Recognition: unknown
SignReasoner: Compositional Reasoning for Complex Traffic Sign Understanding via Functional Structure Units
Pith reviewed 2026-05-10 15:55 UTC · model grok-4.3
The pith
Decomposing traffic signs into minimal functional blocks lets general VLMs reason about novel sign layouts without any model changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Shifting from whole-sign instance modeling to function-based decomposition into minimal Functional Structure Units enables general VLMs to acquire compositional reasoning for traffic signs. The method defines an FSU-Reasoning task and applies a two-stage pipeline of Iterative Caption-FSU Distillation followed by FSU-GRPO optimization that uses Tree Edit Distance as the reward signal, yielding state-of-the-art accuracy and data efficiency on the TrafficSignEval benchmark with no architectural modifications.
What carries the argument
Functional Structure Unit (FSU): a minimal core functional block such as Direction, Notice, or Lane that represents the sign's meaning through flexible composition rather than fixed whole-sign templates.
Load-bearing premise
That any traffic sign can be broken down into a small fixed vocabulary of functional blocks whose combinations fully determine the sign's meaning and allow reliable generalization to unseen layouts.
What would settle it
Create a test set of traffic signs that use entirely new combinations of the defined functional units, then check whether the model's accuracy on these signs falls to the level of unmodified baseline VLMs.
Figures






read the original abstract
Accurate semantic understanding of complex traffic signs-including those with intricate layouts, multi-lingual text, and composite symbols-is critical for autonomous driving safety. Current models, both specialized small ones and large Vision Language Models (VLMs), suffer from a significant bottleneck: a lack of compositional generalization, leading to failure when encountering novel sign configurations. To overcome this, we propose SignReasoner, a novel paradigm that transforms general VLMs into expert traffic sign reasoners. Our core innovation is Functional Structure Unit (FSU), which shifts from common instance-based modeling to flexible function-based decomposition. By breaking down complex signs into minimal, core functional blocks (e.g., Direction, Notice, Lane), our model learns the underlying structural grammar, enabling robust generalization to unseen compositions. We define this decomposition as the FSU-Reasoning task and introduce a two-stage VLM post-training pipeline to maximize performance: Iterative Caption-FSU Distillation that enhances the model's accuracy in both FSU-reasoning and caption generation; FSU-GRPO that uses Tree Edit Distance (TED) to compute FSU differences as the rewards in GRPO algorithm, boosting reasoning abilities. Experiments on the newly proposed FSU-Reasoning benchmark, TrafficSignEval, show that SignReasoner achieves new SOTA with remarkable data efficiency and no architectural modification, significantly improving the traffic sign understanding in various VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SignReasoner, a post-training paradigm that converts general VLMs into traffic-sign reasoners by decomposing complex signs into Functional Structure Units (FSUs) such as Direction, Notice, and Lane. It introduces the FSU-Reasoning task and a two-stage pipeline—Iterative Caption-FSU Distillation followed by FSU-GRPO using Tree Edit Distance (TED) rewards—to improve both caption accuracy and compositional reasoning. Experiments on the new TrafficSignEval benchmark claim new SOTA results with high data efficiency and no architectural changes, attributing gains to learning an underlying structural grammar that enables generalization to unseen sign compositions.
Significance. If the FSU decomposition and training pipeline demonstrably enable productive recombination of unseen FSU combinations, the work would offer a practical, architecture-agnostic route to stronger compositional visual reasoning in safety-critical domains. The emphasis on data efficiency and the introduction of a structured benchmark could influence post-training methods for other structured visual tasks beyond traffic signs.
major comments (2)
- [Experiments / TrafficSignEval benchmark] The central compositional-generalization claim (abstract and §1) rests on FSUs capturing a reusable structural grammar. However, the TrafficSignEval benchmark description and experimental splits do not appear to isolate recombination of novel FSU co-occurrences; without a held-out set of unseen FSU combinations or an ablation that replaces FSU labels with generic tags while preserving layout, it remains possible that gains arise from improved general captioning rather than grammar learning.
