Recognition: unknown
EgoFun3D: Modeling Interactive Objects from Egocentric Videos using Function Templates
Pith reviewed 2026-05-10 16:29 UTC · model grok-4.3
The pith
Function templates capture cross-part interactions in 3D objects from egocentric videos and compile directly into simulation code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
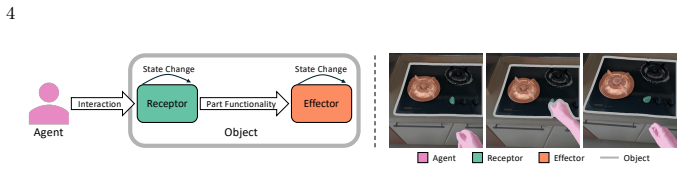
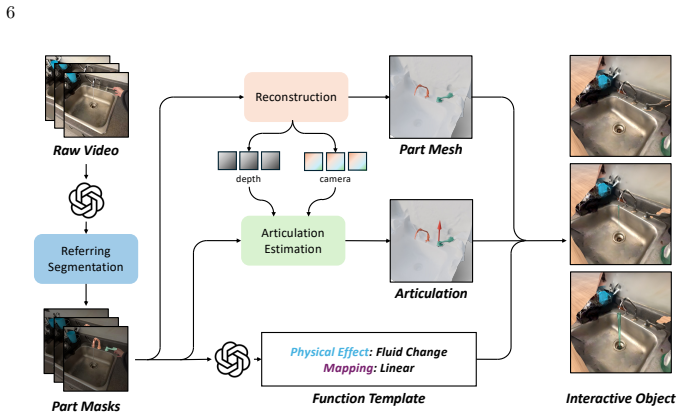
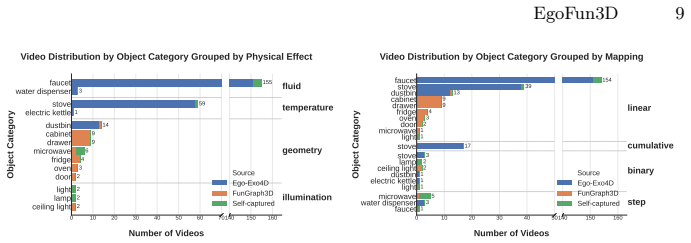
We present EgoFun3D, a coordinated task formulation, dataset, and benchmark for modeling interactive 3D objects from egocentric videos. While prior work largely focuses on articulations, we capture general cross-part functional mappings through function templates, a structured computational representation that enables precise evaluation and direct compilation into executable code across simulation platforms. To enable comprehensive benchmarking, we introduce a dataset of 271 egocentric videos featuring challenging real-world interactions with paired 3D geometry, segmentation over 2D and 3D, articulation and function template annotations. To tackle the task, we propose a 4-stage pipeline of 2
What carries the argument
Function templates, a structured computational representation that records general cross-part functional mappings and compiles them into executable simulation code.
If this is right
- Interactive 3D models obtained from video can be executed as code in multiple simulation environments without manual reprogramming.
- Functional accuracy of object models can be measured quantitatively by comparing template outputs to observed part behaviors.
- A shared benchmark of video, geometry, and templates allows direct comparison of methods for segmentation, reconstruction, and functional inference.
- Separation of geometry from function allows the same template to apply across objects that share interaction patterns.
Where Pith is reading between the lines
- Robotic systems could acquire manipulation skills by converting everyday human videos into simulated practice environments.
- The templates could serve as an intermediate layer for language models to describe or predict object functions from visual input.
- Extending the approach to longer video sequences might capture time-dependent functions such as heating rates or locking mechanisms.
- Synthetic data generated from the compiled templates could augment training sets for vision models that must recognize functional relationships.
Load-bearing premise
Egocentric videos contain enough visual information for the four-stage pipeline to recover accurate 3D geometry, articulations, and function templates despite real-world variations in lighting and viewpoint.
What would settle it
Run the full pipeline on a held-out set of videos and check whether the resulting function templates, when executed in a simulator, reproduce the exact interaction outcomes observed in the original footage.
