Recognition: unknown
3D-Anchored Lookahead Planning for Persistent Robotic Scene Memory via World-Model-Based MCTS
Pith reviewed 2026-05-10 15:00 UTC · model grok-4.3
The pith
3D-Anchored Lookahead Planning keeps a fixed world coordinate anchor so robots can plan reaches to objects hidden by occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
3D-ALP maintains a persistent camera-to-world anchor inside an MCTS planner whose rollouts are generated by a 3D-consistent world model, allowing accurate value estimates and replanning for targets that are no longer visible in the current camera frame.
What carries the argument
The persistent camera-to-world (c2w) anchor combined with the 3D-consistent world model as the MCTS rollout oracle.
Load-bearing premise
The 3D-consistent world model keeps accurate object positions even after they are occluded and the adapted UCT-MCTS produces stable value estimates in continuous action spaces.
What would settle it
Running the same five-step task with the world model replaced by a purely reactive policy that sees only the current camera frame would drop memory-step success rates to near zero.
Figures

read the original abstract
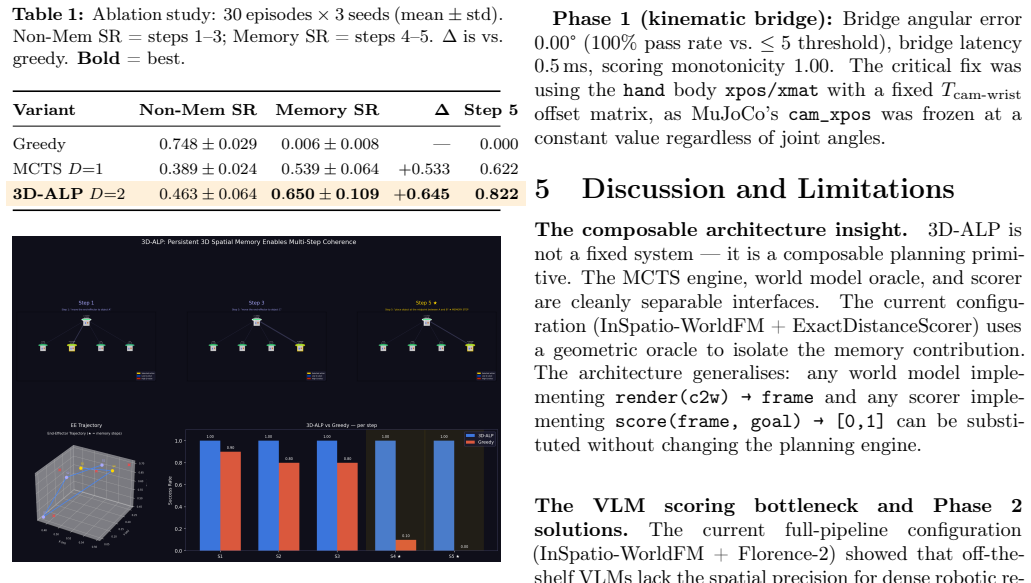
We present 3D-Anchored Lookahead Planning (3D-ALP), a System 2 reasoning engine for robotic manipulation that combines Monte Carlo Tree Search (MCTS) with a 3D-consistent world model as the rollout oracle. Unlike reactive policies that evaluate actions from the current camera frame only, 3D-ALP maintains a persistent camera-to-world (c2w) anchor that survives occlusion, enabling accurate replanning to object positions that are no longer directly observable. On a 5-step sequential reach task requiring spatial memory (Experiment E3), 3D-ALP achieves 0.650 0.109 success rate on memory-required steps versus 0.006 0.008 for a greedy reactive baseline ({\Delta}=+0.645), while step 5 success reaches 0.822 against 0.000 for greedy. An ablation study (30 episodes, 3 seeds) isolates tree search spatial memory as the primary driver (+0.533, 82% of gain) with additional benefit from deeper lookahead (+0.111, 17%). We also identify and resolve four structural failure modes in applying UCT-MCTS (Upper Confidence Bounds applied to Trees [10]) to continuous robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 3D-Anchored Lookahead Planning (3D-ALP), which augments Monte Carlo Tree Search (MCTS) with a 3D-consistent world model and a persistent camera-to-world (c2w) anchor to support robotic manipulation tasks that require spatial memory across occlusions. Unlike reactive greedy policies, 3D-ALP performs lookahead planning in a stable 3D frame. On a 5-step sequential reach task (Experiment E3), it reports 0.650 ± 0.109 success on memory-required steps versus 0.006 ± 0.008 for the baseline, with step-5 success of 0.822 versus 0.000. An ablation on 30 episodes across 3 seeds attributes +0.533 (82%) of the gain to tree-search spatial memory and +0.111 (17%) to deeper lookahead. The work also identifies and resolves four structural failure modes when applying UCT-MCTS to continuous robotic action spaces.