- [FSU-GRPO subsection] §3.2 (FSU-GRPO): The TED reward is defined on FSU trees, yet the manuscript does not specify the exact tree-construction procedure from the FSU decomposition or provide validation that TED correlates with human judgments of sign similarity. This makes it difficult to assess whether the reward truly incentivizes compositional structure rather than surface-level caption similarity.
minor comments (2)
- [Abstract / §1] The abstract and introduction use the term 'FSU-Reasoning task' without a concise formal definition or example of input/output format; adding a short illustrative figure or table early would improve readability.
- [Results tables] Table captions and axis labels in the experimental results should explicitly state whether reported metrics are on seen versus unseen FSU combinations to allow direct assessment of the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our work. We address the major comments point by point below, and we will make revisions to improve the clarity and rigor of the manuscript as outlined.
read point-by-point responses
-
Referee: [Experiments / TrafficSignEval benchmark] The central compositional-generalization claim (abstract and §1) rests on FSUs capturing a reusable structural grammar. However, the TrafficSignEval benchmark description and experimental splits do not appear to isolate recombination of novel FSU co-occurrences; without a held-out set of unseen FSU combinations or an ablation that replaces FSU labels with generic tags while preserving layout, it remains possible that gains arise from improved general captioning rather than grammar learning.
Authors: We agree that demonstrating isolation of novel FSU recombinations is essential to support the claim of learning a reusable structural grammar. Although the TrafficSignEval benchmark was designed to include diverse compositions, the manuscript's description of the experimental splits may not have sufficiently highlighted the held-out novel combinations. In the revised version, we will expand the benchmark section to explicitly describe the construction of splits that hold out specific FSU co-occurrences for testing generalization. We will also include the suggested ablation, where FSU labels are replaced with generic tags while preserving the visual layout, to verify that the performance improvements are attributable to compositional structure learning rather than enhanced general captioning capabilities. revision: yes
-
Referee: [FSU-GRPO subsection] §3.2 (FSU-GRPO): The TED reward is defined on FSU trees, yet the manuscript does not specify the exact tree-construction procedure from the FSU decomposition or provide validation that TED correlates with human judgments of sign similarity. This makes it difficult to assess whether the reward truly incentivizes compositional structure rather than surface-level caption similarity.
Authors: The referee is correct that additional details are needed for full reproducibility and to confirm the reward's focus on structure. The current manuscript introduces the use of Tree Edit Distance on FSU trees but omits the precise mapping from FSU decompositions to tree structures and any empirical validation against human judgments. We will revise §3.2 to provide the exact tree-construction procedure, including how individual FSUs (such as Direction, Notice, and Lane) and their attributes are organized into a hierarchical tree. We will also report a validation study correlating TED scores with human similarity assessments on a sample of traffic signs. These additions will help demonstrate that the GRPO reward effectively promotes compositional reasoning. revision: yes
