Recognition: 2 theorem links
· Lean TheoremFrom Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation
Pith reviewed 2026-05-13 04:39 UTC · model grok-4.3
The pith
MoLA extracts latent actions from generated robot videos using a mixture of inverse dynamics models to bridge imagination and control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
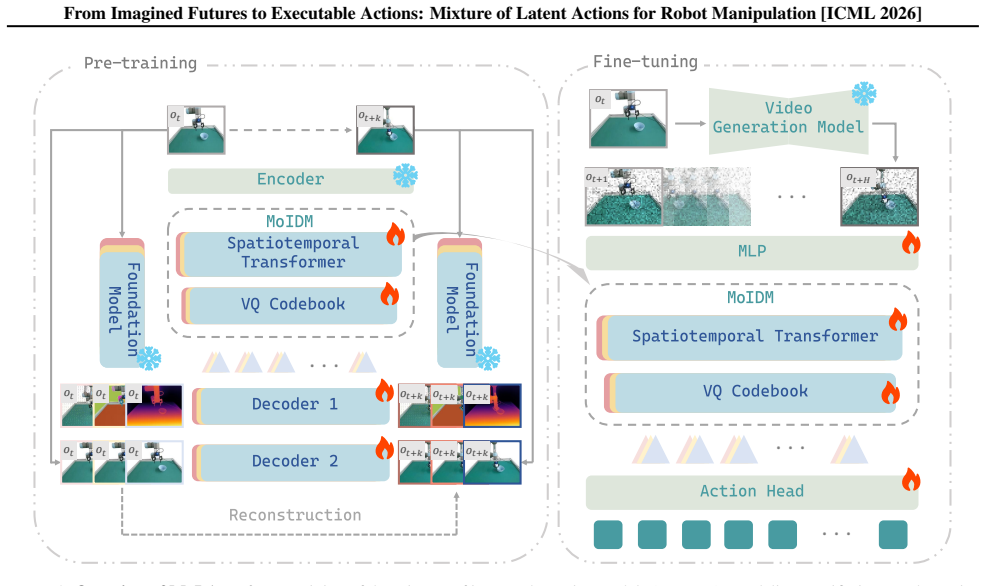
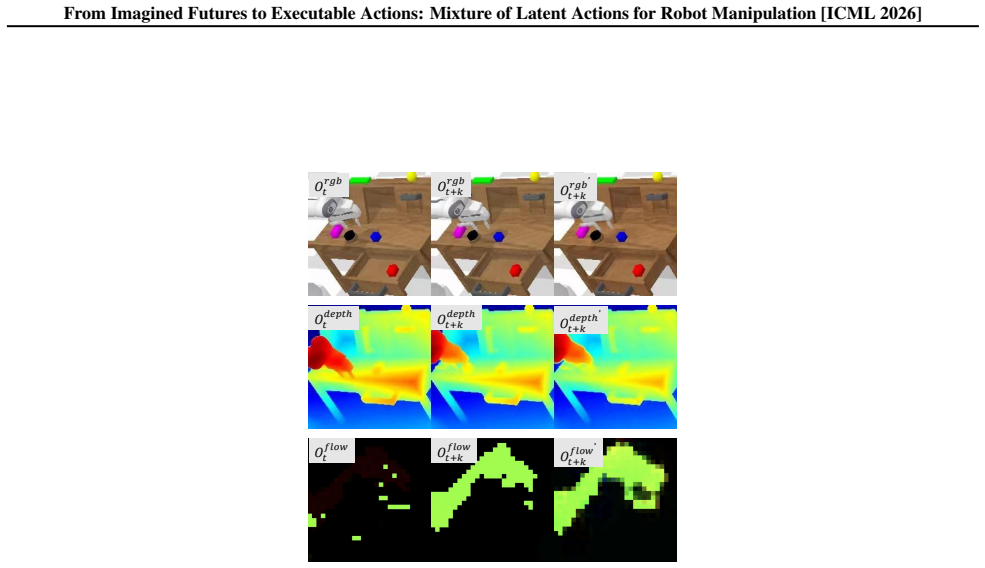
MoLA transforms imagined future videos into executable representations by leveraging a mixture of pretrained inverse dynamics models to infer a mixture of latent actions implied by generated visual transitions. These modality-aware inverse dynamics models capture complementary semantic, depth, and flow cues, providing a structured and physically grounded action representation that bridges video imagination and policy execution.
