Recognition: unknown
MathAgent: Adversarial Evolution of Constraint Graphs for Mathematical Reasoning Data Synthesis
Pith reviewed 2026-05-10 15:18 UTC · model grok-4.3
The pith
Adversarial evolution of constraint graphs synthesizes math reasoning data that lets 1K fine-tuning samples beat standard datasets on eight benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
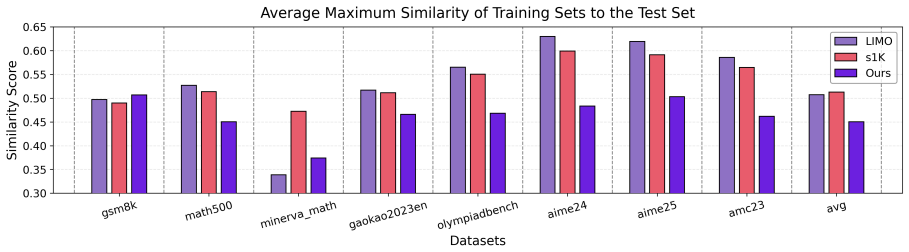
Formulating data synthesis as adversarial optimization over constraint graphs in a Legislator-Executor setup produces training examples with higher logical complexity and diversity than prior mutation or prompting methods, so that models fine-tuned on one thousand such examples outperform models trained on LIMO or s1K across eight mathematical reasoning benchmarks while showing improved out-of-distribution performance.
What carries the argument
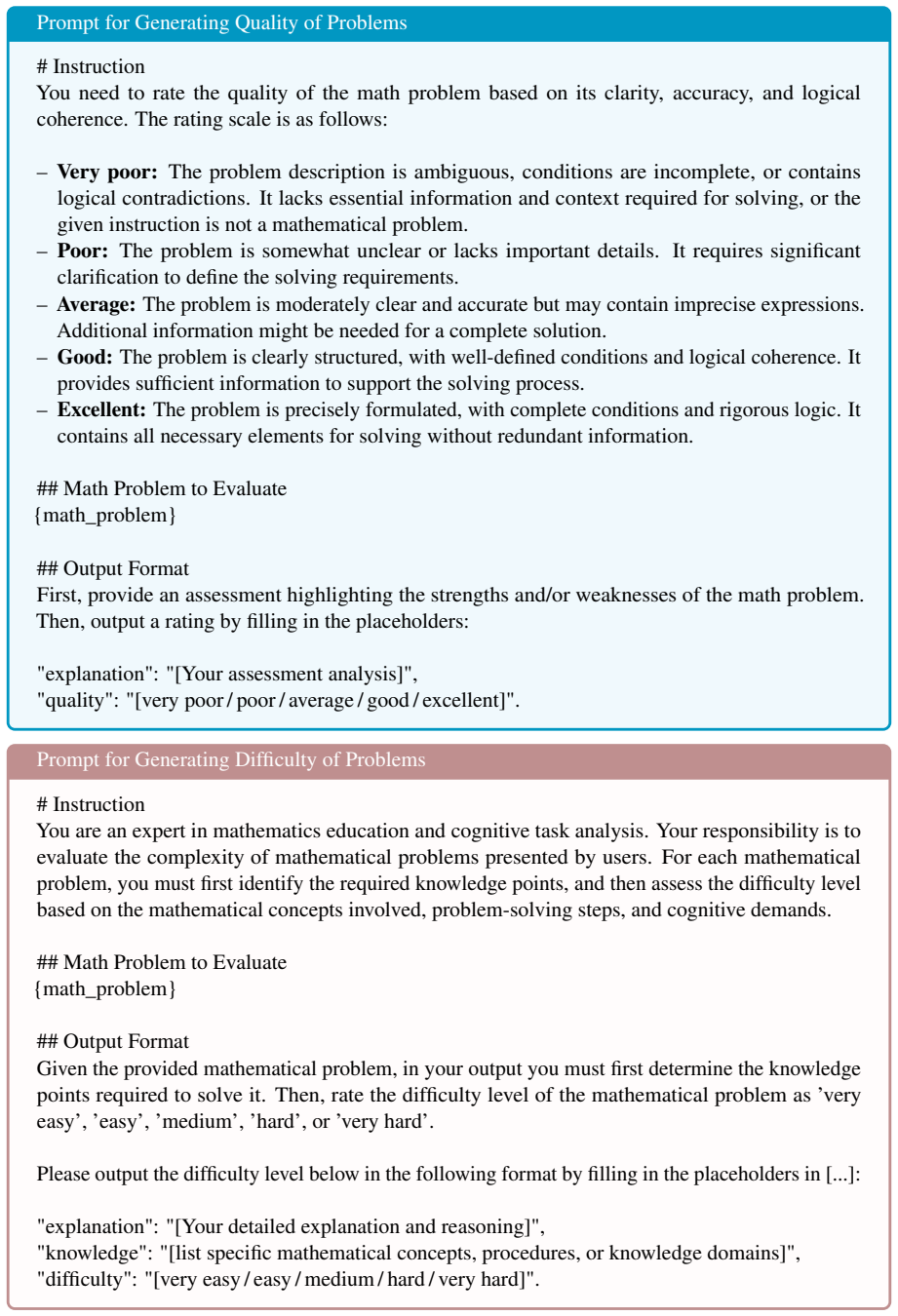
The Legislator-Executor paradigm in which the Legislator adversarially evolves constraint graphs as generation blueprints encoding problem constraints, and the Executor instantiates those graphs into natural language scenarios.
