Recognition: unknown
ScoRe-Flow: Complete Distributional Control via Score-Based Reinforcement Learning for Flow Matching
Pith reviewed 2026-05-10 15:58 UTC · model grok-4.3
The pith
ScoRe-Flow achieves complete distributional control in flow matching by using a closed-form score to modulate drift during RL fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The score function can be obtained in closed form directly from the velocity field of a flow matching model. Inserting this score into the drift of the equivalent stochastic differential equation, while predicting variance separately, produces a policy whose stochastic transitions have independently controllable mean and variance. This complete distributional control improves exploration and training stability when fine-tuning flow matching policies with reinforcement learning on robotic tasks.
What carries the argument
Closed-form score function derived from the velocity field that modulates the drift term, combined with separate variance prediction for decoupled mean-variance control.
If this is right
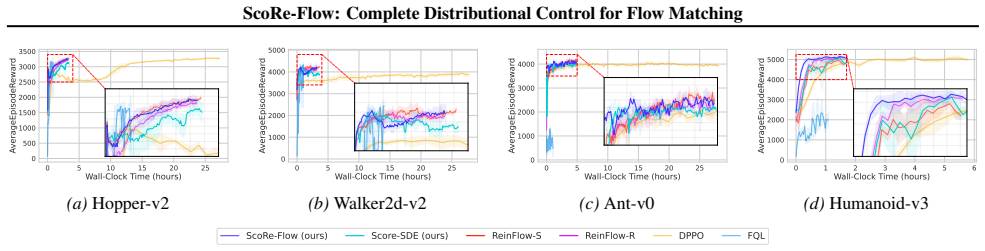
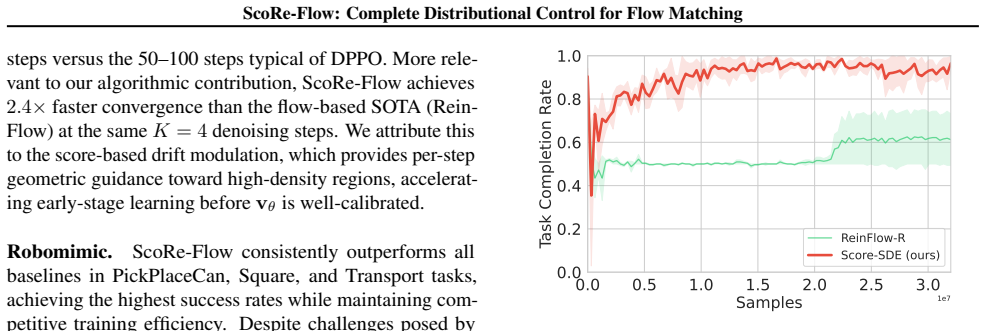
- ScoRe-Flow reaches 2.4 times faster convergence than prior flow-based methods on D4RL locomotion tasks.
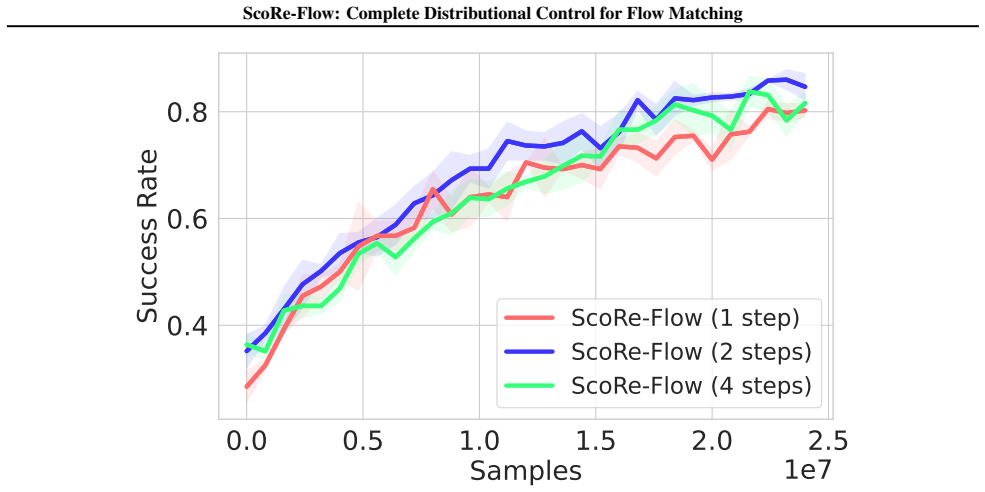
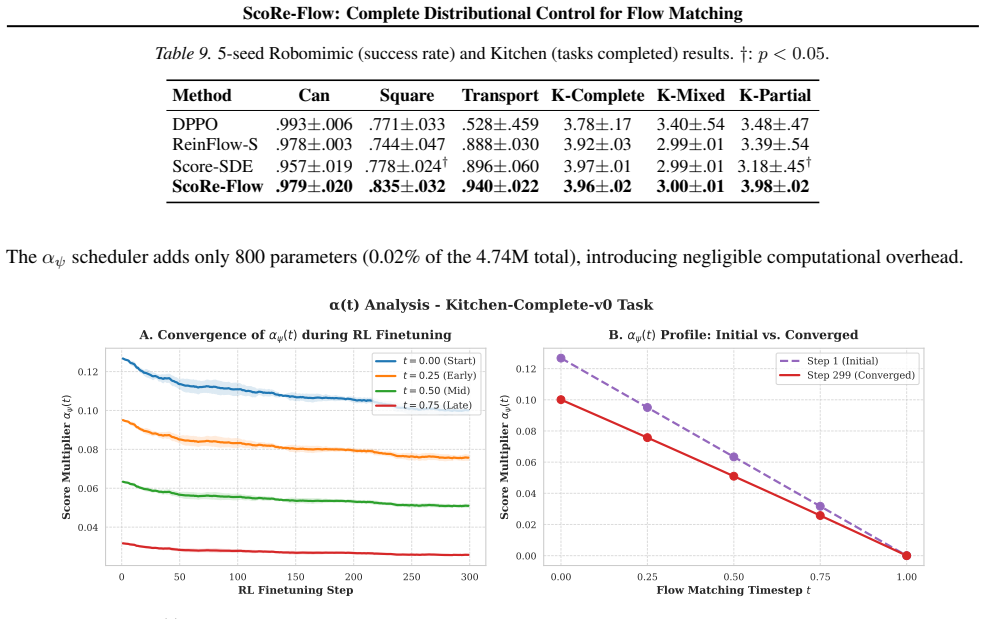
- The approach yields up to 5.4 percent higher success rates on Robomimic and Franka Kitchen manipulation benchmarks.
- No auxiliary network is required to obtain the score, preserving the efficiency of the original flow matching backbone.
- Likelihoods remain tractable while exploration is steered toward high-density regions of the state-action space.
Where Pith is reading between the lines
- The same closed-form score construction could be applied to fine-tune other continuous generative models used in robotics beyond flow matching.
- Decoupled mean-variance control may reduce the amount of demonstration data needed before reinforcement learning begins.
- The method supplies a concrete route to add calibrated uncertainty to flow-based planners without retraining the entire model.
- Direct experiments on multi-task or sim-to-real robotic settings would test whether the stability gains hold when task distributions shift.
Load-bearing premise
Modulating the drift term via the closed-form score function steers exploration toward high-probability regions and improves training stability without introducing new instabilities or bias.
