Recognition: unknown
AmodalSVG: Amodal Image Vectorization via Semantic Layer Peeling
Pith reviewed 2026-05-10 16:32 UTC · model grok-4.3
The pith
AmodalSVG reconstructs natural images into separate editable vector layers that include the full geometry of each object, even parts hidden by occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AmodalSVG reformulates image vectorization as a two-stage process that first applies Semantic Layer Peeling to decompose an input image into amodally complete semantic layers through VLM-guided progressive decomposition and hybrid inpainting to recover occluded object appearances, then converts those layers into independent SVGs using Adaptive Layered Vectorization that allocates primitives according to an error budget.
What carries the argument
Semantic Layer Peeling (SLP), a VLM-guided strategy that progressively decomposes an image into semantically coherent layers while using hybrid inpainting to recover complete object appearances under occlusions.
If this is right
- The resulting amodal layers support object-level editing directly in the vector domain.
- SVGs become semantically organized rather than entangled across overlapping objects.
- Geometric completeness is achieved for each object rather than only tracing visible pixels.
- Independent vectorization of layers enables capabilities absent from prior modal vectorization methods.
Where Pith is reading between the lines
- Design software could incorporate amodal layers as a native editing mode so users adjust hidden parts of objects without redrawing.
- The approach may extend naturally to video by propagating layer decompositions across frames to maintain consistent editable vectors over time.
- Automated illustration pipelines could use the complete layers to generate variants where objects are rearranged or restyled while preserving vector editability.
Load-bearing premise
The vision-language model guided peeling step must produce accurate semantic separation and artifact-free inpainted appearances for occluded regions so that the subsequent vectorization remains high quality.
What would settle it
A controlled test set of images containing objects with known full geometries where the output amodal SVGs are checked for geometric fidelity in hidden regions and for whether manual edits to individual layers produce visually consistent results without introducing new artifacts.
Figures






read the original abstract
We introduce AmodalSVG, a new framework for amodal image vectorization that produces semantically organized and geometrically complete SVG representations from natural images. Existing vectorization methods operate under a modal paradigm: tracing only visible pixels and disregarding occlusion. Consequently, the resulting SVGs are semantically entangled and geometrically incomplete, limiting SVG's structural editability. In contrast, AmodalSVG reconstructs full object geometries, including occluded regions, into independent, editable vector layers. To achieve this, AmodalSVG reformulates image vectorization as a two-stage framework, performing semantic decoupling and completion in the raster domain to produce amodally complete semantic layers, which are then independently vectorized. In the first stage, we introduce Semantic Layer Peeling (SLP), a VLM-guided strategy that progressively decomposes an image into semantically coherent layers. By hybrid inpainting, SLP recovers complete object appearances under occlusions, enabling explicit semantic decoupling. To vectorize these layers efficiently, we propose Adaptive Layered Vectorization (ALV), which dynamically modulates the primitive budget via an error-budget-driven adjustment mechanism. Extensive experiments demonstrate that AmodalSVG significantly outperforms prior methods in visual fidelity. Moreover, the resulting amodal layers enable object-level editing directly in the vector domain, capabilities not supported by existing vectorization approaches. Code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AmodalSVG, a two-stage framework for amodal image vectorization from natural images. It first applies Semantic Layer Peeling (SLP), a VLM-guided progressive decomposition with hybrid inpainting to recover complete object appearances under occlusion and produce semantically decoupled raster layers; these are then independently vectorized via Adaptive Layered Vectorization (ALV), which modulates primitive budgets using an error-budget threshold. The result is a set of independent, geometrically complete SVG layers that support object-level editing in the vector domain, unlike existing modal vectorization methods.
Significance. If the central claims hold, the work would be significant for extending vector graphics beyond visible surfaces, enabling new editing workflows in design and graphics applications. The SLP and ALV components introduce a novel pipeline for semantic decoupling and adaptive vectorization; the planned code release would further strengthen reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that AmodalSVG 'significantly outperforms prior methods in visual fidelity' and enables 'capabilities not supported by existing vectorization approaches' is unsupported by any quantitative metrics, baselines, ablation results, or dataset details, which are load-bearing for the central claim of amodal completeness and editability.
