Recognition: unknown
Early Decisions Matter: Proximity Bias and Initial Trajectory Shaping in Non-Autoregressive Diffusion Language Models
Pith reviewed 2026-05-10 15:10 UTC · model grok-4.3
The pith
Proximity bias in non-autoregressive diffusion language models makes the full generation trajectory depend on the position of the first unmasked token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
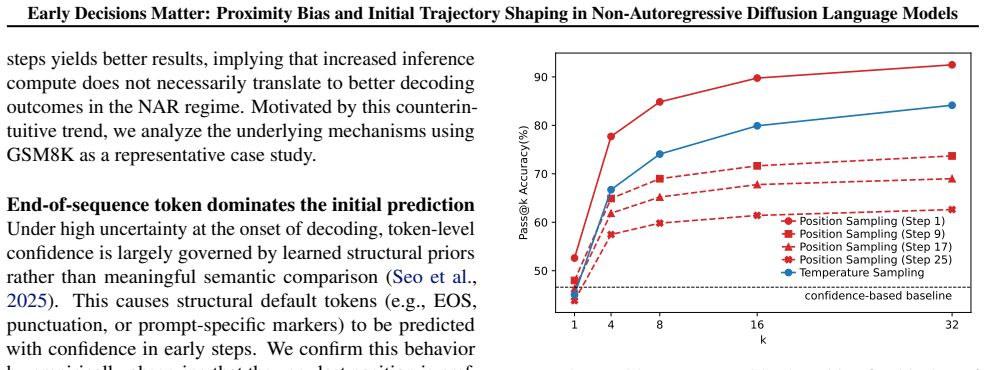
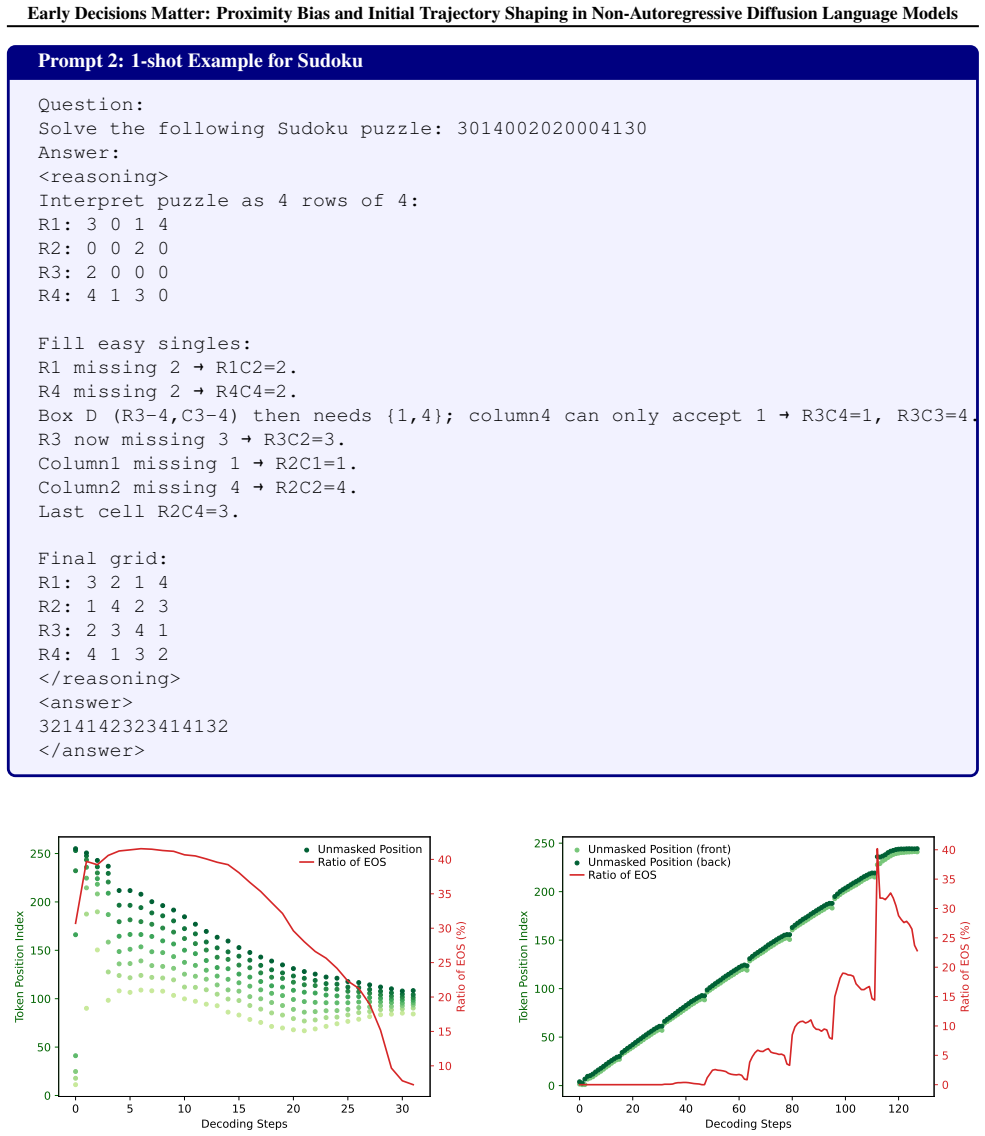
In confidence-based non-autoregressive generation for diffusion language models, the denoising order exhibits a strong proximity bias that concentrates unmasking on spatially adjacent tokens. This local dependency produces spatial error propagation, rendering the entire generation trajectory critically contingent on the initial unmasking position. A minimal-intervention method that employs a lightweight planner for early token selection and end-of-sequence temperature annealing delivers substantial gains over heuristic baselines on reasoning and planning tasks without meaningful overhead.
