Recognition: unknown
Optimal multiple testing under family-wise error control: elementary symmetric polynomials and a scalable algorithm
Pith reviewed 2026-05-10 16:30 UTC · model grok-4.3
The pith
Elementary symmetric polynomials of likelihood ratios yield closed-form FWER constraints and a scalable optimal test for exchangeable hypotheses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The family-wise error rate constraint coefficients b_{l,k}(vec u) admit closed-form expressions through elementary symmetric polynomials of the likelihood-ratio values g(u_1),...,g(u_K). This algebraic structure implies a global monotonicity theorem: the target functions F_gamma(mu) = FWER_gamma(D^mu) are simultaneously non-increasing in every component of mu, for arbitrary K, which guarantees unique coordinate-wise roots and enables a bisection-based coordinate-descent algorithm with O(log ε^{-1}) convergence rate.
What carries the argument
Elementary symmetric polynomials of the likelihood-ratio values g(u_1) to g(u_K), which supply the closed-form expressions for the FWER constraint coefficients b_{l,k} and establish the monotonicity property.
If this is right
- The optimal dual vector mu* can be recovered by a coordinate-descent procedure whose per-coordinate search converges at rate O(log epsilon inverse).
- The resulting test produces relative power gains over Hommel's method that grow from 15 percent at K equals 3 to 84 percent at K equals 12.
- Unique coordinate-wise roots exist for every equation because each target function is strictly monotone in its own variable.
- The procedure applies directly to replication studies, clinical trials, and replicability assessments that satisfy the exchangeability condition.
Where Pith is reading between the lines
- If the exchangeability assumption holds only approximately, the same algorithmic skeleton may still yield useful power improvements in practice.
- Analogous closed-form reductions could be sought for other multiple-testing criteria whenever a comparable symmetry is present.
- The monotonicity result supplies a design principle that may guide the construction of tests even when the hypotheses exhibit limited dependence.
Load-bearing premise
The K hypotheses are exchangeable, that is, identically distributed under the null hypothesis.
What would settle it
A concrete numerical counter-example with small K in which any of the target functions F_gamma(mu) increases when one coordinate of mu is increased while the others are held fixed would disprove the monotonicity theorem.
Figures

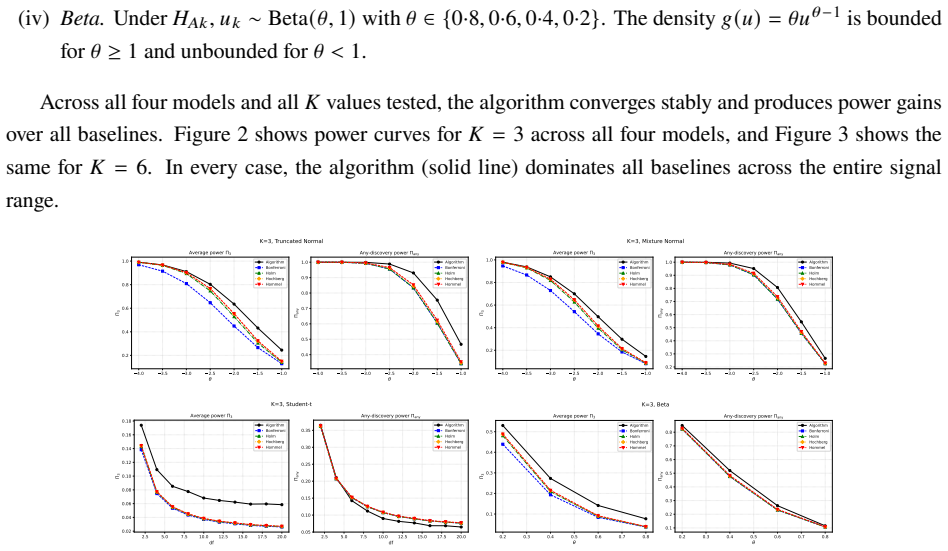


read the original abstract
Simultaneously testing $K$ hypotheses while controlling the family-wise error rate is a fundamental problem in statistics. Existing procedures (Bonferroni, Holm, Hochberg, Hommel) provide valid control but sacrifice power, increasingly so as $K$ grows, because they base decisions on marginal $p$-value ranks rather than the joint likelihood. Rosset et al. (2022) formulated the most powerful family-wise-error-rate-controlling test as a dual program and proved the existence of an optimal dual vector $\mu^*$, but left its computation as an open problem. We solve this problem for $K$ exchangeable hypotheses. The key insight is that the family-wise error rate constraint coefficients $b_{l,k}(\vec{u})$ admit closed-form expressions through elementary symmetric polynomials of the likelihood-ratio values $g(u_1), \ldots, g(u_K)$. This algebraic structure implies a global monotonicity theorem: the target functions $F_\gamma(\mu) = {\rm FWER}_\gamma(\vec{D}^\mu)$ are simultaneously non-increasing in every component of $\mu$, for arbitrary $K$, which guarantees unique coordinate-wise