Recognition: unknown
Delving Aleatoric Uncertainty in Medical Image Segmentation via Vision Foundation Models
Pith reviewed 2026-05-10 16:19 UTC · model grok-4.3
The pith
Vision foundation models quantify aleatoric uncertainty via singular value energy to improve medical image segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
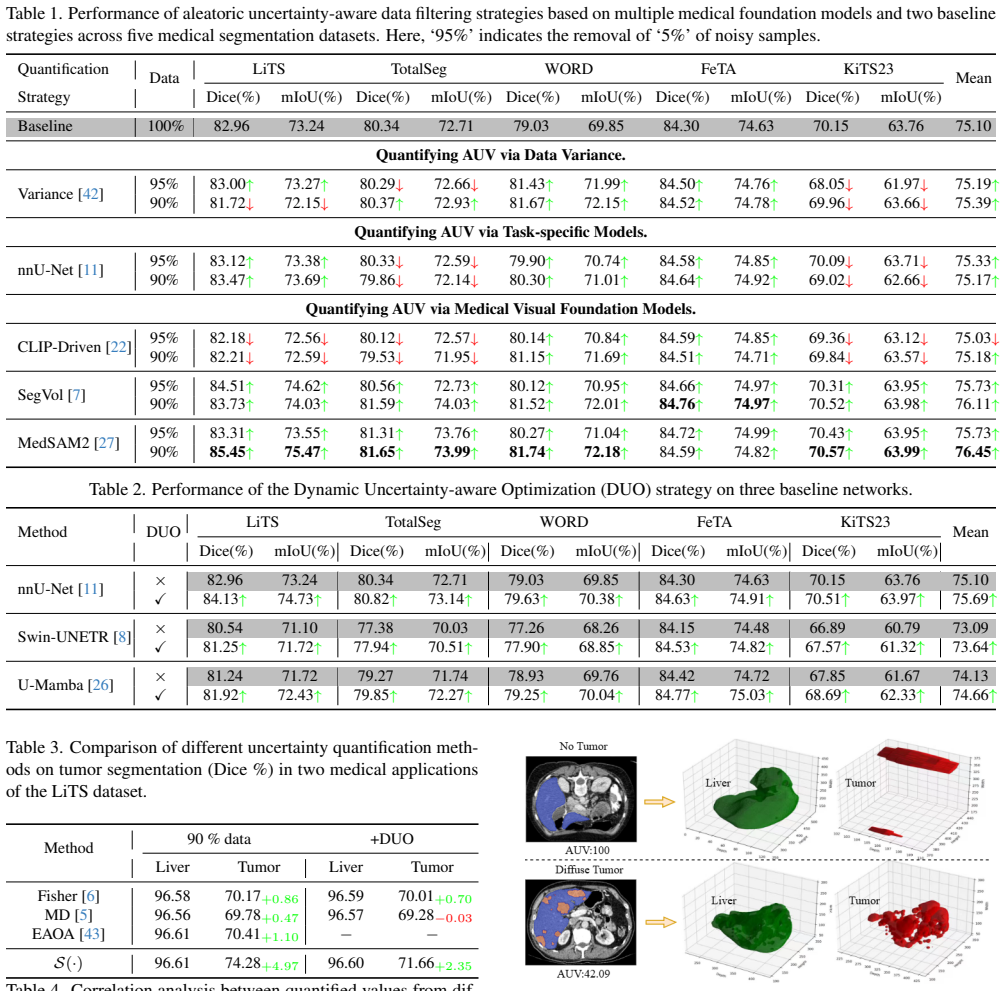
The paper claims that the singular value energy of decoded representations extracted from vision foundation models serves as a quantitative measure of the semantic perception scale for each class. This scale directly captures the aleatoric uncertainty induced by acquisition noise and annotation ambiguity in medical images. Using this measure, the method implements an aleatoric uncertainty-aware data filtering mechanism to discard noisy samples and a dynamic uncertainty-aware optimization strategy that adjusts class-specific loss weights while incorporating label denoising. Validation across five public CT and MRI datasets for multi-organ and tumor segmentation shows consistent improvements 0
What carries the argument
The semantic perception scale, computed as the singular value energy of decoded feature representations from vision foundation models, which quantifies per-class aleatoric uncertainty and guides uncertainty-aware training adjustments.