If this is right
- Smaller synthesized datasets can replace or exceed larger human-curated or mutated ones for mathematical fine-tuning.
- Data synthesis can be reframed as optimization over logical constraint structures instead of direct text generation.
- The resulting models exhibit stronger generalization on unseen mathematical problems compared with baselines.
- The approach scales across multiple model families including Qwen, Llama, Mistral, and Gemma.
Where Pith is reading between the lines
- The same graph-evolution loop could be tested on code or scientific reasoning tasks to check whether logical structure quality transfers.
- If constraint graphs capture the essential reasoning skeleton, they may reduce the volume of human-annotated data needed for training capable reasoners.
- Running the synthesis at even smaller scales, such as a few hundred samples, would test the lower bound on data volume required for strong benchmark gains.
Load-bearing premise
Adversarially evolving constraint graphs without human priors will reliably produce more complex and diverse logical structures than seed mutation or prompt engineering.
What would settle it
Fine-tuning the same models on one thousand samples from this method and finding no improvement over LIMO or s1K scores on the eight benchmarks, especially on out-of-distribution tests.
Figures









read the original abstract
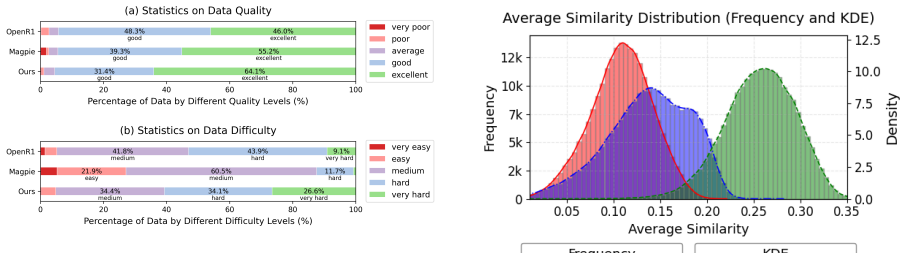
Synthesizing high-quality mathematical reasoning data without human priors remains a significant challenge. Current approaches typically rely on seed data mutation or simple prompt engineering, often suffering from mode collapse and limited logical complexity. This paper proposes a hierarchical synthesis framework that formulates data synthesis as an unsupervised optimization problem over a constraint graph followed by semantic instantiation, rather than treating it as a direct text generation task. We introduce a Legislator-Executor paradigm: The Legislator adversarially evolves structured generation blueprints encoding the constraints of the problem, while the Executor instantiates these specifications into diverse natural language scenarios. This decoupling of skeleton design from linguistic realization enables a prioritized focus on constructing complex and diverse logical structures, thereby guiding high-quality data synthesis. Experiments conducted on a total of 10 models across the Qwen, Llama, Mistral, and Gemma series demonstrate that our method achieves notable results: models fine-tuned on 1K synthesized samples outperform widely-used datasets of comparable scale (LIMO, s1K) across eight mathematical benchmarks, exhibiting superior out-of-distribution generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MathAgent, a hierarchical framework for synthesizing mathematical reasoning data without human priors. It formulates synthesis as unsupervised optimization over constraint graphs using a Legislator-Executor paradigm: the Legislator adversarially evolves structured blueprints encoding logical constraints, while the Executor instantiates them into natural language scenarios. The central empirical claim is that fine-tuning 10 models (Qwen, Llama, Mistral, Gemma series) on 1K synthesized samples outperforms widely-used datasets of similar scale (LIMO, s1K) across eight mathematical benchmarks and exhibits superior out-of-distribution generalization.
Significance. If the results hold after proper validation, the work could be significant for automated data synthesis in mathematical reasoning. By decoupling constraint-graph evolution from linguistic realization, it targets mode collapse and limited logical complexity in prior methods, potentially enabling more efficient, scalable generation of high-quality training data that improves LLM generalization on math tasks.
major comments (3)
- [Abstract] Abstract: the headline result (1K samples outperforming LIMO/s1K on eight benchmarks with better OOD generalization) is presented without methodological details, baseline comparisons, statistical tests, or error analysis, so the central claim cannot be evaluated from the given text.
- [Method] Method (Legislator-Executor paradigm): the claim that adversarial evolution of constraint graphs reliably yields higher structural complexity and diversity than seed mutation or prompt engineering lacks any quantitative metrics on graph properties (e.g., average constraint depth, number of interdependent variables, logical step count).
