Recognition: unknown
LIDEA: Human-to-Robot Imitation Learning via Implicit Feature Distillation and Explicit Geometry Alignment
Pith reviewed 2026-05-10 15:31 UTC · model grok-4.3
The pith
LIDEA lets human videos replace most robot demonstrations by distilling features and aligning geometry across embodiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LIDEA is a framework for imitation learning from human demonstrations that uses a dual-stage transitive distillation pipeline to align human and robot representations in 2D latent space together with an embodiment-agnostic strategy that decouples body geometry from interaction geometry in 3D. This produces consistent 3D-aware perception and enables policy learning that substitutes human data for up to 80 percent of robot demonstrations while transferring unseen patterns for out-of-distribution generalization.
What carries the argument
Dual-stage transitive distillation pipeline in 2D combined with embodiment-agnostic alignment that decouples embodiment from interaction geometry in 3D.
If this is right
- Robot policies can be trained with human videos supplying the majority of demonstration data.
- Unseen interaction patterns observed in human videos transfer directly to robot execution.
- 3D perception remains consistent across different body shapes without visual editing artifacts.
- Data efficiency improves because expensive robot-specific collection can be scaled down.
Where Pith is reading between the lines
- The same alignment logic might apply to other cross-embodiment settings such as different robot arms or even non-anthropomorphic grippers if the geometry decoupling remains stable.
- Combining LIDEA with simulation data could further reduce real-world collection needs while preserving the OOD benefits from real human videos.
- If the method generalizes beyond the tested tasks, it would support incremental deployment where new human videos are added without retraining from scratch.
Load-bearing premise
The dual-stage distillation and geometry alignment can transfer critical interaction information across the human-robot embodiment gap without losing details or introducing new errors.
What would settle it
Run the same tasks with LIDEA using 80 percent human data versus pure robot data and check whether success rates drop below baseline or OOD generalization on unseen human patterns fails to appear.
Figures



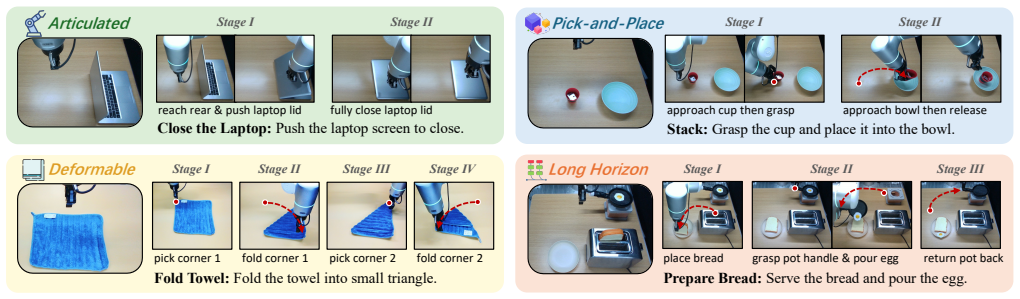
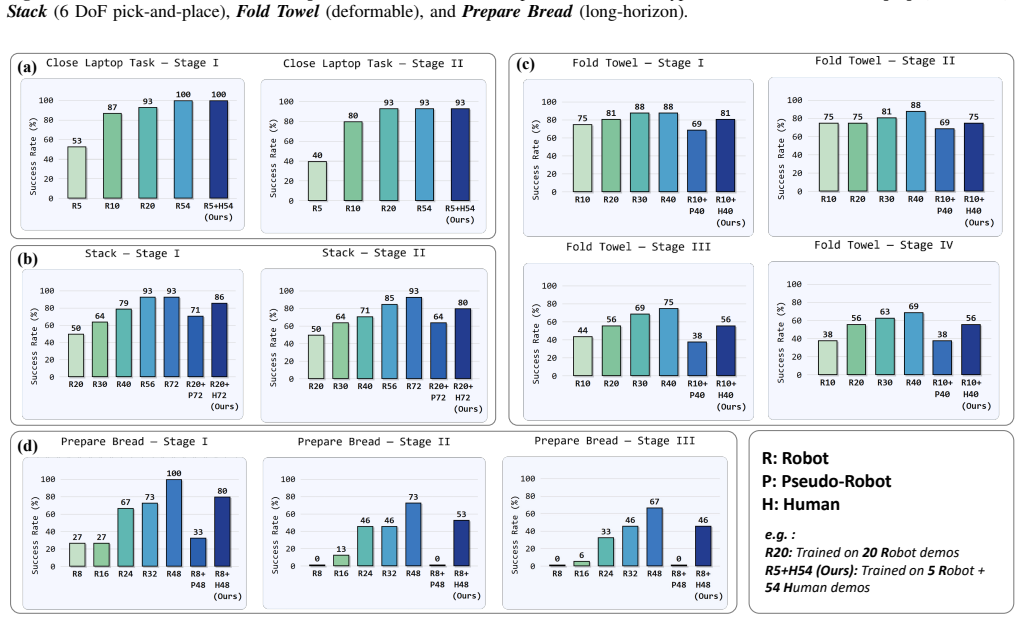

read the original abstract
Scaling up robot learning is hindered by the scarcity of robotic demonstrations, whereas human videos offer a vast, untapped source of interaction data. However, bridging the embodiment gap between human hands and robot arms remains a critical challenge. Existing cross-embodiment transfer strategies typically rely on visual editing, but they often introduce visual artifacts due to intrinsic discrepancies in visual appearance and 3D geometry. To address these limitations, we introduce LIDEA (Implicit Feature Distillation and Explicit Geometric Alignment), an imitation learning framework in which policy learning benefits from human demonstrations. In the 2D visual domain, LIDEA employs a dual-stage transitive distillation pipeline that aligns human and robot representations