What would settle it
If replacing the score-modulated drift with pure noise injection on the same D4RL locomotion tasks produced equal or faster convergence and no drop in final performance, the claimed advantage of drift modulation would be falsified.
Figures





read the original abstract
Flow Matching (FM) policies have emerged as an efficient backbone for robotic control, offering fast and expressive action generation that underpins recent large-scale embodied AI systems. However, FM policies trained via imitation learning inherit the limitations of demonstration data; surpassing suboptimal behaviors requires reinforcement learning (RL) fine-tuning. Recent methods convert deterministic flows into stochastic differential equations (SDEs) with learnable noise injection, enabling exploration and tractable likelihoods, but such noise-only control can compromise training efficiency when demonstrations already provide strong priors. We observe that modulating the drift via the score function, i.e., the gradient of log-density, steers exploration toward high-probability regions, improving stability. The score admits a closed-form expression from the velocity field, requiring no auxiliary networks. Based on this, we propose ScoRe-Flow, a score-based RL fine-tuning method that combines drift modulation with learned variance prediction to achieve decoupled control over the mean and variance of stochastic transitions. Experiments demonstrate that ScoRe-Flow achieves 2.4x faster convergence than flow-based SOTA on D4RL locomotion tasks and up to 5.4% higher success rates on Robomimic and Franka Kitchen manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ScoRe-Flow, a score-based RL fine-tuning method for flow matching policies in robotic control. It converts deterministic FM policies to SDEs, modulates the drift term using a closed-form score (gradient of log-density) derived directly from the velocity field without auxiliary networks, and pairs this with learned variance prediction to achieve decoupled mean/variance control over stochastic transitions. The approach is claimed to improve exploration stability and yield 2.4x faster convergence on D4RL locomotion tasks plus up to 5.4% higher success rates on Robomimic and Franka Kitchen manipulation tasks compared to flow-based SOTA.