What carries the argument
Mixture of modality-aware pretrained inverse dynamics models that infer latent actions from visual transitions in generated videos
If this is right
- Delivers consistent gains in task success rates across simulated benchmarks including LIBERO, CALVIN, and LIBERO-Plus.
- Improves temporal consistency of executed action sequences derived from long-horizon predictions.
- Enhances generalization to unseen tasks and real-world robot manipulation settings.
- Avoids the indirect control that arises when policies receive predicted observations directly or when videos are decoded without latent grounding.
Where Pith is reading between the lines
- The same mixture approach could be tested with other generative outputs such as depth sequences or language-described futures to see if latent-action extraction remains effective.
- Using pretrained rather than jointly trained models suggests a modular way to incorporate new sensing modalities without retraining the entire pipeline.
- If the gains hold under distribution shift, it implies video-based imagination can become a practical planning layer for robots without requiring end-to-end video-to-action training.
- A natural extension would measure whether the number of modalities in the mixture can be reduced while preserving most of the reported improvements.
Load-bearing premise
That combining inverse dynamics models across different visual modalities will reliably produce complementary latent actions that are more control-relevant than the original video frames without introducing new instabilities.
What would settle it
An experiment on LIBERO or CALVIN where replacing MoLA with direct policy conditioning on the same predicted frames yields equal or higher task success and temporal consistency would show the mixture step adds no benefit.
Figures













read the original abstract
Video generation models offer a promising imagination mechanism for robot manipulation by predicting long-horizon future observations, but effectively exploiting these imagined futures for action execution remains challenging. Existing approaches either condition policies on predicted frames or directly decode generated videos into actions, both suffering from a mismatch between visual realism and control relevance. As a result, predicted observations emphasize perceptual fidelity rather than action-centric causes of state transitions, leading to indirect and unstable control. To address this gap, we propose MoLA (Mixture of Latent Actions), a control-oriented interface that transforms imagined future videos into executable representations. Instead of passing predicted frames directly to the policy, MoLA leverages a mixture of pretrained inverse dynamics models to infer a mixture of latent actions implied by generated visual transitions. These modality-aware inverse dynamics models capture complementary semantic, depth, and flow cues, providing a structured and physically grounded action representation that bridges video imagination and policy execution. We evaluate our approach on simulated benchmarks (LIBERO, CALVIN, and LIBERO-Plus) and real-world robot manipulation tasks, achieving consistent gains in task success, temporal consistency, and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoLA (Mixture of Latent Actions), a method that converts future videos generated by video models into executable robot actions by applying a mixture of pretrained modality-aware inverse dynamics models (capturing semantic, depth, and flow cues) to infer latent actions from visual transitions. This is positioned as addressing the mismatch between perceptual fidelity in generated observations and control relevance, with evaluation on LIBERO, CALVIN, LIBERO-Plus, and real-world manipulation tasks claiming consistent improvements in task success, temporal consistency, and generalization.
Significance. If the empirical claims hold under scrutiny, the work could meaningfully advance robot manipulation by providing a structured, control-oriented bridge between video-based imagination and policy execution, leveraging complementary pretrained models without requiring end-to-end retraining. The emphasis on physically grounded latent actions from generated futures is a targeted contribution to long-horizon planning, provided the mixture mechanism demonstrably mitigates instabilities.
major comments (2)
- [§3] §3 (Method): The central claim that the mixture of pretrained IDMs produces 'physically grounded' and 'executable' latent actions from generated videos rests on the untested assumption that these models generalize without adaptation or calibration to the distributional shift between their training data (real/simulator trajectories) and the outputs of video generation models. No quantitative validation of IDM prediction accuracy on generated frames (e.g., action reconstruction error or consistency metrics) is provided, directly risking the reintroduction of control instability the method aims to resolve.