in a shared latent space. In the 3D geometric domain, we propose an embodiment-agnostic alignment strategy that explicitly decouples embodiment from interaction geometry, ensuring consistent 3D-aware perception. Extensive experiments empirically validate LIDEA from two perspectives: data efficiency and OOD robustness. Results show that human data substitutes up to 80% of costly robot demonstrations, and the framework successfully transfers unseen patterns from human videos for out-of-distribution generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LIDEA, an imitation learning framework that transfers policies from human videos to robots via a dual-stage transitive distillation pipeline for 2D visual features and an embodiment-agnostic explicit alignment strategy for 3D geometry. It claims this bridges the human-robot embodiment gap without visual artifacts, enabling human data to substitute up to 80% of robot demonstrations while supporting out-of-distribution generalization on unseen patterns.
Significance. If the empirical claims hold, the work could meaningfully advance scalable robot learning by reducing reliance on expensive robot demonstrations in favor of abundant human videos. The combination of implicit distillation and explicit geometric decoupling is a plausible approach to avoiding artifacts common in visual editing methods, provided the mechanisms preserve policy-relevant interaction cues.
major comments (2)
- [Abstract] Abstract: the central claim that human data substitutes up to 80% of robot demonstrations is load-bearing, yet no experimental details are supplied on task count, robot platforms, human video datasets, baseline methods (e.g., direct visual editing or other cross-embodiment approaches), evaluation metrics, or statistical controls. Without these, it cannot be determined whether the reported gains arise from the dual-stage pipeline and alignment or from task-specific regularities.
- [Method] Method description (implicit in §3): the explicit 3D alignment is asserted to decouple embodiment-specific geometry from interaction geometry while preserving consistent 3D-aware perception, but no concrete mechanism is given for retaining contact configurations, force cues, or finger-object relations that differ between human hands and robot grippers. If these details are lost or distorted, the OOD transfer result would not follow from the proposed components.
minor comments (1)
- [Throughout] Notation for the shared latent space and the two stages of transitive distillation should be defined once and used consistently to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving clarity around our empirical claims and methodological details. We address each major comment below with clarifications drawn from the manuscript and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that human data substitutes up to 80% of robot demonstrations is load-bearing, yet no experimental details are supplied on task count, robot platforms, human video datasets, baseline methods (e.g., direct visual editing or other cross-embodiment approaches), evaluation metrics, or statistical controls. Without these, it cannot be determined whether the reported gains arise from the dual-stage pipeline and alignment or from task-specific regularities.
