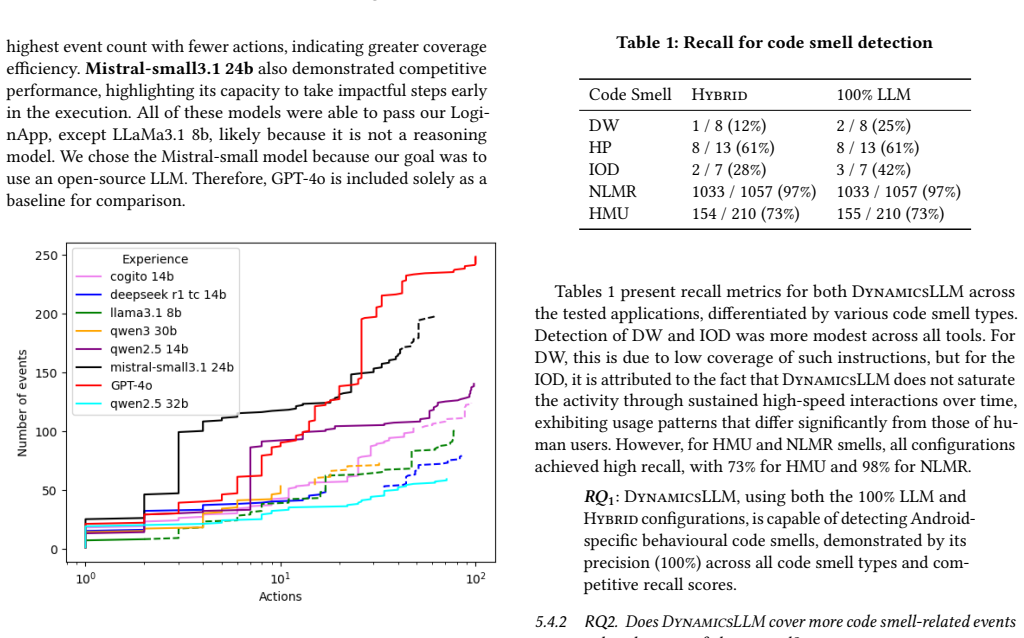
Recognition: unknown
DynamicsLLM: a Dynamic Analysis-based Tool for Generating Intelligent Execution Traces Using LLMs to Detect Android Behavioural Code Smells
Pith reviewed 2026-05-10 15:42 UTC · model grok-4.3
The pith
DynamicsLLM uses LLMs to generate execution traces that detect three times more Android behavioral code smells than prior dynamic analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that DynamicsLLM, by leveraging LLMs to intelligently generate execution traces, covers three times more code smell-related events than the Dynamics tool when limited to the same number of actions. A novel hybrid approach combining LLM and traditional methods improves coverage by 25.9% for applications with few activities. Furthermore, the tool successfully triggers 12.7% of the code smell-related events that the original Dynamics method cannot reach, as validated on 333 F-Droid applications.
What carries the argument
The key mechanism is the use of LLMs to produce intelligent execution traces, defined as targeted sequences of actions that trigger the runtime behaviors associated with code smells.
If this is right
- Apps with limited activities benefit from the hybrid LLM-traditional method for higher detection rates.
- More code smell instances become detectable without increasing the number of test actions required.
- The method extends dynamic analysis capabilities to reach events previously missed by non-LLM approaches.
- Results from testing on hundreds of real-world apps indicate practical utility for developers.
Where Pith is reading between the lines
- Extending this to other programming languages or platforms could broaden automated smell detection beyond Android.
- Reducing false positives in LLM-generated traces would make the tool more reliable for production use.
- Combining with static analysis tools might yield even higher overall detection accuracy.
Load-bearing premise
That the execution traces generated by the LLM reliably trigger the intended behavioral code smells and that the identification process maintains a low rate of false positives across diverse applications.
What would settle it
A direct comparison on an independent set of Android apps where manual verification shows no increase in detected smells or reveals high false positive rates in the LLM-generated traces.
