Recognition: unknown
ZoomR: Memory Efficient Reasoning through Multi-Granularity Key Value Retrieval
Pith reviewed 2026-05-10 16:31 UTC · model grok-4.3
The pith
ZoomR lets LLMs compress long reasoning thoughts into summaries and fetch only the needed KV details on demand, cutting memory use by more than four times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
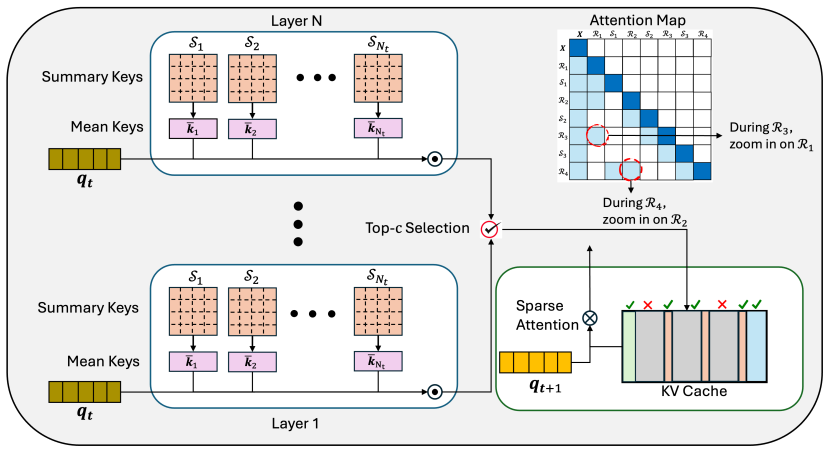
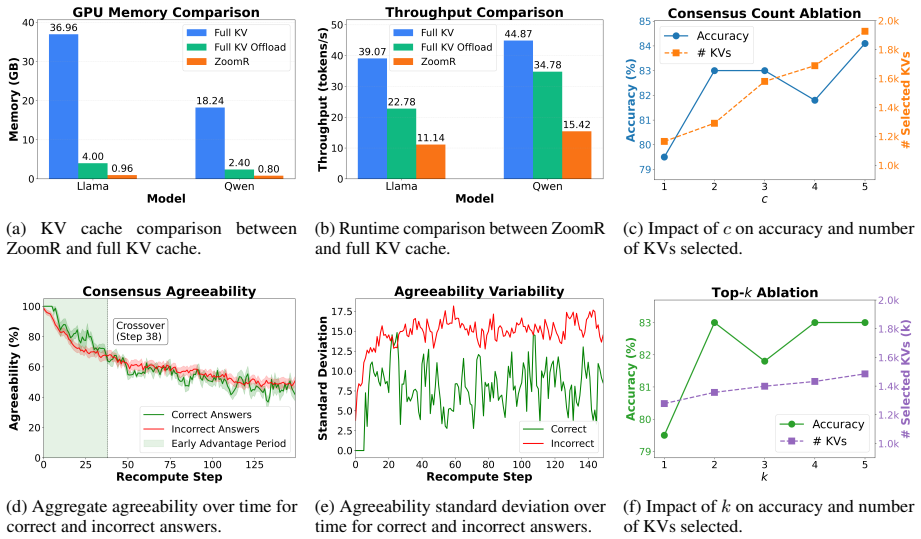
ZoomR compresses verbose reasoning thoughts into summary keys that serve as a coarse-grained index during autoregressive decoding. The query attends only to these summaries to identify the most relevant thoughts, then strategically retrieves the fine-grained KV details for those thoughts alone. This multi-granularity selection policy avoids full-cache attention at each step and thereby keeps memory usage far below the linear growth of standard KV caches, while experiments on math and reasoning tasks report competitive accuracy with more than 4 times lower inference memory.
What carries the argument
The dynamic KV cache selection policy that uses summary keys as a coarse-grained index to retrieve only the necessary fine-grained details on demand.
Load-bearing premise
Summary keys can reliably act as a coarse-grained index that lets the model retrieve only the truly necessary fine-grained KV details without losing information required for correct final answers.
