Recognition: no theorem link
ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace Residual Rotation Approximation
Pith reviewed 2026-05-10 16:12 UTC · model grok-4.3
The pith
ReSpinQuant approximates per-layer rotation matrices with residual subspaces so that layer-wise LLM quantization accuracy can be obtained at the speed of global rotation methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReSpinQuant demonstrates that a residual subspace rotation approximation, computed via offline matching bases, can be fused directly into model weights, delivering the expressivity of per-layer rotation transformations with only negligible inference overhead.
What carries the argument
residual subspace rotation approximation that decomposes layer-specific rotations into a global component plus a low-dimensional residual whose basis can be matched and fused offline
Load-bearing premise
The residual subspace rotation approximation captures enough of the expressivity of full per-layer transformations to match their accuracy while still allowing complete offline fusion into the model weights.
What would settle it
Apply both ReSpinQuant and an unfused full layer-wise rotation method to the same model and dataset; if the accuracy of ReSpinQuant falls substantially below the full layer-wise result, the subspace approximation is insufficient.
Figures




read the original abstract
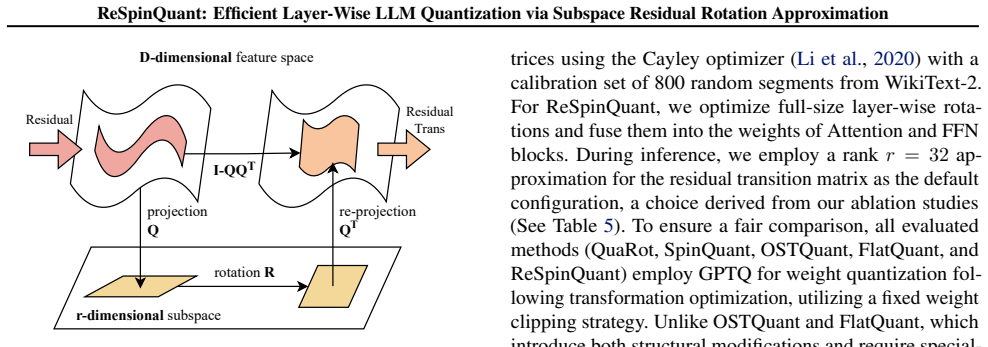
Rotation-based Post-Training Quantization (PTQ) has emerged as a promising solution for mitigating activation outliers in the quantization of Large Language Models (LLMs). Global rotation methods achieve inference efficiency by fusing activation rotations into attention and FFN blocks, but suffer from limited expressivity as they are constrained to use a single learnable rotation matrix across all layers. To tackle this, layer-wise transformation methods emerged, achieving superior accuracy through localized adaptation. However, layer-wise methods cannot fuse activation rotation matrices into weights, requiring online computations and causing significant overhead. In this paper, we propose ReSpinQuant, a quantization framework that resolves such overhead by leveraging offline activation rotation fusion and matching basis using efficient residual subspace rotation. This design reconciles the high expressivity of layer-wise adaptation with only negligible inference overhead. Extensive experiments on W4A4 and W3A3 quantization demonstrate that ReSpinQuant achieves state-of-the-art performance, outperforming global rotation methods and matching the accuracy of computationally expensive layer-wise methods with minimal overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. ReSpinQuant proposes a PTQ framework for LLMs that approximates per-layer activation rotations via residual subspace rotation with a matching basis. This enables complete offline fusion of the rotations into the model weights, delivering the expressivity of layer-wise methods while incurring only negligible inference overhead. The paper reports SOTA results on W4A4 and W3A3 quantization tasks, outperforming global rotation baselines and matching the accuracy of full layer-wise transformations.