Figures






read the original abstract
We present EgoFun3D, a coordinated task formulation, dataset, and benchmark for modeling interactive 3D objects from egocentric videos. Interactive objects are of high interest for embodied AI but scarce, making modeling from readily available real-world videos valuable. Our task focuses on obtaining simulation-ready interactive 3D objects from egocentric video input. While prior work largely focuses on articulations, we capture general cross-part functional mappings (e.g., rotation of stove knob controls stove burner temperature) through function templates, a structured computational representation. Function templates enable precise evaluation and direct compilation into executable code across simulation platforms. To enable comprehensive benchmarking, we introduce a dataset of 271 egocentric videos featuring challenging real-world interactions with paired 3D geometry, segmentation over 2D and 3D, articulation and function template annotations. To tackle the task, we propose a 4-stage pipeline consisting of: 2D part segmentation, reconstruction, articulation estimation, and function template inference. Comprehensive benchmarking shows that the task is challenging for off-the-shelf methods, highlighting avenues for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EgoFun3D as a new task formulation, dataset (271 egocentric videos with paired 3D geometry, 2D/3D segmentation, articulation, and function template annotations), and benchmark for obtaining simulation-ready interactive 3D objects from egocentric video. It introduces function templates as a structured computational representation capturing general cross-part functional mappings (e.g., knob rotation controlling burner temperature) that support precise evaluation and direct compilation to executable code in simulators. A 4-stage pipeline (2D part segmentation, reconstruction, articulation estimation, function template inference) is proposed to tackle the task, with benchmarking showing that off-the-shelf methods struggle.
Significance. If the pipeline and function templates can be shown to work reliably, the work would be significant for embodied AI by addressing the scarcity of interactive 3D models through modeling from common egocentric videos. The dataset and annotations provide a valuable new benchmark, while function templates offer a novel, structured alternative to articulation-only representations that could enable more general and portable simulation. The emphasis on direct compilability to code is a strength if demonstrated.
major comments (2)
- [Abstract and Evaluation/Results] The abstract and evaluation sections state that 'comprehensive benchmarking shows that the task is challenging for off-the-shelf methods' but report no quantitative metrics (accuracy, error rates, simulation fidelity, or end-to-end success rates) for the authors' own 4-stage pipeline on the 271-video dataset. This absence directly undermines the central claim that the pipeline produces usable simulation-ready objects via function templates.
- [Abstract and §4 (Pipeline description)] The claim that function templates 'enable direct compilation into executable code across simulation platforms' (abstract) is presented without any demonstrated examples, compilation procedure, or fidelity metrics in the pipeline description or results; this is load-bearing for the novelty of the representation.
minor comments (2)
- [Dataset section] Clarify the exact criteria for video selection and annotation protocol for the 271-video dataset to support reproducibility.
- [Figures] Ensure figures showing pipeline outputs include clear comparisons to ground-truth annotations and simulation results.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript. We address each major comment point by point below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Evaluation/Results] The abstract and evaluation sections state that 'comprehensive benchmarking shows that the task is challenging for off-the-shelf methods' but report no quantitative metrics (accuracy, error rates, simulation fidelity, or end-to-end success rates) for the authors' own 4-stage pipeline on the 271-video dataset. This absence directly undermines the central claim that the pipeline produces usable simulation-ready objects via function templates.
Authors: We appreciate the referee for highlighting this issue. The benchmarking in the manuscript applies off-the-shelf methods to the individual stages of the proposed 4-stage pipeline and reports their performance on the EgoFun3D dataset to demonstrate the inherent challenges of the task. The pipeline itself is presented as an initial baseline approach rather than a fully optimized solution with claimed high-fidelity outputs. The abstract and results sections emphasize the new task, dataset, and function template representation, along with the difficulties faced by existing methods, without asserting end-to-end quantitative superiority for the pipeline. We agree that adding quantitative metrics would strengthen the presentation of the pipeline's utility for producing simulation-ready objects. In the revised manuscript, we will add a dedicated evaluation subsection reporting metrics such as part segmentation IoU, articulation parameter errors, and function template matching accuracy on the 271-video dataset. revision: yes
-
Referee: [Abstract and §4 (Pipeline description)] The claim that function templates 'enable direct compilation into executable code across simulation platforms' (abstract) is presented without any demonstrated examples, compilation procedure, or fidelity metrics in the pipeline description or results; this is load-bearing for the novelty of the representation.
