Recognition: unknown
AffordGen: Generating Diverse Demonstrations for Generalizable Object Manipulation with Afford Correspondence
Pith reviewed 2026-05-10 16:17 UTC · model grok-4.3
The pith
By matching semantic keypoints across 3D meshes, AffordGen generates varied manipulation trajectories that let trained policies succeed on objects never seen in the original data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
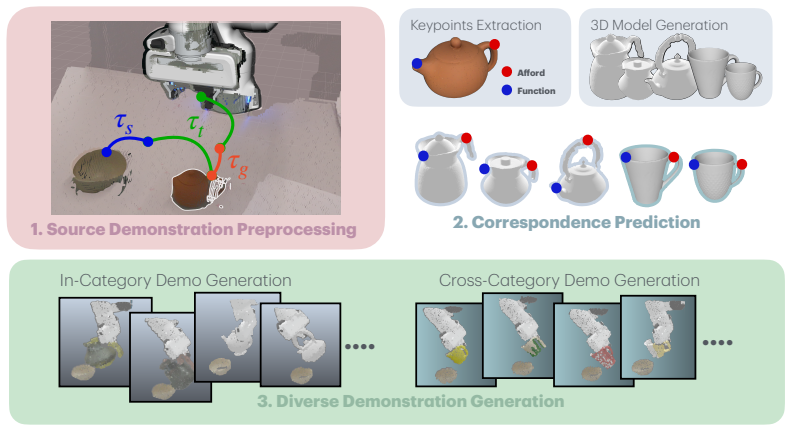
AffordGen produces new, affordance-consistent robot manipulation trajectories by propagating actions through semantic keypoint correspondences identified across large-scale 3D object meshes; the expanded dataset then trains an end-to-end policy that merges the semantic generalizability of affordances with the robustness of reactive visuomotor control.
What carries the argument
Semantic correspondence of meaningful keypoints across large-scale 3D meshes, used to transfer and diversify manipulation trajectories while preserving affordance structure.
If this is right
- Policies trained on the generated data achieve high success rates in both simulation and real-world closed-loop execution.
- Zero-shot generalization to objects never present in the original human demonstrations becomes feasible.
- Data efficiency increases because one set of base demonstrations can be expanded into a diverse training corpus without additional human collection.
- The combination of affordance-level semantic transfer and end-to-end reactive control improves robustness to geometric variation.
Where Pith is reading between the lines
- The method could reduce the need for large-scale human teleoperation if high-quality 3D meshes are already available for target object classes.
- Extending the same correspondence principle to articulated objects or multi-object scenes would test whether the approach scales beyond rigid single-object pick-and-place.
- If mesh quality or keypoint detection accuracy drops, the generated trajectories may introduce systematic biases that closed-loop policies cannot fully correct.
Load-bearing premise
Semantic correspondence of meaningful keypoints across large-scale 3D meshes can reliably generate new, valid, and useful robot manipulation trajectories that transfer to real-world closed-loop control.
What would settle it
A set of generated trajectories that produce physically unstable grasps or collisions on objects whose keypoint matches do not preserve contact geometry would falsify the claim that the correspondence step yields valid demonstrations.
Figures
















read the original abstract
Despite the recent success of modern imitation learning methods in robot manipulation, their performance is often constrained by geometric variations due to limited data diversity. Leveraging powerful 3D generative models and vision foundation models (VFMs), the proposed AffordGen framework overcomes this limitation by utilizing the semantic correspondence of meaningful keypoints across large-scale 3D meshes to generate new robot manipulation trajectories. This large-scale, affordance-aware dataset is then used to train a robust, closed-loop visuomotor policy, combining the semantic generalizability of affordances with the reactive robustness of end-to-end learning. Experiments in simulation and the real world show that policies trained with AffordGen achieve high success rates and enable zero-shot generalization to truly unseen objects, significantly improving data efficiency in robot learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AffordGen, a framework that generates diverse robot manipulation demonstrations by leveraging semantic keypoint correspondence across 3D meshes using vision foundation models and 3D generative models. Starting from limited demonstrations, it creates a large affordance-aware dataset to train closed-loop visuomotor policies, claiming high success rates and zero-shot generalization to unseen objects in both simulation and real-world settings, thereby improving data efficiency in imitation learning for object manipulation.