If this is right
- The filtering mechanism eliminates potentially noisy samples to enhance overall model learning quality.
- The dynamic optimization strategy adaptively adjusts class-specific loss weights based on the semantic perception scale.
- Label denoising is combined with the above to improve training stability.
- Significant and robust performance improvements are achieved across various mainstream network architectures.
- The method applies to both CT and MRI modalities in multi-organ and tumor segmentation tasks.
Where Pith is reading between the lines
- If the singular value energy correlates with human annotation variability, it could prioritize samples for expert re-labeling in dataset curation.
- The approach could be tested for generalization to non-medical dense prediction tasks with similar label noise issues.
- Integrating this data-driven uncertainty with model epistemic uncertainty estimates might enable better risk assessment in clinical applications.
Load-bearing premise
The singular value energy in the decoded representations specifically and directly reflects aleatoric uncertainty from acquisition noise and annotation ambiguity rather than capturing other unrelated sources of feature variation.
What would settle it
Observe whether the computed semantic perception scale increases when known levels of acquisition noise or label perturbations are introduced to a controlled medical image dataset, and whether removing samples according to this scale yields larger performance gains than removing random samples.
Figures



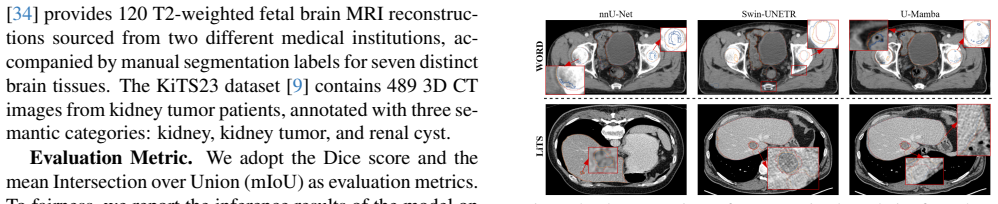

read the original abstract
Medical image segmentation supports clinical workflows by precisely delineating anatomical structures and lesions. However, medical image datasets medical image datasets suffer from acquisition noise and annotation ambiguity, causing pervasive data uncertainty that substantially undermines model robustness. Existing research focuses primarily on model architectural improvements and predictive reliability estimation, while systematic exploration of the intrinsic data uncertainty remains insufficient. To address this gap, this work proposes leveraging the universal representation capabilities of visual foundation models to estimate inherent data uncertainty. Specifically, we analyze the feature diversity of the model's decoded representations and quantify their singular value energy to define the semantic perception scale for each class, thereby measuring sample difficulty and aleatoric uncertainty. Based on this foundation, we design two uncertainty-driven application strategies: (1) the aleatoric uncertainty-aware data filtering mechanism to eliminate potentially noisy samples and enhance model learning quality; (2) the dynamic uncertainty-aware optimization strategy that adaptively adjusts class-specific loss weights during training based on the semantic perception scale, combined with a label denoising mechanism to improve training stability. Experimental results on five public datasets encompassing CT and MRI modalities and involving multi-organ and tumor segmentation tasks demonstrate that our method achieves significant and robust performance improvements across various mainstream network architectures, revealing the broad application potential of aleatoric uncertainty in medical image understanding and segmentation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision foundation models can be used to estimate aleatoric uncertainty in medical image segmentation by computing singular value energy on decoded representations to define a per-class semantic perception scale. This scale then drives an aleatoric uncertainty-aware data filtering mechanism and a dynamic uncertainty-aware optimization strategy with label denoising. The approach is reported to yield significant performance gains on five public CT/MRI datasets for multi-organ and tumor segmentation tasks across multiple mainstream network architectures.
