Recognition: no theorem link
MIDI-Informed Singing Accompaniment Generation in a Compositional Song Pipeline
Pith reviewed 2026-05-15 20:15 UTC · model grok-4.3
The pith
MIDI timing, chords and structure planning let score-to-song systems stay coherent across long vocal and silent sections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
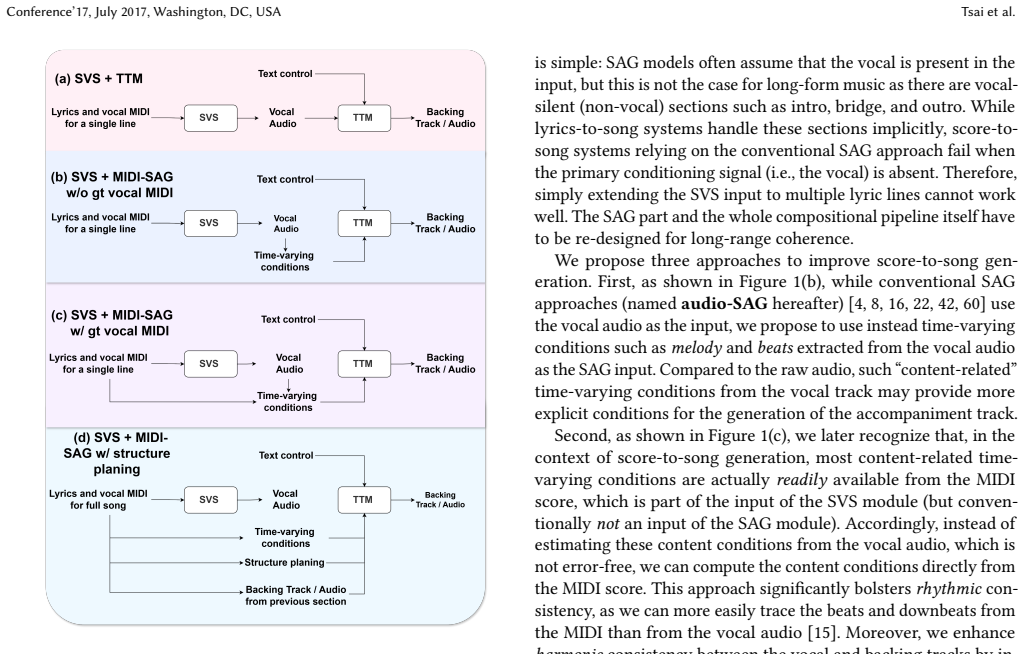
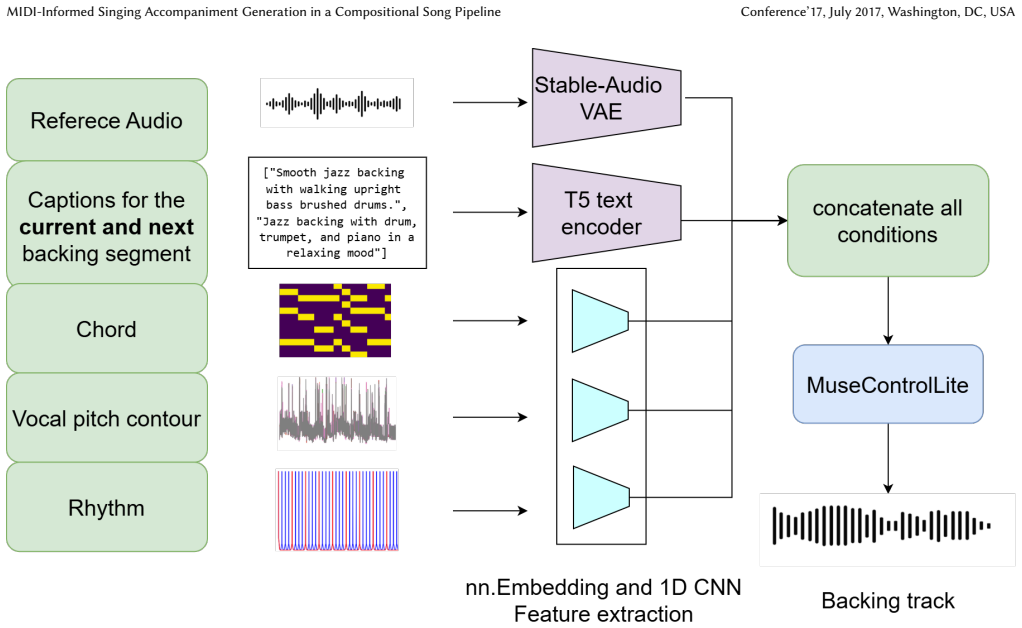
MIDI-informed singing accompaniment generation (MIDI-SAG) uses symbolic timing and chord information extracted from the vocal MIDI together with structure planning that defines temporal boundaries and semantic labels, producing consistent accompaniment across vocal and non-vocal sections in long-form songs while requiring only data-efficient fine-tuning of existing pre-trained modules.
