Recognition: unknown
AIM: Intent-Aware Unified world action Modeling with Spatial Value Maps
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
AIM improves robot manipulation by predicting spatial value maps that encode interaction intent from video models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
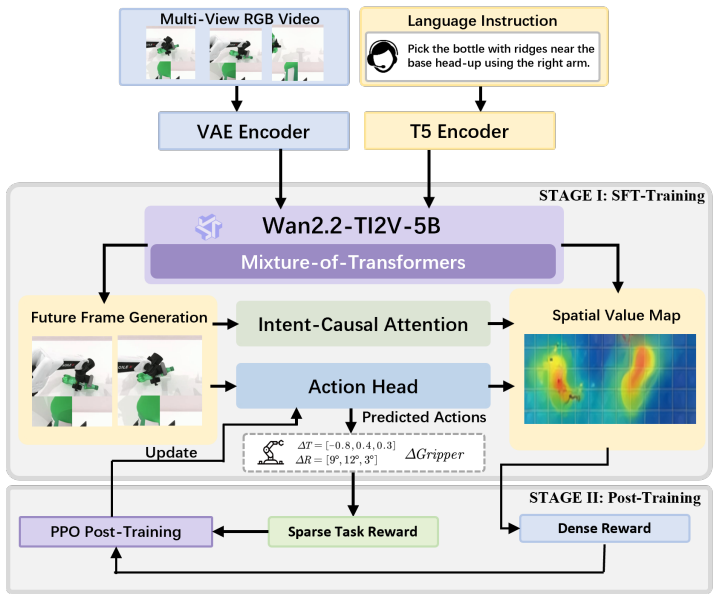
AIM introduces an intent-aware unified world action model that jointly predicts future observations and aligned spatial value maps within a shared mixture-of-transformers architecture, using intent-causal attention to route future information exclusively through the value representation, followed by a self-distillation reinforcement learning stage that freezes the video and value branches while optimizing the action head with dense rewards from projected value-map responses and sparse task signals.
What carries the argument
The aligned spatial value map that encodes task-relevant interaction structure and serves as the explicit spatial interface between visual future modeling and action decoding.
If this is right
- Joint modeling of observations and value maps within one architecture improves action reliability over direct decoding from visual features.
- Intent-causal attention ensures future information influences actions only through the value representation.
- Freezing the video and value branches during reinforcement learning allows efficient optimization focused on the action head.
- The constructed 30K-trajectory simulation dataset with synchronized multi-view data and value annotations enables scalable training.
Where Pith is reading between the lines
- The value-map intermediate could make the model's decisions more interpretable for debugging robot failures.
- Similar spatial-intent interfaces might transfer to non-robot domains that combine visual prediction with sequential decision making.
- Scaling the approach to real-world data could test whether the same value-map bridge reduces the need for domain-specific fine-tuning.
Load-bearing premise
An aligned spatial value map predicted from a pretrained video model encodes enough task-relevant interaction structure to support reliable action decoding without substantial additional robot-specific training.
What would settle it
An ablation that removes the spatial value map prediction and shows success rates on long-horizon contact-sensitive tasks falling back to levels of prior unified world action baselines.
