Recognition: unknown
Thinking Fast, Thinking Wrong: Intuitiveness Modulates LLM Counterfactual Reasoning in Policy Evaluation
Pith reviewed 2026-05-10 15:42 UTC · model grok-4.3
The pith
Intuitiveness dominates LLM performance in counterfactual policy reasoning, nullifying chain-of-thought benefits on counter-intuitive cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
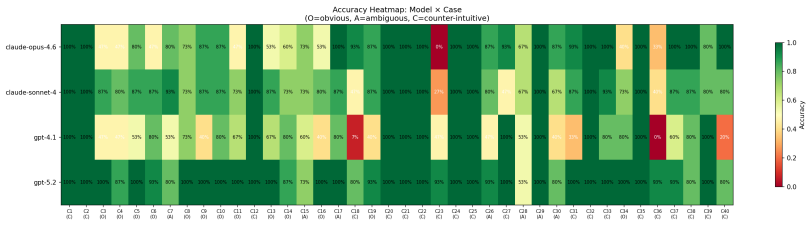
In evaluations of frontier LLMs on 40 grounded policy cases, chain-of-thought prompting improves accuracy substantially on cases whose results align with common priors but provides little benefit on cases whose results contradict those priors, as shown by a significant interaction in mixed-effects logistic regression (OR=0.053). Intuitiveness accounts for the largest share of variance in performance, while familiarity via citations does not predict accuracy. The results suggest that LLMs can produce deliberative reasoning output without achieving the corresponding improvement in handling counter-intuitive causal claims.
What carries the argument
The classification of policy cases by intuitiveness (alignment with common prior expectations) and its interaction with prompting strategy in predicting reasoning accuracy via mixed-effects models.
If this is right
- Chain-of-thought prompting improves accuracy on obvious cases but shows almost no benefit on counter-intuitive ones.
- Intuitiveness of the case explains more performance variance than the choice of model or prompting strategy.
- Citation-based familiarity with the cases is unrelated to accuracy, indicating a knowledge-reasoning dissociation.
- Performance degrades as cases move from obvious to ambiguous to counter-intuitive.
Where Pith is reading between the lines
- LLMs may generate the appearance of deliberate reasoning without actually revising their outputs to accommodate contradictory evidence.
- The pattern may generalize to other tasks requiring override of default assumptions, such as anomaly detection in data or ethical dilemma resolution.
- Future LLM designs could benefit from explicit mechanisms to flag and override intuitive priors during reasoning.
- Testing on dynamically generated cases where intuitiveness is manipulated could confirm the causal role of prior expectations.
Load-bearing premise
The manual or rater-based classification of the 40 cases into obvious, ambiguous, and counter-intuitive categories accurately captures common prior expectations without introducing systematic bias.
What would settle it
Reclassifying the cases with new independent raters and finding that the interaction between chain-of-thought and intuitiveness no longer holds, or demonstrating high accuracy on counter-intuitive cases when models are given explicit contrary evidence in the prompt.
Figures


read the original abstract
Large language models (LLMs) are increasingly used for causal and counterfactual reasoning, yet their reliability in real-world policy evaluation remains underexplored. We construct a benchmark of 40 empirical policy evaluation cases drawn from economics and social science, each grounded in peer-reviewed evidence and classified by intuitiveness -- whether the empirical finding aligns with (obvious), is unclear relative to (ambiguous), or contradicts (counter-intuitive) common prior expectations. We evaluate four frontier LLMs across five prompting strategies with 2,400 experimental trials and analyze the results using mixed-effects logistic regression. Our findings reveal three key results: (1) a chain-of-thought (CoT) paradox, where chain-of-thought prompting dramatically improves performance on obvious cases but this benefit is nearly eliminated on counter-intuitive ones (interaction OR = 0.053, $p < 0.001$); (2) intuitiveness as the dominant factor, explaining more variance than model choice or prompting strategy (ICC = 0.537); and (3) a knowledge-reasoning dissociation, where citation-based familiarity is unrelated to accuracy ($p = 0.53$), suggesting models possess relevant knowledge but fail to reason with it when findings contradict intuition. We frame these results through the lens of dual-process theory (System 1 vs. System 2) and argue that current LLMs' "slow thinking" may be little more than "slow talking" -- they produce the form of deliberative reasoning without the substance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that intuitiveness of policy evaluation cases modulates LLM performance in counterfactual reasoning. Using a benchmark of 40 cases classified as obvious, ambiguous, or counter-intuitive, and 2400 trials with four LLMs and five prompting strategies, mixed-effects logistic regression reveals that chain-of-thought prompting boosts accuracy on obvious cases but the benefit disappears for counter-intuitive cases (interaction OR = 0.053, p < 0.001). Intuitiveness explains more variance than model or prompt (ICC = 0.537), and citation familiarity does not predict accuracy (p = 0.53). This is framed as evidence of dual-process-like behavior in LLMs, where 'slow thinking' is superficial.
