Recognition: unknown
Lightweight Low-Light Image Enhancement via Distribution-Normalizing Preprocessing and Depthwise U-Net
Pith reviewed 2026-05-10 16:17 UTC · model grok-4.3
The pith
A frozen preprocessing step normalizes low-light distributions so a compact depthwise U-Net can handle only residual color correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that frozen algorithm-based preprocessing which provides complementary brightness-corrected views normalizes the input distribution, enabling a compact U-Net constructed solely from depthwise-separable convolutions to focus on residual color correction and thereby deliver competitive low-light enhancement performance with substantially reduced parameter counts compared with existing approaches.
What carries the argument
Distribution-normalizing preprocessing that supplies complementary brightness-corrected views to a depthwise-separable U-Net for residual color correction.
If this is right
- The two-stage design achieves perceptual quality competitive with larger networks while using markedly fewer trainable parameters.
- The method placed fourth in the CVPR 2026 NTIRE Efficient Low-Light Image Enhancement Challenge.
- Extended benchmarks and ablations confirm effectiveness across multiple low-light datasets and design choices.
- The separation of fixed normalization from learned correction supports efficient deployment on edge devices.
Where Pith is reading between the lines
- The same preprocessing-plus-residual-network pattern could transfer to other restoration tasks such as denoising or deblurring when a suitable fixed normalizer exists.
- Reducing the learning burden to residuals may allow training with smaller datasets than end-to-end models require.
- On mobile or embedded platforms the lower parameter count would enable real-time low-light enhancement without dedicated accelerators.
Load-bearing premise
The selected frozen preprocessing algorithm must reliably generate complementary brightness-corrected views whose distribution is normalized enough for the depthwise U-Net to learn only residual corrections on varied low-light scenes.
What would settle it
Run the complete pipeline on a new low-light dataset where the preprocessing step produces poorly normalized or non-complementary views; if the depthwise U-Net then requires significantly more parameters or loses quality relative to heavier baselines, the claim does not hold.
Figures



read the original abstract
We present a lightweight two-stage framework for low-light image enhancement (LLIE) that achieves competitive perceptual quality with significantly fewer parameters than existing methods. Our approach combines frozen algorithm-based preprocessing with a compact U-Net built entirely from depthwise-separable convolutions. The preprocessing normalizes the input distribution by providing complementary brightness-corrected views, enabling the trainable network to focus on residual color correction. Our method achieved 4th place in the CVPR 2026 NTIRE Efficient Low-Light Image Enhancement Challenge. We further provide extended benchmarks and ablations to demonstrate the general effectiveness of our methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a lightweight two-stage framework for low-light image enhancement (LLIE) that pairs a frozen algorithm-based preprocessing step—intended to normalize the input distribution by supplying complementary brightness-corrected views—with a compact U-Net built exclusively from depthwise-separable convolutions that performs only residual color correction. The method is reported to have placed fourth in the CVPR 2026 NTIRE Efficient Low-Light Image Enhancement Challenge; extended benchmarks and ablations are supplied to demonstrate general effectiveness and parameter efficiency.
Significance. If the central assumption holds, the work offers a practically relevant route to efficient LLIE suitable for resource-constrained settings. The external validation via challenge placement and the provision of ablations constitute concrete strengths; the separation of normalization (frozen) from residual learning (trainable) is a clean design choice that could reduce model capacity requirements.
major comments (2)
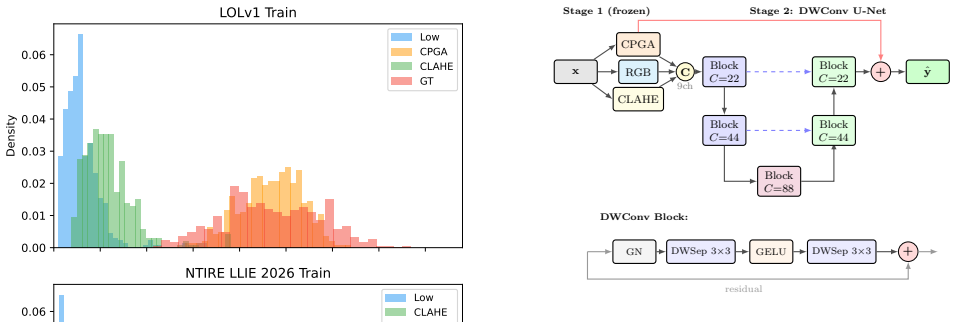
- [§3] §3 (Method): The claim that the frozen preprocessing 'normalizes the input distribution' sufficiently for the depthwise U-Net to learn only residual corrections lacks supporting quantitative evidence. No distribution statistics (histograms, mean/variance shifts, or KL-divergence measures) before/after preprocessing are reported, nor is there an ablation that removes the preprocessing stage. This is load-bearing because depthwise-separable convolutions have limited cross-channel mixing, and low-light scenes exhibit highly variable noise and color casts; without this evidence the residual-only learning premise remains unverified.