Significance. If the singular-value-energy metric can be shown to specifically isolate aleatoric uncertainty arising from acquisition noise and annotation ambiguity (rather than anatomical complexity or model priors), the method would provide a practical, architecture-agnostic way to improve robustness in medical segmentation by directly addressing data-inherent uncertainty. The multi-dataset, multi-modality, multi-architecture evaluation is a strength that would support broad applicability if the core assumption holds.
major comments (2)
- [Methods (semantic perception scale definition)] The central claim that singular value energy of decoded VFM representations quantifies aleatoric uncertainty specifically due to acquisition noise and annotation ambiguity (as opposed to class-intrinsic feature spread or anatomical variation) is load-bearing for both the data-filtering and dynamic-weighting strategies, yet no calibration against multiple annotations, simulated noise injection, or inter-rater variability is provided to validate this specificity.
- [Experiments] The experimental results section asserts 'significant and robust performance improvements' across five datasets and various architectures, but the abstract and methods description supply no quantitative baselines, error bars, ablation studies isolating the uncertainty components, or statistical tests; without these, it is impossible to attribute gains to aleatoric-uncertainty handling rather than generic difficulty-aware reweighting.
minor comments (2)
- [Abstract] The abstract contains a duplicated phrase: 'medical image datasets medical image datasets'.
- [Methods] Notation for the semantic perception scale and singular-value-energy computation should be introduced with explicit equations and variable definitions to avoid ambiguity when the scale is later used for loss weighting.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating planned revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Methods (semantic perception scale definition)] The central claim that singular value energy of decoded VFM representations quantifies aleatoric uncertainty specifically due to acquisition noise and annotation ambiguity (as opposed to class-intrinsic feature spread or anatomical variation) is load-bearing for both the data-filtering and dynamic-weighting strategies, yet no calibration against multiple annotations, simulated noise injection, or inter-rater variability is provided to validate this specificity.
Authors: We agree that direct empirical calibration would strengthen the claim that the singular value energy metric isolates aleatoric uncertainty from acquisition noise and annotation ambiguity rather than other sources of feature diversity. Our approach is grounded in the observation that pre-trained vision foundation models produce decoded representations whose energy spectrum reflects semantic perception difficulty, which we posit correlates with data-inherent uncertainty. While we did not perform explicit multi-annotation or noise-injection experiments (as the public benchmarks lack consistent multi-rater labels), the method's effectiveness is evidenced by consistent gains across modalities and tasks. In the revised manuscript we will expand the Methods section with additional theoretical justification for the metric's specificity and include a limitations paragraph acknowledging the absence of such direct calibrations. revision: partial
-
Referee: [Experiments] The experimental results section asserts 'significant and robust performance improvements' across five datasets and various architectures, but the abstract and methods description supply no quantitative baselines, error bars, ablation studies isolating the uncertainty components, or statistical tests; without these, it is impossible to attribute gains to aleatoric-uncertainty handling rather than generic difficulty-aware reweighting.
Authors: We appreciate the referee highlighting the need for clearer attribution. The Experiments section (Section 4) contains quantitative baseline comparisons against standard segmentation methods, performance metrics reported with standard deviations from multiple random seeds, ablation studies that isolate the contributions of the uncertainty-aware filtering and dynamic optimization modules, and statistical significance testing (paired t-tests). These results are presented in tables and figures to support that gains arise from the proposed uncertainty mechanisms. The abstract and Methods provide high-level summaries. In revision we will incorporate key quantitative highlights and error-bar references into the abstract and add explicit cross-references in Methods to the ablation and statistical analyses for improved clarity. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines a semantic perception scale via singular value energy on decoded VFM representations and applies it for data filtering plus dynamic loss weighting. This is an empirical heuristic linking external pre-trained features to training adjustments, not a self-referential loop where the output is definitionally equivalent to the input. No equations reduce a claimed prediction to a fitted parameter by construction, no load-bearing self-citation chains appear, and the performance claims rest on experimental results across datasets rather than tautological renaming or ansatz smuggling. The assumption that the energy metric isolates aleatoric uncertainty specifically is an unvalidated modeling choice (correctness risk) but does not create circularity per the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decoded representations from vision foundation models contain feature diversity that reflects intrinsic data uncertainty rather than model-specific artifacts.