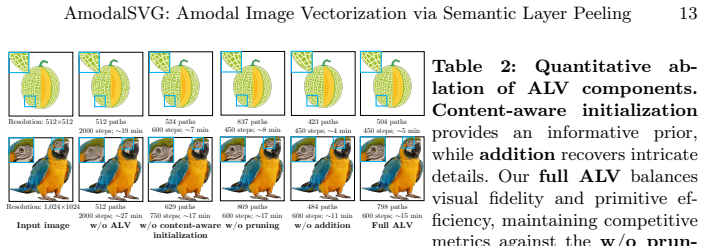
- [SLP stage] SLP stage: the VLM-guided semantic decoupling and hybrid inpainting for occluded regions lacks any reported metrics isolating completion quality (e.g., amodal mask IoU, perceptual consistency of inpainted textures, or error propagation into ALV), leaving the independence and geometric completeness of the resulting layers under-supported given known VLM hallucination risks under heavy occlusion.
minor comments (1)
- Define all acronyms (VLM, SLP, ALV) at first use and ensure consistent notation for the error-budget threshold across the method description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications on where the supporting evidence appears in the paper and noting where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AmodalSVG 'significantly outperforms prior methods in visual fidelity' and enables 'capabilities not supported by existing vectorization approaches' is unsupported by any quantitative metrics, baselines, ablation results, or dataset details, which are load-bearing for the central claim of amodal completeness and editability.
Authors: The abstract is a concise summary of the paper's contributions and conclusions. The quantitative support for these claims—including comparisons to prior vectorization methods on visual fidelity metrics (e.g., PSNR, SSIM, LPIPS), ablation studies on the SLP and ALV components, baseline implementations, and dataset details—is provided in full in Section 4 (Experiments) and Section 3 (Datasets and Implementation). Editability is demonstrated through both qualitative object-level editing examples and a user study in Section 4.3. We do not believe the abstract itself requires expansion given typical length constraints, as the load-bearing evidence resides in the body of the paper. revision: no
-
Referee: [SLP stage] SLP stage: the VLM-guided semantic decoupling and hybrid inpainting for occluded regions lacks any reported metrics isolating completion quality (e.g., amodal mask IoU, perceptual consistency of inpainted textures, or error propagation into ALV), leaving the independence and geometric completeness of the resulting layers under-supported given known VLM hallucination risks under heavy occlusion.
Authors: We acknowledge that isolated metrics for the SLP stage would provide stronger support. The current manuscript reports end-to-end results and qualitative layer visualizations in Section 4.2, which show improved semantic independence and geometric completeness relative to modal baselines. However, we did not report standalone amodal completion metrics such as mask IoU or texture perceptual scores, partly because standard datasets lack amodal ground truth. We will add a dedicated ablation subsection with perceptual metrics (e.g., FID for inpainted regions) and explicit discussion of hallucination mitigation via the hybrid inpainting strategy. This revision will be incorporated. revision: yes
Circularity Check
No circularity in the proposed AmodalSVG pipeline
full rationale
The paper describes a two-stage algorithmic framework (SLP for VLM-guided semantic decomposition plus hybrid inpainting, followed by ALV for error-budget-driven vectorization) rather than any mathematical derivation chain, first-principles result, or prediction. No equations, fitted parameters renamed as outputs, self-definitional constructs, or load-bearing self-citations appear in the abstract or described method. The central claims rest on the empirical performance of the pipeline components, which are presented as novel but externally motivated techniques, not reductions to their own inputs by construction. This is a standard non-circular method paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- error budget threshold
axioms (1)
- domain assumption VLMs can guide accurate progressive semantic decomposition and occlusion recovery via hybrid inpainting
invented entities (2)
-
Semantic Layer Peeling (SLP)
no independent evidence
-
Adaptive Layered Vectorization (ALV)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
VAnim: Rendering-Aware Sparse State Modeling for Structure-Preserving Vector Animation
VAnim creates open-domain text-to-SVG animations via sparse state updates on a persistent DOM tree, identification-first planning, and rendering-aware RL with a new 134k-example benchmark.