- [§4] §4 (Experiments): While consistent gains are claimed across LIBERO, CALVIN, LIBERO-Plus, and real-world tasks, the manuscript supplies insufficient detail on baselines, statistical significance, error bars, or ablation isolating the contribution of the mixture versus individual modalities or direct frame conditioning. This weakens the ability to attribute improvements specifically to the proposed interface rather than implementation choices.
minor comments (2)
- [§3.2] Notation for the mixture weights and latent action aggregation (Eq. in §3.2) could be clarified to distinguish learned vs. fixed components.
- [Figure 1] Figure 1 (pipeline overview) would benefit from explicit arrows indicating how modality-specific IDM outputs are combined before policy input.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify how to strengthen the presentation of MoLA. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that the mixture of pretrained IDMs produces 'physically grounded' and 'executable' latent actions from generated videos rests on the untested assumption that these models generalize without adaptation or calibration to the distributional shift between their training data (real/simulator trajectories) and the outputs of video generation models. No quantitative validation of IDM prediction accuracy on generated frames (e.g., action reconstruction error or consistency metrics) is provided, directly risking the reintroduction of control instability the method aims to resolve.
Authors: We agree that explicit validation of IDM accuracy on generated frames would provide stronger support for the physical grounding claim. The manuscript currently relies on the fact that the three modality-aware IDMs were pretrained on large-scale, diverse trajectory data (including both real and simulated sources) and that the mixture is intended to average out individual model errors. However, we acknowledge this does not substitute for direct measurement on video-model outputs. In the revised version we will add a dedicated quantitative analysis section reporting action reconstruction error, temporal consistency, and cross-modal agreement metrics when the IDMs are applied to frames sampled from the video generation model used in our experiments. This will directly test the generalization assumption and quantify any residual instability. revision: yes
-
Referee: [§4] §4 (Experiments): While consistent gains are claimed across LIBERO, CALVIN, LIBERO-Plus, and real-world tasks, the manuscript supplies insufficient detail on baselines, statistical significance, error bars, or ablation isolating the contribution of the mixture versus individual modalities or direct frame conditioning. This weakens the ability to attribute improvements specifically to the proposed interface rather than implementation choices.
Authors: We accept that the current experimental section lacks sufficient detail for readers to fully isolate the contribution of the mixture mechanism. In the revision we will (1) provide a complete table of all baselines with exact implementation references, (2) report mean and standard deviation across at least three random seeds for every metric, (3) include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) with p-values, and (4) expand the ablation study to explicitly compare the full mixture against each single-modality IDM, against direct frame conditioning, and against a non-mixture ensemble. These additions will make the attribution of gains to the proposed interface unambiguous. revision: yes
Circularity Check
No significant circularity; method combines external pretrained models without self-referential reduction
full rationale
The paper's core proposal is MoLA, which applies a mixture of existing pretrained inverse dynamics models (semantic, depth, flow) to generated video frames to produce latent actions. This is presented as a novel interface rather than a derivation from first principles or fitted parameters. No equations are shown that define a quantity in terms of itself, no 'predictions' are made from subsets of the paper's own data, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The approach is evaluated on external benchmarks (LIBERO, CALVIN) with empirical gains, keeping the claim independent of its own outputs. The derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained inverse dynamics models can be mixed to capture complementary semantic, depth, and flow cues from generated visual transitions.