Significance. If the central technical claims hold—specifically that drift modulation via the closed-form score preserves tractable unbiased likelihoods for RL gradients and reliably steers without new instabilities—the work offers a practical advance in fine-tuning expressive flow-based policies for robotics. The absence of extra networks for scoring and the decoupled control are notable strengths that could benefit large-scale embodied AI systems, provided the quantitative gains are robustly supported.
major comments (2)
- [Method / Theoretical Analysis] The derivation that modulating the SDE drift with the closed-form score from the velocity field preserves the original probability-flow density (or yields an equivalent Fokker-Planck equation) and maintains unbiased likelihoods for policy gradients must be provided explicitly. The central claim of decoupled distributional control and improved stability rests on this; without it, the RL objective may be biased as noted in the stress-test concern.
- [Experiments] Table or section reporting the D4RL and manipulation results: the 2.4x convergence and 5.4% success improvements require accompanying details on baselines, number of seeds, statistical tests, and ablations (e.g., drift modulation vs. variance-only) to substantiate attribution to the score-based component rather than other factors.
minor comments (2)
- Clarify notation for the modulated SDE (e.g., how the score term is inserted into the drift) and ensure all equations are numbered for cross-reference.
- [Abstract] The abstract could more precisely state the key assumption that the closed-form score relation extends to the modulated process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of ScoRe-Flow for fine-tuning flow-based policies in robotics. We address each major comment below with clarifications and commit to revisions that strengthen the theoretical and empirical support without altering the core contributions.
read point-by-point responses
-
Referee: [Method / Theoretical Analysis] The derivation that modulating the SDE drift with the closed-form score from the velocity field preserves the original probability-flow density (or yields an equivalent Fokker-Planck equation) and maintains unbiased likelihoods for policy gradients must be provided explicitly. The central claim of decoupled distributional control and improved stability rests on this; without it, the RL objective may be biased as noted in the stress-test concern.
Authors: We agree that an explicit derivation is essential to substantiate the claims. The manuscript already states that the score is obtained in closed form from the velocity field (which defines the probability-flow ODE), but we will expand the Methods section with a new subsection and add a dedicated appendix containing the full step-by-step derivation. This will show that the modulated drift term produces an SDE whose Fokker-Planck equation is equivalent to the original flow-matching marginals, thereby preserving the density and ensuring the likelihoods entering the RL objective remain unbiased. We will also include a brief discussion of why this construction avoids the bias concerns raised in the stress-test. revision: yes
-
Referee: [Experiments] Table or section reporting the D4RL and manipulation results: the 2.4x convergence and 5.4% success improvements require accompanying details on baselines, number of seeds, statistical tests, and ablations (e.g., drift modulation vs. variance-only) to substantiate attribution to the score-based component rather than other factors.
Authors: We concur that more granular experimental reporting is required. The current results section presents the headline metrics, but we will revise it to include: (i) a complete table listing all baselines with citations, (ii) performance averaged over five independent random seeds together with standard deviations, (iii) statistical significance tests (paired t-tests or Wilcoxon rank-sum) comparing ScoRe-Flow against the strongest baselines, and (iv) an explicit ablation study isolating drift modulation from variance-only control. These additions will appear in updated tables, figures, and an expanded experimental analysis subsection. revision: yes
Circularity Check
No circularity detected; derivation relies on standard mathematical identities in flow matching
full rationale
The paper's key step is the claim that the score function admits a closed-form expression directly from the velocity field of the base flow-matching model, with no auxiliary networks or fitted parameters. This is a standard property of probability-flow ODEs and conditional flow matching (not a self-definition or fitted input renamed as prediction). The subsequent drift modulation plus learned variance is then used for RL fine-tuning with tractable likelihoods asserted from the construction. No load-bearing self-citation chains, uniqueness theorems imported from the same authors, or ansatz smuggling appear in the abstract or described method. The reported gains are empirical on external benchmarks (D4RL, Robomimic, Franka Kitchen) rather than tautological. The derivation chain is therefore self-contained against external flow-matching and RL machinery.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned variance predictor
axioms (2)
- domain assumption The score function admits a closed-form expression from the velocity field of the flow matching model
- domain assumption Converting deterministic flows into SDEs with learnable noise enables tractable likelihoods and exploration
Reference graph
Works this paper leans on
-
[1]
Albergo, M. S. and Vanden-Eijnden, E. Stochastic inter- polants: A unifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797,
work page internal anchor Pith review arXiv
-
[2]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dhabalia, K., DiCarlo, J., Driess, D., et al. π0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759,
-
[3]
Training Diffusion Models with Reinforcement Learning
Black, K., Janner, M., Du, Y ., Kostrikov, I., and Levine, S. Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review arXiv
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Braun, M., Jaquier, N., Rozo, L., and Asfour, T. Rieman- nian flow matching policy for robot motion learning. in 2024 ieee. InRSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5144–5151. Chen, K., Liu, Z., Zhang, T., Guo, Z., Xu, S., Lin, H., Zang, H., Zhang, Q., Yu, Z., Fan, G., et al. πRL: Online rl fine-tuning for flow-based vi...