Significance. Should the classification of cases prove robust, this work has significant implications for deploying LLMs in policy analysis, as it demonstrates that standard prompting techniques may fail precisely when reasoning is most needed—on counter-intuitive findings. The large-scale experimental design with real-world cases and appropriate statistical modeling (mixed-effects logistic regression) provides a solid empirical foundation. It also contributes to the literature on LLM reasoning limitations by linking them to intuitiveness, potentially inspiring new prompting or training approaches.
major comments (1)
- Methods (Benchmark Construction): The description of how the 40 cases were selected and classified into obvious, ambiguous, and counter-intuitive categories lacks details on inter-rater reliability, whether raters were blind to the study hypotheses or LLM performance, and how 'common prior expectations' were measured or elicited (e.g., no mention of pre-study surveys). This is load-bearing for the reported interaction effect, as any bias in classification could confound the intuitiveness variable with case difficulty for LLMs.
minor comments (2)
- Abstract: The abstract mentions 'classified by intuitiveness' but provides no summary statistics on the distribution of cases across the three categories or examples of each type.
- Results: It would be helpful to include a table showing accuracy rates broken down by intuitiveness level and prompting strategy to complement the regression results.
Simulated Author's Rebuttal
We are grateful to the referee for their careful reading and insightful comments on our paper. The feedback on the methods section is particularly helpful, and we will make revisions to improve clarity and address potential concerns about the robustness of our case classifications.
read point-by-point responses
-
Referee: Methods (Benchmark Construction): The description of how the 40 cases were selected and classified into obvious, ambiguous, and counter-intuitive categories lacks details on inter-rater reliability, whether raters were blind to the study hypotheses or LLM performance, and how 'common prior expectations' were measured or elicited (e.g., no mention of pre-study surveys). This is load-bearing for the reported interaction effect, as any bias in classification could confound the intuitiveness variable with case difficulty for LLMs.
Authors: We agree that the Methods section would benefit from greater detail on the benchmark construction to allow readers to assess the validity of the intuitiveness classification. In the revised manuscript, we will include an expanded description of how the 40 cases were selected from the economics and social science literature, specifying the search criteria and inclusion standards used. We will also clarify that the classification into obvious, ambiguous, and counter-intuitive categories was carried out by the authors drawing on established theoretical priors in the relevant fields (e.g., predictions from standard models in public economics or behavioral science). No formal inter-rater reliability statistics were computed, as the classification was not performed by independent raters external to the study team; instead, it reflects the consensus judgment of the research team. The authors were not blind to the hypotheses, but classification occurred prior to the LLM experiments. We did not elicit 'common prior expectations' via surveys but relied on alignment with widely accepted findings as documented in review articles and textbooks. We will explicitly note these aspects as limitations in the revised paper and discuss their implications for interpreting the results. To further support the classification, we will add the complete list of cases with brief justifications for their intuitiveness labels in the supplementary materials. We maintain that the large effect sizes observed and the consistency across models support the main conclusions, but we welcome this opportunity to enhance the transparency of our approach. revision: yes
Circularity Check
No significant circularity in empirical benchmark construction and regression analysis
full rationale
The paper is a purely empirical study: it assembles 40 policy cases grounded in peer-reviewed evidence, classifies them into intuitiveness bins according to alignment with common prior expectations (an external input), runs LLM evaluations under controlled prompting conditions, and fits a mixed-effects logistic regression whose outputs (interaction OR=0.053, ICC=0.537) are statistical estimates from the observed data. No derivation chain, self-definitional loop, fitted parameter renamed as prediction, or self-citation load-bearing premise exists. The intuitiveness variable functions as an independent predictor; the regression results are not equivalent to the classification inputs by construction. The analysis is self-contained against external LLM performance benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dual-process theory (System 1 intuitive vs System 2 deliberative) applies to LLM behavior in counterfactual tasks