Figures

read the original abstract
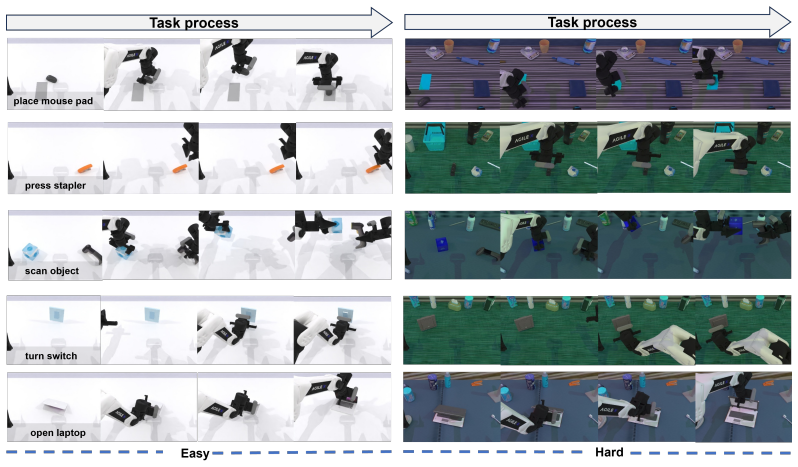
Pretrained video generation models provide strong priors for robot control, but existing unified world action models still struggle to decode reliable actions without substantial robot-specific training. We attribute this limitation to a structural mismatch: while video models capture how scenes evolve, action generation requires explicit reasoning about where to interact and the underlying manipulation intent. We introduce AIM, an intent-aware unified world action model that bridges this gap via an explicit spatial interface. Instead of decoding actions directly from future visual representations, AIM predicts an aligned spatial value map that encodes task-relevant interaction structure, enabling a control-oriented abstraction of future dynamics. Built on a pretrained video generation model, AIM jointly models future observations and value maps within a shared mixture-of-transformers architecture. It employs intent-causal attention to route future information to the action branch exclusively through the value representation. We further propose a self-distillation reinforcement learning stage that freezes the video and value branches and optimizes only the action head using dense rewards derived from projected value-map responses together with sparse task-level signals. To support training and evaluation, we construct a simulation dataset of 30K manipulation trajectories with synchronized multi-view observations, actions, and value-map annotations. Experiments on RoboTwin 2.0 benchmark show that AIM achieves a 94.0% average success rate, significantly outperforming prior unified world action baselines. Notably, the improvement is more pronounced in long-horizon and contact-sensitive manipulation tasks, demonstrating the effectiveness of explicit spatial-intent modeling as a bridge between visual world modeling and robot control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AIM, an intent-aware unified world action model that uses a pretrained video generation model within a mixture-of-transformers architecture to jointly predict future observations and aligned spatial value maps. It incorporates intent-causal attention to route information to the action branch exclusively through the value representation, followed by a self-distillation RL stage that freezes the video and value branches while optimizing only the action head with dense rewards from projected value-map responses plus sparse task signals. Training and evaluation rely on a custom simulation dataset of 30K manipulation trajectories with synchronized multi-view observations, actions, and value-map annotations. Experiments on the RoboTwin 2.0 benchmark report a 94.0% average success rate, with larger gains in long-horizon and contact-sensitive tasks, positioning explicit spatial-intent modeling as a bridge between visual world modeling and robot control.
Significance. If the empirical claims hold after addressing the noted concerns, this work could meaningfully advance unified world models for robotics by demonstrating that explicit spatial value maps can serve as an effective interface for action decoding, reducing reliance on extensive robot-specific fine-tuning. The integration of pretrained video priors with a control-oriented abstraction and the reported improvements on challenging manipulation scenarios would represent a substantive contribution to the field.
major comments (3)
- [Abstract (Experiments on RoboTwin 2.0)] The abstract reports a 94.0% average success rate significantly outperforming prior unified world action baselines, with pronounced gains in long-horizon and contact-sensitive tasks, but provides no details on the specific baselines, ablation results, error bars, or statistical tests. This absence makes it impossible to verify the robustness of the central claim that explicit spatial-intent modeling is the key enabling factor.
- [Self-distillation reinforcement learning stage] The self-distillation reinforcement learning stage freezes the video and value branches and optimizes the action head using dense rewards derived from projected value-map responses together with sparse task signals. Because the value maps are both predicted by the model and used to generate the training rewards, this creates a potential circular dependency that may allow the action head to exploit privileged annotation structure from the custom dataset rather than demonstrating emergent intent encoding from video priors alone.
