Recognition: unknown
LLMs for Qualitative Data Analysis Fail on Security-specificComments in Human Experiments
Pith reviewed 2026-05-10 15:05 UTC · model grok-4.3
The pith
LLMs cannot reliably annotate security-specific comments from human code analysis experiments
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
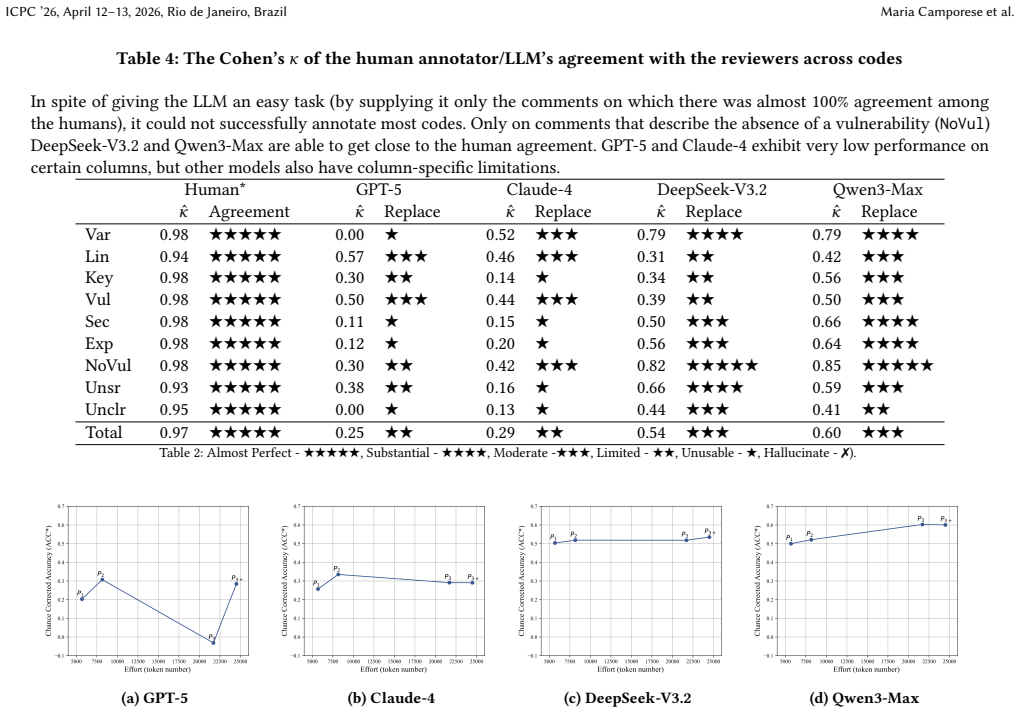
The authors find that large language models produce annotations for security aspects in experiment comments that match human experts only modestly, with clear but non-uniform gains from detailed code descriptions that nevertheless remain insufficient to replace human annotators as measured by Cohen's Kappa.
What carries the argument
Prompt variations that add detailed code descriptions and examples, evaluated by Cohen's Kappa agreement with human annotations on nine security codes extracted from free-text comments.
Load-bearing premise
The nine security-relevant codes and the chosen human annotations form a sufficient test of LLM capability for qualitative security analysis tasks in general.
What would settle it
An experiment in which one or more LLMs achieve high and uniform Cohen's Kappa scores with humans across all nine codes under comparable prompting conditions.
Figures




read the original abstract
[Background:] Thematic analysis of free-text justifications in human experiments provides significant qualitative insights. Yet, it is costly because reliable annotations require multiple domain experts. Large language models (LLMs) seem ideal candidates to replace human annotators. [Problem:] Coding security-specific aspects (code identifiers mentioned, lines-of-code mentioned, security keywords mentioned) may require deeper contextual understanding than sentiment classification. [Objective:] Explore whether LLMs can act as automated annotators for technical security comments by human subjects. [Method:] We prompt four top-performing LLMs on LiveBench to detect nine security-relevant codes in free-text comments by human subjects analyzing vulnerable code snippets. Outputs are compared to human annotators using Cohen's Kappa (chance-corrected accuracy). We test different prompts mimicking annotation best practices, including emerging codes, detailed codebooks with examples, and conflicting examples. [Negative Results:] We observed marked improvements only when using detailed code descriptions; however, these improvements are not uniform across codes and are insufficient to reliably replace a human annotator. [Limitations:] Additional studies with more LLMs and annotation tasks are needed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether LLMs can serve as automated annotators for nine security-relevant codes in free-text comments from human subjects analyzing vulnerable code snippets. It evaluates four top LLMs using Cohen's Kappa against human annotations, testing prompting strategies that include detailed codebooks, examples, and conflicting cases. The central finding is that detailed code descriptions yield marked but non-uniform improvements, which remain insufficient to reliably replace human annotators.