What would settle it
An experiment that disables the fine-grained zoom-in step, forcing reliance on summaries alone, and measures whether accuracy on the same math and reasoning benchmarks drops substantially below the full-cache baseline.
Figures




read the original abstract
Large language models (LLMs) have shown great performance on complex reasoning tasks but often require generating long intermediate thoughts before reaching a final answer. During generation, LLMs rely on a key-value (KV) cache for autoregressive decoding. However, the memory footprint of the KV cache grows with output length. Prior work on KV cache optimization mostly focus on compressing the long input context, while retaining the full KV cache for decoding. For tasks requiring long output generation, this leads to increased computational and memory costs. In this paper, we introduce ZoomR, a novel approach that enables LLMs to adaptively compress verbose reasoning thoughts into summaries and uses a dynamic KV cache selection policy that leverages these summaries while also strategically "zooming in" on fine-grained details. By using summary keys as a coarse-grained index during decoding, ZoomR uses the query to retrieve details for only the most important thoughts. This hierarchical strategy significantly reduces memory usage by avoiding full-cache attention at each step. Experiments across math and reasoning tasks show that our approach achieves competitive performance compared to baselines, while reducing inference memory requirements by more than $4\times$. These results demonstrate that a multi-granularity KV selection enables more memory efficient decoding, especially for long output generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ZoomR, a hierarchical KV-cache management technique for LLMs performing long-chain reasoning. It adaptively compresses verbose intermediate thoughts into summaries that serve as coarse-grained indices; during autoregressive decoding a dynamic selection policy uses query-summary similarity to retrieve only the relevant fine-grained KV entries while discarding the rest, claiming >4× inference memory reduction with competitive accuracy on math and reasoning tasks.
Significance. If the summary-based indexing reliably preserves critical reasoning steps, the approach would meaningfully address the KV-cache memory bottleneck that grows linearly with output length, enabling longer, more complex reasoning chains under fixed memory budgets. The multi-granularity idea is a natural extension of prior KV compression work and could influence efficient inference designs if the central retrieval assumption holds empirically.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of competitive performance and >4× memory savings is stated without any reported baselines, task list, number of runs, error bars, or ablation on summary quality; this prevents verification of the central claim and leaves post-hoc selection risks unassessable.
- [§3] §3 (Method): the assumption that summary keys function as a reliable coarse-grained index—retrieving precisely the fine-grained KV entries needed for next-token prediction without omitting critical intermediate reasoning steps—is load-bearing for both the accuracy and memory claims, yet no equations, algorithm, or empirical test of information loss under imperfect summaries is provided.
- [§4.2] §4.2 (Ablations): if an ablation on summary fidelity or retrieval precision exists, it is not described; without it the weakest link between the hierarchical mechanism and the reported competitive accuracy remains untested.
minor comments (2)
- [§3] Notation for the summary key construction and the dynamic selection policy should be formalized with explicit equations or pseudocode to improve reproducibility.
- [Figures] Figure captions and axis labels for memory-vs-accuracy plots would benefit from explicit units and baseline names for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and commit to revisions that will strengthen the experimental reporting, methodological formalization, and empirical validation of the hierarchical KV mechanism.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of competitive performance and >4× memory savings is stated without any reported baselines, task list, number of runs, error bars, or ablation on summary quality; this prevents verification of the central claim and leaves post-hoc selection risks unassessable.
Authors: We agree that clearer reporting is needed for independent verification. Section 4 of the manuscript already compares against full KV cache and prior compression baselines on math/reasoning benchmarks, but we will revise the abstract to explicitly name the tasks and baselines. We will add a table in §4 listing all tasks, report results with error bars from multiple runs (minimum 3 seeds), and include a new ablation on summary quality to address post-hoc selection concerns. revision: yes
-
Referee: [§3] §3 (Method): the assumption that summary keys function as a reliable coarse-grained index—retrieving precisely the fine-grained KV entries needed for next-token prediction without omitting critical intermediate reasoning steps—is load-bearing for both the accuracy and memory claims, yet no equations, algorithm, or empirical test of information loss under imperfect summaries is provided.
