Recognition: unknown
Simple but Stable, Fast and Safe: Achieve End-to-end Control by High-Fidelity Differentiable Simulation
Pith reviewed 2026-05-10 16:23 UTC · model grok-4.3
The pith
A differentiable simulator trained policy maps depth images directly to quadrotor bodyrate commands for end-to-end obstacle avoidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
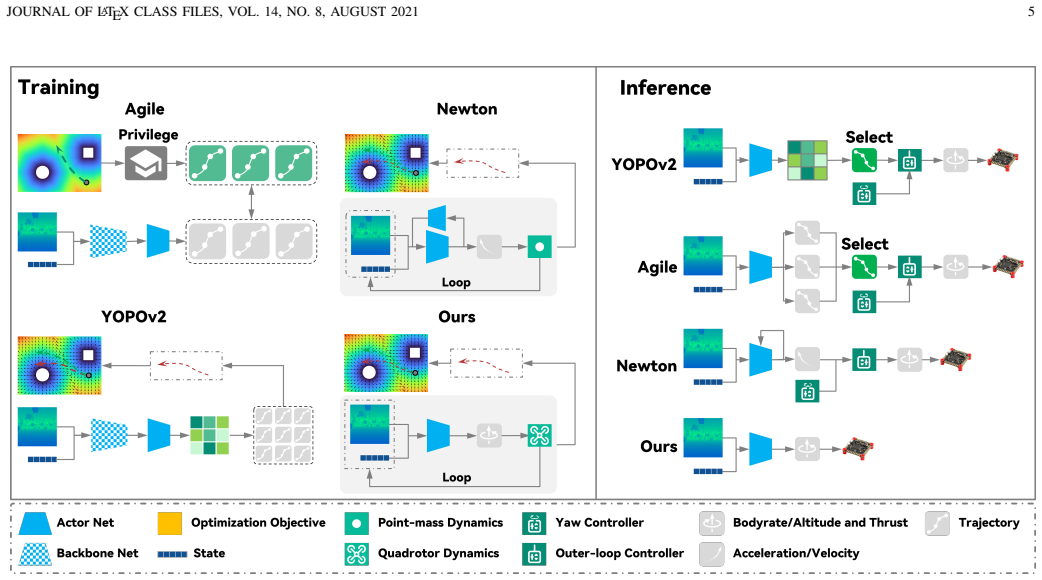
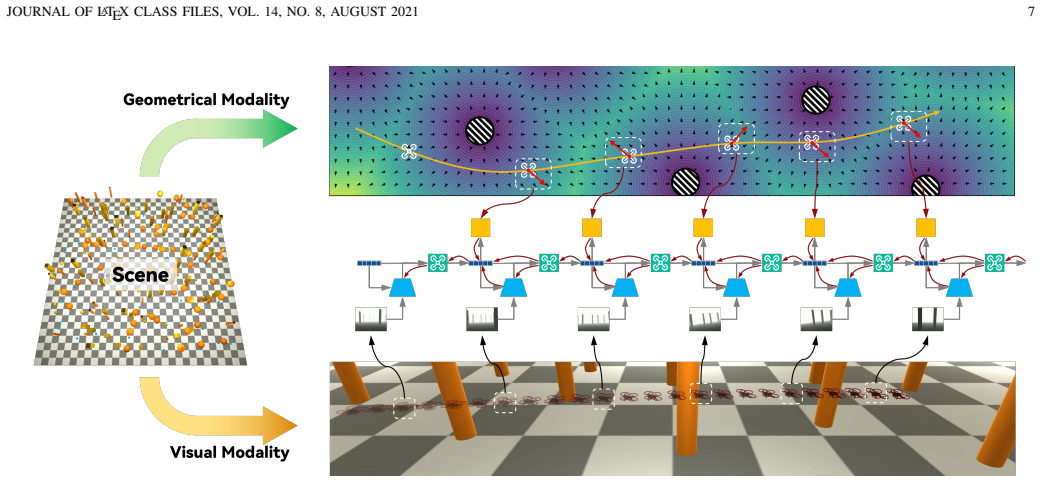
By first identifying parameters on the real quadrotor to build an accurate differentiable simulator, reinforcement learning produces a policy that directly converts depth images into bodyrate commands. This enables full flight-envelope control, avoids infeasible trajectories, and supports training without expert demonstrations or curriculum learning.
What carries the argument
High-fidelity differentiable simulation after real-world parameter identification, which supplies accurate gradients for training the end-to-end depth-to-bodyrate policy.