Significance. If the results hold, the work supplies concrete empirical evidence on the limits of LLMs for domain-specific qualitative coding tasks in security research, where contextual understanding of code identifiers, lines, and keywords is required. The study is strengthened by its use of multiple LLMs, systematic variation of prompts that mimic annotation best practices, and direct chance-corrected comparison to independent human labels.
major comments (2)
- The claim that improvements 'are insufficient to reliably replace a human annotator' (abstract and conclusion) is load-bearing yet unanchored. No human inter-annotator agreement figures (e.g., pairwise Cohen's Kappa among the human coders) are reported, nor is any explicit threshold or parity criterion defined for 'reliable' replacement. Without this benchmark, the sufficiency judgment cannot be evaluated quantitatively.
- Method section: the number of free-text comments, number of human subjects, and total annotation instances are not stated in the provided abstract or method summary. These quantities are required to assess the statistical power of the reported Kappa values and the robustness of the negative result across codes.
minor comments (2)
- Abstract: the four LLMs are described only as 'top-performing on LiveBench'; naming them and providing at least one full prompt template would improve reproducibility.
- The limitations paragraph could explicitly note the absence of a human-human baseline as a direction for follow-up work.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of our work. We address each major comment below.
read point-by-point responses
-
Referee: The claim that improvements 'are insufficient to reliably replace a human annotator' (abstract and conclusion) is load-bearing yet unanchored. No human inter-annotator agreement figures (e.g., pairwise Cohen's Kappa among the human coders) are reported, nor is any explicit threshold or parity criterion defined for 'reliable' replacement. Without this benchmark, the sufficiency judgment cannot be evaluated quantitatively.
Authors: We agree that the claim requires better anchoring with an explicit criterion. In the revision we will define 'reliable replacement' using standard interpretations of Cohen's Kappa (substantial agreement at Kappa ≥ 0.61). We will also add a limitations paragraph stating that human inter-annotator agreement was not computed, as the study used expert annotations without pairwise independent coding. These changes will be made in the abstract, conclusion, and a new limitations subsection. revision: yes
-
Referee: Method section: the number of free-text comments, number of human subjects, and total annotation instances are not stated in the provided abstract or method summary. These quantities are required to assess the statistical power of the reported Kappa values and the robustness of the negative result across codes.
Authors: We thank the referee for noting this clarity issue. The full Method section already contains these quantities. In the revised manuscript we will add an explicit summary paragraph at the start of the Method section stating the number of human subjects, free-text comments, and total annotation instances to facilitate evaluation of statistical power and robustness. revision: yes
- Human inter-annotator agreement figures (pairwise Cohen's Kappa) are not available, as the original study design did not include multiple independent annotations per comment for IAA calculation.
Circularity Check
No circularity: pure empirical comparison to independent human annotations
full rationale
The paper conducts an empirical study: it prompts four LLMs on security comment data, applies different prompt variants (codebooks, examples), and measures agreement with separate human annotations via Cohen's Kappa. No equations, fitted parameters, derived predictions, or self-referential derivations appear. The central claim rests on observed performance differences against an external human benchmark, not on any reduction to the paper's own inputs or prior self-citations. This matches the default case of a self-contained empirical evaluation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human annotations provide the correct ground truth labels for security codes.
- standard math Cohen's Kappa is an appropriate chance-corrected measure of agreement for this task.
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed, Amiangshu Bosu, Anindya Iqbal, and Shahram Rahimi. 2017. SentiCR: A customized sentiment analysis tool for code review interactions. In 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 106–111
2017
-
[2]
Anthropic. 2025. Claude 4: Claude Opus 4 & Claude Sonnet 4 Large Language Models. System card / technical documentation. https://www.anthropic.com/ news/claude-4 Includes Opus 4 and Sonnet 4, released May 22, 2025
2025
-
[3]
Andreas Armborst. 2017. Thematic proximity in content analysis.Sage Open7, 2 (2017), 2158244017707797