- [Dataset construction paragraph] The training dataset consists of 30K manipulation trajectories with synchronized value-map annotations whose generation process (simulation-derived, expert-labeled, or otherwise) is unspecified. Without this information or evidence that the same value maps can be accurately predicted on held-out tasks or real-robot settings, the claim that the approach bridges visual world modeling and control without substantial robot-specific training cannot be fully evaluated.
minor comments (2)
- [Abstract] The abstract contains minor inconsistencies in capitalization (e.g., 'world action Modeling').
- [Abstract] The abstract would be strengthened by a concise statement of the number of compared baselines or key ablation outcomes to support the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and noting revisions to the manuscript where they strengthen the presentation without altering the core claims or experimental results.
read point-by-point responses
-
Referee: [Abstract (Experiments on RoboTwin 2.0)] The abstract reports a 94.0% average success rate significantly outperforming prior unified world action baselines, with pronounced gains in long-horizon and contact-sensitive tasks, but provides no details on the specific baselines, ablation results, error bars, or statistical tests. This absence makes it impossible to verify the robustness of the central claim that explicit spatial-intent modeling is the key enabling factor.
Authors: We agree the abstract is concise and omits granular details due to length limits. The full paper specifies the baselines in Section 4.2 (prior unified world action models), presents ablation results in Section 4.3 and Table 3 that isolate the contribution of spatial value maps and intent-causal attention, and reports all metrics as means with standard deviations over 5 seeds along with paired t-test p-values (p < 0.01 for the main 94.0% result). We have revised the abstract to name the primary baseline category and note the statistical significance of gains on long-horizon and contact-rich tasks, improving verifiability while preserving brevity. revision: yes
-
Referee: [Self-distillation reinforcement learning stage] The self-distillation reinforcement learning stage freezes the video and value branches and optimizes the action head using dense rewards derived from projected value-map responses together with sparse task signals. Because the value maps are both predicted by the model and used to generate the training rewards, this creates a potential circular dependency that may allow the action head to exploit privileged annotation structure from the custom dataset rather than demonstrating emergent intent encoding from video priors alone.
Authors: We appreciate this observation and have clarified the separation of stages. The value branch is first trained supervised on ground-truth value-map annotations to predict spatial values from video observations. In the RL stage the video and value branches remain frozen; only the action head is updated using rewards computed from the frozen value branch's own predictions. Because gradients do not flow back to the value branch, the action head cannot modify or directly access raw annotations; it learns to decode actions aligned with the already-learned intent representation. We have expanded Section 3.3 with a dedicated paragraph explaining this one-way distillation and why it avoids circularity while still leveraging video priors through the value-map interface. revision: yes
-
Referee: [Dataset construction paragraph] The training dataset consists of 30K manipulation trajectories with synchronized value-map annotations whose generation process (simulation-derived, expert-labeled, or otherwise) is unspecified. Without this information or evidence that the same value maps can be accurately predicted on held-out tasks or real-robot settings, the claim that the approach bridges visual world modeling and control without substantial robot-specific training cannot be fully evaluated.
Authors: We agree the original description was incomplete. Value-map annotations are generated automatically in simulation by projecting task-specific dense reward functions (derived from ground-truth object poses, contact states, and goal distances) onto image-space spatial maps for each trajectory. This procedure is now fully specified in the revised Section 3.1. The RoboTwin 2.0 test set contains held-out task variants and object configurations; AIM's reported success rates on these demonstrate generalization of the learned value maps. The current study is simulation-focused, so we lack real-robot validation; we have added an explicit limitations paragraph acknowledging this and discussing the visual-only nature of value-map prediction as a step toward reduced robot-specific training. revision: yes
- The manuscript does not contain real-robot experiments or direct evidence of value-map prediction accuracy on physical hardware.