invented entities (1)
-
Mixture of Latent Actions (MoLA)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMoLA leverages a mixture of pretrained inverse dynamics models to infer a mixture of latent actions implied by generated visual transitions... modality-aware inverse dynamics models capture complementary semantic, depth, and flow cues
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe employ Diffusion Transformer... optimized using a flow matching objective
Reference graph
Works this paper leans on
-
[1]
Rt-h: Action hierarchies using language.arXiv preprint arXiv:2403.01823,
Belkhale, S., Ding, T., Xiao, T., Sermanet, P., Vuong, Q., Tompson, J., Chebotar, Y ., Dwibedi, D., and Sadigh, D. Rt-h: Action hierarchies using language.arXiv preprint arXiv:2403.01823,
-
[2]
Motus: A Unified Latent Action World Model
Bi, H., Tan, H., Xie, S., Wang, Z., Huang, S., Liu, H., Zhao, R., Feng, Y ., Xiang, C., Rong, Y ., et al. Mo- tus: A unified latent action world model.arXiv preprint arXiv:2512.13030,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Casta˜neda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y ., Fox, D., Hu, F., Huang, S., et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Black, K., Nakamoto, M., Atreya, P., Walke, H., Finn, C., Kumar, A., and Levine, S. Zero-shot robotic manipulation with pretrained image-editing diffusion models.arXiv preprint arXiv:2310.10639,
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y ., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. NeurIPS, 33:1877–1901,
work page 1901
-
[8]
Bu, Q., Li, H., Chen, L., Cai, J., Zeng, J., Cui, H., Yao, M., and Qiao, Y . Towards synergistic, generalized, and efficient dual-system for robotic manipulation.arXiv preprint arXiv:2410.08001, 2024a. Bu, Q., Zeng, J., Chen, L., Yang, Y ., Zhou, G., Yan, J., Luo, P., Cui, H., Ma, Y ., and Li, H. Closed-loop visuomotor control with generative expectation ...
-
[9]
Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
Cen, J., Huang, S., Yuan, Y ., Li, K., Yuan, H., Yu, C., Jiang, Y ., Guo, J., Li, X., Luo, H., et al. Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025a. Cen, J., Yu, C., Yuan, H., Jiang, Y ., Huang, S., Guo, J., Li, X., Song, Y ., Luo, H., Wang, F., et al. Worldvla: To- wards autoregressive action world m...
-
[10]
Large Video Planner Enables Generalizable Robot Control
Chen, B., Zhang, T., Geng, H., Song, K., Zhang, C., Li, P., Freeman, W. T., Malik, J., Abbeel, P., Tedrake, R., et al. Large video planner enables generalizable robot control. arXiv preprint arXiv:2512.15840, 2025a. Chen, C., Wu, Y .-F., Yoon, J., and Ahn, S. TransDreamer: Reinforcement learning with transformer world models. arXiv preprint arXiv:2202.09481,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Chen, H., Sun, B., Zhang, A., Pollefeys, M., and Leuteneg- ger, S. Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manip- ulation. InCVPR, pp. 27661–27672, 2025b. Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y ., Li, Z., Liang, Q., Lin, X., Ge, Y ., Gu, Z., et al. Robotwin 2.0: A scal- able data generator an...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Internvla-m1: A spatially guided vision- language-action framework for generalist robot policy,
Chen, X., Chen, Y ., Fu, Y ., Gao, N., Jia, J., Jin, W., Li, H., Mu, Y ., Pang, J., Qiao, Y ., et al. Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025d. Chen, Y ., Ge, Y ., Tang, W., Li, Y ., Ge, Y ., Ding, M., Shan, Y ., and Liu, X. Moto: Latent motion token as the bridgin...
-
[13]
Mind: Unified visual imagination and control via hierarchical world models
Chi, X., Ge, K., Liu, J., Zhou, S., Jia, P., He, Z., Liu, Y ., Li, T., Han, L., Han, S., et al. Mind: Unified visual imagination and control via hierarchical world models. arXiv preprint arXiv:2506.18897, 2025a. Chi, X., Jia, P., Fan, C.-K., Ju, X., Mi, W., Zhang, K., Qin, Z., Tian, W., Ge, K., Li, H., et al. Wow: Towards a world omniscient world model th...