What carries the argument
The proximity bias in denoising order, which forces unmasking to favor nearby tokens and makes the starting unmasking position determine the quality of the full spatial trajectory.
If this is right
- The quality of non-autoregressive outputs is largely decided by the first few unmasking decisions rather than later refinement steps.
- Error propagation remains spatially local because the denoising order avoids distant tokens.
- Inference-time guidance of early positions can lift performance on complex tasks without retraining the underlying model.
- Temperature annealing at the sequence end stabilizes final tokens once the trajectory is set by initial choices.
Where Pith is reading between the lines
- The bias may arise from how diffusion models are trained on ordered data, so altering training order or objectives could reduce it at the source.
- Similar spatial concentration effects might appear in other iterative non-autoregressive generators outside the diffusion setting.
- Hybrid systems that mix limited autoregressive steps with diffusion could bypass the bias by handling the critical early tokens sequentially.
- The planner approach might scale to larger models but could require task-specific tuning to avoid introducing its own local traps.
Load-bearing premise
The observed proximity bias is the dominant cause of poor non-autoregressive performance and a lightweight planner plus temperature annealing will correct it reliably across tasks without new failure modes or significant overhead.
What would settle it
If experiments with random initial unmasking positions show no consistent variation in final generation quality, or if the planner-plus-annealing method produces no measurable improvement on a new set of reasoning tasks, the claim that proximity bias is the key failure mode would be falsified.
Figures












read the original abstract
Diffusion-based language models (dLLMs) have emerged as a promising alternative to autoregressive language models, offering the potential for parallel token generation and bidirectional context modeling. However, harnessing this flexibility for fully non-autoregressive decoding remains an open question, particularly for reasoning and planning tasks. In this work, we investigate non-autoregressive decoding in dLLMs by systematically analyzing its inference dynamics along the temporal axis. Specifically, we uncover an inherent failure mode in confidence-based non-autoregressive generation stemming from a strong proximity bias-the tendency for the denoising order to concentrate on spatially adjacent tokens. This local dependency leads to spatial error propagation, rendering the entire trajectory critically contingent on the initial unmasking position. Leveraging this insight, we present a minimal-intervention approach that guides early token selection, employing a lightweight planner and end-of-sequence temperature annealing. We thoroughly evaluate our method on various reasoning and planning tasks and observe substantial overall improvement over existing heuristic baselines without significant computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes non-autoregressive decoding dynamics in diffusion language models (dLLMs). It identifies a proximity bias in confidence-based token selection, where denoising concentrates on spatially adjacent tokens, causing spatial error propagation and making the full generation trajectory dependent on the initial unmasking position. The authors propose a minimal-intervention fix consisting of a lightweight planner for early token selection and end-of-sequence temperature annealing, claiming substantial improvements over heuristic baselines on reasoning and planning tasks with negligible overhead.