2017
-
[4]
Anthony G Barnston. 1992. Correspondence among the correlation, RMSE, and Heidke forecast verification measures; refinement of the Heidke score.Weather and Forecasting7, 4 (1992), 699–709
1992
-
[5]
Avik Bhattacharjee. 2025. Introduction to Amazon Bedrock. InA Practical Guide to Generative AI Using Amazon Bedrock: Building, Deploying, and Securing Generative AI Applications. Springer, 79–112
2025
-
[6]
David M Blei, Andrew Y Ng, and Michael I Jordan. 2003. Latent dirichlet allocation. Journal of machine Learning research3, Jan (2003), 993–1022
2003
-
[7]
Fabio Calefato, Filippo Lanubile, Federico Maiorano, and Nicole Novielli. 2018. Sentiment polarity detection for software development. InProceedings of the 40th International Conference on Software Engineering. 128–128
2018
-
[8]
Fabio Calefato, Filippo Lanubile, and Nicole Novielli. 2017. Emotxt: a toolkit for emotion recognition from text. In2017 seventh international conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW). IEEE, 79–80
2017
-
[9]
Victoria Clarke and Virginia Braun. 2017. Thematic analysis.The journal of positive psychology12, 3 (2017), 297–298
2017
-
[10]
Guilherme A Maldonado da Cruz, Elisa Hatsue Moriya Huzita, and Valéria D Feltrim. 2016. Estimating Trust in Virtual Teams-A Framework based on Sen- timent Analysis. InInternational Conference on Enterprise Information Systems, Vol. 2. SciTePress, 464–471
2016
- [11]
-
[12]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
Denae Ford, Justin Smith, Philip J Guo, and Chris Parnin. 2016. Paradise un- plugged: Identifying barriers for female participation on stack overflow. InPro- ceedings of the 2016 24th ACM SIGSOFT International symposium on foundations of software engineering. 846–857
2016
-
[15]
Robert Wayne Gregory, Mark Keil, Jan Muntermann, and Magnus Mähring
-
[16]
Information Systems Research26, 1 (2015), 57–80
Paradoxes and the nature of ambidexterity in IT transformation programs. Information Systems Research26, 1 (2015), 57–80
2015
-
[17]
2011.Applied thematic analysis
Greg Guest, Kathleen M MacQueen, and Emily E Namey. 2011.Applied thematic analysis. sage publications
2011
-
[18]
Wang, and Xinyu Xing
Wenbo Guo, Dongliang Mu, Jun Xu, Purui Su, G. Wang, and Xinyu Xing. 2018. LEMNA: Explaining Deep Learning based Security Applications.Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (2018)
2018
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Md Rakibul Islam and Minhaz F Zibran. 2018. DEVA: sensing emotions in the valence arousal space in software engineering text. InProceedings of the 33rd annual ACM symposium on applied computing. 1536–1543
2018
-
[21]
Nishant Jha and Anas Mahmoud. 2018. Using frame semantics for classifying and summarizing application store reviews.Empirical Software Engineering23, 6 (2018), 3734–3767
2018
-
[22]
Nishant Jha and Anas Mahmoud. 2019. Mining non-functional requirements from app store reviews.Empirical Software Engineering24 (2019), 3659–3695
2019
-
[23]
Jing Jiang, David Lo, Jiahuan He, Xin Xia, Pavneet Singh Kochhar, and Li Zhang
-
[24]
Why and how developers fork what from whom in GitHub.Empirical Software Engineering22, 1 (2017), 547–578
2017
-
[25]
Brittany Johnson, Rahul Pandita, Justin Smith, Denae Ford, Sarah Elder, Emerson Murphy-Hill, Sarah Heckman, and Caitlin Sadowski. 2016. A cross-tool com- munication study on program analysis tool notifications. InProceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. 73–84
2016
-
[26]
Robbert Jongeling, Proshanta Sarkar, Subhajit Datta, and Alexander Serebrenik
-
[27]
On negative results when using sentiment analysis tools for software engineering research.Empirical Software Engineering22 (2017), 2543–2584
2017
-
[28]
Rafael Kallis, Andrea Di Sorbo, Gerardo Canfora, and Sebastiano Panichella
-
[29]
In2019 IEEE International Conference on Software Maintenance and Evolution (ICSME)
Ticket tagger: Machine learning driven issue classification. In2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 406–409
-
[30]
Kevin Danis Li, Adrian M Fernandez, Rachel Schwartz, Natalie Rios, Mar- vin Nathaniel Carlisle, Gregory M Amend, Hiren V Patel, and Benjamin N Breyer
-
[31]
Comparing GPT-4 and human researchers in health care data analysis: qualitative description study.Journal of Medical Internet Research26 (2024), e56500
2024
- [32]
-
[33]
Bin Lin, Nathan Cassee, Alexander Serebrenik, Gabriele Bavota, Nicole Novielli, and Michele Lanza. 2022. Opinion mining for software development: a systematic literature review.ACM Transactions on Software Engineering and Methodology (TOSEM)31, 3 (2022), 1–41
2022
- [34]
-
[35]
Mika V Mäntylä and Casper Lassenius. 2008. What types of defects are really discovered in code reviews?IEEE Transactions on Software Engineering35, 3 (2008), 430–448
2008
-
[36]