Authors: We thank the referee for this observation. Function templates are introduced in the manuscript as a structured representation capturing cross-part functional mappings, with the abstract noting their support for precise evaluation and direct compilation to executable code. The current version defines the template structure and its role in the pipeline but does not include concrete compilation examples or fidelity metrics. This capability is positioned as a core advantage for portability and simulator integration. We acknowledge that explicit demonstration is needed to fully substantiate the claim. In the revision, we will expand Section 4 to include an illustrative example of compiling a function template to code for a standard simulator (e.g., with pseudocode or a specific platform), along with a general description of the compilation procedure. revision: yes
Circularity Check
No significant circularity; new task, dataset, and pipeline are independent contributions
full rationale
The paper introduces a new coordinated task, 271-video dataset with independent annotations (2D/3D segmentation, articulations, function templates), and a 4-stage pipeline (2D segmentation, reconstruction, articulation estimation, function template inference). Function templates are defined as a novel structured representation for cross-part mappings without being derived from or equivalent to the pipeline outputs by construction. Benchmarking evaluates off-the-shelf methods rather than claiming predictions from fitted parameters on the same data. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way that reduces the central claims to prior author work or self-referential definitions. The derivation chain consists of empirical task formulation and data collection that remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Egocentric videos contain sufficient information to infer 3D geometry, articulations, and functional mappings via the proposed pipeline.
invented entities (1)
-
Function templates
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: 8th Annual Conference on Robot Learning (2024) 2
Abou-Chakra, J., Rana, K., Dayoub, F., Suenderhauf, N.: Physically Embodied Gaussian Splatting: A Realtime Correctable World Model for Robotics. In: 8th Annual Conference on Robot Learning (2024) 2
2024
-
[2]
Authors, G.: Genesis: A Generative and Universal Physics Engine for Robotics and Beyond (December 2024),https://github.com/Genesis-Embodied-AI/Genesis 2, 5, 8, 14, 20, 21, 22, 29
2024
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2602.16356 (2026) 4
Buechner, M., Roefer, A., Engelbracht, T., Welschehold, T., Bauer, Z., Blum, H., Pollefeys, M., Valada, A.: Articulated 3D Scene Graphs for Open-World Mobile Manipulation. arXiv preprint arXiv:2602.16356 (2026) 4
-
[5]
In: NeurIPS (2025) 3, 4
Cao, Z., Chen, Z., Pan, L., Liu, Z.: PhysX-3D: Physical-Grounded 3D Asset Gen- eration. In: NeurIPS (2025) 3, 4
2025
-
[6]
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
2025
-
[7]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 3
Chen, C., Liu, I., Wei, X., Su, H., Liu, M.: FreeArt3D: Training-Free Articulated Object Generation using 3D Diffusion. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 3
2025
-
[8]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 3
Chen, H., Lan, Y., Chen, Y., Pan, X.: ArtiLatent: Realistic Articulated 3D Object Generation via Structured Latents. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 3
2025
-
[9]
In: Robotics: Science and Systems (RSS) (2024) 3