What carries the argument
Structure planning module that supplies temporal boundaries and semantic labels, guided by MIDI-derived symbolic timing and chord information as a stable musical roadmap.
If this is right
- Professional songwriters can retain control over core melody while generating full-length accompaniments.
- The same pipeline supports both score-to-song and lyrics-to-song tasks with minimal additional training.
- Single-GPU training becomes feasible by composing existing pre-trained modules rather than training from scratch.
- Long-form generation no longer fails primarily at vocal-silent transitions such as intros and bridges.
Where Pith is reading between the lines
- The method could be extended by feeding the same MIDI roadmap into separate stem generators for drums or bass to keep the whole arrangement aligned.
- Structure planning might later accept higher-level user instructions such as "build tension here" and translate them into boundary and label sequences.
- Because the roadmap is symbolic, the system could accept live MIDI input for real-time accompaniment adjustments during composition.
Load-bearing premise
Symbolic timing and chord data from the vocal MIDI plus structure planning already give enough information to keep long-form accompaniment coherent without further audio-level modeling.
What would settle it
Objective coherence metrics or listening tests on generated intros and bridges that drop sharply when the structure-planning labels are removed while MIDI timing and chords remain.
Figures



read the original abstract
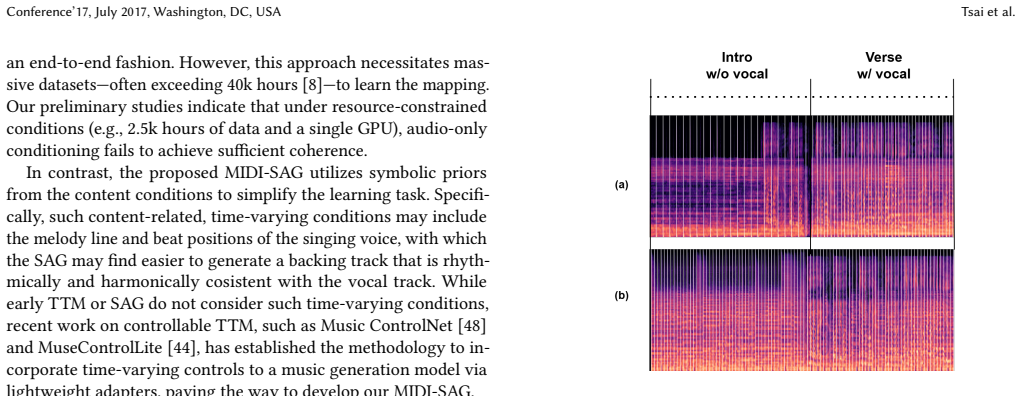
While end-to-end lyrics-to-song models offer convenience for casual users, professional songwriters require score-to-song systems that allow them to retain authorship over the core melody. However, existing score-to-song methods are limited to short-form snippets and fail to maintain coherence in long-form generation, particularly during vocal-silent sections like intros and bridges. To address this long-form bottleneck, we propose MIDI-informed singing accompaniment generation (MIDI-SAG). Unlike conventional audio-only models, MIDI-SAG utilizes symbolic timing and chord information derived from the vocal MIDI to provide a stable musical roadmap. By incorporating structure planning, which defines temporal boundaries and semantic labels, our framework facilitates consistent generation across both vocal and non-vocal sections. We demonstrate the feasibility of this compositional pipeline by leveraging specialized pre-trained modules, enabling data-efficient training on a single GPU. Our experiments show the potential of this approach for both professional score-to-song and general lyrics-to-song tasks. While an early exploration, MIDI-SAG suggests a promising direction for structured, long-form music synthesis. Audio demos are available, and the code will be open-sourced at https://composerflow.github.io/web_revealed/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MIDI-SAG, a compositional pipeline for MIDI-informed singing accompaniment generation. It derives symbolic timing and chord information from vocal MIDI to provide a stable roadmap, augments this with structure planning (temporal boundaries and semantic labels) to ensure coherence across vocal and non-vocal sections in long-form outputs, and composes existing pre-trained modules to enable data-efficient single-GPU training. The work is framed as an early feasibility demonstration for both score-to-song and lyrics-to-song tasks, with audio demos available and code to be released.
