Recognition: 2 theorem links
· Lean TheoremEmergentBridge: Improving Zero-Shot Cross-Modal Transfer in Unified Multimodal Embedding Models
Pith reviewed 2026-05-13 07:10 UTC · model grok-4.3
The pith
EmergentBridge connects unpaired modalities in unified embeddings by aligning them only in directions orthogonal to existing anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EmergentBridge improves zero-shot cross-modal transfer by learning a mapping that produces a noisy bridge anchor from an already-aligned embedding and then enforcing proxy alignment exclusively in the subspace orthogonal to the anchor-alignment direction, which preserves the structure used by existing retrieval and classification while increasing connectivity for unpaired modality pairs.
What carries the argument
The orthogonal subspace restriction applied to proxy alignment, which isolates new-modality updates from the directions that support existing anchor alignments.
If this is right
- Zero-shot classification and retrieval improve on unpaired modality combinations without collecting exhaustive pairwise labels.
- Existing alignments between anchor modalities remain stable when new modalities are added.
- Unified embedding spaces become more scalable because new modalities can be incorporated using only partial supervision.
- Emergent alignment appears between previously disconnected pairs such as audio-depth or infrared-audio.
Where Pith is reading between the lines
- The orthogonal-update idea could extend to continual addition of modalities without full retraining of the embedding space.
- Similar subspace isolation might help in other embedding domains where partial alignments must be preserved while adding new entities.
- The method suggests a general pattern for growing multimodal systems incrementally while protecting performance on the original tasks.
Load-bearing premise
Naively aligning a new modality to a synthesized proxy embedding introduces gradient interference that degrades anchor alignments, and restricting the alignment to the orthogonal subspace avoids this interference while still strengthening the desired connections.
What would settle it
Running the same experiments with the orthogonal restriction removed and finding no degradation in anchor zero-shot performance would show that the subspace constraint is not required to prevent interference.
Figures





read the original abstract
Unified multimodal embedding spaces underpin practical applications such as cross-modal retrieval and zero-shot recognition. In many real deployments, however, supervision is available only for a small subset of modality pairs (e.g., image--text), leaving \emph{unpaired} modality pairs (e.g., audio$\leftrightarrow$depth, infrared$\leftrightarrow$audio) weakly connected and thus performing poorly on zero-shot transfer. Addressing this sparse-pairing regime is therefore essential for scaling unified embedding systems to new tasks without curating exhaustive pairwise data. We propose \textbf{EmergentBridge}, an embedding-level bridging framework that improves performance on these unpaired pairs \emph{without requiring exhaustive pairwise supervision}. Our key observation is that naively aligning a new modality to a synthesized proxy embedding can introduce \emph{gradient interference}, degrading the anchor-alignment structure that existing retrieval/classification relies on. EmergentBridge addresses this by (i) learning a mapping that produces a \emph{noisy bridge anchor} (a proxy embedding of an already-aligned modality) from an anchor embedding, and (ii) enforcing proxy alignment only in the subspace orthogonal to the anchor-alignment direction, preserving anchor alignment while strengthening non-anchor connectivity. Across nine datasets spanning multiple modalities, EmergentBridge consistently outperforms prior binding baselines on zero-shot classification and retrieval, demonstrating strong emergent alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EmergentBridge, an embedding-level bridging framework for improving zero-shot cross-modal transfer in unified multimodal models under sparse modality-pair supervision. It identifies gradient interference from naive proxy alignment as a key issue and addresses it via a noisy bridge anchor combined with proxy alignment restricted to the orthogonal complement of the anchor-alignment direction. The central empirical claim is consistent outperformance over prior binding baselines on zero-shot classification and retrieval across nine datasets spanning multiple modalities.
Significance. If the empirical results hold under detailed scrutiny, the work could meaningfully advance scalable unified multimodal embeddings by enabling stronger connectivity for unpaired modalities without exhaustive pairwise data. The orthogonal-subspace constraint offers a lightweight structural solution to preserving anchor alignments while enhancing emergent connectivity, which may prove useful in other alignment settings.
major comments (1)
- [§4 (Experiments)] §4 (Experiments): The abstract states that EmergentBridge 'consistently outperforms prior binding baselines on zero-shot classification and retrieval' across nine datasets, yet the manuscript provides no full experimental details, baseline specifications, exact metrics, ablations, or statistical significance tests. This absence is load-bearing because the outperformance claim is the primary support for the method's effectiveness and for the assertion that the orthogonal restriction avoids side effects on existing alignments.
minor comments (2)
- [Abstract] Abstract: The phrase 'noisy bridge anchor' is introduced without an accompanying equation or precise definition of the noise model, making it difficult to reproduce the construction from the text alone.