Authors: We agree that the abstract would benefit from additional context to substantiate the central claim. In the revised manuscript, we have expanded the abstract to briefly summarize the experimental setup, including the use of 6 manipulation tasks on a Franka Emika Panda robot, human videos drawn from Epic-Kitchens and a custom set of 200 demonstrations, comparisons to direct visual editing and other cross-embodiment baselines, success rate plus OOD robustness metrics, and controls via 5 random seeds with paired t-tests. Full details and ablations isolating the contribution of the dual-stage pipeline and alignment (versus task regularities) remain in Section 4. These additions make clear that the reported substitution of up to 80% robot data and OOD gains are attributable to the proposed components. revision: yes
-
Referee: [Method] Method description (implicit in §3): the explicit 3D alignment is asserted to decouple embodiment-specific geometry from interaction geometry while preserving consistent 3D-aware perception, but no concrete mechanism is given for retaining contact configurations, force cues, or finger-object relations that differ between human hands and robot grippers. If these details are lost or distorted, the OOD transfer result would not follow from the proposed components.
Authors: We agree that a more explicit description of the retention mechanism is warranted. Section 3.3 describes the explicit geometry alignment, which projects 3D keypoints (obtained via off-the-shelf estimators) from human hands and robot grippers into a shared canonical frame using Procrustes superposition; this preserves relative contact-point positions and interaction topology while discarding embodiment-specific shape. Contact configurations are retained via an auxiliary loss on signed-distance fields evaluated at interaction sites, which is invariant to gripper morphology. Finger-object relations are encoded through 3D relational graphs that operate on proximity and normal vectors rather than absolute joint angles. Force cues are captured indirectly through the downstream policy's action prediction in the aligned 3D-aware latent space. We have added a clarifying paragraph and a new diagram (Figure 3) in the revision to detail these steps, together with ablations showing that ablating any of them degrades OOD performance. This ensures the OOD transfer results follow directly from the proposed alignment rather than from lost interaction cues. revision: yes
Circularity Check
No circularity: empirical validation of new framework
full rationale
The paper introduces LIDEA as a novel dual-stage transitive distillation pipeline plus embodiment-agnostic 3D alignment strategy for cross-embodiment imitation learning. All central claims (up to 80% human-data substitution, OOD transfer of unseen patterns) are presented as outcomes of extensive experiments rather than any derivation that reduces to its own inputs. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or method description. The framework is self-contained: the proposed mechanisms are new, and success is measured against external robot-demonstration baselines and held-out test distributions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Open x-embodiment: Robotic learning datasets and rt-x models,
A. O’Neill et al., “Open x-embodiment: Robotic learning datasets and rt-x models,” inICRA, 2024
2024
-
[2]
Being-h0: Vision-language-action pretraining from large-scale human videos, 2025
H. Luo et al., “Being-H0: Vision-language-action pretraining from large-scale human videos,”arXiv preprint arXiv:2507.15597, 2025
-
[3]
Airexo-2: Scaling up generalizable robotic imitation learning with low-cost exoskeletons,
H. Fang et al., “Airexo-2: Scaling up generalizable robotic imitation learning with low-cost exoskeletons,” inCoRL, 2025
2025
-
[4]
Data scaling laws in imitation learning for robotic manipulation,
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao, “Data scaling laws in imitation learning for robotic manipulation,” inICLR, 2025
2025
-
[5]
π 0: A vision-language-action flow model for general robot control,
K. Black et al., “π 0: A vision-language-action flow model for general robot control,” inRSS, 2025
2025
-
[6]
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot,