-
[14]
URL https:// openreview.net/forum?id=XTlFwamMo1. Collins, J. A., Cheng, L., Aneja, K., Wilcox, A., Joffe, B., and Garg, A. Amplify: Actionless motion priors for robot learning from videos.arXiv preprint arXiv:2506.14198,
-
[15]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Ebert, F., Yang, Y ., Schmeckpeper, K., Bucher, B., Geor- gakis, G., Daniilidis, K., Finn, C., and Levine, S. Bridge data: Boosting generalization of robotic skills with cross- domain datasets.arXiv preprint arXiv:2109.13396,
work page internal anchor Pith review arXiv
-
[17]
AIM: Intent-Aware Unified world action Modeling with Spatial Value Maps
Fan, L., Xu, Z., Cao, C., Zhang, W., Yuan, M., and Chen, J. Aim: Intent-aware unified world action modeling with spatial value maps.arXiv preprint arXiv:2604.11135,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Fan, S., Wu, K., Che, Z., Wang, X., Wu, D., Liao, F., Liu, N., Zhang, Y ., Zhao, Z., Xu, Z., et al. Xr-1: Towards versatile vision-language-action models via learning unified vision- motion representations.arXiv preprint arXiv:2511.02776,
-
[19]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Fei, S., Wang, S., Shi, J., Dai, Z., Cai, J., Qian, P., Ji, L., He, X., Zhang, S., Fei, Z., et al. Libero-plus: In-depth robust- ness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Feng, Y ., Han, J., Yang, Z., Yue, X., Levine, S., and Luo, J. Reflective planning: Vision-language models for multi- stage long-horizon robotic manipulation.arXiv preprint arXiv:2502.16707, 2025a. Feng, Y ., Tan, H., Mao, X., Xiang, C., Liu, G., Huang, S., Su, H., and Zhu, J. Vidar: Embodied video diffu- sion model for generalist manipulation.arXiv prepr...
-
[21]
G., Rao, K., Yu, W., Fu, C., Gopalakrishnan, K., Xu, Z., et al
Gu, J., Kirmani, S., Wohlhart, P., Lu, Y ., Arenas, M. G., Rao, K., Yu, W., Fu, C., Gopalakrishnan, K., Xu, Z., et al. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches.arXiv preprint arXiv:2311.01977,
-
[22]
11 From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation [ICML 2026] Guo, Y ., Hu, Y ., Zhang, J., Wang, Y .-J., Chen, X., Lu, C., and Chen, J. Prediction with action: Visual policy learning via joint denoising process.NeurIPS, 37:112386– 112410,
work page 2026
-
[23]
Ctrl-world: A controllable generative world model for robot manipulation, 2026
Guo, Y ., Shi, L. X., Chen, J., and Finn, C. Ctrl-world: A con- trollable generative world model for robot manipulation. arXiv preprint arXiv:2510.10125,
-
[24]
Nora: A small open-sourced generalist vision language action model for embodied tasks,
Hung, C.-Y ., Sun, Q., Hong, P., Zadeh, A., Li, C., Tan, U., Majumder, N., Poria, S., et al. Nora: A small open- sourced generalist vision language action model for em- bodied tasks.arXiv preprint arXiv:2504.19854,
-
[25]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dha- balia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al. π0.5: a vision-language-action model with open- world generalization.arXiv preprint arXiv:2504.16054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Enerverse-ac: Envisioning embodied environments with action condition,
Jia, M., Qi, Z., Zhang, S., Zhang, W., Yu, X., He, J., Wang, H., and Yi, L. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models. ICLR, 2025a. Jia, Y ., Liu, J., Chen, S., Gu, C., Wang, Z., Luo, L., Lee, L., Wang, P., Wang, Z., Zhang, R., et al. Lift3d foundation policy: Lifting 2d large-scale pretrained models for rob...
-
[27]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M. K., Chen, L. Y ., Ellis, K., et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Kim, M. J., Gao, Y ., Lin, T.-Y ., Lin, Y .-C., Ge, Y ., Lam, G., Liang, P., Song, S., Liu, M.-Y ., Finn, C., et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Causal World Modeling for Robot Control
Li, C., Wen, J., Peng, Y ., Peng, Y ., and Zhu, Y . Pointvla: Injecting the 3d world into vision-language-action models. IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026a. Li, H., Yang, S., Chen, Y ., Tian, Y ., Yang, X., Chen, X., Wang, H., Wang, T., Zhao, F., Lin, D., et al. Cronusvla: Transferring latent motion across time for multi-frame pr...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Li, X., Li, P., Liu, M., Wang, D., Liu, J., Kang, B., Ma, X., Kong, T., Zhang, H., and Liu, H. Towards generalist robot policies: What matters in building vision-language-action models.arXiv preprint arXiv:2412.14058, 2024b. Li, X., Xu, J., Zhang, M., Liu, J., Shen, Y ., Ponomarenko, I., Xu, J., Heng, L., Huang, S., Zhang, S., et al. Object- centric promp...