Chen, Z., Walsman, A., Memmel, M., Mo, K., Fang, A., Vemuri, K., Wu, A., Fox, D., Gupta, A.: URDFormer: A Pipeline for Constructing Articulated Simulation Environments from Real-World Images. In: Robotics: Science and Systems (RSS) (2024) 3
2024
-
[10]
arXiv (2026) 9, 10
Clark, C., Zhang, J., Ma, Z., Park, J.S., Salehi, M., Tripathi, R., Lee, S., Ren, Z., Kim,C.D.,Yang,Y.,Shao,V.,Yang,Y.,Huang,W.,Gao,Z.,Anderson,T.,Zhang, 16 J., Jain, J., Stoica, G., Han, W., Farhadi, A., Krishna, R.: Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding. arXiv (2026) 9, 10
2026
-
[11]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Corsetti, J., Giuliari, F., Fasoli, A., Boscaini, D., Poiesi, F.: Functionality under- standing and segmentation in 3D scenes. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24550–24559 (2025) 3
2025
-
[12]
CoRL (2025) 2
Dan, P., Kedia, K., Chao, A., Duan, E.W., Pace, M.A., Ma, W.C., Choudhury, S.: X-Sim: Cross-Embodiment Learning via Real-to-Sim-to-Real. CoRL (2025) 2
2025
-
[13]
In: CVPR (2024) 2, 3, 4
Delitzas, A., Takmaz, A., Tombari, F., Sumner, R., Pollefeys, M., Engelmann, F.: SceneFun3D: Fine-Grained Functionality and Affordance Understanding in 3D Scenes. In: CVPR (2024) 2, 3, 4
2024
-
[14]
In: IEEE Conference on Computer Vision and Pattern Recognition (2024) 9
Edstedt, J., Sun, Q., Bökman, G., Wadenbäck, M., Felsberg, M.: RoMa: Robust Dense Feature Matching. In: IEEE Conference on Computer Vision and Pattern Recognition (2024) 9
2024
-
[15]
In: CVPR (2026) 3, 4
Engelbracht, T., Zurbrügg, R., Wohlrapp, M., Büchner, M., Valada, A., Pollefeys, M., Blum, H., Bauer, Z.: Hoi!-A Multimodal Dataset for Force-Grounded, Cross- View Articulated Manipulation. In: CVPR (2026) 3, 4
2026
-
[16]
CoRR (2025) 2
Escontrela, A., Kerr, J., Allshire, A., Frey, J., Duan, R., Sferrazza, C., Abbeel, P.: GaussGym: An Open-Source Real-To-Sim Framework for Learning Locomotion from Pixels. CoRR (2025) 2
2025
-
[17]
google/products-and-platforms/products/gemini/gemini-3/9, 10, 23
Gemini Team: A new era of intelligence with Gemini 3 (2025),https://blog. google/products-and-platforms/products/gemini/gemini-3/9, 10, 23
2025
-
[18]
In: CVPR (2024) 2, 3, 7
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-Exo4D: Understand- ing Skilled Human Activity from First- and Third-Person Perspectives. In: CVPR (2024) 2, 3, 7
2024
-
[19]
arXiv preprint arXiv:2512.24845 (2025) 4
Gu, Q., Sheng, Y., Yu, J., Tang, J., Shan, X., Shen, Z., Yi, T., Liang, X., Chen, X., Wang, Y.: ArtiSG: Functional 3D Scene Graph Construction via Human- demonstrated Articulated Objects Manipulation. arXiv preprint arXiv:2512.24845 (2025) 4
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025) 3, 4
Halacheva, A.M., Miao, Y., Zaech, J.N., Wang, X., Van Gool, L., Paudel, D.P.: Articulate3D: Holistic Understanding of 3D Scenes as Universal Scene Description. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025) 3, 4
2025
-
[21]
arXiv preprint arXiv:2508.10934 (2025)
Huang, J., Zhou, Q., Rabeti, H., Korovko, A., Ling, H., Ren, X., Shen, T., Gao, J., Slepichev, D., Lin, C.H., Ren, J., Xie, K., Biswas, J., Leal-Taixe, L., Fidler, S.: ViPE: Video Pose Engine for 3D Geometric Perception. In: NVIDIA Research Whitepapers arXiv:2508.10934 (2025) 9
-
[22]
ICCV (2025) 2
Jiang, H., Hsu, H.Y., Zhang, K., Yu, H.N., Wang, S., Li, Y.: Phystwin: Physics- informed reconstruction and simulation of deformable objects from videos. ICCV (2025) 2
2025
-
[23]
In: European Conference on Computer Vision