- [§4] §4 (Experiments) and associated tables: The extended benchmarks and ablations referenced in the abstract do not include error bars, per-scene failure-case analysis, or a direct comparison of parameter counts/FLOPs against the top-three challenge entries. This weakens the 'significantly fewer parameters' and 'competitive perceptual quality' assertions, especially given the compact architecture.
minor comments (2)
- [§3] The specific frozen preprocessing algorithm is not named or referenced in the method description; adding the citation or pseudocode would improve reproducibility.
- [Figure 2] Figure 2 (network diagram) would benefit from explicit channel counts and a note on how the complementary views are concatenated or fused.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We have prepared point-by-point responses below and will revise the manuscript to incorporate additional quantitative evidence and experimental details where feasible.
read point-by-point responses
-
Referee: [§3] §3 (Method): The claim that the frozen preprocessing 'normalizes the input distribution' sufficiently for the depthwise U-Net to learn only residual corrections lacks supporting quantitative evidence. No distribution statistics (histograms, mean/variance shifts, or KL-divergence measures) before/after preprocessing are reported, nor is there an ablation that removes the preprocessing stage. This is load-bearing because depthwise-separable convolutions have limited cross-channel mixing, and low-light scenes exhibit highly variable noise and color casts; without this evidence the residual-only learning premise remains unverified.
Authors: We agree that explicit quantitative support for the normalization effect would strengthen the central design rationale. The preprocessing step is a fixed, algorithm-based operation that generates complementary brightness-corrected views to reduce the dynamic range and color-cast variability presented to the network. While the NTIRE challenge results and existing ablations indirectly support the residual-learning premise, we did not include distribution statistics or a complete removal ablation in the original submission. In the revised version we will add before/after histograms, mean/variance shifts, and a dedicated ablation that isolates the contribution of the preprocessing stage, thereby directly addressing the concern regarding limited cross-channel mixing in depthwise-separable convolutions. revision: yes
-
Referee: [§4] §4 (Experiments) and associated tables: The extended benchmarks and ablations referenced in the abstract do not include error bars, per-scene failure-case analysis, or a direct comparison of parameter counts/FLOPs against the top-three challenge entries. This weakens the 'significantly fewer parameters' and 'competitive perceptual quality' assertions, especially given the compact architecture.
Authors: We acknowledge that the current presentation of results would benefit from greater statistical rigor and explicit comparisons. The 4th-place challenge ranking already supplies an external benchmark against competing methods, yet we agree that direct parameter/FLOP tables, error bars, and failure-case analysis would make the efficiency and quality claims more robust. In the revision we will (i) add error bars to quantitative tables where multiple runs exist, (ii) include a side-by-side parameter and FLOP comparison with the top-three NTIRE entries, and (iii) provide per-scene qualitative examples of challenging low-light conditions in the supplementary material. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks and competition results
full rationale
The paper proposes a two-stage LLIE architecture (frozen preprocessing for distribution normalization + depthwise-separable U-Net for residual correction) and validates it solely through empirical performance on external datasets and the NTIRE 2026 challenge leaderboard (4th place). No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the provided abstract or description. The central claims do not reduce to self-definition or construction; they are supported by independent external evaluation, satisfying the criteria for a self-contained non-circular result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen algorithm-based preprocessing produces complementary brightness-corrected views that normalize the input distribution for the subsequent network.
