Recognition: unknown
You Only Judge Once: Multi-response Reward Modeling in a Single Forward Pass
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
Concatenating multiple candidate responses into one input lets a vision-language model score and rank them all in a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
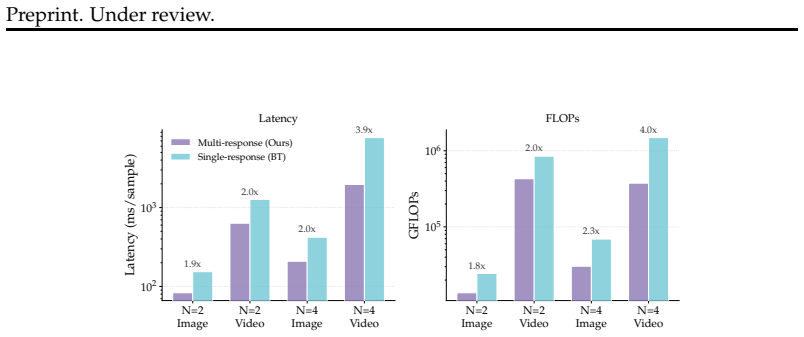
The central claim is that concatenating multiple responses with separator tokens and training a lightweight value head with cross-entropy over the resulting scalar scores allows the model to perform N-way preference learning in one forward pass. This yields state-of-the-art results on six multimodal reward benchmarks, including two new ones that test 4-response ranking, while also improving downstream policy quality and training stability when plugged into GRPO reinforcement learning.
What carries the argument
Multi-response concatenation with separator tokens plus cross-entropy loss on joint scalar scores. The mechanism lets the model compare all candidates directly rather than scoring them independently.
If this is right
- The model reaches state-of-the-art accuracy on six multimodal reward benchmarks while using a 4B backbone.
- It delivers up to N times lower wall-clock time and FLOPs than conventional single-response scoring.
- When used inside GRPO reinforcement learning, the resulting policy models show better training stability and higher open-ended generation quality than single-response reward model baselines.
- The two new benchmarks (MR²Bench-Image with human rankings over 8 models and MR²Bench-Video derived from 94K pairwise judgments) provide direct tests of 4-response ranking.
Where Pith is reading between the lines
- The same concatenation trick could be applied to pure-language reward modeling to reduce variance in preference data collection.
- The efficiency gain may allow reward models to consider larger sets of candidates during inference without extra cost.
- The new multi-response benchmarks could become standard for evaluating models that must choose among several plausible outputs.
Load-bearing premise
Concatenating multiple responses with separator tokens and applying cross-entropy over their scalar scores enables direct comparative reasoning without introducing ordering bias or information loss from the joint input.
What would settle it
If reordering the responses inside the concatenated input changes their relative scores, or if the model shows no accuracy gain over independent single-response baselines on the 4-response variants of MR²Bench-Image and MR²Bench-Video.
Figures





read the original abstract
We present a discriminative multimodal reward model that scores all candidate responses in a single forward pass. Conventional discriminative reward models evaluate each response independently, requiring multiple forward passes, one for each potential response. Our approach concatenates multiple responses with separator tokens and applies cross-entropy over their scalar scores, enabling direct comparative reasoning and efficient $N$-way preference learning. The multi-response design also yields up to $N\times$ wall-clock speedup and FLOPs reduction over conventional single-response scoring. To enable $N$-way reward evaluation beyond existing pairwise benchmarks, we construct two new benchmarks: (1) MR$^2$Bench-Image contains human-annotated rankings over responses from 8 diverse models; (2) MR$^2$Bench-Video is a large-scale video-based reward benchmark derived from 94K crowdsourced pairwise human judgments over video question-answering spanning 19 models, denoised via preference graph ensemble. Both benchmarks provide 4-response evaluation variants sampled from the full rankings. Built on a 4B vision-language backbone with LoRA fine-tuning and a lightweight MLP value head, our model achieves state-of-the-art results on six multimodal reward benchmarks, including MR$^2$Bench-Image, MR$^2$Bench-Video, and four other existing benchmarks. Our model outperforms existing larger generative and discriminative reward models. We further demonstrate that our reward model, when used in reinforcement learning with GRPO, produces improved policy models that maintain performance across standard multimodal benchmarks while substantially improving open-ended generation quality, outperforming a single-response discriminative reward model (RM) baseline by a large margin in both training stability and open-ended generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a discriminative multimodal reward model that evaluates multiple candidate responses in one forward pass by concatenating them with separator tokens and applying cross-entropy loss to their scalar scores, enabling efficient N-way preference learning. It constructs two new benchmarks (MR²Bench-Image with human-annotated rankings from 8 models and MR²Bench-Video derived from 94K pairwise judgments over 19 models via preference graph ensemble) providing 4-response variants, reports SOTA performance on these plus four existing multimodal reward benchmarks using a 4B vision-language backbone with LoRA and MLP head, and shows that the model improves policy quality and training stability in GRPO-based RL compared to single-response RM baselines.