invented entities (1)
-
semantic perception scale
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Data-driven organic solubility prediction at the limit of aleatoric uncertainty.Nature Communications, 16(1):7497, 2025
Lucas Attia, Jackson W Burns, Patrick S Doyle, and William H Green. Data-driven organic solubility prediction at the limit of aleatoric uncertainty.Nature Communications, 16(1):7497, 2025
2025
-
[2]
Foundation models defining a new era in vision: a survey and outlook
Muhammad Awais, Muzammal Naseer, Salman Khan, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Foundation models defining a new era in vision: a survey and outlook. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025
2025
-
[3]
The liver tumor segmentation benchmark (lits).Medical Image Analysis, 84:102680, 2023
Patrick Bilic, Patrick Christ, Hongwei Bran Li, Eugene V orontsov, Avi Ben-Cohen, Georgios Kaissis, Adi Szeskin, Colin Jacobs, Gabriel Efrain Humpire Mamani, Gabriel Chartrand, et al. The liver tumor segmentation benchmark (lits).Medical Image Analysis, 84:102680, 2023
2023
-
[4]
Learning sample difficulty from pre-trained models for reliable prediction.Advances in Neural Information Process- ing Systems, 36:25390–25408, 2023
Peng Cui, Dan Zhang, Zhijie Deng, Yinpeng Dong, and Jun Zhu. Learning sample difficulty from pre-trained models for reliable prediction.Advances in Neural Information Process- ing Systems, 36:25390–25408, 2023
2023
-
[5]
Peng Cui, Guande He, Dan Zhang, Zhijie Deng, Yinpeng Dong, and Jun Zhu. Exploring aleatoric uncertainty in ob- ject detection via vision foundation models.arXiv preprint arXiv:2411.17767, 2024
-
[6]
Uncertainty estimation by fisher information-based evidential deep learning
Danruo Deng, Guangyong Chen, Yang Yu, Furui Liu, and Pheng-Ann Heng. Uncertainty estimation by fisher information-based evidential deep learning. InInternational conference on machine learning, pages 7596–7616. PMLR, 2023
2023
-
[7]
Segvol: Universal and interactive volumetric medical image segmen- tation.Advances in Neural Information Processing Systems, 37:110746–110783, 2024
Yuxin Du, Fan Bai, Tiejun Huang, and Bo Zhao. Segvol: Universal and interactive volumetric medical image segmen- tation.Advances in Neural Information Processing Systems, 37:110746–110783, 2024
2024
-
[8]
Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d med- ical image segmentation
Yufan He, Vishwesh Nath, Dong Yang, Yucheng Tang, An- driy Myronenko, and Daguang Xu. Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d med- ical image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Interven- tion, pages 416–426. Springer, 2023
2023
-
[9]
Nicholas Heller, Fabian Isensee, Dasha Trofimova, Resha Tejpaul, Zhongchen Zhao, Huai Chen, Lisheng Wang, Alex Golts, Daniel Khapun, Daniel Shats, et al. The kits21 chal- lenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase ct.arXiv preprint arXiv:2307.01984, 2023
-
[10]
A review of uncertainty quantification in medical image anal- ysis: Probabilistic and non-probabilistic methods.Medical Image Analysis, 97:103223, 2024
Ling Huang, Su Ruan, Yucheng Xing, and Mengling Feng. A review of uncertainty quantification in medical image anal- ysis: Probabilistic and non-probabilistic methods.Medical Image Analysis, 97:103223, 2024
2024
-
[11]
nnu-net: a self-configuring method for deep learning-based biomedical image segmen- tation.Nature methods, 18(2):203–211, 2021
Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Pe- tersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmen- tation.Nature methods, 18(2):203–211, 2021