Significance. If the central assumptions hold, the approach offers a concrete mechanism for System-2-style lookahead in robotics that can maintain accurate beliefs about occluded objects, yielding large empirical gains on memory-dependent tasks. The provision of standard errors, a quantitative ablation isolating the memory component, and explicit treatment of MCTS failure modes are strengths that would make the result reproducible and extensible if the world-model accuracy is confirmed.
major comments (2)
- [Experiment E3] Experiment E3 and ablation study: the headline delta (+0.645 success rate on memory-required steps) is attributed to the persistent c2w anchor enabling accurate MCTS rollouts to occluded object positions. No quantitative tracking error (e.g., mean position RMSE versus simulator ground truth for occluded objects) or noise-injection ablation into the rollout oracle is reported. Without this, the performance gain cannot be cleanly credited to 3D-anchored lookahead rather than an idealized simulator world model.
- [MCTS failure modes discussion] Section on UCT-MCTS failure modes: the manuscript states that four structural failure modes were identified and resolved to produce reliable value estimates in continuous action spaces, yet provides no explicit verification, ablation, or metric showing that the proposed fixes systematically eliminate those modes under the experimental conditions. This verification is load-bearing for the claim that the resolved MCTS variants are reliable.
minor comments (2)
- [Abstract] Abstract: success rates are written as '0.650 0.109' and '0.006 0.008' without the ± symbol or consistent formatting; standardize to conventional statistical reporting.
- [Ablation study] Ablation study: the protocol states 30 episodes and 3 seeds, but it is unclear whether these numbers apply uniformly to all reported results (including the main E3 comparison) or only to the ablation; explicit statement would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to improve the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Experiment E3] Experiment E3 and ablation study: the headline delta (+0.645 success rate on memory-required steps) is attributed to the persistent c2w anchor enabling accurate MCTS rollouts to occluded object positions. No quantitative tracking error (e.g., mean position RMSE versus simulator ground truth for occluded objects) or noise-injection ablation into the rollout oracle is reported. Without this, the performance gain cannot be cleanly credited to 3D-anchored lookahead rather than an idealized simulator world model.
Authors: We agree that the manuscript would be strengthened by direct quantitative evidence of world-model accuracy on occluded objects. The existing ablation already isolates the tree-search spatial memory component (+0.533 success, 82% of total gain) as the primary driver, which depends on the persistent c2w anchor for rollout accuracy. In the revised version we will add (i) mean position RMSE of the world-model predictions versus simulator ground truth specifically for occluded objects in Experiment E3 and (ii) a noise-injection ablation into the rollout oracle. These additions will allow readers to evaluate the fidelity of the 3D world model independently of the planning gains. revision: yes
-
Referee: [MCTS failure modes discussion] Section on UCT-MCTS failure modes: the manuscript states that four structural failure modes were identified and resolved to produce reliable value estimates in continuous action spaces, yet provides no explicit verification, ablation, or metric showing that the proposed fixes systematically eliminate those modes under the experimental conditions. This verification is load-bearing for the claim that the resolved MCTS variants are reliable.
