Recognition: unknown
Beyond A Fixed Seal: Adaptive Stealing Watermark in Large Language Models
Pith reviewed 2026-05-10 16:36 UTC · model grok-4.3
The pith
An adaptive stealing method for LLM watermarks outperforms fixed strategies by dynamically choosing attack perspectives from token activation states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
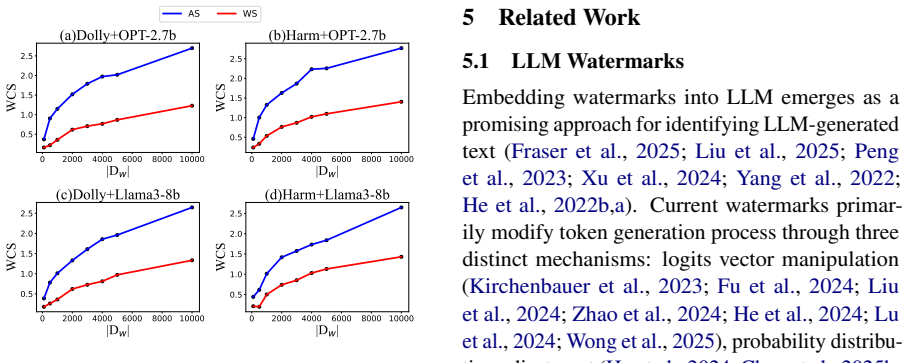
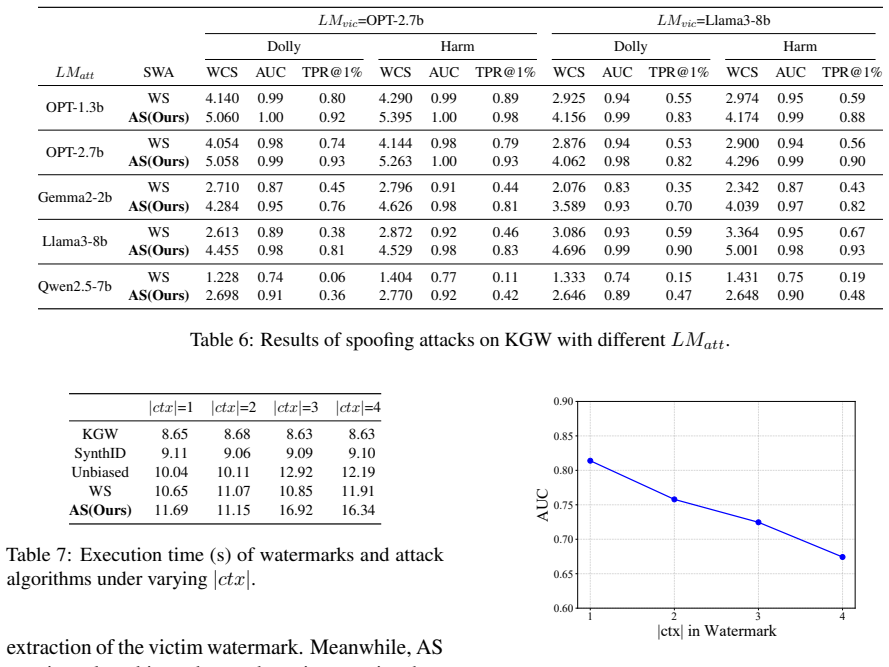
Adaptive Stealing uses Position-Based Seal Construction to build multiple possible attacks from distinct activation states of ordered tokens and an Adaptive Selection module to pick the perspective that best matches current watermark compatibility, generation priority, and dynamic relevance, raising the efficiency of deriving watermark information from victim LLM text compared with fixed-strategy baselines.
What carries the argument
Adaptive Selection module that chooses among multiple attack perspectives derived from token activation states using compatibility, priority, and relevance criteria.
If this is right
- Steal success rates rise measurably against the same target watermarks under controlled conditions.
- Watermark reliability as a detection tool declines when attackers can adapt to token-state variation.
- Attack design must treat watermark information as non-uniformly distributed rather than assuming a single fixed pattern.