2021
-
[12]
Uncertainty-guided learning for im- proving image manipulation detection
Kaixiang Ji, Feng Chen, Xin Guo, Yadong Xu, Jian Wang, and Jingdong Chen. Uncertainty-guided learning for im- proving image manipulation detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 22456–22465, 2023
2023
-
[13]
Deep learning in visual tracking: A review.IEEE transactions on neural networks and learning systems, 34 (9):5497–5516, 2021
Licheng Jiao, Dan Wang, Yidong Bai, Puhua Chen, and Fang Liu. Deep learning in visual tracking: A review.IEEE transactions on neural networks and learning systems, 34 (9):5497–5516, 2021
2021
-
[14]
The new generation brain-inspired sparse learn- ing: A comprehensive survey.IEEE Transactions on Artifi- cial Intelligence, 3(6):887–907, 2022
Licheng Jiao, Yuting Yang, Fang Liu, Shuyuan Yang, and Biao Hou. The new generation brain-inspired sparse learn- ing: A comprehensive survey.IEEE Transactions on Artifi- cial Intelligence, 3(6):887–907, 2022
2022
-
[15]
Ai meets physics: a comprehensive survey.Artificial Intelligence Review, 57(9):256, 2024
Licheng Jiao, Xue Song, Chao You, Xu Liu, Lingling Li, Puhua Chen, Xu Tang, Zhixi Feng, Fang Liu, Yuwei Guo, et al. Ai meets physics: a comprehensive survey.Artificial Intelligence Review, 57(9):256, 2024
2024
-
[16]
Multiscale deep learning for detection and recognition: A comprehen- sive survey.IEEE Transactions on Neural Networks and Learning Systems, 2024
Licheng Jiao, Mengjiao Wang, Xu Liu, Lingling Li, Fang Liu, Zhixi Feng, Shuyuan Yang, and Biao Hou. Multiscale deep learning for detection and recognition: A comprehen- sive survey.IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[17]
Foundation models meet medical image interpretation.Research, 9:1024, 2026
Licheng Jiao, Jiayao Hao, Ruiyang Li, Lingling Li, Xu Liu, Fang Liu, Wenping Ma, Puhua Chen, Zhongjian Huang, Jingyi Yang, et al. Foundation models meet medical image interpretation.Research, 9:1024, 2026
2026
-
[18]
Url: A representation learning bench- mark for transferable uncertainty estimates.Advances in Neural Information Processing Systems, 36:13956–13980, 2023
Michael Kirchhof, B ´alint Mucs ´anyi, Seong Joon Oh, and Dr Enkelejda Kasneci. Url: A representation learning bench- mark for transferable uncertainty estimates.Advances in Neural Information Processing Systems, 36:13956–13980, 2023
2023
-
[19]
Dht-net: Dy- namic hierarchical transformer network for liver and tumor segmentation.IEEE Journal of Biomedical and Health In- formatics, 2023
Ruiyang Li, Longchang Xu, Kun Xie, Jianfeng Song, Xi- aowen Ma, Liang Chang, and Qingsen Yan. Dht-net: Dy- namic hierarchical transformer network for liver and tumor segmentation.IEEE Journal of Biomedical and Health In- formatics, 2023
2023
-
[20]
Unsupervised few-shot image classification by learning features into clustering space
Shuo Li, Fang Liu, Zehua Hao, Kaibo Zhao, and Licheng Jiao. Unsupervised few-shot image classification by learning features into clustering space. InEuropean Conference on Computer Vision, pages 420–436. Springer, 2022
2022
-
[21]
Minent: Minimum entropy for self-supervised representation learning.Pattern Recognition, 138:109364, 2023
Shuo Li, Fang Liu, Zehua Hao, Licheng Jiao, Xu Liu, and Yuwei Guo. Minent: Minimum entropy for self-supervised representation learning.Pattern Recognition, 138:109364, 2023
2023
-
[22]
Clip-driven universal model for organ segmentation and tumor detection