Figures






read the original abstract
Mobile apps have become essential of our daily lives, making code quality a critical concern for developers. Behavioural code smells are characteristics in the source code that induce inappropriate code behaviour during execution, which negatively impact software quality in terms of performance, energy consumption, and memory. Dynamics, the latest state-of-the-art tool-based method, is highly effective at detecting Android behavioural code smells. While it outperforms static analysis tools, it suffers from a high false negative rate, with multiple code smell instances remaining undetected. Large Language Models (LLMs) have achieved notable advances across numerous research domains and offer significant potential for generating intelligent execution traces, particularly for detecting behavioural code smells in Android mobile applications. By intelligent execution trace, we mean a sequence of events generated by specific actions in a way that triggers the identification of a given behaviour. We propose the following three main contributions in this paper: (1) DynamicsLLM, an enhanced implementation of the Dynamics method that leverages LLMs to intelligently generate execution traces. (2) A novel hybrid approach designed to improve the coverage of code smell-related events in applications with a small number of activities. (3) A comprehensive validation of DynamicsLLM on 333 mobile applications from F-DROID, including a comparison with the Dynamics tool. Our results show that, under a limited number of actions, DynamicsLLM configured with 100% LLM covers three times more code smell-related events than Dynamics. The hybrid approach improves LLM coverage by 25.9% for apps containing few activities. Moreover, 12.7% of the code smell-related events that cannot be triggered by Dynamics are successfully triggered by our tool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DynamicsLLM, an extension of the Dynamics dynamic analysis tool that integrates Large Language Models to generate intelligent execution traces for detecting behavioral code smells in Android applications. It proposes a hybrid LLM-Dynamics strategy to boost coverage in apps with few activities and reports a large-scale evaluation on 333 F-Droid apps. The central claims are that, under a limited number of actions, a 100% LLM configuration covers three times more code smell-related events than Dynamics, the hybrid improves LLM coverage by 25.9% for low-activity apps, and the tool triggers 12.7% of events missed by Dynamics.
Significance. If the coverage gains can be shown to rest on validated trace correctness rather than unmeasured false positives, the work would offer a useful demonstration of LLM augmentation for dynamic analysis in mobile software quality, addressing the acknowledged high false-negative rate of prior dynamic tools. The scale of the 333-app F-Droid corpus and explicit comparison against the Dynamics baseline are strengths that could support follow-on research if the measurement methodology is clarified.
major comments (2)
- [Abstract] Abstract: The headline quantitative claims (3x coverage with 100% LLM, 25.9% hybrid improvement, 12.7% additional events) are presented without any definition of how 'code smell-related events' are identified or counted, without reported false-positive rates, statistical significance tests, error bars, or details on LLM prompt construction, validation, and stability. These omissions are load-bearing because the central contribution rests on the assumption that LLM traces reliably trigger and correctly classify true behavioral smells rather than inflating counts via over-triggering.
- [Evaluation] Evaluation section: No systematic manual validation, ablation on prompt sensitivity, or false-positive analysis is described for the LLM-generated traces on the 333 apps. Without such controls, it is impossible to determine whether the reported gains reflect genuine behavioral coverage or artifacts of the LLM prompting and downstream detector, directly affecting the reliability of the comparison to Dynamics.
minor comments (2)
- [Abstract] Abstract: The sentence 'Mobile apps have become essential of our daily lives' contains a grammatical error and should read 'essential to our daily lives'.
- The term 'intelligent execution trace' is introduced in the abstract but not given a precise operational definition that distinguishes it from standard execution traces; this should be clarified early in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of methodological transparency and validation that we will address in the revision. We respond point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claims (3x coverage with 100% LLM, 25.9% hybrid improvement, 12.7% additional events) are presented without any definition of how 'code smell-related events' are identified or counted, without reported false-positive rates, statistical significance tests, error bars, or details on LLM prompt construction, validation, and stability. These omissions are load-bearing because the central contribution rests on the assumption that LLM traces reliably trigger and correctly classify true behavioral smells rather than inflating counts via over-triggering.