Significance. If the central hypothesis holds, the approach could meaningfully advance long-form music synthesis by showing that symbolic conditioning plus structure planning can substitute for full audio-level modeling in maintaining coherence, particularly in vocal-silent regions. The compositional reuse of pre-trained modules and commitment to open-sourcing are concrete strengths that lower barriers for follow-up work. However, absent any quantitative validation, the immediate significance remains prospective rather than demonstrated.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the manuscript asserts that MIDI-derived timing/chords combined with structure planning 'facilitates consistent generation across both vocal and non-vocal sections' and that 'experiments show the potential,' yet supplies no quantitative metrics, ablation results, listening-test scores, or error analysis. This leaves the load-bearing coherence claim unsupported by visible evidence.
- [Method] Method description: the weakest assumption—that symbolic MIDI information plus structure planning supplies a sufficiently stable roadmap without additional audio-level modeling—is presented without discussion of failure modes, edge cases (e.g., complex polyphony or ambiguous chord progressions), or direct comparison to audio-only baselines.
minor comments (2)
- The manuscript would benefit from an explicit pipeline diagram showing how the pre-trained modules are composed and how structure labels are injected at inference time.
- Clarify the exact pre-trained modules employed (model names, training data, fine-tuning details) so that the 'data-efficient single-GPU' claim can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive and balanced review. We appreciate the recognition of MIDI-SAG as an early feasibility demonstration that reuses pre-trained modules for data-efficient long-form generation. We address each major comment below and will revise the manuscript to strengthen the presentation of evidence and limitations while preserving the core contribution as an exploratory pipeline.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the manuscript asserts that MIDI-derived timing/chords combined with structure planning 'facilitates consistent generation across both vocal and non-vocal sections' and that 'experiments show the potential,' yet supplies no quantitative metrics, ablation results, listening-test scores, or error analysis. This leaves the load-bearing coherence claim unsupported by visible evidence.
Authors: We agree that the current version relies on qualitative audio demonstrations rather than quantitative metrics or ablations, which limits the strength of the coherence claims. As an early feasibility study, the experiments were designed to illustrate the pipeline's behavior through examples rather than statistical validation. In revision we will (1) revise the abstract to explicitly frame the work as a qualitative demonstration, (2) expand the Experiments section with a systematic qualitative analysis of the generated examples, including observed failure cases and how structure planning mitigates them, and (3) add a short discussion of planned listening-test protocols for future work. These changes will make the evidential basis clearer without overstating the current results. revision: partial
-
Referee: [Method] Method description: the weakest assumption—that symbolic MIDI information plus structure planning supplies a sufficiently stable roadmap without additional audio-level modeling—is presented without discussion of failure modes, edge cases (e.g., complex polyphony or ambiguous chord progressions), or direct comparison to audio-only baselines.
Authors: We accept that the Method section would be strengthened by explicit discussion of the central assumption and its limitations. In the revised manuscript we will add a dedicated Limitations subsection that (a) enumerates edge cases such as dense polyphony where MIDI chord extraction may become ambiguous and (b) describes observed failure modes from our demo set (e.g., drift in long vocal-silent regions when structure labels are coarse). We will also include a brief qualitative comparison to audio-only conditioning, grounded in the same demo examples, to illustrate why symbolic timing and chords appear to provide a more stable scaffold. These additions will clarify the scope of the current claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a compositional pipeline that assembles existing pre-trained modules for MIDI-informed accompaniment generation and structure planning. No equations, derivations, fitted parameters, or uniqueness theorems are presented. The central claim is explicitly framed as an early feasibility demonstration rather than a closed-form result derived from inputs. No self-citation chains or ansatzes reduce outputs to inputs by construction. This is a standard non-circular engineering paper whose load-bearing assumption (symbolic conditioning suffices) is offered as a hypothesis for community testing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained specialized modules can be leveraged for data-efficient single-GPU training of the full pipeline
Forward citations
Cited by 1 Pith paper
-
LaDA-Band: Language Diffusion Models for Vocal-to-Accompaniment Generation
LaDA-Band applies discrete masked diffusion with dual-track conditioning and progressive training to generate vocal-to-accompaniment tracks that improve acoustic authenticity, global coherence, and dynamic orchestrati...