Significance. If the central claims hold, this work could be significant for the field of robot learning by addressing the data scarcity issue through scalable generation of demonstrations from 3D assets. The use of affordance correspondence to transfer trajectories is a novel way to combine generative models with policy learning. The inclusion of real-world experiments strengthens the practical relevance. Strengths include the integration of external foundation models for generalization.
major comments (2)
- [Section 3.2] Section 3.2: The trajectory generation process via keypoint correspondence is described, but there is no quantitative evaluation of the validity of the transferred trajectories, such as success rate of the generated demos in simulation or metrics for collision avoidance and kinematic feasibility. This is load-bearing for the generalization claim because semantic correspondence alone may not ensure physical feasibility when meshes differ in curvature or topology.
- [Section 5.2, Table 2] Section 5.2, Table 2: The reported success rates for zero-shot generalization to unseen objects are high, but without details on the number of trials, variance, or comparison to baselines that use only original data or random augmentation, it is difficult to attribute the improvement specifically to AffordGen rather than other factors like policy architecture or simulation randomization.
minor comments (2)
- [Abstract] The abstract mentions 'high success rates' and 'significantly improving data efficiency' but lacks specific numbers or references to figures/tables; consider adding quantitative highlights.
- [Figure 3] The visualization of generated trajectories could benefit from annotations showing contact points or potential failure modes to illustrate the affordance correspondence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify and strengthen our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2: The trajectory generation process via keypoint correspondence is described, but there is no quantitative evaluation of the validity of the transferred trajectories, such as success rate of the generated demos in simulation or metrics for collision avoidance and kinematic feasibility. This is load-bearing for the generalization claim because semantic correspondence alone may not ensure physical feasibility when meshes differ in curvature or topology.
Authors: We agree that direct quantitative validation of the transferred trajectories is important to support the generalization claims. The current manuscript evaluates the approach primarily via downstream policy success rates in simulation and real-world experiments. In the revised version, we will add to Section 3.2 a quantitative analysis of trajectory validity, including: (i) success rates when executing the generated demonstrations in simulation, (ii) collision avoidance metrics (percentage of trajectories without self-collisions or environment collisions), and (iii) kinematic feasibility via IK solver success rates. These additions will demonstrate that affordance correspondences produce physically plausible trajectories across varying mesh topologies. revision: yes
-
Referee: [Section 5.2, Table 2] Section 5.2, Table 2: The reported success rates for zero-shot generalization to unseen objects are high, but without details on the number of trials, variance, or comparison to baselines that use only original data or random augmentation, it is difficult to attribute the improvement specifically to AffordGen rather than other factors like policy architecture or simulation randomization.
Authors: We concur that more detailed statistics and targeted baselines are needed to isolate AffordGen's contribution. The manuscript reports average success rates in Table 2, but we will revise Section 5.2 and Table 2 to specify the number of trials per object (100 trials), include standard deviations, and add comparisons against two baselines: (1) policies trained solely on the original limited demonstrations and (2) policies trained with random augmentations (without affordance-based correspondence). These changes will provide stronger evidence that the performance gains stem from the affordance-aware generated data. revision: yes