- Releasing the implementation lets researchers measure how quickly new watermark schemes can be broken.
Where Pith is reading between the lines
- Watermark creators may need to harden schemes against simultaneous or switching attack views rather than single fixed patterns.
- Service operators could face quicker loss of watermark trust if adaptive stealing spreads beyond the lab.
- Defenses might shift toward monitoring for patterns that indicate dynamic perspective selection during an attack.
Load-bearing premise
That defining and dynamically selecting among multiple attack perspectives from token activation states will consistently beat fixed strategies without creating new detection risks or extra costs in deployed LLM systems.
What would settle it
A head-to-head test in which a fixed stealing baseline matches or exceeds the adaptive method's success rate when both attack the same watermarks during live, variable-length text generation.
Figures




read the original abstract
Watermarking provides a critical safeguard for large language model (LLM) services by facilitating the detection of LLM-generated text. Correspondingly, stealing watermark algorithms (SWAs) derive watermark information from watermarked texts generated by victim LLMs to craft highly targeted adversarial attacks, which compromise the reliability of watermarks. Existing SWAs rely on fixed strategies, overlooking the non-uniform distribution of stolen watermark information and the dynamic nature of real-world LLM generation processes. To address these limitations, we propose Adaptive Stealing (AS), a novel SWA featuring enhanced design flexibility through Position-Based Seal Construction and Adaptive Selection modules. AS operates by defining multiple attack perspectives derived from distinct activation states of contextually ordered tokens. During attack execution, AS dynamically selects the optimal perspective based on watermark compatibility, generation priority, and dynamic generation relevance. Our experiments demonstrate that AS significantly increases steal efficiency against target watermarks under identical experimental conditions. These findings highlight the need for more robust LLM watermarks to withstand potential attacks. We release our code to the community for future research\footnote{https://github.com/DrankXs/AdaptiveStealingWatermark}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing stealing watermark algorithms (SWAs) for LLMs rely on fixed strategies that overlook the non-uniform distribution of stolen watermark information and the dynamic nature of real-world LLM generation. It proposes Adaptive Stealing (AS) featuring Position-Based Seal Construction and Adaptive Selection modules. AS defines multiple attack perspectives derived from distinct activation states of contextually ordered tokens and dynamically selects the optimal perspective based on watermark compatibility, generation priority, and dynamic generation relevance. Experiments are claimed to demonstrate that AS significantly increases steal efficiency against target watermarks under identical experimental conditions, with code released to support further research.
Significance. If the experimental results hold, this work is significant for exposing limitations in current LLM watermarking schemes and motivating more robust designs. The adaptive selection logic directly targets the stated non-uniformity issue in fixed strategies. A notable strength is the release of code, which supports reproducibility and community extension of the empirical findings.
minor comments (2)
- Abstract: the claim of significant experimental improvement would be strengthened by including at least one concrete quantitative result (e.g., efficiency gain percentage or comparison metric) rather than a qualitative statement alone.
- Method section (Adaptive Selection module): the criteria for 'dynamic generation relevance' and the exact selection algorithm could be formalized with pseudocode or a concise equation to improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of our work and the recommendation for minor revision. The report correctly identifies the core contribution of Adaptive Stealing in addressing non-uniform watermark information distribution and dynamic generation processes. We note that the provided report does not list any specific major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity; empirical algorithmic contribution
full rationale
The paper introduces Adaptive Stealing (AS) as a novel SWA with Position-Based Seal Construction and Adaptive Selection modules that define multiple attack perspectives from token activation states and select dynamically via compatibility/priority/relevance. This is presented as an empirical design choice tested experimentally against fixed-strategy baselines under matched conditions, with code released for reproducibility. No derivation chain, mathematical prediction, or first-principles result reduces by construction to its own inputs; no self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The central claim of increased steal efficiency rests on experimental outcomes rather than tautological redefinition of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Watermark smoothing attacks against lan- guage models. InFindings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 4915–4941. As- sociation for Computational Linguistics. Canyu Chen and Kai Shu. 2024. Can llm-generated misinformation be detected? InThe Twelfth Inter- national Conference on Learning Rep...