-
[6]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review arXiv 2004
-
[7]
Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning
Gupta, A., Kumar, V ., Lynch, C., Levine, S., and Hausman, K. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning.arXiv preprint arXiv:1910.11956,
-
[8]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Hansen-Estruch, P., Kostrikov, I., Janner, M., Kuba, J. G., and Levine, S. Idql: Implicit q-learning as an actor- critic method with diffusion policies.arXiv preprint arXiv:2304.10573,
work page internal anchor Pith review arXiv
-
[9]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Planning with Diffusion for Flexible Behavior Synthesis
Janner, M., Du, Y ., Tenenbaum, J. B., and Levine, S. Plan- ning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991,
work page internal anchor Pith review arXiv
-
[11]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Flow Matching for Generative Modeling
9 ScoRe-Flow: Complete Distributional Control for Flow Matching Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I. and Hutter, F. Sgdr: Stochastic gra- dient descent with warm restarts.arXiv preprint arXiv:1608.03983,
work page internal anchor Pith review arXiv
-
[14]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Mandlekar, A., Xu, D., Wong, J., Nasiriany, S., Wang, C., Kulkarni, R., Fei-Fei, L., Savarese, S., Zhu, Y ., and Mart´ın-Mart´ın, R. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298,
work page internal anchor Pith review arXiv
-
[15]
Flow Q - Learning , May 2025 c
Park, S., Li, Q., and Levine, S. Flow q-learning.arXiv preprint arXiv:2502.02538,
-
[16]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Rajeswaran, A., Kumar, V ., Gupta, A., Vezzani, G., Schul- man, J., Todorov, E., and Levine, S. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087,
-
[17]
Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
Ren, A. Z., Lidard, J., Ankile, L. L., Simeonov, A., Agrawal, P., Majumdar, A., Burchfiel, B., Dai, H., and Simchowitz, M. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588,
-
[18]
Albergo, Carles Domingo-Enrich, Nicholas M
Sabour, A., Albergo, M. S., Domingo-Enrich, C., Boffi, N. M., Fidler, S., Kreis, K., and Vanden-Eijnden, E. Test- time scaling of diffusions with flow maps.arXiv preprint arXiv:2511.22688,
-
[19]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review arXiv
-
[20]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[22]
Coefficients-preserving sampling for reinforcement learning with flow matching
Wang, F. and Yu, Z. Coefficients-preserving sampling for re- inforcement learning with flow matching.arXiv preprint arXiv:2509.05952,
-
[23]
Yu, B., Liu, J., and Cui, J. Smart-grpo: Smartly sampling noise for efficient rl of flow-matching models.arXiv preprint arXiv:2510.02654,
-
[24]
Affordance-based robot manipulation with flow matching,
Zhang, F. and Gienger, M. Affordance-based robot manipulation with flow matching.arXiv preprint arXiv:2409.01083,
-
[25]
Zhang, S., Zhang, W., and Gu, Q. Energy-weighted flow matching for offline reinforcement learning.arXiv preprint arXiv:2503.04975, 2025a. Zhang, T., Yu, C., Su, S., and Wang, Y . Reinflow: Fine- tuning flow matching policy with online reinforcement learning.arXiv preprint arXiv:2505.22094, 2025b. Zhong, S., Ding, S., Diao, H., Wang, X., Teh, K. C., and Pe...
-
[26]
arXiv preprint arXiv:2509.15207 , year=
10 ScoRe-Flow: Complete Distributional Control for Flow Matching Zhu, X., Cheng, D., Zhang, D., Li, H., Zhang, K., Jiang, C., Sun, Y ., Hua, E., Zuo, Y ., Lv, X., et al. Flowrl: Matching reward distributions for llm reasoning.arXiv preprint arXiv:2509.15207,
-
[27]
Actions True Max Ep
4 Condition Stacking 1 Denoising Steps (K) 4 BC Loss Coef (β) 0.01 Clip Interm. Actions True Max Ep. Steps / Rollout Steps 1000 / 500 Exploration Mechanism Exploration Noise Typeϵ-SDE Stochastic Learnable Noise Scheduler Explorationϵ t Schedule Linear Decay N/A Noise Hold Ratio N/A 35% of total iteration Noise Decay Target N/A0.3σ min + 0.7σmax Score Para...
1947
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.