- [Abstract] Abstract: The claim that the method works 'without requiring exhaustive pairwise supervision' would be strengthened by an explicit statement of the minimal supervision regime used in the experiments (e.g., which modality pairs remain unpaired).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the experimental claims require substantially more detail to be fully convincing and will revise the paper accordingly.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): The abstract states that EmergentBridge 'consistently outperforms prior binding baselines on zero-shot classification and retrieval' across nine datasets, yet the manuscript provides no full experimental details, baseline specifications, exact metrics, ablations, or statistical significance tests. This absence is load-bearing because the outperformance claim is the primary support for the method's effectiveness and for the assertion that the orthogonal restriction avoids side effects on existing alignments.
Authors: We acknowledge that the submitted manuscript does not present the experimental protocol with sufficient completeness. In the revised version we will expand §4 with: (i) full dataset descriptions and preprocessing for all nine benchmarks, (ii) exact baseline implementations, architectures, and hyper-parameters, (iii) complete numerical tables reporting all metrics (accuracy, mAP, Recall@K, etc.) together with standard deviations over multiple random seeds, (iv) targeted ablations that isolate the noisy-bridge-anchor component and the orthogonal-subspace constraint, and (v) statistical significance tests (paired t-tests and Wilcoxon signed-rank tests) comparing EmergentBridge against each baseline. These additions will directly substantiate the outperformance claim and demonstrate that the orthogonal restriction preserves anchor-alignment performance. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central proposal introduces a structural constraint (noisy bridge anchor plus orthogonal-subspace restriction) to mitigate an observed training issue in multimodal embeddings. This is framed as an empirical engineering solution rather than a derivation that reduces to its own fitted parameters or self-referential definitions. No load-bearing step equates a claimed prediction or uniqueness result to an input by construction, and the performance claims rest on external dataset evaluations rather than internal tautologies. Self-citations, if present, are not invoked to justify the core mechanism as an external theorem.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embedding spaces contain identifiable anchor-alignment directions that can be isolated from other connectivity directions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
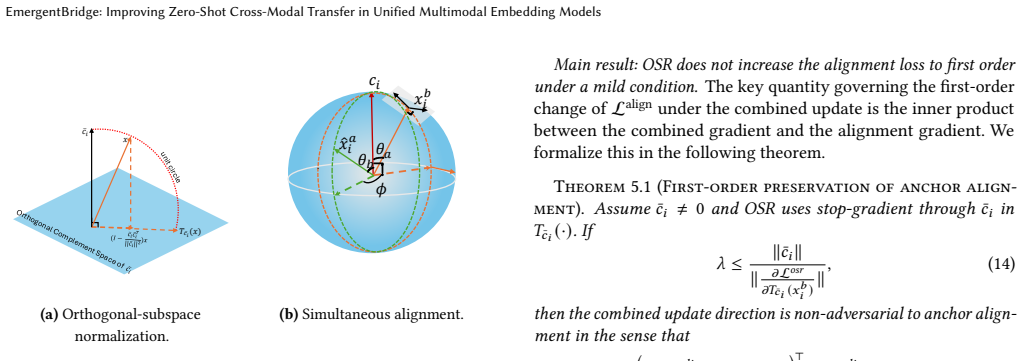
We define the orthogonal-subspace normalization operator T¯c_i(x) ≜ normalize((I − sg(¯c_i)sg(¯c_i)^T / ∥sg(¯c_i)∥² + ε) x) ... Losr aligns T¯c_i(x^b_i) with the proxy ˆx^a_i in the orthogonal complement of ¯c_i.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 via cohomology orthogonality) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 5.1 (First-order preservation of anchor alignment) ... λ ≤ ∥¯c_i∥ / ∥∂Losr/∂T¯c_i(x^b_i)∥ implies (∇L_align + λ∇Losr)^T ∇L_align ≥ 0.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Adria Recasens, Rosalia Schneider, Relja Arandjelović, Jason Ramapuram, Jeffrey De Fauw, Lucas Smaira, Sander Dieleman, and Andrew Zisserman. 2020. Self-supervised multimodal versatile networks.Advances in neural information processing systems33 (2020), 25–37
work page 2020
- [2]
-
[3]
Philip Bachman, R Devon Hjelm, and William Buchwalter. 2019. Learning representations by maximizing mutual information across views.Advances in neural information processing systems32 (2019)
work page 2019
-
[4]
Stephen Boyd and Lieven Vandenberghe. 2004.Convex optimization. Cambridge university press
work page 2004
-
[5]
Yuanzhouhan Cao, Zifeng Wu, and Chunhua Shen. 2018. Estimating Depth From Monocular Images as Classification Using Deep Fully Convolutional Residual Networks.IEEE Transactions on Circuits and Systems for Video Technology28, 11 (2018), 3174–3182. doi:10.1109/TCSVT.2017.2740321
-
[6]
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. 2020. Vg- gsound: A Large-Scale Audio-Visual Dataset.ICASSP 2020 - 2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP)(2020), 721–725. https://api.semanticscholar.org/CorpusID:216522760
work page 2020
-
[7]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev
-
[8]
InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Reproducible scaling laws for contrastive language-image learning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2818–2829
- [9]
-
[10]
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. 2019. Clotho: an Audio Captioning Dataset.ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)(2019), 736–740. https: //api.semanticscholar.org/CorpusID:204800739
work page 2019
-
[11]
Simon Du, Jason Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. 2019. Gradient Descent Finds Global Minima of Deep Neural Networks. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 1675–1685. https://proceedings.mlr.press/v97/d...