Authors: We agree the abstract is too terse on these points. In the revised version we will add a concise definition of 'code smell-related events' (events that activate the rule-based detectors ported from Dynamics) and a brief note on prompt construction. We will also reference the Evaluation section for LLM details and add statistical significance tests plus error bars to the reported results. The downstream detector is identical to the validated Dynamics implementation, so false-positive rates for smell classification are unchanged; however, we will clarify this assumption and discuss potential over-triggering risks. revision: partial
-
Referee: [Evaluation] Evaluation section: No systematic manual validation, ablation on prompt sensitivity, or false-positive analysis is described for the LLM-generated traces on the 333 apps. Without such controls, it is impossible to determine whether the reported gains reflect genuine behavioral coverage or artifacts of the LLM prompting and downstream detector, directly affecting the reliability of the comparison to Dynamics.
Authors: We acknowledge that the current Evaluation section lacks explicit controls for trace validity. We will add a new subsection reporting manual inspection of a random sample of 50 LLM-generated traces (verifying executable UI sequences and alignment with detected smells). We will also include an ablation on prompt variations performed on a 20-app subset and expand the false-positive discussion by analyzing discrepant detections between Dynamics and DynamicsLLM on that subset. These additions will be feasible without altering the scale of the 333-app corpus. revision: partial
Circularity Check
No circularity in empirical comparison
full rationale
The paper reports direct empirical measurements of code-smell event coverage on 333 independent F-Droid apps when running DynamicsLLM (with 100% LLM and hybrid modes) versus the external prior Dynamics tool. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or described contributions; the 3x coverage, 25.9% hybrid gain, and 12.7% additional events are presented as observed outcomes from tool execution rather than quantities derived by construction from the inputs. The derivation chain is therefore self-contained as a standard tool-comparison study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024.Mobile Application Coverage: The 30% Curse and Ways Forward
Faridah Akinotcho, Lili Wei, and Julia Rubin. 2024.Mobile Application Coverage: The 30% Curse and Ways Forward. Ph. D. Dissertation. University of British Columbia. DynamicsLLM: a Dynamic Analysis-based Tool for Generating Intelligent Execution Traces Using LLMs to Detect Android Behavioural Code Smells FORGE ’26, April 12–13, 2026, Rio de Janeiro, Brazil
2024
-
[2]
Mohammed K. Alzaylaee, Suleiman Y. Yerima, and Sakir Sezer. 2017. Improving dynamic analysis of Android apps using hybrid test input generation. In2017 International Conference on Cyber Security and Protection of Digital Services (Cyber Security). 1–8. doi:10.1109/CyberSecPODS.2017.8074845
-
[3]
Larisse Amorim, Ivandeclei Mendes da Costa, Leticia Alves, and Eduardo Figueiredo. 2025. Bad Smell Detection using Google Gemini. In2025 IEEE 49th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 1637– 1642
2025
-
[4]
Android. 2025. Android Debug Bridge (adb). https://developer.android.com/ studio/command-line/adb
2025
-
[5]
Anonymous. 2025. Replication Package. https://figshare.com/s/ 918941f831325d537a57 Private sharing link
2025
-
[6]
Jianchao Cao, Fan Guo, and Yanwen Qu. 2024. JNFuzz-Droid: A Lightweight Fuzzing and Taint Analysis Framework for Android Native Code. In2024 IEEE In- ternational Conference on Software Analysis, Evolution and Reengineering (SANER). 255–266. doi:10.1109/SANER60148.2024.00033
-
[7]
Laura Ceci. 2022. App Stores and Marketplaces. https://www.statista.com/topics/ 1729/app-stores/
2022
-
[8]
Laura Ceci. 2022. Google Play App Downloads and Revenue Statistics. https: //www.statista.com/statistics/734332/google-play-app-installs-per-year/
2022
-
[9]
F-Droid Community. 2025. F-Droid: Free and Open Source Android App Reposi- tory. https://f-droid.org/
2025
-
[10]
Oracle Corporation. 2025. Apksigner. https://developer.android.com/tools/ apksigner Accessed: October 2025
2025
-
[11]
Android Developers. 2010. The Monkey Tool. https://developer.android.com/ studio/test/monkey
2010
-
[12]
Android Developers. 2024. Exécuter des applications sur Android Emulator. https://developer.android.com/studio/run/emulator
2024
-
[13]
Android Developers. 2025. Android SDK Command-Line Tools. https://developer. android.com/studio/command-line
2025
-
[14]
1999.Refactoring - Improving the Design of Existing Code(1 ed.)