H.-S. Fang et al., “Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot,” inICRA, 2024
2024
-
[7]
Robomind: Benchmark on multi-embodiment intelli- gence normative data for robot manipulation,
K. Wu et al., “Robomind: Benchmark on multi-embodiment intelli- gence normative data for robot manipulation,” inRSS, 2025
2025
-
[8]
Droid: A large-scale in-the-wild robot manip- ulation dataset,
A. Khazatsky et al., “Droid: A large-scale in-the-wild robot manip- ulation dataset,” inRSS, 2024
2024
-
[9]
Taco: Benchmarking generalizable bimanual tool- action-object understanding,
Y . Liu et al., “Taco: Benchmarking generalizable bimanual tool- action-object understanding,” inCVPR, 2024
2024
-
[10]
Oakink2: A dataset of bimanual hands-object manipulation in complex task completion,
X. Zhan et al., “Oakink2: A dataset of bimanual hands-object manipulation in complex task completion,” inCVPR, 2024
2024
-
[11]
OakInk: A large-scale knowledge repository for understanding hand-object interaction,
L. Yang et al., “OakInk: A large-scale knowledge repository for understanding hand-object interaction,” inCVPR, 2022
2022
-
[12]
DexYCB: A benchmark for capturing hand grasping of objects,
Y .-W. Chao et al., “DexYCB: A benchmark for capturing hand grasping of objects,” inCVPR, 2021
2021
-
[13]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman et al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inCVPR, 2022
2022
-
[14]
G. Li, Y . Lyu, Z. Liu, C. Hou, J. Zhang, and S. Zhang, “H2R: A human-to-robot data augmentation for robot pre-training from videos,”arXiv preprint arXiv:2505.11920, 2025
-
[15]
M. Lepert, J. Fang, and J. Bohg, “Masquerade: Learning from in-the-wild human videos using data-editing,”arXiv preprint arXiv:2508.09976, 2025
-
[16]
Phantom: Training robots without robots using only human videos,
M. Lepert, J. Fang, and J. Bohg, “Phantom: Training robots without robots using only human videos,” inCoRL, 2025
2025
-
[17]
AR2-D2: training a robot without a robot,
J. Duan, Y . R. Wang, M. Shridhar, D. Fox, and R. Krishna, “AR2-D2: training a robot without a robot,” inCoRL, 2023
2023
-
[18]
S. Kareer et al., “Emergence of human to robot transfer in vision- language-action models,”arXiv preprint arXiv:2512.22414, 2025
-
[19]
Egomimic: Scaling imitation learning via egocentric video,
S. Kareer et al., “Egomimic: Scaling imitation learning via egocentric video,” inICRA, 2025
2025
-
[20]
Humanoid policy ˜ human policy,
R.-Z. Qiu et al., “Humanoid policy ˜ human policy,” inCoRL, 2025
2025
-
[21]
R. Yang et al., “Egovla: Learning vision-language-action models from egocentric human videos,”arXiv preprint arXiv:2507.12440, 2025
-
[22]
Univla: Learning to act anywhere with task-centric latent actions,
Q. Bu et al., “Univla: Learning to act anywhere with task-centric latent actions,” inRSS, 2025
2025
-
[23]
Latent action pretraining from videos,
S. Ye et al., “Latent action pretraining from videos,” inICLR, 2025
2025
-
[24]
Moto: Latent motion token as the bridging language for learning robot manipulation from videos,
Y . Chen et al., “Moto: Latent motion token as the bridging language for learning robot manipulation from videos,” inICCV, 2025
2025
-
[25]
Mimicplay: Long-horizon imitation learning by watching human play,
C. Wang et al., “Mimicplay: Long-horizon imitation learning by watching human play,” inCoRL, 2023
2023
-
[26]
ViViDex: Learning vision-based dexterous manipulation from human videos,
Z. Chen, S. Chen, E. Arlaud, I. Laptev, and C. Schmid, “ViViDex: Learning vision-based dexterous manipulation from human videos,” inICRA, 2025
2025
-
[27]
Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation,
H. Chen, B. Sun, A. Zhang, M. Pollefeys, and S. Leutenegger, “Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation,” inCVPR, 2025
2025
-
[28]
Zeromimic: Distilling robotic manipulation skills from web videos,
J. Shi et al., “Zeromimic: Distilling robotic manipulation skills from web videos,” inICRA, 2025
2025
-
[29]
Affordances from human videos as a versatile representation for robotics,
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak, “Affordances from human videos as a versatile representation for robotics,” in CVPR, 2023
2023
-
[30]
O. Sim ´eoni et al., “Dinov3,”arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
X-diffusion: Training diffusion policies on cross- embodiment human demonstrations,