Significance. If the proximity bias is shown to be causal and the proposed planner plus annealing reliably corrects it across tasks, the work would provide a practical advance for non-autoregressive generation in dLLMs, enabling better parallel decoding for complex reasoning without heavy compute. The focus on inference-time dynamics offers a useful diagnostic lens, though the absence of detailed quantitative support and causal tests in the current presentation limits the assessed impact.
major comments (2)
- [analysis of denoising dynamics] The central claim that proximity bias is the mechanistic driver of spatial error propagation (abstract and analysis of denoising order) rests on observational evidence of adjacent-token concentration. A controlled intervention that breaks spatial locality while holding confidence scores fixed (e.g., re-ranking high-confidence candidates with an explicit anti-proximity penalty or uniform sampling over top-confidence tokens) is required to establish causality rather than correlation; without it, early-step confidence miscalibration or data-distribution effects remain plausible alternative drivers.
- [experimental evaluation] The abstract states 'substantial overall improvement' and 'thorough evaluation' on reasoning/planning tasks, yet provides no quantitative metrics, error bars, ablation tables, or experimental-setup details. If the full manuscript similarly omits these (or reports only point estimates without controls for the planner's contribution), the empirical support for the method's effectiveness and the claim that it avoids new failure modes cannot be assessed.
minor comments (2)
- Define the precise architecture and training of the 'lightweight planner' (e.g., parameter count, input features, whether it is task-specific) so readers can reproduce the minimal-intervention claim.
- Clarify how end-of-sequence temperature annealing interacts with the planner and whether it is applied only at the final step or throughout the trajectory.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our analysis of denoising dynamics in diffusion language models. We address each major comment below with clarifications and planned revisions to strengthen the causal claims and empirical presentation.
read point-by-point responses
-
Referee: The central claim that proximity bias is the mechanistic driver of spatial error propagation (abstract and analysis of denoising order) rests on observational evidence of adjacent-token concentration. A controlled intervention that breaks spatial locality while holding confidence scores fixed (e.g., re-ranking high-confidence candidates with an explicit anti-proximity penalty or uniform sampling over top-confidence tokens) is required to establish causality rather than correlation; without it, early-step confidence miscalibration or data-distribution effects remain plausible alternative drivers.
Authors: We acknowledge that the current evidence for proximity bias as the primary driver is observational. To establish causality, we will add a controlled ablation in the revised manuscript: during early denoising steps, we will re-rank the top-confidence tokens using an explicit anti-proximity penalty (while preserving the original confidence values) and compare generation trajectories and error propagation against the baseline selection. We will also analyze the planner's intervention as a direct disruption of spatial locality in initial unmasking. This should help rule out alternative explanations such as confidence miscalibration. revision: yes
-
Referee: The abstract states 'substantial overall improvement' and 'thorough evaluation' on reasoning/planning tasks, yet provides no quantitative metrics, error bars, ablation tables, or experimental-setup details. If the full manuscript similarly omits these (or reports only point estimates without controls for the planner's contribution), the empirical support for the method's effectiveness and the claim that it avoids new failure modes cannot be assessed.
Authors: The full manuscript includes quantitative comparisons on reasoning and planning tasks along with ablation studies on the planner and annealing components. To improve transparency, we will revise the experimental section to report error bars across multiple random seeds, expanded ablation tables that isolate the planner's contribution from annealing, and additional details on experimental setups and hyperparameters. We will also include analysis addressing potential new failure modes introduced by the interventions. revision: yes
Circularity Check
No circularity: claims rest on empirical observation of denoising order, not self-referential definitions or fitted predictions
full rationale
The paper identifies proximity bias through direct inspection of confidence-based token selection sequences in non-autoregressive diffusion decoding. This is presented as an observed pattern in inference dynamics rather than a quantity derived from or defined in terms of the error propagation it is said to cause. The subsequent lightweight planner and temperature annealing are introduced as a minimal intervention motivated by the observation, without any equations that reduce the intervention's success metric to the bias measurement by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core premises. The analysis remains self-contained against external task benchmarks and does not rename known results or treat fitted parameters as predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
URL https://openreview.net/forum? id=WBcBhT1NKO. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901, 2020. Campbell, A., Benton, J., De Bortoli, V ., Rainforth, T., Deli- ...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[2]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J
URL https://openreview.net/forum? id=j1tSLYKwg8. Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Process- ing Systems Datasets and Benchmarks Track (Round 2),
-
[3]
Ho, J., Jain, A., and Abbeel, P
URL https://openreview.net/forum? id=7Bywt2mQsCe. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion proba- bilistic models.Advances in neural information process- ing systems, 33:6840–6851, 2020. Israel, D. M., den Broeck, G. V ., and Grover, A. Ac- celerating diffusion LLMs via adaptive parallel decod- ing. InThe Thirty-ninth Annual Conference on Neur...