Martin Fowler. 1999.Refactoring - Improving the Design of Existing Code(1 ed.). Addison-Wesley
1999
-
[15]
Mohammad Ghafari, Pascal Gadient, and Oscar Nierstrasz. 2017. Security Smells in Android.2017 IEEE 17th International Working Conference on Source Code Analysis and Manipulation (SCAM)(2017), 121–130
2017
-
[16]
Xin Guo, Xiaofang Qi, Yanhui Li, and Chao Wu. 2024. PredRacer: Predictively Detecting Data Races in Android Applications. In2024 IEEE International Con- ference on Software Analysis, Evolution and Reengineering (SANER). 239–249. doi:10.1109/SANER60148.2024.00031
-
[17]
Sylvain Hallé and Raphaël Khoury. 2017. Event Stream Processing with BeepBeep
2017
-
[18]
Xiaocong He and openatx. 2024. uiautomator2 Documentation. https://github. com/openatx/uiautomator2
2024
-
[19]
Geoffrey Hecht, Romain Rouvoy, Naouel Moha, and Laurence Duchien. 2015. Detecting antipatterns in Android apps. In2015 2nd ACM international conference on mobile software engineering and systems. IEEE, 148–149
2015
-
[20]
Muhammad Umair Khan, Scott Uk-Jin Lee, Shanza Abbas, Asad Abbas, and Ali Kashif Bashir. 2021. Detecting Wake Lock Leaks in Android Apps Using Machine Learning.IEEE Access9 (2021), 125753–125767. doi:10.1109/ACCESS. 2021.3110244
-
[21]
Muhammad Umair Khan, Scott Uk-Jin Lee, Zhiqiang Wu, and Shanza Abbas
-
[22]
Electronics10, 18 (2021), 2211
Wake lock leak detection in android apps using multi-layer perceptron. Electronics10, 18 (2021), 2211
2021
-
[23]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K Lahiri, and Siddhartha Sen
-
[24]
In2023 IEEE/ACM 45th International Conference on Soft- ware Engineering (ICSE)
Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In2023 IEEE/ACM 45th International Conference on Soft- ware Engineering (ICSE). IEEE, 919–931
-
[25]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2017. Droidbot: a lightweight UI-guided test input generator for Android. In2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C). IEEE, 23– 26
2017
-
[26]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2019. Humanoid: A Deep Learning-Based Approach to Automated Black-box Android App Testing. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1070–1073. doi:10.1109/ASE.2019.00104
-
[27]
Tianming Liu, Haoyu Wang, Li Li, Guangdong Bai, Yao Guo, and Guoai Xu. 2019. DaPanda: Detecting Aggressive Push Notifications in Android Apps. In2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). 66–78. doi:10.1109/ASE.2019.00017
- [28]
-
[29]
G.E. Manukulasooriya, R.S.I. Munasingha, Harinda Fernando, H.K.I. Uthpali, A.V.S.H. Yeshani, and Deemantha Siriwardana. 2024. Enhancing Automated Android Application Security through Hybrid Static and Dynamic Analysis Techniques. In2024 International Congress on Human-Computer Interaction, Opti- mization and Robotic Applications (HORA). 1–6. doi:10.1109/H...