work page 2019
-
[12]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
-
[13]
InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Clap learning audio concepts from natural language supervision. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2023
- [14]
- [15]
-
[16]
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Au- dio Set: An ontology and human-labeled dataset for audio events. InProc. IEEE ICASSP 2017. New Orleans, LA
work page 2017
-
[17]
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. 2019. An Investigation into Neural Net Optimization via Hessian Eigenvalue Density. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 2232–2241. https://proceedings.mlr.press...
work page 2019
- [18]
-
[19]
Rohit Girdhar, Mannat Singh, Nikhila Ravi, Laurens Van Der Maaten, Armand Joulin, and Ishan Misra. 2022. Omnivore: A single model for many visual modal- ities. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16102–16112
work page 2022
-
[20]
Michael Gutmann and Aapo Hyvärinen. 2010. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. InProceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 297–304
work page 2010
- [21]
-
[22]
Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, Xudong Lu, Shuai Ren, Yafei Wen, Xiaoxin Chen, Xiangyu Yue, Hongsheng Li, and Yu Jiao Qiao. 2023. ImageBind- LLM: Multi-modality Instruction Tuning.ArXivabs/2309.03905 (2023). https: //api.semanticscholar.org/CorpusID:261582620
-
[23]
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. 2020. Mo- mentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9729–9738
work page 2020
-
[24]
Zhang, Shaoqing Ren, and Jian Sun
Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. 2015. Deep Residual Learning for Image Recognition.2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(2015), 770–778. https://api.semanticscholar.org/CorpusID: 206594692
work page 2015
-
[25]
Roger A Horn and Charles R Johnson. 2012.Matrix analysis. Cambridge univer- sity press
work page 2012
-
[26]
Xinyu Jia, Chuang Zhu, Minzhen Li, Wenqi Tang, and Wenli Zhou. 2021. LLVIP: A Visible-infrared Paired Dataset for Low-light Vision.2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)(2021), 3489–3497. https: //api.semanticscholar.org/CorpusID:237278539
work page 2021
-
[27]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. Au- dioCaps: Generating Captions for Audios in The Wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio ...
-
[28]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. 2013. Auto-Encoding Variational Bayes. CoRRabs/1312.6114 (2013). https://api.semanticscholar.org/CorpusID:216078090
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[29]
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. 2022. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning.Advances in Neural Information Processing Systems35 (2022), 17612–17625
work page 2022
-
[30]
Openshape: Scaling up 3d shape representation towards open-world understanding,
Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, H. Cai, Fatih Murat Porikli, and Hao Su. 2023. OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding.ArXivabs/2305.10764 (2023). https://api.semanticscholar.org/CorpusID:258762826
- [31]
-
[32]
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. 2022. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.Neurocomputing508 (2022), 293–304
work page 2022
-
[33]
Yuanhuiyi Lyu, Xu Zheng, Jiazhou Zhou, and Lin Wang. 2024. UniBind: LLM- Augmented Unified and Balanced Representation Space to Bind Them All. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 26752–26762
work page 2024
-
[34]
Charles H. Martin and Michael W. Mahoney. 2021. Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning.Journal of Machine Learning Research22, 165 (2021), 1–73. http: //jmlr.org/papers/v22/20-410.html
work page 2021
-
[35]
Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. 2020. End-to-end learning of visual representations from uncurated instructional videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9879–9889
work page 2020
-
[36]
Arsha Nagrani, Paul Hongsuck Seo, Bryan Seybold, Anja Hauth, Santiago Manén, Chen Sun, and Cordelia Schmid. 2022. Learning Audio-Video Modali- ties from Image Captions. InEuropean Conference on Computer Vision. https: //api.semanticscholar.org/CorpusID:247939759
work page 2022
-
[37]
Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. 2012. Indoor Segmentation and Support Inference from RGBD Images. InECCV