Ggaliwango Marvin, Nakayiza Hellen, Daudi Jjingo, and Joyce Nakatumba- Nabende. 2023. Prompt engineering in large language models. InInternational conference on data intelligence and cognitive informatics. Springer, 387–402
2023
-
[37]
Meta AI. 2024. The LLaMA 3 Herd of Models.arXiv preprint(2024). https: //arxiv.org Most recent LLaMA model family at time of writing
2024
-
[38]
Mistral AI. 2024. Mixtral of Experts.arXiv preprint(2024). https://arxiv.org Sparse mixture-of-experts language model
2024
-
[39]
OpenAI. 2025. GPT-5: Technical Overview and Capabilities. Model documenta- tion and release notes. https://openai.com Large multimodal foundation model released by OpenAI
2025
-
[40]
OpenAI. 2025. OpenAI o3: Reasoning-Focused Large Language Model. Technical documentation and model card. https://openai.com Reasoning-optimized model in the OpenAI o-series
2025
-
[41]
Aurora Papotti, Ranindya Paramitha, and Fabio Massacci. 2024. On the acceptance by code reviewers of candidate security patches suggested by Automated Program Repair tools.Empirical Software Engineering29, 5 (2024), 1–35
2024
-
[42]
Aurora Papotti, Katja Tuma, and Fabio Massacci. 2025. On the effects of program slicing for vulnerability detection during code inspection.Empirical Software Engineering30, 3 (2025), 1–37
2025
-
[43]
Mohammad Masudur Rahman, Chanchal K Roy, and Raula G Kula. 2017. Predict- ing usefulness of code review comments using textual features and developer experience. In2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR). IEEE, 215–226
2017
- [44]
-
[45]
Per Runeson and Martin Höst. 2009. Guidelines for conducting and reporting case study research in software engineering.Empirical software engineering14 ICPC ’26, April 12–13, 2026, Rio de Janeiro, Brazil Maria Camporese et al. (2009), 131–164
2009
-
[46]
Antonino Sabetta, Serena Elisa Ponta, Rocio Cabrera Lozoya, Michele Bezzi, Tommaso Sacchetti, Matteo Greco, Gergő Balogh, Péter Hegedűs, Rudolf Ferenc, Ranindya Paramitha, et al. 2024. Known vulnerabilities of open source projects: Where are the fixes?IEEE Security & Privacy22, 2 (2024), 49–59
2024
-
[47]
Hope Schroeder, Marianne Aubin Le Quéré, Casey Randazzo, David Mimno, and Sarita Schoenebeck. 2025. Large Language Models in Qualitative Research: Uses, Tensions, and Intentions. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–17
2025
-
[48]
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulhoff, et al
-
[49]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
The prompt report: a systematic survey of prompt engineering techniques. arXiv preprint arXiv:2406.06608(2024)
work page internal anchor Pith review arXiv 2024
-
[50]
Carolyn B. Seaman. 1999. Qualitative methods in empirical studies of software engineering.IEEE Transactions on software engineering25, 4 (1999), 557–572
1999
-
[51]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review arXiv 2025
-
[52]
Mike Thelwall, Kevan Buckley, Georgios Paltoglou, Di Cai, and Arvid Kappas
-
[53]
Sentiment strength detection in short informal text.Journal of the American society for information science and technology61, 12 (2010), 2544–2558
2010
-
[54]
Matthijs J Warrens. 2015. Five ways to look at Cohen’s kappa.Journal of Psychology & Psychotherapy5 (2015)
2015
-
[55]
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, et al. 2024. LiveBench: A challenging, contamination-limited LLM benchmark.arXiv preprint arXiv:2406.19314(2024)
work page internal anchor Pith review arXiv 2024
-
[56]
2012.Experimentation in software engineering
Claes Wohlin, Per Runeson, Martin Höst, Magnus C Ohlsson, Björn Regnell, Anders Wesslén, et al. 2012.Experimentation in software engineering. Vol. 236. Springer
2012
-
[57]
xAI. 2024. Grok: A Large Language Model by xAI. Model documentation and release announcement. https://x.ai Latest publicly released Grok model family at time of writing
2024
-
[58]
Ziang Xiao, Xingdi Yuan, Q Vera Liao, Rania Abdelghani, and Pierre-Yves Oudeyer
-
[59]
InCompanion proceedings of the 28th international conference on intelligent user interfaces
Supporting qualitative analysis with large language models: Combining codebook with GPT-3 for deductive coding. InCompanion proceedings of the 28th international conference on intelligent user interfaces. 75–78
-
[60]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding con- volutional networks. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13. Springer, 818–833
2014
-
[62]
Yan Zhang and Barbara M Wildemuth. 2009. Qualitative analysis of content. Applications of social research methods to questions in information and library science308, 319 (2009), 1–12
2009
-
[63]
Wayne Xin Zhao, Jing Jiang, Jianshu Weng, Jing He, Ee-Peng Lim, Hongfei Yan, and Xiaoming Li. 2011. Comparing twitter and traditional media using topic models. InAdvances in Information Retrieval: 33rd European Conference on IR Research, ECIR 2011, Dublin, Ireland, April 18-21, 2011. Proceedings 33. Springer, 338–349
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.