Reference graph
Works this paper leans on
-
[1]
IEEE transactions on pattern analysis and machine intelligence34(11), 2274–2282 (2012) 4
Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., Süsstrunk, S.: Slic superpix- els compared to state-of-the-art superpixel methods. IEEE transactions on pattern analysis and machine intelligence34(11), 2274–2282 (2012) 4
2012
-
[2]
AI,R.:Aiimagevectorizer:Convertrasterimagestovectorgraphics(2024),https: //www.recraft.ai/ai-image-vectorizer10
2024
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ao, J., Jiang, Y., Ke, Q., Ehinger, K.A.: Open-world amodal appearance comple- tion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6490–6499 (2025) 4
2025
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020) 6
2020
-
[6]
Advances in Neural Information Processing Systems (NeurIPS)33, 16351–16361 (2020) 3, 4
Carlier, A., Danelljan, M., Alahi, A., Timofte, R.: Deepsvg: A hierarchical gen- erative network for vector graphics animation. Advances in Neural Information Processing Systems (NeurIPS)33, 16351–16361 (2020) 3, 4
2020
-
[7]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Chen, H., Zhao, Z., Chen, Y., Liang, Z., Ni, B.: Svgthinker: Instruction-aligned and reasoning-driven text-to-svg generation. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 11004–11012 (2025) 4
2025
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, Y., Hu, Z., Zhao, Z., Zhu, Y., Shi, Y., Xiong, Y., Ni, B.: Easy-editable image vectorization with multi-layer multi-scale distributed visual feature embedding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23345–23354 (2025) 6
2025
-
[9]
Consortium, W.W.W.: Scalable vector graphics (svg) specification (1999),https: //www.w3.org/TR/1999/WD-SVG-19990211/2
1999
-
[10]
In: Advances in Neural Information Pro- cessing Systems (NeurIPS) (2022) 3
Frans, K., Soros, L., Witkowski, O.: CLIPDraw: Exploring text-to-drawing syn- thesis through language-image encoders. In: Advances in Neural Information Pro- cessing Systems (NeurIPS) (2022) 3
2022
-
[11]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Gao, J., Qian, X., Wang, Y., Xiao, T., He, T., Zhang, Z., Fu, Y.: Coarse-to-fine amodal segmentation with shape prior. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 1262–1271 (2023) 4
2023
-
[12]
In: International Conference on Learning Representations (ICLR) (2018),https://openreview
Ha, D., Eck, D.: A neural representation of sketch drawings. In: International Conference on Learning Representations (ICLR) (2018),https://openreview. net/forum?id=Hy6GHpkCW3
2018
-
[13]
In: Proceedings of the AAAI Conference on Artificial In- telligence
Hirschorn, O., Jevnisek, A., Avidan, S.: Optimize & reduce: a top-down approach for image vectorization. In: Proceedings of the AAAI Conference on Artificial In- telligence. vol. 38, pp. 2148–2156 (2024) 2, 3, 4, 7, 10, 13
2024
-
[14]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Hu, T., Yi, R., Qian, B., Zhang, J., Rosin, P.L., Lai, Y.K.: Supersvg: Superpixel- based scalable vector graphics synthesis. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 24892–24901 (2024) 4, 6 16 J. Hu et al
2024
-
[15]
ACM Transactions on Graphics (TOG)42(4), 1–11 (2023) 3
Iluz, S., Vinker, Y., Hertz, A., Berio, D., Cohen-Or, D., Shamir, A.: Word-as- image for semantic typography. ACM Transactions on Graphics (TOG)42(4), 1–11 (2023) 3
2023
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Jain, A., Xie, A., Abbeel, P.: Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 1911–1920 (2023) 3
1911
-
[17]
In: Psychology of learning and motivation
Kellman, P.J., Massey, C.M.: Perceptual learning, cognition, and expertise. In: Psychology of learning and motivation. Elsevier (2013) 4
2013
-
[18]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023) 4, 6, 19
2023
-
[19]
black forest lab: Flux.1 fill [pro] (2024),https://huggingface.co/black-forest- labs/FLUX.1-Fill-dev6, 19, 22
2024
-
[20]
ACM Transactions on Graphics (TOG) 39(6), 1–15 (2020) 2, 3, 4, 7, 10, 13, 19, 22
Li, T.M., Lukáč, M., Gharbi, M., Ragan-Kelley, J.: Differentiable vector graph- ics rasterization for editing and learning. ACM Transactions on Graphics (TOG) 39(6), 1–15 (2020) 2, 3, 4, 7, 10, 13, 19, 22
2020
-
[21]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Li, Z., Lavreniuk, M., Shi, J., Bhat, S.F., Wonka, P.: Amodal depth anything: Amodal depth estimation in the wild. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 9673–9682 (2025) 4
2025
-
[22]
In: European Conference on Computer Vision