If this is right
- The policy records the highest success rate and lowest jerk among compared baselines on multiple benchmarks.
- The same policy deploys zero-shot in unseen outdoor scenes and reaches speeds up to 7.5 m/s.
- It maintains stable flight inside super-dense forests.
- Inference requires no explicit mapping, backbone networks, primitives, recurrent modules, backend controllers, curriculum, or privileged information.
Where Pith is reading between the lines
- Similar differentiable-simulation training could shorten the development cycle for other agile mobile robots that currently rely on layered planning and control.
- Direct low-level command output may allow the vehicle to exploit aerodynamic effects that higher-level planners typically ignore.
- Adding explicit modeling of actuator delays inside the differentiable simulator would be a natural next step to further reduce sim-to-real mismatch.
Load-bearing premise
The simulator dynamics and sensor model must match the physical quadrotor closely enough for training gradients to transfer directly to hardware.
What would settle it
A flight test in which the policy exhibits instability, high jerk, or low success rates in benchmark environments similar to those used in training would show that the simulation fidelity is insufficient.
Figures












read the original abstract
Obstacle avoidance is a fundamental vision-based task essential for enabling quadrotors to perform advanced applications. When planning the trajectory, existing approaches both on optimization and learning typically regard quadrotor as a point-mass model, giving path or velocity commands then tracking the commands by outer-loop controller. However, at high speeds, planned trajectories sometimes become dynamically infeasible in actual flight, which beyond the capacity of controller. In this paper, we propose a novel end-to-end policy that directly maps depth images to low-level bodyrate commands by reinforcement learning via differentiable simulation. The high-fidelity simulation in training after parameter identification significantly reduces all the gaps between training, simulation and real world. Analytical process by differentiable simulation provides accurate gradient to ensure efficiently training the low-level policy without expert guidance. The policy employs a lightweight and the most simple inference pipeline that runs without explicit mapping, backbone networks, primitives, recurrent structures, or backend controllers, nor curriculum or privileged guidance. By inferring low-level command directly to the hardware controller, the method enables full flight envelope control and avoids the dynamic-infeasible issue.Experimental results demonstrate that the proposed approach achieves the highest success rate and the lowest jerk among state-of-the-art baselines across multiple benchmarks. The policy also exhibits strong generalization, successfully deploying zero-shot in unseen, outdoor environments while reaching speeds of up to 7.5m/s as well as stably flying in the super-dense forest. This work is released at https://github.com/Fanxing-LI/avoidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to achieve end-to-end control for quadrotor obstacle avoidance by training a reinforcement learning policy that maps depth images directly to low-level bodyrate commands using a high-fidelity differentiable simulator. After identifying quadrotor dynamics parameters on the real platform, the simulation is used to train the policy, which is then deployed zero-shot on hardware. The approach avoids complex components like explicit mapping or backend controllers and reports superior success rates, lower jerk, and generalization to high-speed (7.5 m/s) flights in unseen outdoor and dense forest environments.
Significance. Should the sim-to-real transfer via parameter-identified differentiable simulation prove robust, this would represent a meaningful advance in simplifying high-speed vision-based quadrotor control, reducing reliance on domain randomization or privileged information. The public code release enhances the potential for follow-up work and verification. The focus on a minimal policy architecture is a practical strength for real-time deployment on resource-constrained platforms.
major comments (3)
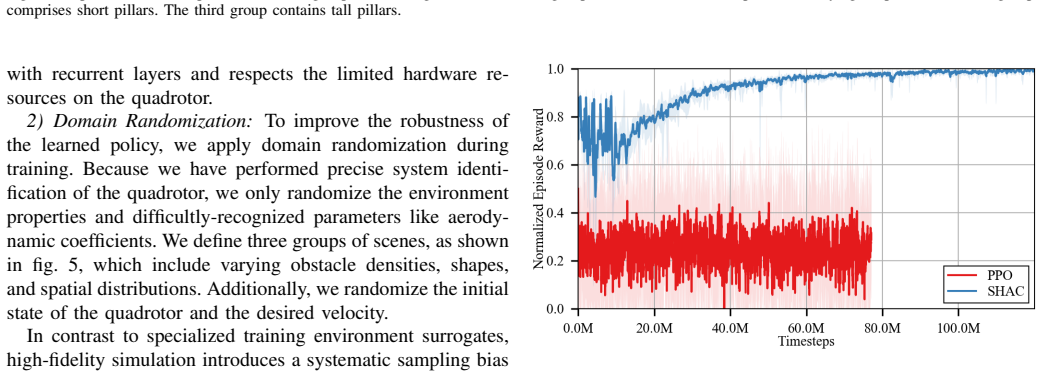
- [Experimental Results] The reported highest success rate and lowest jerk among baselines lack accompanying details on baseline implementations, number of evaluation trials, statistical significance testing, or rules for data exclusion, which are essential to substantiate the performance claims.