Circularity Check
No circularity: derivation uses external 3D generative models and VFMs without self-referential reduction
full rationale
The abstract and described framework rely on semantic correspondence from external vision foundation models and 3D generative models to create new trajectories, followed by standard policy training. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce the zero-shot generalization claim to its own inputs by construction. The central mechanism is presented as an application of independent external tools rather than a closed self-definition or renaming of known results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
AffordGen framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Genaug: Retargeting behaviors to unseen situations via generative augmentation, 2023
Zoey Chen, Sho Kiami, Abhishek Gupta, and Vikash Ku- mar. Genaug: Retargeting behaviors to unseen situations via generative augmentation, 2023. 2
2023
-
[2]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffu- sion policy: Visuomotor policy learning via action diffusion. ArXiv, abs/2303.04137, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[3]
Peter R Florence, Lucas Manuelli, and Russ Tedrake. Dense object nets: Learning dense visual object descriptors by and for robotic manipulation.arXiv preprint arXiv:1806.08756,
-
[4]
Skillmimicgen: Automated demonstration generation for efficient skill learning and deployment, 2024
Caelan Garrett, Ajay Mandlekar, Bowen Wen, and Dieter Fox. Skillmimicgen: Automated demonstration generation for efficient skill learning and deployment, 2024. 2
2024
-
[5]
Kaizhe Hu, Zihang Rui, Yao He, Yuyao Liu, and Pu Hua. Generalizable visual imitation learning with stem-like con- vergent observation through diffusion inversion.arXiv preprint arXiv:2411.04919, 1, 2024. 2
-
[6]
Gensim2: Scal- ing robot data generation with multi-modal and reasoning llms, 2024
Pu Hua, Minghuan Liu, Annabella Macaluso, Yunfeng Lin, Weinan Zhang, Huazhe Xu, and Lirui Wang. Gensim2: Scal- ing robot data generation with multi-modal and reasoning llms, 2024. 2
2024
-
[7]
Dexmim- icgen: Automated data generation for bimanual dexterous manipulation via imitation learning, 2025
Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi Fan, and Yuke Zhu. Dexmim- icgen: Automated data generation for bimanual dexterous manipulation via imitation learning, 2025. 2
2025
-
[8]
Robo-abc: Affordance gener- alization beyond categories via semantic correspondence for robot manipulation
Yuanchen Ju, Kaizhe Hu, Guowei Zhang, Gu Zhang, Min- grun Jiang, and Huazhe Xu. Robo-abc: Affordance gener- alization beyond categories via semantic correspondence for robot manipulation. InEuropean Conference on Computer Vision, 2024. 2, 3
2024
-
[9]
Ram: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation
Yuxuan Kuang, Junjie Ye, Haoran Geng, Jiageng Mao, Congyue Deng, Leonidas Guibas, He Wang, and Yue Wang. Ram: Retrieval-based affordance transfer for gen- eralizable zero-shot robotic manipulation.arXiv preprint arXiv:2407.04689, 2024. 3
-
[10]
Data scaling laws in im- itation learning for robotic manipulation
Fanqi Lin, Yingdong Hu, Pingyue Sheng, Chuan Wen, Ji- acheng You, and Yang Gao. Data scaling laws in imitation learning for robotic manipulation.ArXiv, abs/2410.18647,
-
[11]
Constraint-preserving data generation for visuomotor policy learning, 2025
Kevin Lin, Varun Ragunath, Andrew McAlinden, Aa- ditya Prasad, Jimmy Wu, Yuke Zhu, and Jeannette Bohg. Constraint-preserving data generation for visuomotor policy learning, 2025. 2, 6
2025
-
[12]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipu- lation.ArXiv, abs/2410.07864, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[13]
Cacti: A framework for scalable multi-task multi-scene visual imita- tion learning, 2023