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Dale J Barr, Roger Levy, Christoph Scheepers, and Harry J Tily. 2013. https://doi.org/10.1016/j.jml.2012.11.001 Random Effects Structure for Confirmatory Hypothesis Testing: Keep It Maximal . Journal of Memory and Language, 68(3):255--278
-
[4]
Douglas Bates, Martin M \"a chler, Ben Bolker, and Steve Walker. 2015. https://doi.org/10.18637/jss.v067.i01 Fitting Linear Mixed-Effects Models Using lme4 . Journal of Statistical Software, 67(1):1--48
-
[5]
Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language Models are Few-Shot Learners . In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 1877--1901
2020
-
[6]
Gordon Dahl and Stefano DellaVigna. 2009. https://doi.org/10.1162/qjec.2009.124.2.677 Does Movie Violence Increase Violent Crime? Quarterly Journal of Economics, 124(2):677--734
-
[7]
Donohue, Abhay Aneja, and Kyle D
John J. Donohue, Abhay Aneja, and Kyle D. Weber. 2019. https://doi.org/10.1111/jels.12219 Right‐to‐Carry Laws and Violent Crime: A Comprehensive Assessment Using Panel Data and a State‐Level Synthetic Control Analysis . Journal of Empirical Legal Studies, 16(2):198--247
-
[8]
Jonathan St BT Evans. 2003. https://doi.org/10.1016/j.tics.2003.08.012 In Two Minds: Dual-Process Accounts of Reasoning . Trends in Cognitive Sciences, 7(10):454--459
-
[9]
Uri Gneezy and Aldo Rustichini. 2000. https://doi.org/10.1086/468061 A Fine is a Price . The Journal of Legal Studies, 29(1):1--17
-
[10]
Yinya Huang, Ruixin Hong, Hongming Zhang, Wei Shao, Zhicheng Yang, Dong Yu, Changshui Zhang, Xiaodan Liang, and Linqi Song. 2024. CLOMO: Counterfactual Logical Modification with Large Language Models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[11]
Alon Jacovi, Yonatan Bitton, Bernd Bohnet, Jonathan Herzig, Or Honovich, Michael Tseng, Michael Collins, Roee Aharoni, and Mor Geva. 2024. A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[12]
Zhijing Jin, Yuen Chen, Felix Leber, Luigi Gresele, Ojasv Kamath, and 1 others. 2024. CLadder: A Benchmark to Assess Causal Reasoning Capabilities of Language Models . Advances in Neural Information Processing Systems (NeurIPS), 36
2024
-
[13]
Daniel Kahneman. 2011. Thinking, Fast and Slow . Farrar, Straus and Giroux
2011
- [14]
-
[15]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large Language Models are Zero-Shot Reasoners . In Advances in Neural Information Processing Systems (NeurIPS), volume 35
2022
-
[16]
Philipp Mondorf and Barbara Plank. 2024. Comparing Inferential Strategies of Humans and Large Language Models in Deductive Reasoning . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[17]
Feiteng Mu and Wenjie Li. 2024. A Causal Approach for Counterfactual Reasoning in Narratives . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[18]
OpenAI . 2023. GPT-4 Technical Report . arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Guobin Shen, Dongcheng Zhao, Aorigele Bao, Xiang He, Yiting Dong, and Yi Zeng. 2025. StressPrompt: Does Stress Impact Large Language Models and Human Performance Similarly? In Proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI)
2025
-
[20]
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2025. Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Parameters for Reasoning . In Proceedings of the 13th International Conference on Learning Representations (ICLR)
2025
-
[21]
Keith E Stanovich and Richard F West. 2000. https://doi.org/10.1017/S0140525X00003435 Individual Differences in Reasoning: Implications for the Rationality Debate? Behavioral and Brain Sciences, 23(5):645--665
-
[22]
Amos Tversky and Daniel Kahneman. 1974. https://doi.org/10.1126/science.185.4157.1124 Judgment Under Uncertainty: Heuristics and Biases . Science, 185(4157):1124--1131
-
[23]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models . In Proceedings of the 11th International Conference on Learning Representations (ICLR)
2023
-
[24]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models . In Advances in Neural Information Processing Systems (NeurIPS), volume 35
2022
-
[25]
Maxwell Weinzierl and Sanda Harabagiu. 2024. Tree-of-Counterfactual Prompting for Zero-Shot Stance Detection . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[26]
Jiahao Ying, Yixin Cao, Kai Xiong, Long Cui, Yidong He, and Yongbin Liu. 2024. Intuitive or Dependent? Investigating LLMs' Behavior Style to Conflicting Prompts . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[27]
Matej Ze c evi \'c , Moritz Willig, Devendra Singh Dhami, and Kristian Kersting. 2023. Causal Parrots: Large Language Models May Talk Causality But Are Not Causal . Transactions on Machine Learning Research
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.