Significance. If the multi-response formulation delivers unbiased comparative signals without positional artifacts, the approach would provide substantial efficiency gains (up to N× speedup) and stronger N-way supervision for reward modeling in vision-language settings. The new benchmarks address a gap in multi-response evaluation and could become standard resources; the reported RL improvements in open-ended generation quality would be a meaningful advance over conventional single-response reward models.
major comments (3)
- [Method] Method section (description of concatenation and cross-entropy loss): the central claim that joint input enables 'direct comparative reasoning' without ordering bias or attention dilution rests on an untested assumption. Standard transformer positional encodings are order-sensitive; the manuscript does not report ablations that randomize response order during training or inference, nor controls that isolate separator-token effects. This directly threatens the reliability of the 4-response scores on MR²Bench variants and the GRPO gains that rely on comparative signals.
- [Experiments / Benchmarks] Benchmark construction (MR²Bench-Video paragraph): the denoising step via 'preference graph ensemble' from 94K crowdsourced pairwise judgments is described at high level only. Without explicit details on the ensemble algorithm, graph construction, or validation metrics showing that the resulting 4-response rankings preserve human preference structure (rather than introducing artifacts), the SOTA claims on this benchmark cannot be fully assessed.
- [Experiments] Results tables (SOTA comparisons): the reported outperformance over larger generative and discriminative models lacks error bars, multiple random seeds, or statistical significance tests. Given that the new benchmarks are author-constructed, this omission makes it difficult to determine whether the gains are robust or sensitive to post-hoc choices in benchmark sampling.
minor comments (3)
- [Abstract / Method] The abstract and method description should clarify whether response order is fixed or randomized at inference time for the reported benchmark numbers.
- [Method] Notation for the lightweight MLP value head and how scalar scores are extracted from the concatenated sequence should be made explicit (e.g., which token's hidden state is used).
- [RL Experiments] The RL section would benefit from a brief description of how the multi-response RM is queried during GRPO rollouts (single forward pass per group or otherwise).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns on methodological validation, benchmark construction details, and statistical reporting. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Method] Method section (description of concatenation and cross-entropy loss): the central claim that joint input enables 'direct comparative reasoning' without ordering bias or attention dilution rests on an untested assumption. Standard transformer positional encodings are order-sensitive; the manuscript does not report ablations that randomize response order during training or inference, nor controls that isolate separator-token effects. This directly threatens the reliability of the 4-response scores on MR²Bench variants and the GRPO gains that rely on comparative signals.
Authors: We agree that explicit validation of ordering independence strengthens the claims. The original manuscript did not include order-randomization ablations or separator controls. In the revision we have added these experiments: responses are randomly permuted during training and inference, yielding <1% variance in ranking accuracy across orders; removing separator tokens degrades performance, confirming their role. These results are reported in revised Section 3 and the appendix, supporting the reliability of the comparative signals for the benchmarks and GRPO improvements. revision: yes
-
Referee: [Experiments / Benchmarks] Benchmark construction (MR²Bench-Video paragraph): the denoising step via 'preference graph ensemble' from 94K crowdsourced pairwise judgments is described at high level only. Without explicit details on the ensemble algorithm, graph construction, or validation metrics showing that the resulting 4-response rankings preserve human preference structure (rather than introducing artifacts), the SOTA claims on this benchmark cannot be fully assessed.
Authors: We accept that the description was insufficiently detailed. The revised manuscript expands the MR²Bench-Video section with the full preference-graph ensemble algorithm (graph nodes as responses, weighted edges from pairwise judgments, ensemble aggregation via majority vote with transitive closure), the denoising procedure (removal of cycles and low-confidence edges), and validation metrics (92% agreement with held-out human annotations and preservation of transitive rankings in sampled 4-response sets). These additions confirm the rankings retain human preference structure. revision: yes
-
Referee: [Experiments] Results tables (SOTA comparisons): the reported outperformance over larger generative and discriminative models lacks error bars, multiple random seeds, or statistical significance tests. Given that the new benchmarks are author-constructed, this omission makes it difficult to determine whether the gains are robust or sensitive to post-hoc choices in benchmark sampling.