roots and enables a bisection-based coordinate-descent algorithm with $O(\log \varepsilon^{-1})$ convergence rate. The relative power gain over Hommel's method grows from 15\% at $K{=}3$ to 84\% at $K{=}12$. Applications to replication studies, a clinical trial, and a replicability assessment illustrate both the power gains and the role of the exchangeability assumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to resolve the open computational problem posed by Rosset et al. (2022) for finding the optimal dual vector μ* that yields the most powerful FWER-controlling test. For exchangeable hypotheses, the authors derive closed-form expressions for the FWER constraint coefficients b_{l,k}(u) in terms of elementary symmetric polynomials of the likelihood-ratio values g(u_i), establish a global monotonicity theorem showing that F_γ(μ) is simultaneously non-increasing in each coordinate of μ for any K, and use this to construct a coordinate-wise bisection algorithm with O(log ε^{-1}) convergence. Numerical results report relative power gains over Hommel's procedure ranging from 15% at K=3 to 84% at K=12, with illustrations on replication studies, a clinical trial, and replicability assessment.
Significance. If the algebraic reduction to symmetric polynomials and the accompanying monotonicity theorem are correct, the work supplies a practical, scalable algorithm that closes the computational gap left by the dual-program formulation of Rosset et al. and delivers measurable power improvements for moderate K under the stated exchangeability assumption. The approach is parameter-free once the g(u_i) are fixed, directly leverages the symmetry to avoid exponential complexity, and is supported by reproducible applications; these features make the contribution substantive for multiple-testing methodology in statistics.
major comments (1)
- [§4, Theorem 2] §4, Theorem 2 (monotonicity): the claim that F_γ(μ) is simultaneously non-increasing in every coordinate of μ for arbitrary K rests on the closed-form b_{l,k} via symmetric polynomials; the provided sketch should be expanded to an explicit inductive or combinatorial argument showing that the partial derivatives remain non-positive under exchangeability, as this is the load-bearing step enabling the bisection procedure.
minor comments (3)
- [§5.2, Table 2] §5.2, Table 2: the reported power gains are given as relative percentages; adding absolute power values (or the underlying rejection counts) for each method and K would allow readers to assess the practical magnitude of the improvement.
- [Notation] Notation: the definition of the likelihood-ratio function g(u_i) and its relation to the dual variables μ should be restated once in the main text (currently only in the appendix), as it is used repeatedly in the symmetric-polynomial expressions.
- [§6] §6 (applications): the replicability-assessment example would benefit from an explicit statement of how the exchangeability assumption is justified or checked for the selected studies.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the specific suggestion regarding the proof of Theorem 2. We address the comment below and will incorporate the requested expansion in the revised manuscript.
read point-by-point responses
-
Referee: [§4, Theorem 2] §4, Theorem 2 (monotonicity): the claim that F_γ(μ) is simultaneously non-increasing in every coordinate of μ for arbitrary K rests on the closed-form b_{l,k} via symmetric polynomials; the provided sketch should be expanded to an explicit inductive or combinatorial argument showing that the partial derivatives remain non-positive under exchangeability, as this is the load-bearing step enabling the bisection procedure.