Jiang, H., Mao, Y., Savva, M., Chang, A.X.: OPD: Single-view 3D openable part detection. In: European Conference on Computer Vision. pp. 410–426. Springer (2022) 2
2022
-
[24]
In: ICLR (2026) 3, 4
Jin, Z., Che, Z., Zhao, Z., Wu, K., Zhang, Y., Zhao, Y., Liu, Z., Zhang, Q., Ju, X., Tian, J., et al.: ArtVIP: Articulated Digital Assets of Visual Realism, Modular Interaction, and Physical Fidelity for Robot Learning. In: ICLR (2026) 3, 4
2026
-
[25]
In: International Conference on 3D Vision (2026) 7, 9, 24
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, EgoFun3D 17 M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: Ma- pAnything: Universal Feed-Forward Metric 3D Reconstruction. In: International Conference on 3D Vision (2026) 7, 9, 24
2026
-
[26]
AI2-THOR: An Interactive 3D Environment for Visual AI
Kolve, E., Mottaghi, R., Han, W., VanderBilt, E., Weihs, L., Herrasti, A., Deitke, M., Ehsani, K., Gordon, D., Zhu, Y., et al.: AI2-THOR: An interactive 3D envi- ronment for visual AI. arXiv preprint arXiv:1712.05474 (2017) 2
work page internal anchor Pith review arXiv 2017
-
[27]
In: International Con- ference on Learning Representations (ICLR) (2025) 3
Le, L., Xie, J., Liang, W., Wang, H.J., Yang, Y., Ma, Y.J., Vedder, K., Krishna, A., Jayaraman, D., Eaton, E.: Articulate-Anything: Automatic Modeling of Artic- ulated Objects via a Vision-Language Foundation Model. In: International Con- ference on Learning Representations (ICLR) (2025) 3
2025
-
[28]
In: Conference on Robot Learning
Li, C., Zhang, R., Wong, J., Gokmen, C., Srivastava, S., Martín-Martín, R., Wang, C.,Levine,G.,Lingelbach,M.,Sun,J.,etal.:BEHAVIOR-1K:AHuman-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation. In: Conference on Robot Learning. pp. 80–93. PMLR (2023) 2, 3, 4, 5, 8, 14, 21, 22, 29
2023
-
[29]
In: CVPR (2025) 3
Li, Z., Zhang, C., Li, Z., Howard-Jenkins, H., Lv, Z., Geng, C., Wu, J., Newcombe, R., Engel, J., Dong, Z.: ART: Articulated Reconstruction Transformer. In: CVPR (2025) 3
2025
-
[30]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth Anything 3: Recovering the Visual Space from Any Views. arXiv preprint arXiv:2511.10647 (2025) 9, 24
work page internal anchor Pith review arXiv 2025
-
[31]
arXiv preprint arXiv:2409.19650 (2024) 3
Liu, C., Zhai, W., Yang, Y., Luo, H., Liang, S., Cao, Y., Zha, Z.J.: Grounding 3D Scene Affordance From Egocentric Interactions. arXiv preprint arXiv:2409.19650 (2024) 3
-
[32]
In: International Conference on Learning Representations (ICLR) (2025) 3
Liu, J., Iliash, D., Chang, A.X., Savva, M., Mahdavi-Amiri, A.: SINGAPO: Sin- gle Image Controlled Generation of Articulated Parts in Object. In: International Conference on Learning Representations (ICLR) (2025) 3
2025
-
[33]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2023) 2, 3
Liu, J., Mahdavi-Amiri, A., Savva, M.: PARIS: Part-level Reconstruction and Mo- tion Analysis for Articulated Objects. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2023) 2, 3
2023
-
[34]
In: Computer Graphics Forum
Liu, J., Savva, M., Mahdavi-Amiri, A.: Survey on Modeling of Human-made Ar- ticulated Objects. In: Computer Graphics Forum. vol. 44, p. e70092. Wiley Online Library (2025) 2
2025
-
[35]
arXiv preprint arXiv:2509.17647 (2025) 2, 3
Liu, Y., Jia, B., Lu, R., Gan, C., Chen, H., Ni, J., Zhu, S.C., Huang, S.: VideoArtGS:BuildingDigitalTwinsofArticulatedObjectsfromMonocularVideo. arXiv preprint arXiv:2509.17647 (2025) 2, 3
-
[36]
In: International Confer- ence on Learning Representations (ICLR) (2025) 2, 3