Reference graph
Works this paper leans on
-
[1]
Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, An- toine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. 2023. MusicLM: Generating music from text.arXiv preprint arXiv:2301.11325 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Li Chai and Donglin Wang. 2025. CSL-L2M: Controllable Song-Level Lyric- to-Melody Generation Based on Conditional Transformer with Fine-Grained Lyric and Musical Controls. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23541–23549
work page 2025
- [3]
- [4]
-
[5]
C.-H. Chuan and E. Chew. 2007. A Hybrid System for Automatic Generation of Style-Specific Accompaniment. InProc. Int. Joint Workshop on Computational Creativity
work page 2007
-
[6]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2024. Simple and controllable music generation. Advances in Neural Information Processing Systems36 (2024)
work page 2024
-
[7]
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. 2020. Jukebox: A Generative Model for Music.arXiv preprint arXiv:2005.00341(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [8]
-
[9]
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. 2025. Stable Audio Open. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
work page 2025
- [10]
-
[11]
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao-Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, et al. 2025. Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models.arXiv preprint arXiv:2507.08128(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
Maarten Grachten and Javier Nistal. 2025. Accompaniment Prompt Adherence: A measure for evaluating music accompaniment systems. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2025
- [14]
- [15]
-
[16]
Zhiqing Hong, Rongjie Huang, Xize Cheng, Yongqi Wang, Ruiqi Li, Fuming You, Zhou Zhao, and Zhimeng Zhang. 2024. Text-to-Song: Towards Controllable Music Generation Incorporating Vocals and Accompaniment. InAnnual Meeting of the Association for Computational Linguistics (ACL)
work page 2024
-
[17]
Siyuan Hou, Shansong Liu, Ruibin Yuan, Wei Xue, Ying Shan, Mangsuo Zhao, and Chao Zhang. 2025. Editing music with melody and text: Using ControlNet for diffusion Transformer. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
work page 2025
- [18]
-
[19]
Taejun Kim and Juhan Nam. 2023. All-in-one metrical and functional structure analysis with neighborhood attentions on demixed audio. InIEEE Workshop on Applications of Signal Processing to Audio and Acoustics (W ASPAA)
work page 2023
- [20]
- [21]
- [22]
-
[23]
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D Plumbley. 2024. Audioldm 2: Learning holistic audio generation with self-supervised pretraining.IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 2871–2883
work page 2024
-
[24]
Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, and Zhou Zhao. 2022. DiffSinger: Singing voice synthesis via shallow diffusion mechanism. InProceedings of the AAAI conference on artificial intelligence, Vol. 36. 11020–11028
work page 2022
-
[25]
Renhang Liu, Chia-Yu Hung, Navonil Majumder, Taylor Gautreaux, Amir Ali Bagherzadeh, Chuan Li, Dorien Herremans, and Soujanya Poria. 2025. JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment.arXiv preprint arXiv:2507.20880(2025). Conference’17, July 2017, Washington, DC, USA Tsai et al
- [26]
- [27]
-
[28]
Music Information Retrieval Evaluation eXchange (MIREX). 2018. MIREX 2018: Automatic Lyrics-to-Audio Alignment. https://music-ir.org/mirex/wiki/2018: Automatic_Lyrics-to-Audio_Alignment. Accessed: 2025-11-21
work page 2018
- [29]
-
[30]
Xinlei Niu, Kin Wai Cheuk, Jing Zhang, Naoki Murata, Chieh-Hsin Lai, Michele Mancusi, Woosung Choi, Giorgio Fabbro, Wei-Hsiang Liao, Charles Patrick Mar- tin, and Yuki Mitsufuji. 2026. SteerMusic: Enhanced Musical Consistency for Zero-shot Text-guided and Personalized Music Editing. InProceedings of the AAAI Conference on Artificial Intelligence