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper's core derivation introduces an explicit spatial value map as an interface between a pretrained video backbone and action decoding, with intent-causal attention routing information through that map. The self-distillation RL stage freezes the video and value branches and trains only the action head using rewards derived from projected value-map responses plus sparse task signals. However, the value maps are trained via supervised learning on externally constructed dataset annotations (30K trajectories with synchronized value-map labels), and the video model is pretrained externally. No equation, prediction, or first-principles result reduces by construction to its own inputs; the architecture and training procedure do not tautologically force the reported 94% success rate. The result remains an empirical claim on the RoboTwin benchmark rather than a definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained video generation models capture scene evolution sufficiently for downstream control when augmented with an explicit spatial interface.
invented entities (2)
-
Spatial value map
no independent evidence
-
Intent-causal attention
no independent evidence
Forward citations
Cited by 2 Pith papers
-
From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation
MoLA infers a mixture of latent actions from generated future videos via modality-aware inverse dynamics models to improve robot manipulation policies.
-
World Action Models: The Next Frontier in Embodied AI
The paper introduces World Action Models as a new paradigm unifying predictive world modeling with action generation in embodied foundation models and provides a taxonomy of existing approaches.
Reference graph
Works this paper leans on
-
[1]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Jun Zhu, et al. Motus: A unified latent action world model, 2025. URL https: //arxiv.org/abs/2512.13030
work page internal anchor Pith review arXiv 2025
-
[2]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[4]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control. arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review arXiv 2026
-
[7]
Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
-
[8]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Towards physically executable 3d gaussian for embodied navigation,
Bingchen Miao, Rong Wei, Zhiqi Ge, Xiaoquan Sun, Shiqi Gao, Jingzhe Zhu, Renhan Wang, Siliang Tang, Jun Xiao, Rui Tang, and Juncheng Li. Towards physically executable 3d gaussian for embodied navigation, 2025. URLhttps://arxiv.org/abs/2510.21307
-
[10]
Guibas, Mustafa Mukadam, Abhinav Gupta, and Shubham Tulsiani
Kaichun Mo, Leonidas J. Guibas, Mustafa Mukadam, Abhinav Gupta, and Shubham Tulsiani. Where2act: From pixels to actions for articulated 3d objects. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6813–6823, 2021
2021
-
[11]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Physical Intelligence, Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A Vision- Language-Action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A Vision- Language-Action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020. 10
2020
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Cliport: What and where pathways for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. InProceedings of the 5th Conference on Robot Learning, volume 164 of Proceedings of Machine Learning Research, pages 894–906, 2022
2022
-
[17]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InProceedings of The 6th Conference on Robot Learning, pages 785–799, 2023
2023
-
[18]
Wenxuan Song, Jiayi Chen, Xiaoquan Sun, Huashuo Lei, Yikai Qin, Wei Zhao, Pengxiang Ding, Han Zhao, Tongxin Wang, Pengxu Hou, Zhide Zhong, Haodong Yan, Donglin Wang, Jun Ma, and Haoang Li. Rethinking the practicality of vision-language-action model: A comprehensive benchmark and an improved baseline.arXiv preprint arXiv:2602.22663, 2026
-
[19]
Xiaoquan Sun, Zetian Xu, Chen Cao, Zonghe Liu, Yihan Sun, Jingrui Pang, Ruijian Zhang, Zhen Yang, Kang Pang, Dingxin He, et al. Atomvla: Scalable post-training for robotic manipulation via predictive latent world models.arXiv preprint arXiv:2603.08519, 2026
-
[20]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, and Feiwu Yu. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Calamari: Contact-aware and language conditioned spatial action mapping for contact-rich manipulation
Youngsun Wi, Mark Van der Merwe, Pete Florence, Andy Zeng, and Nima Fazeli. Calamari: Contact-aware and language conditioned spatial action mapping for contact-rich manipulation. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 2753–2771, 2023
2023
-
[22]
Gigaworld-policy: An efficient action- centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, Min Cao, and Peng Li. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
-
[23]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review arXiv 2026
-
[24]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review arXiv 2026
-
[25]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Rt-2: Vision- language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Nikhil Joshi, Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, et al. Rt-2: Vision- language-action models transfer web knowledge to robotic control. InProceedings of The 7th Conference on Robot Learning, pages 2165–2183, 2023. 11
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.