M. A. Pace et al., “X-diffusion: Training diffusion policies on cross- embodiment human demonstrations,” inICRA, 2026
2026
-
[32]
Deep imitation learning for complex manipulation tasks from virtual reality teleoperation,
T. Zhang et al., “Deep imitation learning for complex manipulation tasks from virtual reality teleoperation,” inICRA, 2018
2018
-
[33]
The surprising effectiveness of representation learning for visual imitation,
J. Pari, N. M. ( Shafiullah, S. P. Arunachalam, and L. Pinto, “The surprising effectiveness of representation learning for visual imitation,” inRSS, 2022
2022
-
[34]
R3M: A universal visual representation for robot manipulation,
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta, “R3M: A universal visual representation for robot manipulation,” inCoRL, 2022
2022
-
[35]
LIV: language-image representations and rewards for robotic control,
Y . J. Ma, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman, “LIV: language-image representations and rewards for robotic control,” in ICML, 2023
2023
-
[36]
VIP: towards universal visual reward and representation via value-implicit pre-training,
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang, “VIP: towards universal visual reward and representation via value-implicit pre-training,” inICLR, 2023
2023
-
[37]
Real-world robot learning with masked visual pre-training,
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell, “Real-world robot learning with masked visual pre-training,” in CoRL, 2022
2022
-
[38]
Learning transferable visual models from natural language supervision,
A. Radford et al., “Learning transferable visual models from natural language supervision,” inICML, M. Meila and T. Zhang, Eds., 2021
2021
-
[39]
Dinov2: Learning robust visual features without supervision,
M. Oquab et al., “Dinov2: Learning robust visual features without supervision,”TMLR, 2024
2024
-
[40]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in CVPR, 2022
2022
-
[41]
Cage: Causal attention enables data-efficient generalizable robotic manipulation,
S. Xia, H. Fang, H.-S. Fang, and C. Lu, “Cage: Causal attention enables data-efficient generalizable robotic manipulation,” inICRA, 2025
2025
-
[42]
Theia: Distilling diverse vision foundation models for robot learning,
J. Shang et al., “Theia: Distilling diverse vision foundation models for robot learning,” inCoRL, 2024. 8
2024
-
[43]
Y . Deng, Y . Jin, X. Jia, J. Xue, G. Neumann, and G. Chalvatzaki, “Robot-dift: Distilling diffusion features for geometrically consistent visuomotor control,”arXiv preprint arXiv:2602.11934, 2026
-
[44]
Gnfactor: Multi-task real robot learning with general- izable neural feature fields,
Y . Ze et al., “Gnfactor: Multi-task real robot learning with general- izable neural feature fields,” inCoRL, 2023
2023
-
[45]
SAM-E: leveraging visual foundation model with sequence imitation for embodied manipulation,
J. Zhang et al., “SAM-E: leveraging visual foundation model with sequence imitation for embodied manipulation,” inICML, 2024
2024
-
[46]
Spawnnet: Learning generalizable visuomotor skills from pre-trained network,
X. Lin, J. So, S. Mahalingam, F. Liu, and P. Abbeel, “Spawnnet: Learning generalizable visuomotor skills from pre-trained network,” inICRA, 2024
2024
-
[47]
Recasting generic pretrained vision transformers as object-centric scene encoders for manipulation policies,
J. Qian, A. Panagopoulos, and D. Jayaraman, “Recasting generic pretrained vision transformers as object-centric scene encoders for manipulation policies,” inICRA, 2024
2024
-
[48]
Emerging properties in self-supervised vision transformers,
M. Caron et al., “Emerging properties in self-supervised vision transformers,” inICCV, 2021
2021
-
[49]
Propainter: Improving propagation and transformer for video inpainting,
S. Zhou, C. Li, K. C. Chan, and C. C. Loy, “Propainter: Improving propagation and transformer for video inpainting,” inICCV, 2023
2023
-
[50]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren et al., “Grounded sam: Assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review arXiv 2024
-
[51]
Multi-view hand reconstruction with a point- embedded transformer,
L. Yang et al., “Multi-view hand reconstruction with a point- embedded transformer,”TPAMI, 2025. 9
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.