- [Parameter Identification] The assertion that parameter identification 'significantly reduces all the gaps' is central to the sim-to-real argument, yet no held-out prediction error metrics, sensitivity analysis, or ablation comparing identified versus nominal dynamics models are provided to quantify the simulation accuracy.
- [Generalization Experiments] While zero-shot deployment in outdoor settings at up to 7.5 m/s and in super-dense forests is claimed, the manuscript does not report the total number of flights attempted, specific failure cases, or variations in environmental conditions, limiting assessment of the generalization strength.
minor comments (2)
- [Abstract] The term 'analytical process by differentiable simulation' is used to describe gradient provision; clarifying whether this refers to automatic differentiation through the simulator or another technique would improve precision.
- [Introduction] Ensure that all baseline methods referenced in comparisons are cited with full references for reader accessibility.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the referee's careful reading and address each major comment below. We will revise the manuscript to incorporate additional details and analyses as outlined in our responses.
read point-by-point responses
-
Referee: [Experimental Results] The reported highest success rate and lowest jerk among baselines lack accompanying details on baseline implementations, number of evaluation trials, statistical significance testing, or rules for data exclusion, which are essential to substantiate the performance claims.
Authors: We agree that these details are essential for substantiating the claims. In the revised manuscript, we will add: detailed descriptions of baseline implementations and hyperparameter tuning; the exact number of evaluation trials (50 per method per environment); statistical significance testing results (paired t-tests with p-values); and explicit data exclusion rules (e.g., excluding trials with hardware faults or sensor failures). These additions will provide the necessary rigor. revision: yes
-
Referee: [Parameter Identification] The assertion that parameter identification 'significantly reduces all the gaps' is central to the sim-to-real argument, yet no held-out prediction error metrics, sensitivity analysis, or ablation comparing identified versus nominal dynamics models are provided to quantify the simulation accuracy.
Authors: We acknowledge the value of quantitative support for this claim. We will include in the revision: held-out prediction error metrics (RMSE on velocity, acceleration, and attitude using unseen real data); a sensitivity analysis of key parameters; and an ablation comparing identified vs. nominal models in terms of both simulation fidelity and real-world policy success rates. This will directly quantify the reduction in gaps. revision: yes
-
Referee: [Generalization Experiments] While zero-shot deployment in outdoor settings at up to 7.5 m/s and in super-dense forests is claimed, the manuscript does not report the total number of flights attempted, specific failure cases, or variations in environmental conditions, limiting assessment of the generalization strength.
Authors: We agree that greater transparency is needed here. The revised version will report the total flights attempted (20 outdoor, 15 dense forest), describe observed failure cases (e.g., rare collisions from wind gusts or depth noise), and specify environmental variations (wind speeds, lighting changes, obstacle densities). This will better substantiate the generalization claims. revision: yes
Circularity Check
No significant circularity; empirical hardware results stand independent of fitted simulation parameters
full rationale
The paper's derivation chain consists of training an RL policy in a differentiable simulator (after parameter identification) and validating it via real-world flight tests. The strongest claims—highest success rate, lowest jerk, zero-shot deployment at 7.5 m/s in unseen dense forests—are reported as outcomes of hardware experiments and benchmark comparisons, not as quantities that reduce by construction to the identified dynamics parameters or to any self-referential equation. No self-definitional loop, fitted-input-renamed-as-prediction, or load-bearing self-citation is present in the provided text. The sim-to-real gap reduction is asserted but tested externally rather than assumed tautologically.