Jie Liu, Yixiao Zhang, Jie-Neng Chen, Junfei Xiao, Yongyi Lu, Bennett A Landman, Yixuan Yuan, Alan Yuille, Yucheng Tang, and Zongwei Zhou. Clip-driven universal model for organ segmentation and tumor detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 21152–21164, 2023
2023
-
[23]
Bio-inspired multi- scale contourlet attention networks.IEEE Transactions on Multimedia, 2023
Mengkun Liu, Licheng Jiao, Xu Liu, Lingling Li, Fang Liu, Shuyuan Yang, and Xiangrong Zhang. Bio-inspired multi- scale contourlet attention networks.IEEE Transactions on Multimedia, 2023
2023
-
[24]
Biomedical foun- dation model: A survey.arXiv preprint arXiv:2503.02104, 2025
Xiangrui Liu, Yuanyuan Zhang, Yingzhou Lu, Changchang Yin, Xiaoling Hu, Xiaoou Liu, Lulu Chen, Sheng Wang, Alexander Rodriguez, Huaxiu Yao, et al. Biomedical foun- dation model: A survey.arXiv preprint arXiv:2503.02104, 2025
-
[25]
Word: A large scale dataset, benchmark and clinical applicable study for abdom- inal organ segmentation from ct image.Medical Image Anal- ysis, 82:102642, 2022
Xiangde Luo, Wenjun Liao, Jianghong Xiao, Jieneng Chen, Tao Song, Xiaofan Zhang, Kang Li, Dimitris N Metaxas, Guotai Wang, and Shaoting Zhang. Word: A large scale dataset, benchmark and clinical applicable study for abdom- inal organ segmentation from ct image.Medical Image Anal- ysis, 82:102642, 2022
2022
-
[26]
U-mamba: Enhancing long-range dependency for biomedical image segmentation
Jun Ma, Feifei Li, and Bo Wang. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722, 2024
-
[27]
Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
Jun Ma, Zongxin Yang, Sumin Kim, Bihui Chen, Mo- hammed Baharoon, Adibvafa Fallahpour, Reza Asakereh, Hongwei Lyu, and Bo Wang. Medsam2: Segment any- thing in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
-
[28]
Delving into semantic scale imbalance
Yanbiao Ma, Licheng Jiao, Fang Liu, Yuxin Li, Shuyuan Yang, and Xu Liu. Delving into semantic scale imbalance. arXiv preprint arXiv:2212.14613, 2022
-
[29]
Unveiling and mitigating generalized biases of dnns through the intrinsic dimensions of perceptual manifolds.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Yanbiao Ma, Licheng Jiao, Fang Liu, Lingling Li, Wenping Ma, Shuyuan Yang, Xu Liu, and Puhua Chen. Unveiling and mitigating generalized biases of dnns through the intrinsic dimensions of perceptual manifolds.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[30]
Predicting and enhancing the fairness of dnns with the curva- ture of perceptual manifolds.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yanbiao Ma, Licheng Jiao, Fang Liu, Maoji Wen, Lingling Li, Wenping Ma, Shuyuan Yang, Xu Liu, and Puhua Chen. Predicting and enhancing the fairness of dnns with the curva- ture of perceptual manifolds.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[31]
Foundation models for generalist medi- cal artificial intelligence.Nature, 616(7956):259–265, 2023
Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. Foundation models for generalist medi- cal artificial intelligence.Nature, 616(7956):259–265, 2023
2023
-
[32]
Benchmarking uncertainty disentanglement: Specialized un- certainties for specialized tasks.Advances in neural infor- mation processing systems, 37:50972–51038, 2024
B ´alint Mucs ´anyi, Michael Kirchhof, and Seong Joon Oh. Benchmarking uncertainty disentanglement: Specialized un- certainties for specialized tasks.Advances in neural infor- mation processing systems, 37:50972–51038, 2024
2024
-
[33]