Zhao Mandi, Homanga Bharadhwaj, Vincent Moens, Shu- ran Song, Aravind Rajeswaran, and Vikash Kumar. Cacti: A framework for scalable multi-task multi-scene visual imita- tion learning, 2023. 2
2023
-
[14]
Mimicgen: A data generation system for scalable robot learning using human demonstrations, 2023
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations, 2023. 2
2023
-
[15]
kpam: Keypoint affordances for category-level robotic ma- nipulation
Lucas Manuelli, Wei Gao, Peter Florence, and Russ Tedrake. kpam: Keypoint affordances for category-level robotic ma- nipulation. InThe International Symposium of Robotics Re- search, pages 132–157. Springer, 2019. 3
2019
-
[16]
Robocasa: Large-scale simulation of every- day tasks for generalist robots, 2024
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of every- day tasks for generalist robots, 2024. 2
2024
-
[17]
Dinov2: Learning robust visual features with- out supervision, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
2024
-
[18]
Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints
Mingjie Pan, Jiyao Zhang, Tianshu Wu, Yinghao Zhao, Wen- long Gao, and Hao Dong. Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17359–17369,
-
[19]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Animating rotation with quaternion curves
Ken Shoemake. Animating rotation with quaternion curves. InProceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques, page 245–254, New York, NY , USA, 1985. Association for Computing Machin- ery. 5
1985
-
[21]
Neural descriptor fields: Se (3)- equivariant object representations for manipulation
Anthony Simeonov, Yilun Du, Andrea Tagliasacchi, Joshua B Tenenbaum, Alberto Rodriguez, Pulkit Agrawal, and Vincent Sitzmann. Neural descriptor fields: Se (3)- equivariant object representations for manipulation. In 2022 International Conference on Robotics and Automation (ICRA), pages 6394–6400. IEEE, 2022. 3
2022
-
[22]
Hrp: Human affordances for robotic pre- training
Mohan Kumar Srirama, Sudeep Dasari, Shikhar Bahl, and Abhinav Gupta. Hrp: Human affordances for robotic pre- training. InRobotics: Science and Systems (RSS), Delft, Netherlands, 2024. 3
2024
-
[23]
Chao Tang, Anxing Xiao, Yuhong Deng, Tianrun Hu, Wen- long Dong, Hanbo Zhang, David Hsu, and Hong Zhang. Functo: Function-centric one-shot imitation learning for tool manipulation.ArXiv, abs/2502.11744, 2025. 2, 3, 7
-
[24]
Mimicfunc: Imitating tool manipulation from a single human video via functional correspondence,
Chao Tang, Anxing Xiao, Yuhong Deng, Tianrun Hu, Wen- long Dong, Hanbo Zhang, David Hsu, and Hong Zhang. Mimicfunc: Imitating tool manipulation from a single hu- man video via functional correspondence.arXiv preprint arXiv:2508.13534, 2025. 3
-
[25]
Emergent correspondence from image diffusion.Advances in Neural Information Pro- cessing Systems, 36:1363–1389, 2023
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent correspondence from image diffusion.Advances in Neural Information Pro- cessing Systems, 36:1363–1389, 2023. 3
2023
-
[26]
Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embod- ied ai.Robotics: Science and Systems, 2025
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse kai Chan, Yuan Gao, Xuanlin Li, Tongzhou Mu, Nan Xiao, Arnav Gurha, Viswesh Nagaswamy Rajesh, Yong Woo Choi, Yen-Ru Chen, Zhiao Huang, Roberto Calandra, Rui Chen, Shan Luo, and Hao Su. Maniskill3: Gpu parallelized robotics simulation and r...
2025
-
[27]
Hunyuan3d 2.0: Scaling diffu- sion models for high resolution textured 3d assets generation,
Tencent Hunyuan3D Team. Hunyuan3d 2.0: Scaling diffu- sion models for high resolution textured 3d assets generation,
-
[28]
A careful examination of large behavior mod- els for multitask dexterous manipulation, 2025
TRI LBM Team, Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching- Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, Naveen Kuppuswamy, Kuan-Hui Lee, Katherine Liu, Dale McConachie, Ian McMahon, Haruki Nishimura, Calder Phillips-Grafflin, Charles Richter, Paarth Shah, Krishnan Srinivasan, Blake W...
