Recognition: unknown
LaDA-Band: Language Diffusion Models for Vocal-to-Accompaniment Generation
Pith reviewed 2026-05-10 16:03 UTC · model grok-4.3
The pith
Discrete masked diffusion generates vocal accompaniments that preserve acoustic detail while maintaining long-range coherence across full songs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LaDA-Band formulates vocal-to-accompaniment generation as discrete masked diffusion, a global non-autoregressive denoising process on discrete audio codec tokens that supplies full-sequence bidirectional context. This core formulation is extended with a dual-track prefix-conditioning architecture, an auxiliary replaced-token detection objective for weakly anchored regions, and a two-stage progressive curriculum that scales the diffusion process to full-song lengths. Experiments on academic and real-world benchmarks indicate consistent gains in acoustic authenticity, global coherence, and dynamic orchestration compared with prior continuous-latent and autoregressive baselines.
What carries the argument
Discrete Masked Diffusion: a global, non-autoregressive denoising formulation on discrete audio codec tokens that supplies bidirectional context across the full sequence.
If this is right
- The method improves acoustic authenticity, global coherence, and dynamic orchestration over existing baselines on both academic and real-world data.
- Performance remains strong even when no auxiliary reference audio is supplied.
- The two-stage curriculum enables scaling to full-song durations without proportional growth in artifacts.
- Dual-track conditioning and replaced-token detection improve temporal synchronization and anchoring in accompaniment regions.
Where Pith is reading between the lines
- The same bidirectional discrete diffusion structure could be tested on related tasks such as instrumental arrangement from melody or multi-instrument generation.
- If the scaling holds, the approach may reduce dependence on autoregressive models that accumulate errors over long sequences.
- Integration into production tools could become feasible for real-time or iterative vocal arrangement once inference speed is addressed.
- Genre-specific or multilingual extensions would be natural next measurements to check whether the trilemma solution generalizes beyond the reported benchmarks.
Load-bearing premise
The assumption that combining masked diffusion on discrete tokens with prefix conditioning and curriculum training will scale to complete songs without introducing coherence failures or artifacts that standard metrics overlook.
What would settle it
A controlled listening test or long-range structural metric on full-length generated tracks in which listeners or automated scores rate the outputs as less coherent or natural than strong autoregressive baselines.
Figures







read the original abstract
Vocal-to-accompaniment (V2A) generation, which aims to transform a raw vocal recording into a fully arranged accompaniment, inherently requires jointly addressing an accompaniment trilemma: preserving acoustic authenticity, maintaining global coherence with the vocal track, and producing dynamic orchestration across a full song. Existing open-source approaches typically make compromises among these goals. Continuous-latent generation models can capture long musical spans but often struggle to preserve fine-grained acoustic detail. In contrast, discrete autoregressive models retain local fidelity but suffer from unidirectional generation and error accumulation in extended contexts. We present LaDA-Band, an end-to-end framework that introduces Discrete Masked Diffusion to the V2A task. Our approach formulates V2A generation as Discrete Masked Diffusion, i.e., a global, non-autoregressive denoising formulation that combines the representational advantages of discrete audio codec tokens with full-sequence bidirectional context modeling. This design improves long-range structural consistency and temporal synchronization while preserving crisp acoustic details. Built on this formulation, LaDA-Band further introduces a dual-track prefix-conditioning architecture, an auxiliary replaced-token detection objective for weakly anchored accompaniment regions, and a two-stage progressive curriculum to scale Discrete Masked Diffusion to full-song vocal-to-accompaniment generation. Extensive experiments on both academic and real-world benchmarks show that LaDA-Band consistently improves acoustic authenticity, global coherence, and dynamic orchestration over existing baselines, while maintaining strong performance even without auxiliary reference audio. Codes and audio samples are available at https://github.com/Duoluoluos/TME-LaDA-Band .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LaDA-Band, a framework that formulates vocal-to-accompaniment (V2A) generation as discrete masked diffusion over audio codec tokens. It augments this with a dual-track prefix-conditioning architecture, an auxiliary replaced-token detection objective, and a two-stage progressive curriculum to scale to full-song lengths. The central claim is that this combination resolves the accompaniment trilemma—acoustic authenticity, global coherence with the vocal, and dynamic orchestration—more effectively than prior continuous-latent or autoregressive baselines, with strong results even in the absence of reference audio.