Significance. If the residual subspace approximation is shown to preserve sufficient outlier-mitigation benefits, the work would meaningfully advance practical LLM quantization by removing the efficiency-expressivity trade-off that currently forces practitioners to choose between global rotations (fast but limited accuracy) and per-layer methods (accurate but online overhead). The offline-fusion design is a clear practical strength.
major comments (2)
- [Method section (residual subspace rotation approximation)] The central claim rests on the residual subspace rotation (with matching basis) approximating the optimal per-layer transformation matrices closely enough to retain their accuracy gains after fusion. No quantitative bound, approximation-error analysis, or ablation on subspace dimension is provided to demonstrate that the residual component aligns with layer-specific optima rather than collapsing toward a global rotation; this is load-bearing for the reconciliation of expressivity and efficiency.
- [Experiments section (Tables reporting W4A4/W3A3 results)] The reported SOTA results on W4A4 and W3A3 lack error bars, multiple random seeds, or statistical significance tests, making it impossible to determine whether the gains over global methods are reliable or whether the method truly matches full layer-wise accuracy within experimental noise.
minor comments (2)
- [Method section] Notation for the subspace dimension, matching basis, and residual component should be introduced with explicit equations and a clear diagram showing how the approximation is fused offline.
- [Introduction] The abstract and introduction would benefit from a short comparison table listing inference overhead (FLOPs or latency) for global, layer-wise, and ReSpinQuant methods to quantify the 'negligible' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the work.
read point-by-point responses
-
Referee: [Method section (residual subspace rotation approximation)] The central claim rests on the residual subspace rotation (with matching basis) approximating the optimal per-layer transformation matrices closely enough to retain their accuracy gains after fusion. No quantitative bound, approximation-error analysis, or ablation on subspace dimension is provided to demonstrate that the residual component aligns with layer-specific optima rather than collapsing toward a global rotation; this is load-bearing for the reconciliation of expressivity and efficiency.
Authors: We agree that the absence of a formal approximation-error analysis or subspace-dimension ablation leaves the central claim without quantitative support. The current manuscript relies on end-to-end accuracy results to show that the residual component preserves layer-specific outlier mitigation. In the revision we will add (i) an ablation varying subspace dimension and (ii) a direct error metric (e.g., Frobenius-norm distance between the learned residual rotation and the optimal per-layer matrix) to demonstrate that the approximation does not collapse to a global rotation. These additions will be placed in the Method and Experiments sections. revision: yes
-
Referee: [Experiments section (Tables reporting W4A4/W3A3 results)] The reported SOTA results on W4A4 and W3A3 lack error bars, multiple random seeds, or statistical significance tests, making it impossible to determine whether the gains over global methods are reliable or whether the method truly matches full layer-wise accuracy within experimental noise.
Authors: We acknowledge that the lack of error bars and multi-seed statistics limits the ability to assess result reliability. Our original experiments used fixed seeds for reproducibility and to control compute cost. We will rerun the primary W4A4 and W3A3 tables with at least three random seeds, report mean and standard deviation, and add error bars. Where appropriate we will also include a simple significance test (e.g., paired t-test) against the global-rotation baseline to quantify whether the observed gains exceed experimental noise. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces ReSpinQuant as a new framework that approximates layer-wise rotations via residual subspace rotations to enable offline fusion. The abstract and title describe this as a design choice reconciling expressivity and efficiency, with empirical results on W4A4/W3A3 tasks. No equations, derivations, or self-citations are visible that reduce any claimed result to a fitted parameter or input by construction. The approximation is presented as a novel technique rather than a tautological renaming or self-referential definition, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BoolQ: Exploring the surprising difficulty of natural yes/no questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Burstein, J., Do- ran, C., and Solorio, T. (eds.),Proceedings of the 2019 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, Volu...
2019
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Associ- ation for Computational Linguistics. doi: 10.18653/v1/ N19-1300. URL https://aclanthology.org/ N19-1300/. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/
-
[3]
URL https: //openreview.net/forum?id=tcbBPnfwxS. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https: //openreview.net/forum?id=rAcgDBdKnP. Li, J., Fuxin, L., and Todorovic, S. Efficient riemannian opti- mization on the stiefel manifold via the cayley transform. arXiv preprint arXiv:2002.01113,
-
[5]
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A
URL https:// openreview.net/forum?id=Byj72udxe. Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Riloff, E., Chiang, D., Hockenmaier, J., and Tsujii, J. (eds.),Proceedings of the 2018 Conference on Empirical Methods in Natural 9 ReSpinQuant: Efficient Layer-Wis...