Circularity Check
No circularity: method proposal and benchmark evaluation are self-contained
full rationale
The paper introduces FSU decomposition and a two-stage post-training pipeline (Iterative Caption-FSU Distillation + FSU-GRPO with TED reward) as a novel paradigm for improving VLMs on traffic sign understanding. No mathematical derivation chain, equations, or first-principles predictions appear; performance claims rest on empirical results from the new TrafficSignEval benchmark rather than any quantity that reduces to its own inputs by construction. The compositional generalization assumption is an empirical hypothesis tested via experiments, not a self-referential definition or fitted parameter renamed as a prediction. Self-citations are absent from the provided text, and the central claims do not rely on load-bearing uniqueness theorems or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
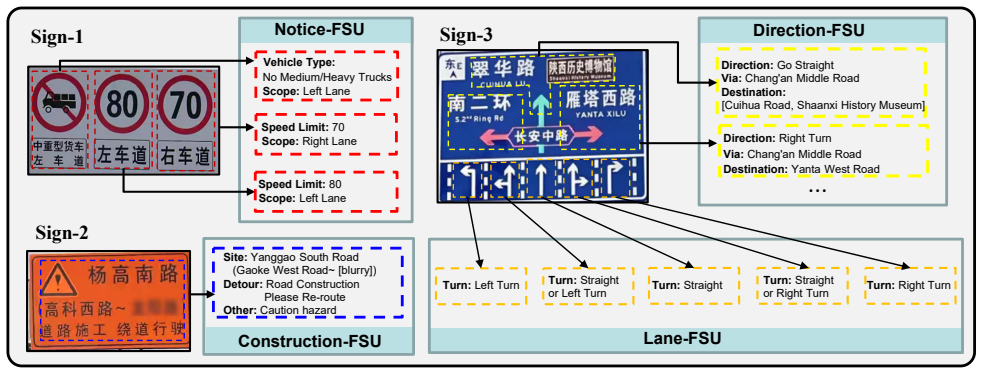
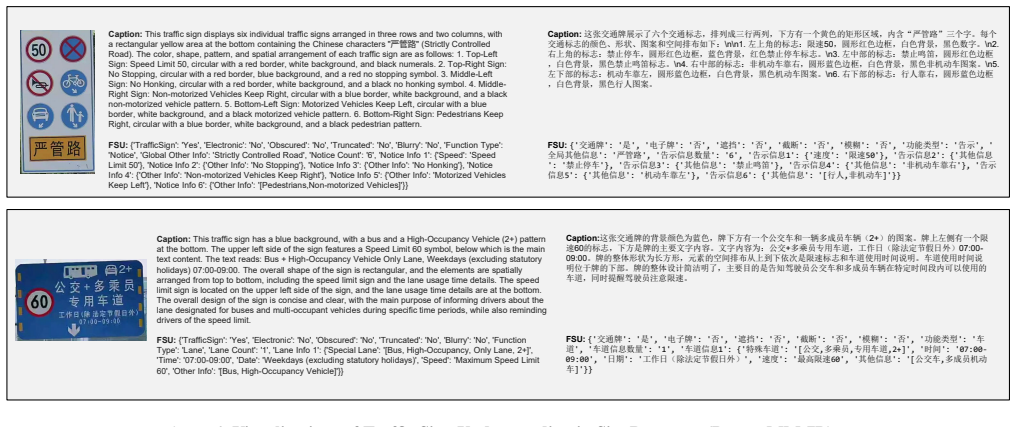
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Driving by the rules: A benchmark for integrating traffic sign regulations into vectorized hd map
Xinyuan Chang, Maixuan Xue, Xinran Liu, Zheng Pan, and Xing Wei. Driving by the rules: A benchmark for integrating traffic sign regulations into vectorized hd map. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 6823–6833, 2025. 1, 2, 3
2025
-
[4]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 3
2024
-
[5]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024. 1
2024
-
[6]
Fast r-cnn
Ross Girshick. Fast r-cnn. InProceedings of the IEEE inter- national conference on computer vision, pages 1440–1448,
-
[7]
A survey of deep learning techniques for autonomous driving.Journal of Field Robotics, 37(3):362– 386, 2020
Sorin Grigorescu, Bogdan Trasnea, Tiberiu Cocias, and Gigel Macesanu. A survey of deep learning techniques for autonomous driving.Journal of Field Robotics, 37(3):362– 386, 2020. 1
2020
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Learning to understand traffic signs
Yunfei Guo, Wei Feng, Fei Yin, Tao Xue, Shuqi Mei, and Cheng-Lin Liu. Learning to understand traffic signs. InPro- ceedings of the 29th ACM International Conference on Mul- timedia, pages 2076–2084, 2021. 2
2076
-
[10]
Visual traffic knowledge graph generation from scene images
Yunfei Guo, Fei Yin, Xiao-hui Li, Xudong Yan, Tao Xue, Shuqi Mei, and Cheng-Lin Liu. Visual traffic knowledge graph generation from scene images. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21604–21613, 2023. 2
2023
-
[11]
Sign- parser: An end-to-end framework for traffic sign understand- ing.International Journal of Computer Vision, 132(3):805– 821, 2024
Yunfei Guo, Wei Feng, Fei Yin, and Cheng-Lin Liu. Sign- parser: An end-to-end framework for traffic sign understand- ing.International Journal of Computer Vision, 132(3):805– 821, 2024. 1, 2, 6
2024
-
[12]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review arXiv
-
[13]
Zilin Huang, Zihao Sheng, Yansong Qu, Junwei You, and Sikai Chen. Vlm-rl: A unified vision language models and reinforcement learning framework for safe autonomous driv- ing.arXiv preprint arXiv:2412.15544, 2024. 3
-
[14]
Al Sallab, Senthil Yogamani, and Patrick P´erez
B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Man- nion, Ahmad A. Al Sallab, Senthil Yogamani, and Patrick P´erez. Deep reinforcement learning for autonomous driving: A survey.IEEE Transactions on Intelligent Transportation Systems, 23(6):4909–4926, 2022. 1
2022
-
[15]
arXiv preprint arXiv:2502.21321