Significance. If the reported gains hold under rigorous scrutiny, the work would constitute a useful step forward for non-autoregressive music generation: it shows how discrete-token bidirectional diffusion can be stabilized at song scale without sacrificing local fidelity. The public release of code and audio samples is a clear strength that supports reproducibility and community follow-up.
major comments (2)
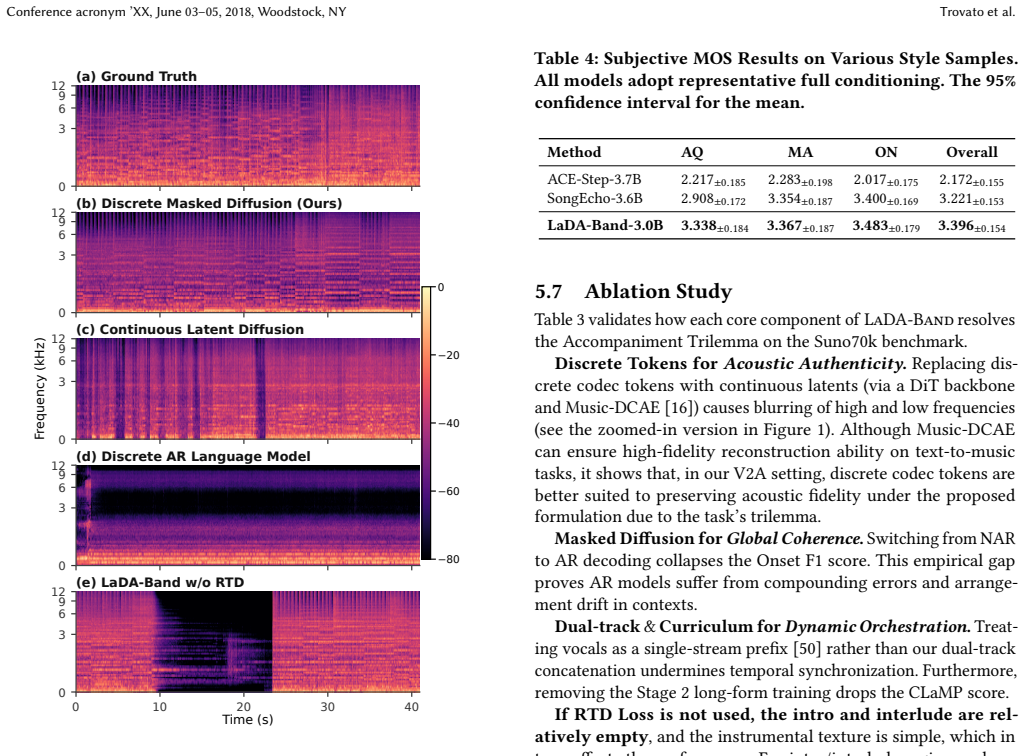
- [§5] §5 (Experiments): The manuscript asserts 'consistent improvements' across acoustic authenticity, global coherence, and dynamic orchestration, yet provides neither tabulated metric values (e.g., FAD, CLAP, or coherence scores), error bars, nor explicit baseline configurations. Without these numbers it is impossible to judge effect size or rule out post-hoc metric selection, which is load-bearing for the empirical claim.
- [§5.2] §5.2 and §4.3 (Evaluation protocol and two-stage curriculum): It is not stated whether objective metrics and listening tests are computed on complete multi-minute songs or on short clips; no diagnostic analysis of long-range failure modes (harmonic drift, loss of dynamic contrast, or desynchronization) is reported. Because the headline contribution is precisely the ability to scale discrete masked diffusion to full songs without new artifacts, this omission directly weakens the scaling argument.
minor comments (3)
- [Abstract] Abstract: The phrase 'extensive experiments on both academic and real-world benchmarks' would be more informative if it named the datasets and at least one headline metric delta.
- [§4.1] §4.1: The notation for the discrete token vocabulary and masking schedule is introduced inline; a compact symbol table would improve readability.
- [Figure 3] Figure 3 (architecture diagram): The flow from dual-track prefix to replaced-token detection head is visually crowded; separating the conditioning and auxiliary-loss paths would clarify the design.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The feedback highlights important areas for improving the clarity and rigor of our experimental reporting. We will revise the manuscript to incorporate the requested details on metrics, baselines, evaluation protocols, and diagnostics. Point-by-point responses follow.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The manuscript asserts 'consistent improvements' across acoustic authenticity, global coherence, and dynamic orchestration, yet provides neither tabulated metric values (e.g., FAD, CLAP, or coherence scores), error bars, nor explicit baseline configurations. Without these numbers it is impossible to judge effect size or rule out post-hoc metric selection, which is load-bearing for the empirical claim.