-
[2]
Large language models can be used to effectively scale spear phishing campaigns
OpenReview.net. Kathleen C. Fraser, Hillary Dawkins, and Svetlana Kir- itchenko. 2025. Detecting ai-generated text: Factors influencing detectability with current methods.J. Artif. Intell. Res., 82:2233–2278. Yu Fu, Deyi Xiong, and Yue Dong. 2024. Watermark- ing conditional text generation for AI detection: Un- veiling challenges and a semantic-aware wate...
-
[3]
InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
Watermark stealing in large language models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
2024
-
[4]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein
OpenReview.net. John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A watermark for large language models. InInterna- tional Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofProceedings of Machine Learning Research, pages 17061–17084. PMLR. Kalpesh Krishna, Yixiao S...
2023
-
[5]
Role of ai chatbots in education: systematic lit- erature review.International journal of Educational Technology in Higher education, 20(1):56. Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, and Lijie Wen. 2024. A semantic invariant robust wa- termark for large language models. InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing: System Demonstrations, pages 61–71, Miami, Florida, USA
MarkLLM: An open-source toolkit for LLM watermarking. InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing: System Demonstrations, pages 61–71, Miami, Florida, USA. Association for Computational Linguistics. Leyi Pan, Aiwei Liu, Shiyu Huang, Yijian Lu, Xum- ing Hu, Lijie Wen, Irwin King, and Philip S. Yu
2024
-
[7]
Can ai-generated text be reliably detected?arXiv preprint arXiv:2303.11156, 2023
Can LLM watermarks robustly prevent unau- thorized knowledge distillation? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 13228–13251. Association for Computational Linguistics. Wenjun Peng, Jingwei Yi, Fangzhao Wu, Shangxi Wu, Bi...
-
[8]
OpenReview.net. Xiaojun Xu, Yuanshun Yao, and Yang Liu. 2024. Learn- ing to watermark llm-generated text via reinforce- ment learning.CoRR, abs/2403.10553. An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Hao- ran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jia...
-
[9]
OPT: Open Pre-trained Transformer Language Models
Watermarks in the sand: Impossibility of strong watermarking for generative models.IACR Cryptol. ePrint Arch., page 1776. Susan Zhang, Stephen Roller, and 1 others. 2022. OPT: open pre-trained transformer language mod- els.CoRR, abs/2205.01068. Zhaoxi Zhang, Xiaomei Zhang, Yanjun Zhang, Leo Yu Zhang, Chao Chen, Shengshan Hu, Asif Gill, and Shirui Pan. 202...
work page internal anchor Pith review arXiv 2022
-
[10]
Full". The sec- ond seal of WS is named
is LeftHash-scheme. LeftHash-scheme spec- ifies that Seal θ(·) only utilize the most left token in ctx. Additionally, other Hash-schemes exist, such as MinHash-scheme which utilizes the token with the minimum hash value in ctx, and MaxHash- scheme which conversely utilizes the token with the maximum hash value. Initially, KGW sets |ctx|= 1 . When generati...
2024
-
[11]
Fine-tuning is a common approach for mod- els to learn data patterns, and can also be used to learn (or steal) watermark information from water- marked text
is a fine-tuning-based implementation of SW A. Fine-tuning is a common approach for mod- els to learn data patterns, and can also be used to learn (or steal) watermark information from water- marked text. However, compared to approaches like WS and AS that are based on token statistical reasoning, fine-tuning has higher requirements for both attack resour...
2024
-
[12]
Meanwhile, Unigram is essentially the extreme case of KGW when|ctx|= 0
as the main attack watermark. Meanwhile, Unigram is essentially the extreme case of KGW when|ctx|= 0. MIP has only open-sourced the code for conduct- ing scrubbing attacks. We evaluates its scrubbing performance, with results presented in Table 10. When compared with WS and AS in Table 1, MIP exhibits significantly lower attack effectiveness. MIP’s disadv...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.