Axiom & Free-Parameter Ledger
free parameters (1)
- quadrotor dynamics parameters
axioms (1)
- domain assumption Differentiable simulation supplies accurate gradients for policy gradient methods
Reference graph
Works this paper leans on
-
[1]
Autonomous Drone Racing: A Survey,
D. Hanover, A. Loquercio, L. Bauersfeld, A. Romero, R. Penicka, Y . Song, G. Cioffi, E. Kaufmann, and D. Scaramuzza, “Autonomous Drone Racing: A Survey,” IEEE Transactions on Robotics, vol. 40, pp. 3044–3067, 2024, conference Name: IEEE Transactions on Robotics. [Online]. Available: https://ieeexplore.ieee.org/document/10530312
-
[2]
EGO-planner: An ESDF-free gradient-based local planner for quadrotors,
X. Zhou, Z. Wang, H. Ye, C. Xu, and F. Gao, “EGO-planner: An ESDF-free gradient-based local planner for quadrotors,” vol. 6, no. 2, pp. 478–485. [Online]. Available: https://ieeexplore.ieee.org/abstract/ document/9309347
-
[3]
Robust and efficient quadrotor trajectory generation for fast autonomous flight,
B. Zhou, F. Gao, L. Wang, C. Liu, and S. Shen, “Robust and efficient quadrotor trajectory generation for fast autonomous flight,” vol. 4, no. 4, pp. 3529–3536
-
[4]
Perception, guidance, and navigation for indoor autonomous drone racing using deep learning,
S. Jung, S. Hwang, H. Shin, and D. H. Shim, “Perception, guidance, and navigation for indoor autonomous drone racing using deep learning,” IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 2539–2544, 2018
2018
-
[5]
Beauty and the beast: Optimal methods meet learning for drone racing
E. Kaufmann, M. Gehrig, P. Foehn, R. Ranftl, A. Dosovitskiy, V . Koltun, and D. Scaramuzza, “Beauty and the beast: Optimal methods meet learning for drone racing.” IEEE, 2019, pp. 690–696
2019
-
[6]
Gate detection for micro aerial vehicles using a single shot detector,
A. A. Cabrera-Ponce, L. O. Rojas-Perez, J. A. Carrasco-Ochoa, J. F. Martinez-Trinidad, and J. Martinez-Carranza, “Gate detection for micro aerial vehicles using a single shot detector,” IEEE Latin America Transactions, vol. 17, no. 12, pp. 2045–2052, 2019
2045
-
[7]
MA VRL: Learn to fly in cluttered environments with varying speed
H. Yu, C. De Wagter, and G. C. de Croon, “MA VRL: Learn to fly in cluttered environments with varying speed.”
-
[8]
Learning high-speed flight in the wild,
A. Loquercio, E. Kaufmann, R. Ranftl, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Learning high-speed flight in the wild,” Science Robotics, vol. 6, no. 59, p. eabg5810, 2021
2021
-
[9]
Vision transformers for end-to-end vision- based quadrotor obstacle avoidance,
A. Bhattacharya, N. Rao, D. Parikh, P. Kunapuli, Y . Wu, Y . Tao, N. Matni, and V . Kumar, “Vision transformers for end-to-end vision- based quadrotor obstacle avoidance,” in 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 1–8. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/11128042
-
[10]
YOPOv2-tracker: An end-to-end agile tracking and navigation framework from perception to action
J. Lu, Y . Hui, X. Zhang, W. Feng, H. Shen, Z. Li, and B. Tian, “YOPOv2-tracker: An end-to-end agile tracking and navigation framework from perception to action.” [Online]. Available: http://arxiv.org/abs/2505.06923
-
[11]
Hierarchically depicting vehicle trajectory with stability in complex environments,
Z. Han, M. Tian, Z. Gongye, D. Xue, J. Xing, Q. Wang, Y . Gao, J. Wang, C. Xu, and F. Gao, “Hierarchically depicting vehicle trajectory with stability in complex environments,” publisher: American Association for the Advancement of Science. [Online]. Available: https://www.science.org/doi/10.1126/scirobotics.ads4551
-
[12]
Back to newton’s laws: Learning vision-based agile flight via differentiable physics
Y . Zhang, Y . Hu, Y . Song, D. Zou, and W. Lin, “Back to newton’s laws: Learning vision-based agile flight via differentiable physics.” [Online]. Available: http://arxiv.org/abs/2407.10648
-
[13]
Polynomial trajectory planning for aggressive quadrotor flight in dense indoor environments
C. Richter, A. Bry, and N. Roy, “Polynomial trajectory planning for aggressive quadrotor flight in dense indoor environments.” Springer, pp. 649–666
-
[14]
Learning perception- aware agile flight in cluttered environments,