Li, Z., Ye, W., Jiang, T., Huang, T.: 2d amodal instance segmentation guided by 3d shape prior. In: European Conference on Computer Vision. pp. 165–181. Springer (2022) 4
2022
-
[23]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024) 19
2024
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ma, X., Zhou, Y., Xu, X., Sun, B., Filev, V., Orlov, N., Fu, Y., Shi, H.: Towards layer-wise image vectorization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16314–16323 (2022) 2, 3, 4, 10, 11, 13
2022
-
[25]
ACM Transactions on Graphics (ToG)27(3), 1–8 (2008) 4
Orzan, A., Bousseau, A., Winnemöller, H., Barla, P., Thollot, J., Salesin, D.: Diffu- sion curves: a vector representation for smooth-shaded images. ACM Transactions on Graphics (ToG)27(3), 1–8 (2008) 4
2008
-
[26]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ozguroglu, E., Liu, R., Surís, D., Chen, D., Dave, A., Tokmakov, P., Vondrick, C.: pix2gestalt: Amodal segmentation by synthesizing wholes. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3931–3940. IEEE Computer Society (2024) 4
2024
-
[27]
Proceedings of the ACM on Computer Graphics and Interactive Techniques7(1), 1–17 (2024) 7
Papantonakis, P., Kopanas, G., Kerbl, B., Lanvin, A., Drettakis, G.: Reducing the memory footprint of 3d gaussian splatting. Proceedings of the ACM on Computer Graphics and Interactive Techniques7(1), 1–17 (2024) 7
2024
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qi, L., Jiang, L., Liu, S., Shen, X., Jia, J.: Amodal instance segmentation with kins dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3014–3023 (2019) 4
2019
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Reddy, P., Gharbi, M., Lukac, M., Mitra, N.J.: Im2vec: Synthesizing vector graph- ics without vector supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7342–7351 (2021) 2, 3, 4, 13
2021
-
[30]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 779–788 (2016) 6 AmodalSVG: Amodal Image Vectorization via Semantic Layer Peeling 17
2016
-
[31]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024) 6, 19, 21
work page internal anchor Pith review arXiv 2024
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Rodriguez, J.A., Puri, A., Agarwal, S., Laradji, I.H., Rodriguez, P., Rajeswar, S., Vazquez, D., Pal, C., Pedersoli, M.: Starvector: Generating scalable vector graphics code from images and text. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16175–16186 (2025) 4
2025
-
[33]
A., Zhang, H., Puri, A., Feizi, A., Pramanik, R., Wichmann, P., Mondal, A., Samsami, M
Rodriguez, J.A., Zhang, H., Puri, A., Feizi, A., Pramanik, R., Wichmann, P., Mondal, A., Samsami, M.R., Awal, R., Taslakian, P., et al.: Rendering-aware rein- forcement learning for vector graphics generation. arXiv preprint arXiv:2505.20793 (2025) 4
-
[34]
Selinger, P.: Potrace: a polygon-based tracing algorithm (2003) 2, 4, 13
2003
-
[35]
Song, Y., Chen, D., Shou, M.Z.: Layertracer: Cognitive-aligned layered svg syn- thesis via diffusion transformer. arXiv preprint arXiv:2502.01105 (2025) 2, 4, 10, 11, 13
-
[36]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Suvorov, R., Logacheva, E., Mashikhin, A., Remizova, A., Ashukha, A., Silvestrov, A., Kong, N., Goka, H., Park, K., Lempitsky, V.: Resolution-robust large mask inpainting with fourier convolutions. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2149–2159 (2022) 6, 19, 22
2022
-
[37]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision
Vinker, Y., Alaluf, Y., Cohen-Or, D., Shamir, A.: Clipascene: Scene sketching with different types and levels of abstraction. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision. pp. 4146–4156 (2023) 3
2023
-
[38]
ACM Transactions on Graphics (TOG)41(4), 1–11 (2022) 3
Vinker, Y., Pajouheshgar, E., Bo, J.Y., Bachmann, R.C., Bermano, A.H., Cohen- Or, D., Zamir, A., Shamir, A.: Clipasso: Semantically-aware object sketching. ACM Transactions on Graphics (TOG)41(4), 1–11 (2022) 3
2022
-
[39]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Vinker, Y., Shaham, T.R., Zheng, K., Zhao, A., E Fan, J., Torralba, A.: Sketcha- gent: Language-driven sequential sketch generation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 23355–23368 (2025) 4
2025
-
[40]
Visioncortex: vtracer (2020),https://www.visioncortex.org/vtracer-docs2, 3, 4, 10, 13
2020
-
[41]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang,F.,Zhao,Z.,Liu,Y.,Zhang,D.,Gao,J.,Sun,H.,Li,X.:Svgen:Interpretable vector graphics generation with large language models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 9608–9617 (2025) 4
2025
-
[42]