work page 2026
-
[31]
Zachary Novack, Ge Zhu, Jonah Casebeer, Julian McAuley, Taylor Berg- Kirkpatrick, and Nicholas J. Bryan. 2025. Presto! Distilling Steps and Layers for Accelerating Music Generation. InInternational Conference on Learning Represen- tations (ICLR)
work page 2025
-
[32]
2023.SOME: Singing-Oriented MIDI Extractor
openvpi. 2023.SOME: Singing-Oriented MIDI Extractor. https://github.com/ openvpi/SOME/releases/tag/v0.0.1 Git commit 02936ec
work page 2023
-
[33]
Jonggwon Park, Kyoyun Choi, Sungwook Jeon, Dokyun Kim, and Jonghun Park
-
[34]
InInterna- tional Society for Music Information Retrieval Conference
A Bi-Directional Transformer for Musical Chord Recognition. InInterna- tional Society for Music Information Retrieval Conference. 620–627
-
[35]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv:2212.04356 [eess.AS]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Zafar Rafii, Antoine Liutkus, Fabian-Robert Stöter, Stylianos Ioannis Mimilakis, and Rachel Bittner. 2017. The MUSDB18 corpus for music separation. (2017)
work page 2017
- [37]
-
[38]
Hendrik Schreiber and Meinard Müller. 2019. Musical Tempo and Key Estimation using Convolutional Neural Networks with Directional Filters. InProceedings of the Sound and Music Computing Conference (SMC). 47–54
work page 2019
-
[39]
Silero Team. 2024. Silero VAD: pre-trained enterprise-grade Voice Activity De- tector (VAD), Number Detector and Language Classifier. https://github.com/ snakers4/silero-vad. Accessed: 2026-01-27
work page 2024
-
[40]
Inc. Suno. 2025. Introducing v4.5. https://suno.com/blog/introducing-v4-5. Ac- cessed: 2025-09-24
work page 2025
-
[41]
David Temperley. 2007. The melodic-harmonic ‘divorce’ in rock.Popular Music 26, 2 (2007), 323–342
work page 2007
-
[42]
Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, Carleigh Wood, Ann Lee, and Wei-Ning Hsu. 2025. Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound. arXiv:2502.05139 [cs.SD] https://arxiv.org/abs/2502.05139
- [43]
- [44]
-
[45]
Fang-Duo Tsai, Shih-Lun Wu, Weijaw Lee, Sheng-Ping Yang, Bo-Rui Chen, Hao- Chung Cheng, and Yi-Hsuan Yang. 2025. MuseControlLite: Multifunctional Music Generation with Lightweight Conditioners. InInternational Conference on Machine Learning
work page 2025
-
[46]
Fang-Duo Tsai and Yi-Hsuan Yang. 2024. Demonstrating Singing accompaniment capabilities for MuseControlLite. InAI for Music Workshop
work page 2024
- [47]
- [48]
-
[49]
Shih-Lun Wu, Chris Donahue, Shinji Watanabe, and Nicholas J Bryan. 2024. Music controlnet: Multiple time-varying controls for music generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 2692–2703
work page 2024
-
[50]
Shih-Lun Wu and Yi-Hsuan Yang. 2023. MuseMorphose: Full-song and fine- grained piano music style transfer with one transformer VAE.IEEE/ACM Trans- actions on Audio, Speech, and Language Processing31 (2023), 1953–1967
work page 2023
- [51]
-
[52]
Ryuichi Yamamoto, Eunwoo Song, and Jae-Min Kim. 2020. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
work page 2020
-
[53]
Chenyu Yang, Hangting Chen, Shuai Wang, Haina Zhu, and Haizhou Li. 2025. TVC-MusicGen: Time-Varying Structure Control for Background Music Genera- tion via Self-Supervised Training. InINTERSPEECH
work page 2025
- [54]
- [55]
- [56]
- [57]
- [58]
-
[59]
Chong Zhang, Yukun Ma, Qian Chen, Wen Wang, Shengkui Zhao, Zexu Pan, Hao Wang, Chongjia Ni, Trung Hieu Nguyen, Kun Zhou, Yidi Jiang, Chaohong Tan, Zhifu Gao, Zhihao Du, and Bin Ma. 2025. InspireMusic: Integrating Super Resolu- tion and Large Language Model for High-Fidelity Long-Form Music Generation. arXiv preprint arXiv:2503.00084(2025)
- [60]
- [61]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.