Y . Song, K. Shi, R. Penicka, and D. Scaramuzza, “Learning perception- aware agile flight in cluttered environments,” pp. 1989–1995
1989
-
[16]
Learning Quadrotor Control From Visual Features Using Differentiable Simulation,
J. Heeg, Y . Song, and D. Scaramuzza, “Learning Quadrotor Control From Visual Features Using Differentiable Simulation,” Oct. 2024, arXiv:2410.15979. [Online]. Available: http://arxiv.org/abs/2410.15979
-
[17]
Search-based motion planning for aggressive flight in SE(3),
S. Liu, K. Mohta, N. Atanasov, and V . Kumar, “Search-based motion planning for aggressive flight in SE(3),” vol. 3, no. 3, pp. 2439–2446
-
[18]
A real-time framework for kinodynamic planning with application to quadrotor obstacle avoidance,
R. Allen and M. Pavone, “A real-time framework for kinodynamic planning with application to quadrotor obstacle avoidance,” p. 1374
-
[19]
EGO-swarm: A fully autonomous and decentralized quadrotor swarm system in cluttered environments,
X. Zhou, J. Zhu, H. Zhou, C. Xu, and F. Gao, “EGO-swarm: A fully autonomous and decentralized quadrotor swarm system in cluttered environments,” in 2021 IEEE International Conference on Robotics and Automation (ICRA), pp. 4101–4107, ISSN: 2577-087X. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9561902
-
[20]
Learning to fly by myself: A self- supervised cnn-based approach for autonomous navigation
A. Kouris and C.-S. Bouganis, “Learning to fly by myself: A self- supervised cnn-based approach for autonomous navigation.” IEEE, 2018, pp. 1–9
2018
-
[21]
Learning to fly by crashing
D. Gandhi, L. Pinto, and A. Gupta, “Learning to fly by crashing.” IEEE, 2017, pp. 3948–3955
2017
-
[22]
A machine learning approach to visual perception of forest trails for mobile robots,
A. Giusti, J. Guzzi, D. C. Cires ¸an, F.-L. He, J. P. Rodr´ıguez, F. Fontana, M. Faessler, C. Forster, J. Schmidhuber, and G. Di Caro, “A machine learning approach to visual perception of forest trails for mobile robots,” IEEE Robotics and Automation Letters, vol. 1, no. 2, pp. 661–667, 2015
2015
-
[23]
Dronet: Learning to fly by driving,
A. Loquercio, A. I. Maqueda, C. R. Del-Blanco, and D. Scaramuzza, “Dronet: Learning to fly by driving,” IEEE Robotics and Automation Letters, vol. 3, no. 2, pp. 1088–1095, 2018
2018
-
[24]
Deep drone racing: From simulation to reality with domain randomization,
A. Loquercio, E. Kaufmann, R. Ranftl, A. Dosovitskiy, V . Koltun, and D. Scaramuzza, “Deep drone racing: From simulation to reality with domain randomization,” IEEE Transactions on Robotics, vol. 36, no. 1, pp. 1–14, 2019
2019
-
[25]
Deep drone racing: Learning agile flight in dynamic environments
E. Kaufmann, A. Loquercio, R. Ranftl, A. Dosovitskiy, V . Koltun, and D. Scaramuzza, “Deep drone racing: Learning agile flight in dynamic environments.” PMLR, 2018, pp. 133–145
2018
-
[26]
Learning Minimum-Time Flight in Cluttered Environments,
R. Penicka, Y . Song, E. Kaufmann, and D. Scaramuzza, “Learning Minimum-Time Flight in Cluttered Environments,” IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 7209–7216, 2022
2022
-
[27]
Reinforcement learning for collision- free flight exploiting deep collision encoding,
M. Kulkarni and K. Alexis, “Reinforcement learning for collision- free flight exploiting deep collision encoding,” in 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 15 781–15 788. [Online]. Available: https://ieeexplore.ieee.org/abstract/ document/10610287
-
[28]
M. Kim, G. Bae, J. Lee, W. Shin, C. Kim, M.-Y . Choi, H. Shin, and H. Oh, “RAPID: Robust and agile planner using inverse reinforcement learning for vision-based drone navigation.” [Online]. Available: http://arxiv.org/abs/2502.02054
-
[29]
Champion-level drone racing using deep reinforcement learning,
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforcement learning,” vol. 620, no. 7976, pp. 982–987
-
[30]
Reach- ing the limit in autonomous racing: Optimal control versus reinforcement learning,
Y . Song, A. Romero, M. M ¨uller, V . Koltun, and D. Scaramuzza, “Reach- ing the limit in autonomous racing: Optimal control versus reinforcement learning,” Science Robotics, vol. 8, no. 82, p. eadg1462, 2023
2023
-