-
[31]
Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Liang, J., Tokmakov, P., Liu, R., Sudhakar, S., Shah, P., Ambrus, R., and V ondrick, C. Video generators are robot policies.arXiv preprint arXiv:2508.00795,
-
[32]
Liao, Y ., Zhou, P., Huang, S., Yang, D., Chen, S., Jiang, Y ., Hu, Y ., Cai, J., Liu, S., Luo, J., et al. Genie envi- sioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635,
-
[33]
Liu, B., Zhu, Y ., Gao, C., Feng, Y ., Liu, Q., Zhu, Y ., and Stone, P. Libero: Benchmarking knowledge transfer for lifelong robot learning.NeurIPS, 36:44776–44791, 2023a. Liu, H., Li, C., Wu, Q., and Lee, Y . J. Visual instruction tuning.NeurIPS, 36:34892–34916, 2023b. Liu, J., Chen, H., An, P., Liu, Z., Zhang, R., Gu, C., Li, X., Guo, Z., Chen, S., Liu,...
-
[34]
Luo, H., Wang, Y ., Zhang, W., Yuan, H., Feng, Y ., Xu, H., Zheng, S., and Lu, Z. Joint-aligned latent action: To- wards scalable vla pretraining in the wild.arXiv preprint arXiv:2602.21736,
-
[35]
13 From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation [ICML 2026] Lyu, J., Liu, K., Zhang, X., Liao, H., Feng, Y ., Zhu, W., Shen, T., Chen, J., Zhang, J., Dong, Y ., et al. Lda-1b: Scaling latent dynamics action model via universal em- bodied data ingestion.arXiv preprint arXiv:2602.12215,
-
[36]
Ma, T., Zheng, J., Wang, Z., Jiang, C., Cui, A., Liang, J., and Yang, S. Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control.arXiv preprint arXiv:2603.10448,
-
[37]
Ma, X., Xing, L., Zhang, H., Li, W., and Lu, S. Unify- ing perception and action: A hybrid-modality pipeline with implicit visual chain-of-thought for robotic action generation.arXiv preprint arXiv:2511.19859,
-
[38]
Pai, J., Achenbach, L., Montesinos, V ., Forrai, B., Mees, O., and Nava, E. mimic-video: Video-action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692,
-
[39]
Peng, B., Zhang, W., Xu, L., Qi, Z., Zhang, J., Liu, H., Zeng, W., and Jin, X. Reworld: Multi-dimensional reward modeling for embodied world models.arXiv preprint arXiv:2601.12428,
-
[40]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V ., Hu, Y .-T., Hu, R., Ryali, C., Ma, T., Khedr, H., R ¨adle, R., Rolland, C., Gustafson, L., et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Transformer-based world models are happy with 100k interactions.ICLR,
14 From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation [ICML 2026] Robine, J., H ¨oftmann, M., Uelwer, T., and Harmeling, S. Transformer-based world models are happy with 100k interactions.ICLR,
work page 2026
-
[42]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zouitine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., et al. Smolvla: A vision-language- action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844,
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Song, H., Qu, D., Yao, Y ., Chen, Q., Lv, Q., Tang, Y ., Shi, M., Ren, G., Yao, M., Zhao, B., et al. Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432,
-
[44]
Vla-jepa: Enhancing vision-language-action model with latent world model, 2026
Sun, J., Zhang, W., Qi, Z., Ren, S., Liu, Z., Zhu, H., Sun, G., Jin, X., and Chen, Z. Vla-jepa: Enhancing vision- language-action model with latent world model.arXiv preprint arXiv:2602.10098,
-
[45]
AnyPos: Automated Task-Agnostic Actions for Bimanual Manipulation
Tan, H., Feng, Y ., Mao, X., Huang, S., Liu, G., Hao, Z., Su, H., and Zhu, J. Anypos: Automated task-agnostic actions for bimanual manipulation.arXiv preprint arXiv:2507.12768, 2025a. Tan, H., Zhou, E., Li, Z., Xu, Y ., Ji, Y ., Chen, X., Chi, C., Wang, P., Jia, H., Ao, Y ., et al. Robobrain 2.5: Depth in sight, time in mind.arXiv preprint arXiv:2601.14352,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Interactive post-training for vision-language- action models, 2025
Tan, S., Dou, K., Zhao, Y ., and Kr¨ahenb¨uhl, P. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025b. Team, G. R., Abeyruwan, S., Ainslie, J., Alayrac, J.-B., Arenas, M. G., Armstrong, T., Balakrishna, A., Baruch, R., Bauza, M., Blokzijl, M., et al. Gemini robotics: Bringing ai into the physical world.arXiv ...