Authors: We agree that a fully explicit proof strengthens the paper. The manuscript currently presents a sketch that derives the closed-form b_{l,k}(u) via elementary symmetric polynomials and invokes their properties to conclude monotonicity. In the revision we will replace the sketch with a complete inductive argument on K. The base case K=1 is immediate. For the inductive step we fix all but one coordinate of μ, increase the remaining coordinate, and track the resulting change in each FWER coefficient b_{l,k} through the recurrence relations satisfied by the elementary symmetric polynomials. Because the likelihood ratios g(u_i) are non-negative and the hypotheses are exchangeable, each incremental change in a symmetric polynomial term is non-positive, which propagates to show that every partial derivative of F_γ(μ) is non-positive. This explicit induction makes the load-bearing step self-contained and directly justifies the coordinate-wise bisection procedure. No other changes to the results or algorithm are required. revision: yes
Circularity Check
No significant circularity identified
full rationale
The derivation begins from the external dual-program formulation of Rosset et al. (2022) and introduces independent algebraic closed forms for the b_{l,k} coefficients via elementary symmetric polynomials of the g(u_i) under the stated exchangeability assumption. The global monotonicity theorem for F_gamma(mu) is proved directly from those closed forms, enabling the coordinate-wise bisection algorithm. No equation reduces by construction to a fitted input, self-referential definition, or load-bearing self-citation; the cited prior work supplies only the optimization setup while the paper supplies the explicit solution and convergence guarantee.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The K hypotheses are exchangeable (identically distributed under the null).
Reference graph
Works this paper leans on
-
[1]
Yoav Benjamini and Yosef Hochberg
doi: 10.1126/science.1211180. Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: A practical and powerful approach to multiple testing.Journal of the Royal Statistical Society. Series B (Methodological), 57(1):289–300,
-
[2]
URLhttp://www.jstor.org/stable/2346101. Carlo Emilio Bonferroni. Teoria statistica delle classi e calcolo delle probabilit `a. InPubblicazioni del R Istituto Superiore di Scienze Economiche e Commerciali di Firenze, volume 8, pages 3–62. Libreria Internazionale Seeber, Firenze, Italy,
-
[3]
doi: 10.1002/sim.3495. Colin F. Camerer, Anna Dreber, Felix Holzmeister, Teck-Hua Ho, J¨ urgen Huber, Magnus Johannesson, Michael Kirchler, Gideon Nave, Brian A. Nosek, Thomas Pfeiffer, et al. Evaluating the replicability of 20 social science experiments in Nature and Science between 2010 and 2015.Nature Human Behaviour, 2: 637–644,
-
[4]
Maxime Derex, Marie-Pauline Beugin, Bernard Godelle, and Michel Raymond
doi: 10.1038/s41562-018-0399-z. Maxime Derex, Marie-Pauline Beugin, Bernard Godelle, and Michel Raymond. Experimental evidence for the influence of group size on cultural complexity.Nature, 503:389–391,
-
[5]
Edgar Dobriban, Kristen Fortney, Stuart K
doi: 10.1038/nature12774. Edgar Dobriban, Kristen Fortney, Stuart K. Kim, and Art B. Owen. Optimal multiple testing under a gaussian prior on the effect sizes.Biometrika, 102(4):753–766, 11
-
[6]
URLhttps://doi.org/10.1093/biomet/asv050
doi: 10.1093/biomet/asv050. URLhttps://doi.org/10.1093/biomet/asv050. Prasanjit Dubey and Xiaoming Huo. Most Powerful Test with Exact Family-Wise Error Rate Control: Necessary Conditions and a Path to Fast Computing.arXiv preprint arXiv:2512.14131,
-
[7]
Katherine Duncan, Arjun Sadanand, and Lila Davachi
URL https://arxiv.org/abs/2512.14131. Katherine Duncan, Arjun Sadanand, and Lila Davachi. Memory’s penumbra: episodic memory decisions induce lingering mnemonic biases.Science, 337:485–488,