[31]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V . Ku- mar, H. Zhu, A. Gupta, P. Abbeel et al., “Soft actor-critic algorithms and applications,” arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review arXiv 2018
-
[33]
Integrated architectures for learning, planning, and reacting based on approximating dynamic programming,
R. S. Sutton, “Integrated architectures for learning, planning, and reacting based on approximating dynamic programming,” in Machine learning proceedings 1990. Elsevier, 1990, pp. 216–224
1990
-
[34]
When to trust your model: Model-based policy optimization,
M. Janner, J. Fu, M. Zhang, and S. Levine, “When to trust your model: Model-based policy optimization,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[35]
Deep reinforce- ment learning in a handful of trials using probabilistic dynamics models,
K. Chua, R. Calandra, R. McAllister, and S. Levine, “Deep reinforce- ment learning in a handful of trials using probabilistic dynamics models,” Advances in neural information processing systems, vol. 31, 2018
2018
-
[36]
Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning,
A. Nagabandi, G. Kahn, R. S. Fearing, and S. Levine, “Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 7559–7566
2018
-
[37]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learn- ing behaviors by latent imagination,” arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review arXiv 1912
-
[38]
Adaptive Barrier Smoothing for First-Order Policy Gradient with Contact Dynamics,
S. Zhang, W. Jin, and Z. Wang, “Adaptive Barrier Smoothing for First-Order Policy Gradient with Contact Dynamics,” in Proceedings of the 40th International Conference on Machine Learning. PMLR, Jul. 2023, pp. 41 219–41 243, iSSN: 2640-3498. [Online]. Available: https://proceedings.mlr.press/v202/zhang23s.html
2023
-
[39]
Do Differentiable Simulators Give Better Policy Gradients?
H. J. Suh, M. Simchowitz, K. Zhang, and R. Tedrake, “Do Differentiable Simulators Give Better Policy Gradients?” in Proceedings of the 39th International Conference on Machine Learning. PMLR, Jun. 2022, pp. 20 668–20 696, iSSN: 2640-3498. [Online]. Available: https://proceedings.mlr.press/v162/suh22b.html
2022
-
[40]
PODS: Policy Optimization via Differentiable Simulation,
M. A. Z. Mora, M. Peychev, S. Ha, M. Vechev, and S. Coros, “PODS: Policy Optimization via Differentiable Simulation,” in Proceedings of the 38th International Conference on Machine Learning. PMLR, Jul. 2021, pp. 7805–7817, iSSN: 2640-3498. [Online]. Available: https://proceedings.mlr.press/v139/mora21a.html
2021
-
[41]
VisFly: An Efficient and Versatile Simulator for Training Vision-based Flight,
F. Li, F. Sun, T. Zhang, and D. Zou, “VisFly: An Efficient and Versatile Simulator for Training Vision-based Flight,” Sep. 2024, arXiv:2407.14783. [Online]. Available: http://arxiv.org/abs/2407.14783 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18
-
[42]
Abpt: Amended backpropagation through time with partially differentiable rewards,
——, “Abpt: Amended backpropagation through time with partially differentiable rewards,” arXiv preprint arXiv:2501.14513, 2025
-
[43]
Learning on the fly: Rapid policy adaptation via differentiable simula- tion,
J. Pan, J. Xing, R. Reiter, Y . Zhai, E. Aljalbout, and D. Scaramuzza, “Learning on the fly: Rapid policy adaptation via differentiable simula- tion,” IEEE Robotics and Automation Letters, 2026
2026
-
[44]
Stable-baselines3: Reliable reinforcement learning implementa- tions,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-baselines3: Reliable reinforcement learning implementa- tions,” Journal of machine learning research, vol. 22, no. 268, pp. 1–8, 2021
2021
-
[45]
Accelerated Policy Learning with Parallel Differentiable Simulation,
J. Xu, V . Makoviychuk, Y . Narang, F. Ramos, W. Matusik, A. Garg, and M. Macklin, “Accelerated Policy Learning with Parallel Differentiable Simulation,” Apr. 2022, arXiv:2204.07137. [Online]. Available: http://arxiv.org/abs/2204.07137
-
[46]
Vins-mono: A robust and versatile monocular visual-inertial state estimator,
T. Qin, P. Li, and S. Shen, “Vins-mono: A robust and versatile monocular visual-inertial state estimator,” IEEE transactions on robotics, vol. 34, no. 4, pp. 1004–1020, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.