Authors: We agree that the main text currently summarizes results qualitatively without full tabulated values, error bars, or detailed baseline configurations. This limits the ability to assess effect sizes and reproducibility. In the revised version, we will add a main-text table reporting all objective metrics (FAD, CLAP, coherence scores, etc.) with means, standard deviations from multiple runs, and explicit baseline setups including hyperparameters and training details. All evaluated metrics will be reported to avoid any appearance of post-hoc selection. revision: yes
-
Referee: [§5.2] §5.2 and §4.3 (Evaluation protocol and two-stage curriculum): It is not stated whether objective metrics and listening tests are computed on complete multi-minute songs or on short clips; no diagnostic analysis of long-range failure modes (harmonic drift, loss of dynamic contrast, or desynchronization) is reported. Because the headline contribution is precisely the ability to scale discrete masked diffusion to full songs without new artifacts, this omission directly weakens the scaling argument.
Authors: We acknowledge that the manuscript does not explicitly state the song lengths used for evaluation nor provide diagnostic analysis of long-range issues. All reported metrics and listening tests were performed on complete multi-minute songs (average ~3-4 minutes) drawn from the full-song benchmarks, consistent with the two-stage curriculum's design for scaling. In revision, we will add explicit statements on song durations, plus an appendix with diagnostic metrics tracking harmonic stability, dynamic contrast, and synchronization over time to directly support the scaling claims. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a new end-to-end framework for vocal-to-accompaniment generation by formulating the task as Discrete Masked Diffusion combined with dual-track prefix conditioning, replaced-token detection, and a two-stage curriculum. No equations, derivations, or first-principles results are presented that reduce any claimed prediction or improvement to fitted parameters, self-definitions, or self-citation chains by construction. The performance gains are asserted via experimental comparisons on benchmarks rather than by algebraic equivalence to inputs, rendering the approach self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
- [4]
-
[5]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, JianZhao JianZhao, Kai Yu, and Xie Chen. 2025. F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6255–6271
2025
- [6]
-
[7]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. 2024. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. Simple and controllable music generation. Advances in neural information processing systems36 (2023), 47704–47720
2023
-
[9]
Yunus Demirag, Danni Liu, and Jan Niehues. 2024. Benchmarking diffusion models for machine translation. InProceedings of the 18th Conference of the Euro- pean Chapter of the Association for Computational Linguistics: Student Research Workshop. 313–324
2024
-
[10]
Duc Anh Do, Luu Anh Tuan, Wray Buntine, et al . 2025. Discrete diffusion language model for efficient text summarization. InFindings of the Association for Computational Linguistics: NAACL 2025. 6278–6290
2025
-
[11]
Chris Donahue, Antoine Caillon, Adam Roberts, Ethan Manilow, Philippe Esling, Andrea Agostinelli, Mauro Verzetti, Ian Simon, Olivier Pietquin, Neil Zeghidour, et al. 2023. SingSong: Generating musical accompaniments from singing. In International Conference on Machine Learning ICML 2023
2023
-
[12]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
-
[13]
InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Clap learning audio concepts from natural language supervision. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
- [14]
- [15]
-
[16]
Junmin Gong, Yulin Song, Wenxiao Zhao, Sen Wang, Shengyuan Xu, and Jing Guo
-
[17]
arXiv preprint arXiv:2602.00744(2026)
ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation. arXiv preprint arXiv:2602.00744(2026)
- [18]
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Azalea Gui, Hannes Gamper, Sebastian Braun, and Dimitra Emmanouilidou. 2024. Adapting frechet audio distance for generative music evaluation. InICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1331–1335
2024
-
[21]
Chunbo Hao, Ruibin Yuan, Jixun Yao, Qixin Deng, Xinyi Bai, Wei Xue, and Lei Xie. 2025. Songformer: Scaling music structure analysis with heterogeneous supervision.arXiv preprint arXiv:2510.02797(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Zhiqing Hong, Rongjie Huang, Xize Cheng, Yongqi Wang, Ruiqi Li, Fuming You, Zhou Zhao, and Zhimeng Zhang. 2024. Text-to-Song: Towards Controllable Music Generation Incorporating Vocal and Accompaniment. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Sr...