-
[8]
doi: 10.1126/science.1221936. Yosef Hochberg. A sharper Bonferroni procedure for multiple tests of significance.Biometrika, 75(4): 800–802,
-
[9]
URLhttp://www.jstor.org/stable/2336325
doi: 10.2307/2336325. URLhttp://www.jstor.org/stable/2336325. Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6 (2):65–70,
- [10]
-
[11]
Ramesh Johari, Pete Koomen, Leonid Pekelis, and David Walsh
URLhttp://www.jstor.org/stable/2336190. Ramesh Johari, Pete Koomen, Leonid Pekelis, and David Walsh. Always valid inference: Continuous monitoring of A/B tests.Operations Research, 70(3):1806–1821,
-
[12]
´Agnes Melinda Kov´acs, Ern˝o T´egl´as, and Ansgar Denis Endress
doi: 10.1287/opre.2021.2135. ´Agnes Melinda Kov´acs, Ern˝o T´egl´as, and Ansgar Denis Endress. The social sense: Susceptibility to others’ beliefs in human infants and adults.Science, 330:1830–1834,
-
[13]
doi: 10.1126/science.1190792. E. L. Lehmann, Joseph P. Romano, and Juliet Popper Shaffer. On optimality of stepdown and stepup multiple test procedures.The Annals of Statistics, 33(3):1084 – 1108,
-
[14]
URLhttps://doi.org/10.1214/009053605000000066
doi: 10.1214/009053605000000066. URLhttps://doi.org/10.1214/009053605000000066. John A List, Azeem M Shaikh, and Yang Xu. Multiple hypothesis testing in experimental economics. Working Paper 21875, National Bureau of Economic Research, January
-
[15]
doi: 10.1126/science.aac4716. Stuart J. Pocock, Nancy L. Geller, and Anastasios A. Tsiatis. The analysis of multiple endpoints in clinical trials.Biometrics, 43(3):487–498,
-
[16]
URLhttp://www.jstor.org/stable/2531989. 21 David G. Rand, Joshua D. Greene, and Martin A. Nowak. Spontaneous giving and calculated greed.Nature, 489:427–430,
-
[17]
doi: 10.1038/nature11467. Joseph P. Romano and Michael Wolf. Stepwise multiple testing as formalized data snooping.Econometrica, 73(4):1237–1282,
-
[18]
doi: 10.1111/j.1468-0262.2005.00615.x. Joseph P. Romano and Michael Wolf. Control of generalized error rates in multiple testing.The Annals of Statistics, 35(4):1378 – 1408,
-
[19]
doi: 10.1214/009053606000001622. URLhttps://doi.org/10. 1214/009053606000001622. Michael Rosenblum, Han Liu, and En-Hsu Yen. Optimal tests of treatment effects for the overall population and two subpopulations in randomized trials, using sparse linear programming.Journal of the American Statistical Association, 109(507):1216–1228,
-
[20]
doi: 10.1080/01621459.2013.879063. URLhttps: //doi.org/10.1080/01621459.2013.879063. Saharon Rosset, Ruth Heller, Amichai Painsky, and Ehud Aharoni. Optimal and maximin procedures for multiple testing problems.Journal of the Royal Statistical Society Series B, 84(4):1105–1128, September
-
[21]
URLhttps://ideas.repec.org/a/bla/jorssb/ v84y2022i4p1105-1128.html
doi: 10.1111/rssb.12507. URLhttps://ideas.repec.org/a/bla/jorssb/ v84y2022i4p1105-1128.html. Betsy Sparrow, Jenny Liu, and Daniel M. Wegner. Google effects on memory: Cognitive consequences of having information at our fingertips.Science, 333:776–778,
-
[22]
doi: 10.1126/science.1207745. Emil Spjøtvoll. On the optimality of some multiple comparison procedures.Annals of Mathematical Statistics, 43:398–411,
-
[23]
Victoria Vickerstaff, Rumana Omar, and Gareth Ambler
doi: 10.1056/NEJMoa1511939. Victoria Vickerstaff, Rumana Omar, and Gareth Ambler. Methods to adjust for multiple comparisons in the analysis and sample size calculation of randomised controlled trials with multiple primary outcomes. BMC Medical Research Methodology, 19, 06
-
[24]
Davide Viviano, Kaspar Wuthrich, and Paul Niehaus
doi: 10.1186/s12874-019-0754-4. Davide Viviano, Kaspar Wuthrich, and Paul Niehaus. A model of multiple hypothesis testing,
- [25]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.