation.Following LightRAG [ 6], we extract high-level and low-level keywords from the user query
Perform merging only when there is high confidence they refer to the same real-world entity; otherwise keep them distinct. H.2 Stage II Retrieval and Stage III Post-Retrieval H.2.1 Query-related Cues Generation.Following LightRAG [ 6], we extract high-level and low-level keywords from the user query. In our framework, these keywords serve as query-related...
-
[56]
Extract high-level keywords that capture the overall query intent and semantic scope
-
[57]
Identify low-level keywords corresponding to specific entities, terms, or detailed aspects
-
[58]
H.2.2 Response.We use grounded prompts to generate answers from retrieved entities, relations, and document chunks while maintaining strict support from the provided context
Produce concise and meaningful keyword sets derived strictly from the query for retrieval guidance. H.2.2 Response.We use grounded prompts to generate answers from retrieved entities, relations, and document chunks while maintaining strict support from the provided context
-
[59]
Identify relevant entities and relations from the provided context to determine the core semantic structure
-
[60]
Ground the selected information using supporting document chunks from the context, preserving original phrasing when possible
-
[61]
H.2.3 Interference Elimination.We leverage LLMs to refine retrieved evidence by suppressing irrelevant or ambiguous items while preserving potentially useful supporting information
Generate a precise answer that integrates only necessary facts, ensuring all statements are strictly supported by the context. H.2.3 Interference Elimination.We leverage LLMs to refine retrieved evidence by suppressing irrelevant or ambiguous items while preserving potentially useful supporting information
-
[62]
Evaluate retrieved entities and relations to identify items that do not contribute to the answer
-
[63]
Suppress irrelevant or ambiguous evidence while preserving potentially useful intermediate or supporting information
-
[64]
Retain a coherent and query-aligned evidence set by removing distracting elements without breaking necessary relational connections
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.