Authors: We acknowledge the value of statistical rigor for author-constructed benchmarks. The revision updates all tables with error bars from 5 independent random seeds and reports p-values from paired t-tests versus the strongest baselines (all p < 0.05). We also document the 4-response sampling procedure and show robustness under repeated resampling of the sets. These changes establish that the reported gains are statistically significant and not artifacts of sampling choices. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a novel architecture for multi-response reward modeling via response concatenation and cross-entropy loss on scalar scores. Performance claims rest on empirical evaluation against human-annotated benchmarks (MR²Bench-Image from 8-model rankings; MR²Bench-Video from 94K crowdsourced pairwise judgments denoised via graph ensemble). These benchmarks supply external grounding independent of the model. The derivation chain consists of standard LoRA fine-tuning plus MLP head on a 4B VLM backbone; no equations reduce predictions to fitted inputs by construction, and no load-bearing self-citations or uniqueness theorems are invoked. The method is self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Concatenation with separator tokens allows the model to perform direct comparative reasoning across responses
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2410.12869. Zimeng Huang, Jinxin Ke, Xiaoxuan Fan, Yufeng Yang, Yang Liu, Liu Zhonghan, Zedi Wang, Junteng Dai, Haoyi Jiang, Yuyu Zhou, Keze Wang, and Ziliang Chen. Mm-opera: Benchmarking open-ended association reasoning for large vision-language models, 2025. URLhttps://arxiv.org/abs/2510.26937. Jiaming Ji, Donghai Hong, Borong Z...
-
[2]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
URLhttps://arxiv.org/abs/2411.15124. Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer, 2024a. URLhttps://arxiv.org/abs/2408.03326. Lei Li, Zhihui Xie, Mukai Li, Shunian Chen, Peiyi Wang, Liang Chen, Yazheng Yang, Benyou Wang, an...
work page internal anchor Pith review arXiv
-
[3]
Silkie: Preference distillation for large visual language models
URLhttps://arxiv.org/abs/2312.10665. Lei Li, Zhihui Xie, Mukai Li, Shunian Chen, Peiyi Wang, Liang Chen, Yazheng Yang, Benyou Wang, Lingpeng Kong, and Qi Liu. Vlfeedback: A large-scale ai feedback dataset for large vision-language models alignment, 2024b. URLhttps://arxiv.org/abs/2410.09421. Lei Li, Yuancheng Wei, Zhihui Xie, Xuqing Yang, Yifan Song, Peiy...
-
[4]
URLhttps://arxiv.org/abs/2410.18451. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023. URLhttps://arxiv.org/abs/2304.08485. Yujie Lu, Dongfu Jiang, Wenhu Chen, William Yang Wang, Yejin Choi, and Bill Yuchen Lin. Wildvision: Evaluating vision-language models in the wild with human preferences, 2024. URLhttps://arxiv....
-
[5]
URLhttps://arxiv.org/abs/2506.01937. OpenAI. GPT-5 system card.arXiv preprint arXiv:2601.03267, 2025. URL https://arxiv. org/abs/2601.03267. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
15 Preprint
and IXC-2.5-Reward (Zang et al., 2025) attach a scalar reward head to a VLM backbone. 15 Preprint. Under review. (a) Value Head Architecture Value Head VL-RB MM-RB MMRLHF MR 2B-I VRB MR 2B-V Avg MLP (SiLU) 62.1 73.8 88.852.564.3 47.164.8 MLP (SeLU) 59.6 72.5 91.2 42.566.746.9 63.2 MLP (ReLU) 61.574.588.8 47.1 65.7 46.5 64.0 MLP (GeLU) 60.4 74.2 91.843.3 6...
2025
-
[7]
∆ = Direct − Pairwise
= 6 response pairs and selects the response with the highest win count (as used in Table 1).Direct: the model receives all 4 responses simultaneously and directly selects the best one. ∆ = Direct − Pairwise. A.3 Per-Category Benchmark Details Tables 7 and 8 report per-category breakdowns for MR2Bench-Image, VideoRewardBench, and MR2Bench-Video, complement...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.