-
[30]
Djamel Mesbah, Nour El Madhoun, Khaldoun Al Agha, and Hani Chalouati
-
[31]
InInternational Conference on Emerging Internet, Data & Web Technologies
Leveraging prompt-based large language models for code smell detection: a comparative study on the MLCQ dataset. InInternational Conference on Emerging Internet, Data & Web Technologies. Springer, 444–454
-
[32]
Radinal Dwiki Novendra and Wikan Danar Sunindyo. 2024. Emerging Trends in Code Quality: Introducing Kotlin-Specific Bad Smell Detection Tool for Android Apps.IEEE Access12 (2024), 63895–63903. doi:10.1109/ACCESS.2024.3397055
-
[33]
Ollama. 2024. Get up and running with LLMs. https://ollama.com
2024
-
[34]
OpenAI. 2025. API reference. https://platform.openai.com/docs/api-reference/ responses/create#responses-create-temperature
2025
-
[35]
Fabio Palomba, Dario Di Nucci, Annibale Panichella, Andy Zaidman, and Andrea De Lucia. 2017. Lightweight detection of android-specific code smells: The adoctor project. In2017 IEEE 24th international conference on software analysis, evolution and reengineering (SANER). IEEE, 487–491
2017
-
[36]
Dimitri Prestat, Naouel Moha, and Roger Villemaire. 2022. An empirical study of Android behavioural code smells detection.Empirical Softw. Engg.27, 7 (dec 2022), 34 pages. doi:10.1007/s10664-022-10212-8
-
[37]
Dimitri Prestat, Naouel Moha, Roger Villemaire, and Florent Avellaneda. 2024. DynAMICS: A Tool-Based Method for the Specification and Dynamic Detection of Android Behavioral Code Smells.IEEE Transactions on Software Engineering 50, 4 (2024), 765–784. doi:10.1109/TSE.2024.3363223
-
[38]
Jan Reimann, Martin Brylski, and Uwe Aßmann. 2014. A Tool-Supported Quality Smell Catalogue For Android Developers.Softwaretechnik-Trends34 (2014)
2014
- [39]
-
[40]
Yutaka Tsutano, Shakthi Bachala, Witawas Srisa-an, Gregg Rothermel, and Jack- son Dinh. 2019. Jitana: A modern hybrid program analysis framework for android platforms.Journal of Computer Languages52 (2019), 55–71. doi:10.1016/j.cola. 2018.12.004
-
[41]
Raja Vallée-Rai, Phong Co, Etienne M. Gagnon, L. Hendren, Patrick Lam, and V. Sundaresan. 2010. Soot: a Java bytecode optimization framework. InProceedings of the 20th ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA 2005). ACM, 249–264. doi:10.1145/1094811. 1094838
-
[42]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software Testing With Large Language Models: Survey, Landscape, and Vision.IEEE Transactions on Software Engineering50, 4 (2024), 911–936. doi:10.1109/TSE.2024.3368208
- [43]
-
[44]
Di Wu, Fangwen Mu, Lin Shi, Zhaoqiang Guo, Kui Liu, Weiguang Zhuang, Yuqi Zhong, and Li Zhang. 2024. iSMELL: Assembling LLMs with Expert Toolsets for Code Smell Detection and Refactoring. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Machinery, New Yor...
-
[45]
Zhiqiang Wu, Xin Chen, and Scott Uk-Jin Lee. 2023. A systematic literature review on Android-specific smells.Journal of Systems and Software201 (2023), 111677. doi:10.1016/j.jss.2023.111677
-
[46]
Husam N Yasin, Siti Hafizah Ab Hamid, and Raja Jamilah Raja Yusof. 2021. Droidbotx: Test case generation tool for android applications using Q-learning. Symmetry13, 2 (2021), 310
2021
-
[47]
Juyeon Yoon, Robert Feldt, and Shin Yoo. 2024. Intent-Driven Mobile GUI Testing with Autonomous Large Language Model Agents. In2024 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 129–139
2024
-
[48]
Rajif Agung Yunmar, Sri Suning Kusumawardani, Widyawan, and Fadi Mohsen
-
[49]
IEEE Access12 (2024), 41255–41286
Hybrid Android Malware Detection: A Review of Heuristic-Based Approach. IEEE Access12 (2024), 41255–41286. doi:10.1109/ACCESS.2024.3377658
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.