arXiv preprint arXiv:2510.11341 (2025)
Wang, H., Yin, J., Wei, Q., Zeng, W., Gu, L., Ye, S., Gao, Z., Wang, Y., Zhang, Y., Li, Y., et al.: Internsvg: Towards unified svg tasks with multimodal large language models. arXiv preprint arXiv:2510.11341 (2025) 4
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Z., Huang, J., Sun, Z., Gong, Y., Cohen-Or, D., Lu, M.: Layered image vectorization via semantic simplification. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7728–7738 (2025) 2, 4, 10, 11, 13
2025
-
[44]
IEEE transactions on image processing 13(4), 600–612 (2004) 10, 22, 23
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004) 10, 22, 23
2004
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, R., Su, W., Liao, J.: Chat2svg: Vector graphics generation with large language models and image diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23690–23700 (2025) 4
2025
-
[46]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 2, 4, 10, 11, 13
Wu, R., Su, W., Liao, J.: Layerpeeler: Autoregressive peeling for layer-wise image vectorization. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 2, 4, 10, 11, 13
2025
-
[47]
Xing, X., Guan, Y., Zhang, J., Xu, D., Yu, Q.: Reason-svg: Hybrid reward rl for aha-moments in vector graphics generation. arXiv preprint arXiv:2505.24499 (2025) 4 18 J. Hu et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xing, X., Hu, J., Liang, G., Zhang, J., Xu, D., Yu, Q.: Empowering llms to un- derstand and generate complex vector graphics. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19487–19497 (2025) 4
2025
-
[49]
Advances in Neural Infor- mation Processing Systems36, 15869–15889 (2023) 3
Xing, X., Wang, C., Zhou, H., Zhang, J., Yu, Q., Xu, D.: Diffsketcher: Text guided vector sketch synthesis through latent diffusion models. Advances in Neural Infor- mation Processing Systems36, 15869–15889 (2023) 3
2023
-
[50]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 3, 7
Xing, X., Yu, Q., Wang, C., Zhou, H., Zhang, J., Xu, D.: Svgdreamer++: Advanc- ing editability and diversity in text-guided svg generation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 3, 7
2025
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xing, X., Zhou, H., Wang, C., Zhang, J., Xu, D., Yu, Q.: Svgdreamer: Text guided svg generation with diffusion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4546–4555 (2024) 3
2024
-
[52]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, K., Zhang, L., Shi, J.: Amodal completion via progressive mixed context dif- fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9099–9109 (2024) 4
2024
-
[53]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xue, Z., Guo, M., Fan, H., Zhang, S., Zhang, Z.: Corrbev: Multi-view 3d object detection by correlation learning with multi-modal prototypes. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27413–27423 (2025) 4
2025
-
[54]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 4
Yang, Y., Cheng, W., Chen, S., Zeng, X., Yin, F., Zhang, J., Wang, L., Yu, G., Ma, X., Jiang, Y.G.: Omnisvg: A unified scalable vector graphics generation model. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 4
2025
-
[55]
Yin, S., Zhang, Z., Tang, Z., Gao, K., Xu, X., Yan, K., Li, J., Chen, Y., Chen, Y., Shum, H.Y., et al.: Qwen-image-layered: Towards inherent editability via layer decomposition. arXiv preprint arXiv:2512.15603 (2025) 11
-
[56]
arXiv preprint arXiv:2512.10894 (2025)
Zhang, P., Zhao, N., Fisher, M., Xu, Y., Liao, J., Liu, D.: Duetsvg: Uni- fied multimodal svg generation with internal visual guidance. arXiv preprint arXiv:2512.10894 (2025) 4
-
[57]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 10, 22, 23
2018
-
[58]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, K., Bao, L., Li, Y., Su, X., Zhang, K., Qiao, X.: Less is more: Efficient image vectorization with adaptive parameterization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18166–18175 (2025) 2, 4, 10, 11, 13
2025
-
[59]
In: European Conference on Computer Vision
Zhou, H., Zhang, H., Wang, B.: Segmentation-guided layer-wise image vectoriza- tion with gradient fills. In: European Conference on Computer Vision. pp. 165–180. Springer (2024) 2, 4, 10, 11, 13
2024
-
[60]
Zhu, H., Chong, J.I., Hu, T., Yi, R., Lai, Y.K., Rosin, P.L.: Samvg: A multi-stage image vectorization model with the segment-anything model. In: ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 4350–4354. IEEE (2024) 3, 4, 6 AmodalSVG: Amodal Image Vectorization via Semantic Layer Peeling 19 Supplem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.