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip HS Torr, Fahad Shahbaz Khan, and Salman Khan. Llm post-training: A deep dive into reasoning large language models.arXiv preprint arXiv:2502.21321, 2025. 3
-
[16]
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement.arXiv preprint arXiv:2503.06520, 2025. 3
-
[17]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025. 3, 5
work page internal anchor Pith review arXiv 2025
-
[18]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual- rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[19]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforce- ment learning.arXiv preprint arXiv:2503.07365, 2025. 3
work page Pith review arXiv 2025
-
[20]
Medvlm-r1: Incentivizing medical reasoning ca- pability of vision-language models (vlms) via reinforcement learning
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning ca- pability of vision-language models (vlms) via reinforcement learning. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 337–
-
[21]
Efficient computa- tion of the tree edit distance.ACM Transactions on Database Systems (TODS), 40(1):1–40, 2015
Mateusz Pawlik and Nikolaus Augsten. Efficient computa- tion of the tree edit distance.ACM Transactions on Database Systems (TODS), 40(1):1–40, 2015. 5
2015
-
[22]
You only look once: Unified, real-time object de- tection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object de- tection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016. 1
2016
-
[23]
Faster r-cnn: Towards real-time object detection with region proposal networks.IEEE transactions on pattern analysis and machine intelligence, 39(6):1137–1149, 2016
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.IEEE transactions on pattern analysis and machine intelligence, 39(6):1137–1149, 2016. 1
2016
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition.Neural net- works, 32:323–332, 2012. 6
2012
-
[26]
Llamav-o1: Rethinking step-by-step vi- sual reasoning in llms
Omkar Thawakar, Dinura Dissanayake, Ketan Pravin More, Ritesh Thawkar, Ahmed Heakl, Noor Ahsan, Yuhao Li, Il- muz Zaman Mohammed Zumri, Jean Lahoud, Rao Muham- mad Anwer, et al. Llamav-o1: Rethinking step-by-step vi- sual reasoning in llms. InFindings of the Association for Computational Linguistics: ACL 2025, pages 24290–24315,
2025
-
[27]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Improved yolov5 network for real-time multi-scale traffic sign detection.Neural Computing and Applications, 35(10): 7853–7865, 2023
Junfan Wang, Yi Chen, Zhekang Dong, and Mingyu Gao. Improved yolov5 network for real-time multi-scale traffic sign detection.Neural Computing and Applications, 35(10): 7853–7865, 2023. 1
2023
-
[29]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reason- ing in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 3, 5
2022
-
[32]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087– 2098, 2025. 3
2087
-
[33]
Traffic sign interpretation via natural language description.IEEE Transactions on Intelligent Transportation Systems, 2024
Chuang Yang, Kai Zhuang, Mulin Chen, Haozhao Ma, Xu Han, Tao Han, Changxing Guo, Han Han, Bingxuan Zhao, and Qi Wang. Traffic sign interpretation via natural language description.IEEE Transactions on Intelligent Transportation Systems, 2024. 1, 3
2024
-
[34]
Signeye: Traffic sign interpretation from vehicle first-person view
Chuang Yang, Xu Han, Tao Han, Yuejiao Su, Junyu Gao, Hongyuan Zhang, Yi Wang, and Lap-Pui Chau. Signeye: Traffic sign interpretation from vehicle first-person view. IEEE Transactions on Intelligent Transportation Systems,
-
[35]
Towards real-time traffic sign detection and classification