- [Experiments] Experiments: no ablations isolate the adversarial Legislator component from the overall framework, Executor instantiation, or synthesis-model strength; without them, performance gains cannot be attributed to the claimed mechanism rather than incidental factors such as topic coverage.
minor comments (1)
- [Abstract] Abstract: the phrase 'notable results' is vague; specific deltas, benchmark names, and significance levels should be stated.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address each major comment point by point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline result (1K samples outperforming LIMO/s1K on eight benchmarks with better OOD generalization) is presented without methodological details, baseline comparisons, statistical tests, or error analysis, so the central claim cannot be evaluated from the given text.
Authors: We agree the abstract is concise and omits supporting details due to typical length limits. Methodological elements of the Legislator-Executor paradigm appear in Section 3, while baseline comparisons, statistical tests (paired t-tests with p-values), and error analysis (standard deviations across runs) are in Section 5. We will revise the abstract to briefly describe the framework and direct readers to the experiments for full evaluation details. revision: yes
-
Referee: [Method] Method (Legislator-Executor paradigm): the claim that adversarial evolution of constraint graphs reliably yields higher structural complexity and diversity than seed mutation or prompt engineering lacks any quantitative metrics on graph properties (e.g., average constraint depth, number of interdependent variables, logical step count).
Authors: The manuscript supports the claim via downstream gains and qualitative examples, but direct quantitative graph metrics are indeed absent. We will add these in revision, reporting average constraint depth, number of interdependent variables, and logical step counts for our method versus seed mutation and prompt engineering baselines in a new analysis subsection. revision: yes
-
Referee: [Experiments] Experiments: no ablations isolate the adversarial Legislator component from the overall framework, Executor instantiation, or synthesis-model strength; without them, performance gains cannot be attributed to the claimed mechanism rather than incidental factors such as topic coverage.
Authors: We recognize that component ablations are needed to attribute gains specifically to the adversarial Legislator. Current results compare full methods but lack targeted ablations. We will add experiments in revision that disable adversarial evolution (e.g., non-adversarial or fixed graphs) while holding the Executor and topics constant, to isolate its role and control for coverage. revision: yes
Circularity Check
No significant circularity; central claims rest on external benchmark comparisons
full rationale
The paper frames data synthesis as an unsupervised optimization over constraint graphs using a Legislator-Executor paradigm, then validates via fine-tuning 1K samples and measuring performance on eight external mathematical benchmarks against LIMO and s1K. No equations or steps reduce the claimed superiority to a self-definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. The adversarial evolution is presented as a methodological choice whose efficacy is tested empirically rather than assumed by construction. The derivation chain remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adversarial evolution of constraint graphs produces logically complex and diverse structures superior to human priors or simple mutations.
Forward citations
Cited by 2 Pith papers
-
Grounding Multi-Hop Reasoning in Structural Causal Models via Group Relative Policy Optimization
SCM-GRPO grounds multi-hop fact verification in structural causal models and applies GRPO reinforcement learning to optimize reasoning chain length, outperforming baselines on HoVer and EX-FEVER.
-
Grounding Multi-Hop Reasoning in Structural Causal Models via Group Relative Policy Optimization
The SCM-GRPO framework models multi-hop fact verification as causal inference and applies reinforcement learning to optimize reasoning depth, reporting outperformance on HoVer and EX-FEVER.
Reference graph
Works this paper leans on
-
[1]
InThe Twelfth International Conference on Learning Representations
Alpagasus: Training a better alpaca with fewer data. InThe Twelfth International Conference on Learning Representations. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sas...
-
[2]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Sirui Chen, Changxin Tian, Binbin Hu, Kunlong Chen, Ziqi Liu, Zhiqiang Zhang, and Jun Zhou. 2025. Ar- rows of math reasoning data synthesis for large lan- guage models: Diversity, complexity and correctness. InProceedings of the 34th ACM International Con- ference on Information ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhi- hong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025a. Deepseek-r1: Incentivizing rea...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Neural tangent kernel: Convergence and gen- eralization in neural networks. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc. Albert Q. Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guil- laume Lample, Lucile Saulnier, Lélio...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Gemma 2: Improving Open Language Models at a Practical Size
IEEE. Jun Rao, Yunjie Liao, Xuebo Liu, Zepeng Lin, Lian Lian, Dong Jin, Shengjun Cheng, Jun Yu, and Min Zhang. 2025a. Seapo: Strategic error amplification for robust preference optimization of large language models. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025. Association for Computational Linguistics. Jun Rao, Zepeng Lin, Xu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Concept: Descrip- tion
datasets as high-quality baselines. These datasets are constructed through expert-designed pipelines and rigorous screening to ensure reason- ing depth, representing the state-of-the-art in small- scale, curated reasoning data. For s1K, which of- fers two reasoning model versions based onGemini (Google, 2024) and DeepSeek-R1 (DeepSeek-AI et al., 2025a) re...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.