Authors: The reliability of summary-based coarse indexing is central. While §3 describes the adaptive summarization and dynamic query-driven retrieval, we will add formal equations for the similarity computation and selection policy, plus algorithm pseudocode, in the revised §3. We will also add an empirical analysis of information loss, including retrieval precision metrics and accuracy impact under controlled summary imperfections, to demonstrate preservation of critical reasoning steps. revision: yes
-
Referee: [§4.2] §4.2 (Ablations): if an ablation on summary fidelity or retrieval precision exists, it is not described; without it the weakest link between the hierarchical mechanism and the reported competitive accuracy remains untested.
Authors: We concur that targeted ablations are required to validate the mechanism. In the revised §4.2 we will add experiments varying summary fidelity (compression ratio vs. accuracy) and measuring retrieval precision (e.g., fraction of relevant KV entries selected and its correlation with next-token quality). These will directly test whether the multi-granularity policy maintains competitive accuracy without omitting key intermediate thoughts. revision: yes
Circularity Check
No circularity: algorithmic policy with no derivations or fitted predictions
full rationale
The paper presents ZoomR as a novel algorithmic method for hierarchical KV cache selection using summary keys, without any equations, first-principles derivations, fitted parameters, or predictions that reduce to inputs by construction. Claims rest on experimental comparisons to baselines for memory reduction and performance, which are externally falsifiable and not self-referential. No self-citations, ansatzes, or uniqueness theorems are invoked in the provided text to support core mechanisms.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching
Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching.Preprint, arXiv:2503.05179. Frederic Charles Bartlett. 1932.Remembering: A Study in Experimental and Social Psychology. Cambridge University Press, Cambridge. Guoxuan Chen, Han Shi, Jiawei Li, Yihang Gao, Xi- aozhe Ren, Yimeng Chen, Xin Jiang, Zhenguo Li, Weiyang Liu, an...
-
[2]
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mi- tra, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Inftythink: Breaking the length limits of long-context reasoning in large language models
Inftythink: Breaking the length limits of long- context reasoning in large language models.Preprint, arXiv:2503.06692. Jintian Zhang, Yuqi Zhu, Mengshu Sun, Yujie Luo, Shuofei Qiao, Lun Du, Da Zheng, Huajun Chen, and Ningyu Zhang. 2025. Lightthinker: Thinking step- by-step compression.Preprint, arXiv:2502.15589. Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tian...
-
[4]
Next, BC: from (3,4) to (4,3)
So AB is3 √ 2. Next, BC: from (3,4) to (4,3). The length BC is p (4−3) 2 + (3−4) 2 = p 12 + (−1)2 =√1 + 1 = √ 2. <|begin_of_summary|>AB= 3 √ 2,BC= √ 2<|end_of_summary|> Third side is CD: from (4,3) to (3,0). The length CD is p (3−4) 2 + (0−3) 2 =p (−1)2 + (−3)2 = √1 + 9 = √ 10. Last side is DA: from (3,0) back to (0,1). The length DA is p (0−3) 2 + (1−0) ...
-
[5]
So the total perimeter is4 √ 2 + 2 √ 10
= 4 √ 2 + 2 √ 10. So the total perimeter is4 √ 2 + 2 √ 10. · · · Figure 5: An example of a segment of reasoning process with intermediate summaries. ZoomR Example Question:The 9 members of a baseball team went to an ice cream parlor after their game. Each player had a single-scoop cone of chocolate, vanilla, or strawberry ice cream. At least one player ch...
-
[6]
Each flavor is chosen by at least one player
-
[7]
So,Ch > V an > Str
The number of players who chose chocolate is greater than those who chose vanilla, which in turn is greater than those who chose strawberry. So,Ch > V an > Str. We need to find the number of different assignments (flavorings) that meet these conditions, then findN(mod 1000). Hmm. Let me break this down. So, each player has 3 choices: C, V , or S. But with...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.