Yi Yang, Hengliang Luo, Huarong Xu, and Fuchao Wu. Towards real-time traffic sign detection and classification. IEEE Transactions on Intelligent transportation systems, 17 (7):2022–2031, 2015. 6
2022
-
[36]
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing gen- eralized multimodal reasoning through cross-modal formal- ization.arXiv preprint arXiv:2503.10615, 2025. 3
-
[37]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforce- ment learning system at scale, 2025.URL https://arxiv. org/abs/2503.14476, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
A survey of autonomous driving: Com- mon practices and emerging technologies.IEEE Access, 8: 58443–58469, 2020
Ekim Yurtsever, Jacob Lambert, Alexander Carballo, and Kazuya Takeda. A survey of autonomous driving: Com- mon practices and emerging technologies.IEEE Access, 8: 58443–58469, 2020. 1
2020
-
[39]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[40]
Simple fast algorithms for the editing distance between trees and related problems
Kaizhong Zhang and Dennis Shasha. Simple fast algorithms for the editing distance between trees and related problems. SIAM journal on computing, 18(6):1245–1262, 1989. 5
1989
-
[41]
Lili Zhang, Kang Yang, Yucheng Han, Jing Li, Wei Wei, Hongxin Tan, Pei Yu, Ke Zhang, and Xudong Yang. Tsd- detr: A lightweight real-time detection transformer of traffic sign detection for long-range perception of autonomous driv- ing.Engineering Applications of Artificial Intelligence, 139: 109536, 2025. 1
2025
-
[42]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable trans- formers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 1
work page internal anchor Pith review arXiv 2010
-
[44]
Traffic-sign detection and classifica- tion in the wild
Zhe Zhu, Dun Liang, Songhai Zhang, Xiaolei Huang, Baoli Li, and Shimin Hu. Traffic-sign detection and classifica- tion in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2110–2118,
-
[45]
1, 6 SignReasoner: Compositional Reasoning for Complex Traffic Sign Understanding via Functional Structure Units Supplementary Material
-
[46]
SignReasoner Implementations We elaborate on several implementation details of SignRea- soner in this section, including the uniquely designed keys for each FSU (Sect.6.1), the specific prompt and response format employed to instruct the VLM for both Captioning and FSU-Reasoning (Sect.6.2), and the algorithmic imple- mentation of Tree Edited Distance (Sec...
-
[47]
Training and Evaluation This section details the specifics of the training and evaluation datasets (Sect.7.1), the training particulars (Sect.7.2)—including data construction, hyper-parameters, and hardware—and the comprehensive evaluation method- ology on the Structure protocols (Sect.7.3). 7.1. Datasets Training Data.We primarily utilize two types of tr...
-
[48]
Traffic Sign
Mingle Road (Mingle Rd) is on the left side of the sign, indicating a left turn. 3. Yangtaishan Road (Yangtaishan Rd) is on the right side of the sign, indicating a right turn. The color and shape of the traffic sign are designed to be simple and clear, using the white crossroad pattern to clearly indicate the options for going straight ahead or turning l...
-
[49]
More Visualizations In this section, we provide more comprehensive visualized results (Fig.6-7) in both Chinese and English to demonstrate the powerful capabilities of SignReasoner. Algorithm 2Tree Edit Distance Require:Tree nodesn 1,n 2 Ensure:Minimum edit cost 1:FunctionHELPER(n 1, n2): 2:cost←0 3:ifISLEAF(n 1)andISLEAF(n 2)then 4:# Case 1: Both are lea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.