Liu, Y., Jia, B., Lu, R., Ni, J., Zhu, S.C., Huang, S.: Building Interactable Replicas of Complex Articulated Objects via Gaussian Splatting. In: International Confer- ence on Learning Representations (ICLR) (2025) 2, 3
2025
-
[37]
In: ICLR (2026) 9
Liu, Y., Qu, T., Zhong, Z., PENG, B., Liu, S., Yu, B., Jia, J.: VisionReasoner: Unified Reasoning-Integrated Visual Perception via Reinforcement Learning. In: ICLR (2026) 9
2026
-
[38]
In: International Conference on Learning Represen- tations (ICLR) (2025) 3
Mandi, Z., Weng, Y., Bauer, D., Song, S.: Real2Code: Reconstruct Articulated Objects via Code Generation. In: International Conference on Learning Represen- tations (ICLR) (2025) 3
2025
-
[39]
In: RSS (2025) 2
Ning, C., Fang, K., Ma, W.C.: Prompting with the Future: Open-World Model Predictive Control with Interactive Digital Twins. In: RSS (2025) 2
2025
-
[40]
NVIDIA: Isaac Sim,https://github.com/isaac-sim/IsaacSim2, 5, 8, 20, 21, 29
-
[41]
https://openai.com/index/introducing-gpt-5/ (2025) 10 18
OpenAI: Introducing GPT-5. https://openai.com/index/introducing-gpt-5/ (2025) 10 18
2025
-
[42]
In: CVPR (2025) 7
Pataki, Z., Sarlin, P.E., Schönberger, J.L., Pollefeys, M.: MP-SfM: Monocular Sur- face Priors for Robust Structure-from-Motion. In: CVPR (2025) 7
2025
-
[43]
In: International Conference on 3D Vision (2026) 2, 3, 4, 10
Peng, W., Lv, J., Lu, C., Savva, M.: iTACO: Interactable Digital Twins of Articu- lated Objects from Casually Captured RGBD Videos. In: International Conference on 3D Vision (2026) 2, 3, 4, 10
2026
-
[44]
In: 8th Annual Conference on Robot Learning (2024) 2
Peng, W., Lv, J., Zeng, Y., Chen, H., Zhao, S., Sun, J., Lu, C., Shao, L.: TieBot: Learning to Knot a Tie from Visual Demonstration through a Real-to-Sim-to-Real Approach. In: 8th Annual Conference on Robot Learning (2024) 2
2024
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025) 2, 3
Perrett, T., Darkhalil, A., Sinha, S., Emara, O., Pollard, S., Parida, K., Liu, K., Gatti, P., Bansal, S., Flanagan, K., Chalk, J., Zhu, Z., Guerrier, R., Abdelazim, F., Zhu, B., Moltisanti, D., Wray, M., Doughty, H., Damen, D.: HD-EPIC: A Highly- Detailed Egocentric Video Dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern ...
2025
-
[46]
Polycam: Polycam (2025),https://poly.cam/7
2025
-
[47]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: SAM 2: Segment Anything in Images and Videos. arXiv preprint arXiv:2408.00714 (2024) 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Record3D: Record3d (2025),https://record3d.app/7
2025
-
[49]
In: IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (2025) 4
Rotondi, D., Scaparro, F., Blum, H., Arras, K.O.: FunGraph: Functionality Aware 3D Scene Graphs for Language-Prompted Scene Interaction. In: IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (2025) 4
2025
-
[50]
In: Scientific and Medical Knowledge Production, 1796-1918, pp
Sherrington, C.S.: The Integrative Action of the Nervous System. In: Scientific and Medical Knowledge Production, 1796-1918, pp. 217–253. Routledge (2023) 2
1918
-
[51]
In: CVPR (2026) 7
Siddiqui, Y., Frost, D., Aroudj, S., Avetisyan, A., Howard-Jenkins, H., DeTone, D., Moulon, P., Wu, Q., Li, Z., Straub, J., Newcombe, R., Engel, J.: ShapeR: Robust Conditional 3D Shape Generation from Casual Captures. In: CVPR (2026) 7
2026
-
[52]
Todorov, E., Erez, T., Tassa, Y.: MuJoCo: A physics engine for model-based con- trol. In: IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 5026–5033. IEEE (2012).https://doi.org/10.1109/IROS.2012.638610920
-
[53]
In: RSS (2024) 2