-
[24]
Siyuan Hou, Shansong Liu, Ruibin Yuan, Wei Xue, Ying Shan, Mangsuo Zhao, and Chao Zhang. 2025. Editing music with melody and text: Using controlnet for diffusion transformer. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
- [25]
- [26]
- [27]
-
[28]
Shuyu Li, Shulei Ji, Zihao Wang, Songruoyao Wu, Jiaxing Yu, and Kejun Zhang
- [29]
- [30]
-
[31]
Zicheng Li, Shoushan Li, and Guodong Zhou. 2022. Pre-trained token-replaced detection model as few-shot learner. InProceedings of the 29th International Conference on Computational Linguistics. 3274–3284. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
2022
- [32]
- [33]
-
[34]
Zihan Liu, Shuangrui Ding, Zhixiong Zhang, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. 2025. SongGen: A Single Stage Auto-regressive Transformer for Text-to-Song Generation. InInternational Con- ference on Machine Learning. PMLR, 38351–38364
2025
-
[35]
Yi Luo and Jianwei Yu. 2023. Music source separation with band-split RNN. IEEE/ACM Transactions on Audio, Speech, and Language Processing31 (2023), 1893–1901
2023
-
[36]
Brian McFee, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, Oriol Nieto, et al. 2015. librosa: Audio and music signal analysis in python.SciPy2015, 18-24 (2015), 7
2015
-
[37]
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. [n. d.]. Large Language Diffusion Models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
- [38]
-
[39]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[40]
Litu Rout, Constantine Caramanis, and Sanjay Shakkottai. [n. d.]. Anchored Diffusion Language Model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[41]
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and Volodymyr Kuleshov. 2024. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems37 (2024), 130136–130184
2024
-
[42]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, et al . 2026. Qwen3-ASR Technical Report.arXiv preprint arXiv:2601.21337(2026)
work page internal anchor Pith review arXiv 2026
-
[43]
Giorgio Strano, Chiara Ballanti, Donato Crisostomi, Michele Mancusi, Luca Cosmo, and Emanuele Rodolà. 2025. STAGE: Stemmed Accompaniment Genera- tion through Prefix-Based Conditioning. InIsmir 2025 Hybrid Conference
2025
-
[44]
PM Suhailudheen and Ms Sheena Km. 2025. Suno AI: Advancing AI-Generated Music with Deep Learning.Authorea Preprints(2025)
2025
- [45]
-
[46]
Fang-Duo Tsai, Yi-An Lai, Fei-Yueh Chen, Hsueh-Wei Fu, Li Chai, Wei-Jaw Lee, Hao-Chung Cheng, and Yi-Hsuan Yang. 2026. MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline.arXiv preprint arXiv:2602.22029(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Fang-Duo Tsai, Shih-Lun Wu, Weijaw Lee, Sheng-Ping Yang, Bo-Rui Chen, Hao- Chung Cheng, and Yi-Hsuan Yang. 2025. MuseControlLite: Multifunctional Music Generation with Lightweight Conditioners. InInternational Conference on Machine Learning. PMLR, 60266–60279
2025
-
[48]
Qi Wang, Shubing Zhang, and Li Zhou. 2023. Emotion-guided music accompani- ment generation based on variational autoencoder. In2023 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
2023
-
[49]
Zihao Wang, Kejun Zhang, Yuxing Wang, Chen Zhang, Qihao Liang, Pengfei Yu, Yongsheng Feng, Wenbo Liu, Yikai Wang, Yuntao Bao, et al. 2022. Songdriver: Real-time music accompaniment generation without logical latency nor exposure bias. InProceedings of the 30th ACM International Conference on Multimedia. 1057– 1067
2022
-
[50]
Shangda Wu, Guo Zhancheng, Ruibin Yuan, Junyan Jiang, Seungheon Doh, Gus Xia, Juhan Nam, Xiaobing Li, Feng Yu, and Maosong Sun. 2025. Clamp 3: Universal music information retrieval across unaligned modalities and unseen languages. InFindings of the Association for Computational Linguistics: ACL 2025. 2605–2625
2025
-
[51]
Yaoxun Xu, Hangting Chen, Jianwei Yu, Wei Tan, Shun Lei, Zhiwei Lin, Rongzhi Gu, and Zhiyong Wu. 2025. MuCodec: Ultra Low-Bitrate Music Codec for Music Generation. InProceedings of the 33rd ACM International Conference on Multime- dia. 689–698
2025
- [52]
-
[53]
Chenyu Yang, Shuai Wang, Hangting Chen, Jianwei Yu, Wei Tan, Rongzhi Gu, Yaoxun Xu, Yizhi Zhou, Haina Zhu, and Haizhou Li. 2025. Songeditor: Adapting zero-shot song generation language model as a multi-task editor. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25597–25605
2025
- [54]
- [55]
- [56]
- [57]
- [58]
- [59]
- [60]
-
[61]
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. 2025. Llada 1.5: Variance- reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223(2025). LaDA-Band: Language Diffusion Models for Vocal-to-Accompaniment Generation Conference acronym ’X...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.