2025
-
[29]
Mimicplay: Long-horizon imitation learning by watching human play
Chen Wang, Linxi (Jim) Fan, Jiankai Sun, Ruohan Zhang, Li Fei-Fei, Danfei Xu, Yuke Zhu, and Anima Anandkumar. Mimicplay: Long-horizon imitation learning by watching human play. InConference on Robot Learning, 2023. 1
2023
-
[30]
Gensim: Generating robotic simulation tasks via large language models, 2024
Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiao- long Wang. Gensim: Generating robotic simulation tasks via large language models, 2024. 2
2024
-
[31]
Robogen: Towards unleashing infi- nite data for automated robot learning via generative simula- tion, 2024
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards unleashing infi- nite data for automated robot learning via generative simula- tion, 2024. 2
2024
-
[32]
Afforddp: Gen- eralizable diffusion policy with transferable affordance
Shijie Wu, Yihang Zhu, Yunao Huang, Kaizhen Zhu, Jiayuan Gu, Jingyi Yu, Ye Shi, and Jingya Wang. Afforddp: Gen- eralizable diffusion policy with transferable affordance. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 6971–6980, 2025. 3
2025
-
[33]
Demogen: Synthetic demonstration generation for data-efficient vi- suomotor policy learning, 2025
Zhengrong Xue, Shuying Deng, Zhenyang Chen, Yixuan Wang, Zhecheng Yuan, and Huazhe Xu. Demogen: Syn- thetic demonstration generation for data-efficient visuomo- tor policy learning.ArXiv, abs/2502.16932, 2025. 1, 2, 5, 6
-
[34]
Scaling robot learning with semantically imagined experi- ence, 2023
Tianhe Yu, Ted Xiao, Austin Stone, Jonathan Tompson, An- thony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Dee M, Jodilyn Peralta, Brian Ichter, Karol Hausman, and Fei Xia. Scaling robot learning with semantically imagined experi- ence, 2023. 2
2023
-
[35]
Zhecheng Yuan, Sizhe Yang, Pu Hua, Cancer Suk Chul Chang, Kaizhe Hu, Xiaolong Wang, and Huazhe Xu. Rl- vigen: A reinforcement learning benchmark for visual gen- eralization.ArXiv, abs/2307.10224, 2023. 1
-
[36]
3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d repre- sentations, 2024
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d repre- sentations, 2024. 1, 4
2024
-
[37]
A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence.Advances in Neural Information Processing Systems, 36:45533–45547,
Junyi Zhang, Charles Herrmann, Junhwa Hur, Luisa Pola- nia Cabrera, Varun Jampani, Deqing Sun, and Ming-Hsuan Yang. A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence.Advances in Neural Information Processing Systems, 36:45533–45547,
-
[38]
Omni6dpose: A benchmark and model for universal 6d object pose esti- mation and tracking
Jiyao Zhang, Weiyao Huang, Bo Peng, Mingdong Wu, Fei Hu, Zijian Chen, Bo Zhao, and Hao Dong. Omni6dpose: A benchmark and model for universal 6d object pose esti- mation and tracking. InEuropean Conference on Computer Vision, pages 199–216. Springer, 2024. 4, 6, 3
2024
-
[39]
Junzhe Zhu, Yuanchen Ju, Junyi Zhang, Muhan Wang, Zhecheng Yuan, Kaizhe Hu, and Huazhe Xu. Dense- matcher: Learning 3d semantic correspondence for category- level manipulation from a single demo.arXiv preprint arXiv:2412.05268, 2024. 2, 3, 4 AffordGen: Generating Diverse Demonstrations for Generalizable Object Manipulation with Affordance Correspondence S...
-
[40]
Point Cloud Processing We follow the preprocessing pipeline for point cloud obser- vations as outlined in DP3 [36]
Hyperparameters 6.1. Point Cloud Processing We follow the preprocessing pipeline for point cloud obser- vations as outlined in DP3 [36]. For simulation tasks, we directly apply Farthest Point Sampling (FPS) to downsam- ple the point cloud to1024points. For real-world tasks, we collect point clouds using a RealSense L515 camera at a depth image resolution ...
-
[41]
Experiment Details 7.1. Task Description We summarize the four tasks (which are the same for both simulation and real-world setups) as follows: •Teapot Pouring:Grasp the handle, position the spout above the cup, and tilt beyond a threshold angle. •Mug Hanging:Grasp the handle and hang the mug by threading its handle onto the rack. •Knife Cutting:Grasp the...
2014
-
[42]
3D Mesh Dataset Pre-processing To obtain a sufficient number of meshes for a specific cat- egory, we leveraged an existing 3D generative model [27]
3D Mesh Dataset 8.1. 3D Mesh Dataset Pre-processing To obtain a sufficient number of meshes for a specific cat- egory, we leveraged an existing 3D generative model [27]. For the teapot and mug categories, the generated meshes are almost upright, with their in-plane rotations (within the XY plane) typically aligning with one of the four cardinal an- gles: ...
-
[43]
Data Generation Details Given that the generated trajectories may vary in length from the original ones, we sample the goal object point cloud from random timestamps (excluding the skill seg- ment) of the source demonstration to serve as the goal ob- ject point cloud for the new demonstration. To preserve the visual authenticity of the occlusions that occ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.