Torne, M., Simeonov, A., Li, Z., Chan, A., Chen, T., Gupta, A., Agrawal, P.: Rec- onciling Reality Through Simulation: A Real-to-Sim-to-Real Approach for Robust Manipulation. In: RSS (2024) 2
2024
-
[54]
In: AAAI (2026) 9
Wang, H., Qiao, L., Jie, Z., Huang, Z., Feng, C., Zheng, Q., Ma, L., Lan, X., Liang, X.: X-SAM: From Segment Anything to Any Segmentation. In: AAAI (2026) 9
2026
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, X., Zhou, B., Shi, Y., Chen, X., Zhao, Q., Xu, K.: Shape2Motion: Joint Analysis of Motion Parts and Attributes from 3D Shapes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8876– 8884 (2019) 2
2019
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 2, 3
Weng, Y., Wen, B., Tremblay, J., Blukis, V., Fox, D., Guibas, L., Birchfield, S.: Neural Implicit Representation for Building Digital Twins of Unknown Articulated Objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 2, 3
2024
-
[57]
Conference on Robot Learning (CoRL) (2025) 3, 4, 10
Werby, A., Buechner, M., Roefer, A., Huang, C., Burgard, W., Valada, A.: Ar- ticulated Object Estimation in the Wild. Conference on Robot Learning (CoRL) (2025) 3, 4, 10
2025
-
[58]
arXiv pre-print (2025) 9 EgoFun3D 19
Yuan, H., Li, X., Zhang, T., Sun, Y., Huang, Z., Xu, S., Ji, S., Tong, Y., Qi, L., Feng, J., Yang, M.H.: Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos. arXiv pre-print (2025) 9 EgoFun3D 19
2025
-
[59]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 3
Yuan, S., Shi, R., Wei, X., Zhang, X., Su, H., Liu, M.: LARM: A Large Articu- lated Object Reconstruction Model. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers (2025) 3
2025
-
[60]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, C., Delitzas, A., Wang, F., Zhang, R., Ji, X., Pollefeys, M., Engelmann, F.: Open-Vocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19401–19413 (2025) 2, 3, 4, 7
2025
-
[61]
Object"].data.joint_pos.Jointstatesarechanged by setting the target joint values:scene[
Zhang, K., Sha, S., Jiang, H., Loper, M., Song, H., Cai, G., Xu, Z., Hu, X., Zheng, C., Li, Y.: Real-to-Sim Robot Policy Evaluation with Gaussian Splatting Simula- tion of Soft-Body Interactions. In: ICRA (2026) 2 20 Supplementary Material A Function Template Implementation Details A.1 Formalization Details Here, we provide in more detail the formalizatio...
2026
-
[62]
Which part of the object r ec ei ve s human action ? \
-
[63]
Which part of the object reacts to human action ? \ 4Please de scr ib e the name and fea tu re s of the part as well as the spatial r e l a t i o n s h i p with s u r r o u n d i n g objects . \ 5Please only answer in this te mp la te : \ 6{1: { name : xxx , d e s c r i p t i o n : aaa } , 2: { name : yyy , d e s c r i p t i o n : bbb }} \ 7S u b s t i t ...
-
[64]
Which p hy sic al effect best d e s c r i b e s the f u n c t i o n a l r e l a t i o n s h i p between the red part and green part ? Please choose one from the f o l l o w i n g : \ 18( a ) ge om et ry change \ 19( b ) i l l u m i n a t i o n change \ 20( c ) t e m p e r a t u r e change \ 21( d ) fluid change \
-
[65]
1\": \" xxx \
Which f un cti on best d e s c r i b e s the n u m e r i c a l r e l a t i o n s h i p between the state of the red part and the green part ? Please choose one from the f o l l o w i n g : \ 23( a ) binary fu nct io n \ 24( b ) step f un cti on \ 25( c ) linear fu nct io n \ 26( d ) c u m u l a t i v e fu nct io n \ 27Please only answer in this te mp la t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.