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Wang, X., Zhu, Z., Huang, G., Wang, B., Chen, X., and Lu, J. WorldDreamer: Towards general world models for video generation via predicting masked tokens.arXiv preprint arXiv:2401.09985,
-
[50]
Z., Shen, C., Cheng, L., Li, Y ., Gao, T., and Zhang, D
Wu, W., Li, Z., He, Y ., Shou, M. Z., Shen, C., Cheng, L., Li, Y ., Gao, T., and Zhang, D. Paragraph-to-image generation with information-enriched diffusion model.International Journal of Computer Vision, pp. 1–22, 2025a. Wu, Z., Zhou, Y ., Xu, X., Wang, Z., and Yan, H. Moma- nipvla: Transferring vision-language-action models for general mobile manipulati...
-
[51]
Yang, J., Shi, Y ., Zhu, H., Liu, M., Ma, K., Wang, Y ., Wu, G., He, T., and Wang, L. Como: Learning continuous latent motion from internet videos for scalable robot learning. arXiv preprint arXiv:2505.17006, 2025a. Yang, J., Shi, Y ., Zhu, H., Liu, M., Ma, K., Wang, Y ., Wu, G., He, T., and Wang, L. Como: Learning continuous latent motion from internet v...
-
[52]
World Action Models are Zero-shot Policies
Ye, S., Ge, Y ., Zheng, K., Gao, S., Yu, S., Kurian, G., Indupuru, S., Tan, Y . L., Zhu, C., Xiang, J., et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026b. Yuan, C., Zhou, R., Liu, M., Hu, Y ., Wang, S., Yi, L., Zhang, S., Wen, C., and Gao, Y . Motiontrans: Human VR data en- able motion-level learning for robotic mani...
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
URL https: //openreview.net/forum?id=vr91mXmRHS. Yuan, T., Dong, Z., Liu, Y ., and Zhao, H. Fast-wam: Do world action models need test-time future imagination? arXiv preprint arXiv:2603.16666,
work page internal anchor Pith review arXiv
-
[54]
Igniting vlms toward the embodied space.arXiv preprint arXiv:2509.11766, 2025
Zhai, A., Liu, B., Fang, B., Cai, C., Ma, E., Yin, E., Wang, H., Zhou, H., Wang, J., Shi, L., et al. Igniting vlms toward the embodied space.arXiv preprint arXiv:2509.11766,
-
[55]
Grape: Gen- eralizing robot policy via preference alignment.arXiv preprint arXiv:2411.19309, 2024c
16 From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation [ICML 2026] Zhang, Z., Zheng, K., Chen, Z., Jang, J., Li, Y ., Han, S., Wang, C., Ding, M., Fox, D., and Yao, H. Grape: Gen- eralizing robot policy via preference alignment.arXiv preprint arXiv:2411.19309, 2024c. Zhao, Q., Lu, Y ., Kim, M. J., Fu, Z., Zhang, Z...
-
[56]
Flare: Robot learning with implicit world modeling, 2025
Zheng, R., Wang, J., Reed, S., Bjorck, J., Fang, Y ., Hu, F., Jang, J., Kundalia, K., Lin, Z., Magne, L., et al. Flare: Robot learning with implicit world modeling.arXiv preprint arXiv:2505.15659, 2025b. Zhou, J., Ma, T., Lin, K.-Y ., Wang, Z., Qiu, R., and Liang, J. Mitigating the human-robot domain discrepancy in visual pre-training for robotic manipula...