2018
-
[6]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Association for Computational Linguistics. doi: 10.18653/v1/D18-1260. URL https: //aclanthology.org/D18-1260/. Paperno, D., Kruszewski, G., Lazaridou, A., Pham, N. Q., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G., and Fern´andez, R. The LAMBADA dataset: Word pre- diction requiring a broad discourse context. In Erk, K. and Smith, N. A. (eds.),Proceed...
-
[7]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Association for Compu- tational Linguistics. doi: 10.18653/v1/P16-1144. URL https://aclanthology.org/P16-1144/. Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y . Winogrande: an adversarial winograd schema challenge at scale.Commun. ACM, 64(9):99–106, August
-
[8]
Noam Shazeer and Mitchell Stern
ISSN 0001-0782. doi: 10.1145/3474381. URL https: //doi.org/10.1145/3474381. Sap, M., Rashkin, H., Chen, D., Le Bras, R., and Choi, Y . Social IQa: Commonsense reasoning about social in- teractions. In Inui, K., Jiang, J., Ng, V ., and Wan, X. (eds.),Proceedings of the 2019 Conference on Empiri- cal Methods in Natural Language Processing and the 9th Intern...
-
[9]
Social IQa: Commonsense Reasoning about Social Interactions
Association for Compu- tational Linguistics. doi: 10.18653/v1/D19-1454. URL https://aclanthology.org/D19-1454/. Sun, Y ., Liu, R., Bai, H., Bao, H., Zhao, K., Li, Y ., Jiax- inHu, Yu, X., Hou, L., Yuan, C., Jiang, X., Liu, W., and Yao, J. Flatquant: Flatness matters for LLM quantization. InForty-second International Conference on Machine Learning,
-
[10]
Llama 2: Open Foundation and Fine-Tuned Chat Models
URL https://openreview.net/ forum?id=uTz2Utym5n. Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ButterflyQuant: Ultra-low- bit LLM quantization through learnable orthogonal butterfly transforms
URL https://proceedings. mlr.press/v202/xiao23c.html. Xu, B., Dong, Z., Elachqar, O., and Shang, Y . Butter- flyquant: Ultra-low-bit llm quantization through learn- able orthogonal butterfly transforms.arXiv preprint arXiv:2509.09679,
-
[12]
H ella S wag: Can a Machine Really Finish Your Sentence?
Association for Computa- tional Linguistics. doi: 10.18653/v1/P19-1472. URL https://aclanthology.org/P19-1472/. 10 ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace Residual Rotation Approximation A. Additional Implementation Details In this section, we provide detailed configurations for our experiments to ensure reproducibility. General Ex...
-
[13]
GPTQ quantization
as the calibration dataset. To evaluate the zero-shot performance, we utilized the lm-evaluation-harnesslibrary (version0.4.4). RTN / GPTQ (Frantar et al., 2023).Since GPTQ is applicable only to weight quantization, any reference to “GPTQ quantization” in our experiments implies applying GPTQ to weights while using Round-to-Nearest (RTN) for activations. ...
2023
-
[14]
Table 6 lists the full W4A4 quantization results for the LLaMA-2 (Touvron et al., 2023), LLaMA-3, and LLaMA- 3.2 (Grattafiori et al.,
and Zero-shot Accuracy across nine benchmarks: BoolQ (Clark et al., 2019), PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (HellaS.) (Zellers et al., 2019), WinoGrande (WinoG.) (Sakaguchi et al., 2021), ARC-easy (ARC-e) and ARC-challenge (ARC-c) (Clark et al., 2018), OpenBookQA (OBQA) (Mihaylov et al., 2018), and LAMBADA (LAMB) (Paperno et al...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.