work page 2012
- [38]
-
[39]
Karol J. Piczak. 2015. ESC: Dataset for Environmental Sound Classification. Proceedings of the 23rd ACM international conference on Multimedia(2015). https: //api.semanticscholar.org/CorpusID:17567398
work page 2015
-
[40]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020 [cs.CV] https://arxiv.org/ abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
W. Rudin. 1976.Principles of Mathematical Analysis. McGraw-Hill. https: //books.google.com.sg/books?id=kwqzPAAACAAJ Trovato et al
work page 1976
-
[42]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexan- der C. Berg, and Li Fei-Fei. 2015. ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision (IJCV)115, 3 (2015), 211–252. doi:10.1007/s11263-015-0816-y
-
[43]
Shuran Song, Samuel P Lichtenberg, and Jianxiong Xiao. 2015. Sun rgb-d: A rgb-d scene understanding benchmark suite. InProceedings of the IEEE conference on computer vision and pattern recognition. 567–576
work page 2015
- [44]
-
[45]
Yonglong Tian, Dilip Krishnan, and Phillip Isola. 2020. Contrastive multiview coding. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16. Springer, 776–794
work page 2020
-
[46]
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chenliang Xu. 2018. Audio- Visual Event Localization in Unconstrained Videos. InECCV
work page 2018
-
[47]
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation Learning with Contrastive Predictive Coding.ArXivabs/1807.03748 (2018). https://api. semanticscholar.org/CorpusID:49670925
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Jianhua Wang, Chuanxia Zheng, Weihai Chen, and Xingming Wu. 2017. Learning aggregated features and optimizing model for semantic labeling.The Visual Computer33 (2017), 1587–1600
work page 2017
- [49]
-
[50]
Tongzhou Wang and Phillip Isola. 2020. Understanding Contrastive Represen- tation Learning through Alignment and Uniformity on the Hypersphere. In International Conference on Machine Learning. https://api.semanticscholar.org/ CorpusID:218718310
work page 2020
-
[51]
Zehan Wang, Ziang Zhang, Xize Cheng, Rongjie Huang, Luping Liu, Zhenhui Ye, Haifeng Huang, Yang Zhao, Tao Jin, Peng Gao, and Zhou Zhao. 2024. Free- Bind: Free Lunch in Unified Multimodal Space via Knowledge Fusion.ArXiv abs/2405.04883 (2024). https://api.semanticscholar.org/CorpusID:269626610
- [52]
-
[53]
Zehan Wang, Yang Zhao, Xize Cheng, Haifeng Huang, Jiageng Liu, Lilian H. Y. Tang, Lin Li, Yongqiang Wang, Aoxiong Yin, Ziang Zhang, and Zhou Zhao. 2023. Connecting Multi-modal Contrastive Representations.ArXivabs/2305.14381 (2023). https://api.semanticscholar.org/CorpusID:258866011
-
[54]
Ho-Hsiang Wu, Prem Seetharaman, Kundan Kumar, and Juan Pablo Bello. 2021. Wav2CLIP: Learning Robust Audio Representations from Clip.ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2021), 4563–4567. https://api.semanticscholar.org/CorpusID:239616434
work page 2021
-
[55]
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and S Yu Philip
-
[56]
In2023 IEEE International Conference on Big Data (BigData)
Multimodal large language models: A survey. In2023 IEEE International Conference on Big Data (BigData). IEEE, 2247–2256
-
[57]
Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov
Yusong Wu, K. Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2022. Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation.ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2022), 1–5. https://api.semanticscholar.org/CorpusID...
work page 2022
-
[58]
Peng Xu, Xiatian Zhu, and David A Clifton. 2023. Multimodal learning with transformers: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence45, 10 (2023), 12113–12132
work page 2023
-
[59]
Fengyu Yang, Chao Feng, Daniel Wang, Tianye Wang, Ziyao Zeng, Zhiyang Xu, Hyoungseob Park, Pengliang Ji, Hanbin Zhao, Yuanning Li, and Alex Wong
-
[60]
https://api.semanticscholar.org/CorpusID: 271310533
NeuroBind: Towards Unified Multimodal Representations for Neural Signals.ArXivabs/2407.14020 (2024). https://api.semanticscholar.org/CorpusID: 271310533
- [61]
-
[62]
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, HongFa Wang, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, Wancai Zhang, Zhifeng Li, Wei Liu, and Li Yuan. 2024. LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment. arXiv:2310.01852 [cs.CV] https://arxiv.org/abs/2310.01852 A Implementation Details T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.