Reference graph
Works this paper leans on
-
[1]
LYT-Net: Lightweight YUV transformer-based network for low-light image enhance- ment.IEEE Signal Processing Letters, 32:2065–2069, 2025
Alexandru Brateanu, Raul Balmez, Adrian Avram, Ciprian Orhei, and Cosmin Ancuti. LYT-Net: Lightweight YUV transformer-based network for low-light image enhance- ment.IEEE Signal Processing Letters, 32:2065–2069, 2025. 2, 4
2065
-
[2]
RetinexFormer: One-stage retinex- based transformer for low-light image enhancement
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Tim- ofte, and Yulun Zhang. RetinexFormer: One-stage retinex- based transformer for low-light image enhancement. In ICCV, 2023. 1, 2, 4, 6
2023
-
[3]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InECCV, 2022. 2
2022
-
[4]
You only need 90k parameters to adapt light: A light weight trans- former for image enhancement and exposure correction
Ziteng Cui, Kunchang Li, Lin Gu, Sheng Su, Peng Gao, Zhengkai Jiang, Yu Qiao, and Tatsuya Harada. You only need 90k parameters to adapt light: A light weight trans- former for image enhancement and exposure correction. In BMVC, 2022. 1, 2, 4, 6
2022
-
[5]
Simoncelli
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P. Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE TPAMI, 2022. 4
2022
-
[6]
Zero-reference deep curve estimation for low-light image enhancement
Chunle Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong. Zero-reference deep curve estimation for low-light image enhancement. In CVPR, 2020. 1, 2, 4, 6
2020
-
[7]
Low-light image enhancement via breaking down the darkness.International Journal of Computer Vision, 131:48–66, 2023
Xiaojie Guo and Qiming Hu. Low-light image enhancement via breaking down the darkness.International Journal of Computer Vision, 131:48–66, 2023. 6
2023
-
[8]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco An- dreetto, and Hartmut Adam. MobileNets: Efficient convolu- tional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017. 2
work page internal anchor Pith review arXiv 2017
-
[9]
Retinexmamba: Retinex-based mamba for low-light image enhancement,
Yuhuo Huang, Daji Shi, Bin Zeng, Tao Wen, and Yaming Yan. RetinexMamba: Retinex-based mamba for low-light image enhancement. InarXiv preprint arXiv:2405.03349,
-
[10]
MUSIQ: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. MUSIQ: Multi-scale image quality transformer. InICCV, 2021. 4
2021
-
[11]
Edwin H. Land. The retinex theory of color vision.Scientific American, 237(6):108–128, 1977. 2
1977
-
[12]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 4
2019
-
[13]
Toward fast, flexible, and robust low-light image enhancement
Long Ma, Tengyu Ma, Risheng Liu, Xin Fan, and Zhongx- uan Luo. Toward fast, flexible, and robust low-light image enhancement. InCVPR, 2022. 1, 2, 4, 6
2022
-
[14]
Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method
Tao Wang, Kaihao Zhang, Tianrun Shen, Wenhan Luo, Bj¨orn Stenger, and Tong Lu. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. InAAAI, 2023. 1
2023
-
[15]
Deep retinex decomposition for low-light enhancement
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. In BMVC, 2018. 1, 2, 3, 4
2018
-
[16]
Shyang-En Weng, Shaou-Gang Miaou, and Ricky Chris- tanto. A lightweight low-light image enhancement network via channel prior and gamma correction.International Jour- nal of Pattern Recognition and Artificial Intelligence, 39(12): 2554013, 2025. 2, 3, 4, 6
2025
-
[17]
URetinex-Net: Retinex-based deep unfolding network for low-light image enhancement
Wenhui Wu, Jian Weng, Pingping Zhang, Xu Wang, Wen- han Yang, and Jianmin Jiang. URetinex-Net: Retinex-based deep unfolding network for low-light image enhancement. In CVPR, 2022. 1, 2
2022
-
[18]
HVI- CIDNet: Half-value isosurface-guided controllable image decomposition network for low-light image enhancement
Yaming Yan, Tao Wen, Daji Shi, and Bin Zeng. HVI- CIDNet: Half-value isosurface-guided controllable image decomposition network for low-light image enhancement. In CVPR, 2025. 1, 2, 4, 6
2025
-
[19]
Sparse gradient regularized deep retinex network for robust low-light image enhancement.IEEE TIP,
Wenhan Yang, Wenjing Wang, Haofeng Huang, Shiqi Wang, and Jiaying Liu. Sparse gradient regularized deep retinex network for robust low-light image enhancement.IEEE TIP,
-
[20]
Diff-retinex: Rethinking low-light image enhancement with a generative diffusion model
Xunpeng Yi, Han Xu, Hao Zhang, Linfeng Tang, and Jiayi Ma. Diff-retinex: Rethinking low-light image enhancement with a generative diffusion model. InICCV, 2023. 1
2023
-
[21]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 4
2018
-
[22]
Blind image quality assessment via vision- language correspondence: A multitask learning perspective
Weixia Zhang, Guangtao Zhai, Ying Wei, Xiaokang Yang, and Kede Ma. Blind image quality assessment via vision- language correspondence: A multitask learning perspective. InCVPR, 2023. 4
2023
-
[23]
Kindling the darkness: A practical low-light image enhancer
Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. Kindling the darkness: A practical low-light image enhancer. InACM MM, 2019. 1, 2
2019
-
[24]
Contrast limited adaptive histogram equal- ization.Graphics Gems IV, pages 474–485, 1994
Karel Zuiderveld. Contrast limited adaptive histogram equal- ization.Graphics Gems IV, pages 474–485, 1994. 2, 3 7
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.