Deep learning on a data diet: Finding important ex- amples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziu- gaite. Deep learning on a data diet: Finding important ex- amples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
2021
-
[34]
An automatic multi-tissue human fetal brain segmentation benchmark using the fetal tissue annotation dataset.Scien- tific data, 8(1):167, 2021
Kelly Payette, Priscille de Dumast, Hamza Kebiri, Ivan Ezhov, Johannes C Paetzold, Suprosanna Shit, Asim Iqbal, Romesa Khan, Raimund Kottke, Patrice Grehten, et al. An automatic multi-tissue human fetal brain segmentation benchmark using the fetal tissue annotation dataset.Scien- tific data, 8(1):167, 2021
2021
-
[35]
Angular gap: Reducing the uncertainty of image difficulty through model calibration
Bohua Peng, Mobarakol Islam, and Mei Tu. Angular gap: Reducing the uncertainty of image difficulty through model calibration. InProceedings of the 30th ACM International Conference on Multimedia, pages 979–987, 2022
2022
-
[36]
Beyond neural scaling laws: beat- ing power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beat- ing power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
2022
-
[37]
Recurrent connectivity supports higher- level visual and semantic object representations in the brain
Jacqueline V on Seth, Victoria I Nicholls, Lorraine K Tyler, and Alex Clarke. Recurrent connectivity supports higher- level visual and semantic object representations in the brain. Communications Biology, 6(1):1207, 2023
2023
-
[38]
To- talsegmentator: robust segmentation of 104 anatomic struc- tures in ct images.Radiology: Artificial Intelligence, 5(5): e230024, 2023
Jakob Wasserthal, Hanns-Christian Breit, Manfred T Meyer, Maurice Pradella, Daniel Hinck, Alexander W Sauter, Tobias Heye, Daniel T Boll, Joshy Cyriac, Shan Yang, et al. To- talsegmentator: robust segmentation of 104 anatomic struc- tures in ct images.Radiology: Artificial Intelligence, 5(5): e230024, 2023
2023
-
[39]
3d medical image segmentation using parallel trans- formers.Pattern Recognition, 138:109432, 2023
Qingsen Yan, Shengqiang Liu, Songhua Xu, Caixia Dong, Zongfang Li, Javen Qinfeng Shi, Yanning Zhang, and Duwei Dai. 3d medical image segmentation using parallel trans- formers.Pattern Recognition, 138:109432, 2023
2023
-
[40]
Structural uncertainty estima- tion for medical image segmentation.Medical Image Analy- sis, page 103602, 2025
Bing Yang, Xiaoqing Zhang, Huihong Zhang, Sanqian Li, Risa Higashita, and Jiang Liu. Structural uncertainty estima- tion for medical image segmentation.Medical Image Analy- sis, page 103602, 2025
2025
-
[41]
Ept-net: Edge perception trans- former for 3d medical image segmentation.IEEE Transac- tions on Medical Imaging, 2023
Jingyi Yang, Licheng Jiao, Ronghua Shang, Xu Liu, Ruiyang Li, and Longchang Xu. Ept-net: Edge perception trans- former for 3d medical image segmentation.IEEE Transac- tions on Medical Imaging, 2023
2023
-
[42]
One step closer to unbiased aleatoric uncertainty estimation
Wang Zhang, Ziwen Martin Ma, Subhro Das, Tsui-Wei Lily Weng, Alexandre Megretski, Luca Daniel, and Lam M Nguyen. One step closer to unbiased aleatoric uncertainty estimation. InProceedings of the AAAI Conference on Arti- ficial Intelligence, pages 16857–16864, 2024
2024
-
[43]
Rethinking epis- temic and aleatoric uncertainty for active open-set annota- tion: An energy-based approach
Chen-Chen Zong and Sheng-Jun Huang. Rethinking epis- temic and aleatoric uncertainty for active open-set annota- tion: An energy-based approach. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10153–10162, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.