2020
-
[4]
Diffusion Language Models Know the Answer Before Decoding
URL https://openreview.net/forum? id=cznTlh7Msz. Kim, J., Shah, K., Kontonis, V ., Kakade, S. M., and Chen, S. Train for the worst, plan for the best: Under- standing token ordering in masked diffusions. InForty- second International Conference on Machine Learning, 2025a. URL https://openreview.net/forum? id=DjJmre5IkP. Kim, S. H., Hong, S., Jung, H., Par...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
org/CorpusID:276161145
URL https://api.semanticscholar. org/CorpusID:276161145. Sahoo, S. S., Arriola, M., Gokaslan, A., Marroquin, E. M., Rush, A. M., Schiff, Y ., Chiu, J. T., and Kuleshov, V . Simple and effective masked diffusion language mod- els. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=L4ua...
2024
-
[6]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://openreview.net/forum? id=HvIRFV0J90. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. Shi, J., Han, K., Wang, Z., Doucet, A., and Titsias, M. Simplified and generalized...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
wd1: Weighted policy optimization for reasoning in diffusion language models
URL https://openreview.net/forum? id=PxTIG12RRHS. Tang, X., Dolga, R., Yoon, S., and Bogunovic, I. wd1: Weighted policy optimization for reasoning in diffusion language models.ArXiv, abs/2507.08838,
-
[8]
LLaMA: Open and Efficient Foundation Language Models
URL https://api.semanticscholar. org/CorpusID:280280745. Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971, 2023. Wagenmaker, A., Nakamoto, M., Zhang, Y ., Park, S., Yagoub, W., Nagaba...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Subsequent studies further refined the formulation of discrete diffusion
to discrete state spaces by defining categorical for- ward noising and reverse denoising processes. Subsequent studies further refined the formulation of discrete diffusion. Campbell et al. (2022) modeled the forward and backward processes over discrete variables as continuous-time Markov chains, enabling principled derivation of training objectives and s...
2022
-
[10]
Start with the largest number, 89, and try to use it in the expression
-
[11]
Let’s try: - 89 - 37 = 52 - 52 - 41 = 11 So, the expression is 89 - 37 - 41 = 11
Use the subtraction operation to get the target number 11. Let’s try: - 89 - 37 = 52 - 52 - 41 = 11 So, the expression is 89 - 37 - 41 = 11. This expression uses each number exactly once and evaluates to the target number 11. </reasoning> <answer> \boxed{89 - 37 - 41}</answer> high confidence rapidly accumulates at the end of the se- quence. As diffusion ...
-
[12]
Input Projection:The hidden states from the diffusion backbone (D= 4096 ) are first projected down to the planner’s dimension (dmodel = 128)
-
[13]
Lightweight Positional Embedding:Positional em- beddings with a low dimension ( dpos = 16 ) are pro- jected to dmodel = 128 to be added to the input fea- tures then input to the transformer layer with ReLU activation in between
-
[14]
Final score for the sampled embeddings is obtained as an average of these values
Scoring Head:The transformer outputs for each token are projected to a scalar value. Final score for the sampled embeddings is obtained as an average of these values. Training ConfigurationThe planner is trained using the Binary Cross Entropy loss. We employ the AdamW opti- mizer with a fixed learning rate of 1e-4 and a batch size of 256. To prevent overf...
2025
-
[15]
Zero-Cost Annealing:The EOS temperature annealing requires only a simple scalar multiplication, adding no measurable delay. Training Compute OverheadOur method is excep- tionally lightweight, especially when contrasted with the massive memory and compute requirements of standard model alignment techniques in RLVR or standard RLHF paradigms (Ouyang et al.,...
2022
-
[16]
Without the need for gradient computation or optimizer states for the large language model, the peak memory footprint is drastically reduced
Offline Trajectory Generation (Inference-Only):Sam- pling training data requires an upfront compute invest- ment but is strictly a forward-pass operation on a frozen backbone. Without the need for gradient computation or optimizer states for the large language model, the peak memory footprint is drastically reduced. Moreover, this is a one-time, highly pa...
-
[17]
Planner Optimization (Lightweight Training):Since gradients are strictly confined to 5M-parameter planner, the training converges rapidly—taking approximately 5 minutes on a single A100 GPU—with a negligible memory footprint. By isolating the 8B model entirely to inference and restrict- ing backpropagation exclusively to the 5M planner module, our approac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.