-
[57]
17 From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation [ICML 2026] A. Appendix A.1. Training, inference, and model details Table 6.Dataset statistics in the video generation model pretraining.Number of trajectories used from each dataset during video generation model pretraining. Training dataset mixture Trajector...
work page 2026
-
[58]
14,347 Video generation model pretraining details.During the pretraining of the video generation model, we used a mixture of human manipulation datasets and robotic video datasets, including Something-something-v2 (Goyal et al., 2017), RT-1 (Brohan et al., 2022), Bridge (Ebert et al., 2021), CALVIN (Mees et al., 2022), LIBERO (Liu et al., 2023a), and LIBE...
work page 2017
-
[59]
This measurement corresponds to the same model configuration used throughout the paper
benchmark and report the model size. This measurement corresponds to the same model configuration used throughout the paper. All experiments in Table 8 are conducted on an NVIDIA GeForce RTX 4090 GPU, with each component’s timing averaged over five runs. Real-world inference cost.The remaining experiments use the same model configuration and 256×256 visua...
work page 2026
-
[60]
In contrast, the RT series (Brohan et al., 2022; Zitkovich et al., 2023; Belkhale et al.,
demonstrating strong generalization capabilities. In contrast, the RT series (Brohan et al., 2022; Zitkovich et al., 2023; Belkhale et al.,
work page 2022
-
[61]
pioneers the fine-tuning of multimodal large language models on robot demonstrations, achieving strong performance in both accuracy and generalization, and inspiring numerous subsequent improvements (Li et al., 2023; Black et al., 2025; Team et al., 2024; Kim et al., 2024; Li et al., 2024a; Lin et al., 2025; Zhang et al., 2024a; Wen et al., 2025b; Qu et a...
work page 2023
-
[62]
that enable agents to predict future states and make informed decisions. Recent advances have significantly improved the scalability and expressiveness of world models by adopting transformer-based architectures capable of modeling long-horizon dynamics (Wu et al., 2025a; Robine et al., 2023; Micheli et al., 2023). These developments establish world model...
work page 2023
-
[63]
as a core mechanism for robotic action prediction and control. In robotics, several works directly employ video generation models as policy backbones, decoding actions through tracking, inverse dynamics, or future-state matching (Black et al., 2023; Du et al., 2024; Yang et al., 2024b; Hu et al., 2025a; Liang et al., 2024; Liao et al., 2025; Tan et al., 2...
work page 2023
-
[64]
and Quest (Mete et al., 2024). To exploit unlabeled videos, several works infer latent actions from visual dynamics by coupling inverse and forward dynamics models, learning latent variables that explain next-frame transitions (Rybkin et al., 2019; Edwards et al., 2019; Bruce et al., 2024; Bu et al., 2025a). Genie (Bruce et al.,
work page 2024
-
[65]
introduce unsupervised pretraining schemes for learning discrete latent actions within Vision–Language–Action models, enabling knowledge transfer from large-scale human videos. Most visual latent action models (Ma et al., 2025; Fan et al., 2025; Li et al., 2025f; Yang et al., 2025e) rely on RGB reconstruction, which inevitably captures task-irrelevant app...
work page 2025
-
[66]
further incorporates sparse action labels to bias latent representations toward controllable robotic behaviors. Future-aware control and representation learningRecent work on future-aware control spans both world action models and VLA-style future-aware representation learning. Within the world action model literature, VPP (Hu et al., 2025a), mimic-video ...
work page 2025
-
[67]
couple the two more tightly through unified architectures. A parallel direction uses a single model to jointly generate future video and action, as exemplified by Unified Video Action Model (Li et al., 2025b), DreamZero (Ye et al., 2026b), GigaWorld-Policy (Ye et al., 2026a), and Cosmos Policy (Kim et al., 2026). Vidar (Feng et al., 2025b) and Large Video...
work page 2026
-
[68]
and LDA-1B (Lyu et al., 2026), while Fast-W AM (Yuan et al.,
work page 2026
-
[69]
combines large-scale robot-video pretraining with latent-action, but its latent action tokenization primarily serves as an auxiliary signal for shaping the representations learned 22 From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation [ICML 2026] by a large video-language model during pretraining. By contrast, MoL...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.