Authors: We acknowledge that while the manuscript describes the four identified failure modes and the resolutions applied, it does not include explicit quantitative verification (e.g., before/after metrics on value-estimate reliability or failure-mode incidence) under the reported experimental conditions. In the revision we will add targeted analysis, such as metrics quantifying the reduction in each failure mode and the resulting improvement in value-estimate stability, evaluated on the same 30-episode, 3-seed setup used for the ablation study. This will provide the requested load-bearing evidence for the reliability of the resolved MCTS variants. revision: yes
Circularity Check
No circularity; empirical results independent of self-defined quantities
full rationale
The paper reports success rates and ablation deltas from direct experimental comparisons (E3 task, 30 episodes, 3 seeds) against a greedy baseline and internal variants. No equations, fitted parameters, or predictions are presented that reduce the claimed gains (+0.645 overall, +0.533 from tree search) to quantities defined by the method itself. The 3D c2w anchor and MCTS rollout oracle are evaluated via external task metrics rather than by construction or self-citation chains. The derivation chain consists of algorithmic description plus empirical measurement and is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A 3D-consistent world model can accurately predict scene states from actions even under occlusion
- domain assumption UCT-MCTS can be made effective for continuous robotic manipulation once four structural failure modes are resolved
invented entities (1)
-
persistent camera-to-world (c2w) anchor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
G. Best, O. Cliff, T. Patten, R. Mettu, and R. Fitch. Dec-mcts: Decentralized planning for multi-robot active perception.International Journal of Robotics Research, 38(2–3):316–337, 2019
2019
-
[2]
Bhatt et al
S. Bhatt et al. Aligning robots’ uncertainty with inherent task ambiguity. InNeurIPS, 2024
2024
-
[3]
GigaBrain Team. GigaBrain-0.5M*: A VLA that learns from world model-based reinforcement learn- ing.arXiv preprint arXiv:2602.12099, 2026
-
[4]
Gigaworld-0: World models as data engine to empower embodied ai,
GigaWorld Team. Gigaworld-0: World models as data engine to empower embodied AI.arXiv preprint arXiv:2511.19861, 2025
- [5]
-
[6]
Mastering Diverse Domains through World Models
D. Hafner et al. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
Hansen, H
N. Hansen, H. Su, and X. Wang. Td-mpc2: Scalable, robust world models for continuous control. InIn- ternational Conference on Learning Representations (ICLR), 2024
2024
-
[8]
M. Jaderberg et al. Population based training of neural networks.arXiv preprint arXiv:1711.09846, 2017
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
M. Kim et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Kocsis and C
L. Kocsis and C. Szepesvári. Bandit based monte- carlo planning. InEuropean Conference on Machine Learning (ECML), pages 282–293, 2006
2006
-
[11]
Lauri, D
M. Lauri, D. Hsu, and J. Pajarinen. Partially ob- servable markov decision processes in robotics: A survey.IEEE Transactions on Robotics, 2023
2023
-
[12]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human-in-the- loop reinforcement learning.Science Robotics, 2024
2024
-
[13]
L. Maes, Q. Le Lidec, D. Scieur, Y. LeCun, and R. Balestriero. Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels. arXiv preprint arXiv:2603.19312, 2026. [14]π 0 Team.π 0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164, 2024
-
[14]
Schadd, M
M. Schadd, M. Winands, H. van den Herik, G. Chaslot, and J. Uiterwijk. Single-player monte- carlo tree search. InComputers and Games, pages 1–12, 2008. 5
2008
-
[15]
Schrittwieser et al
J. Schrittwieser et al. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588:604–609, 2020
2020
-
[16]
VLMs Need Words: Vision Language Models Ignore Visual Detail In Favor of Semantic Anchors
H.S. Shahgir, X. Chen, Y. Fu, E. Shayegani, N. Abu- Ghazaleh, Y. Kementchedjhieva, and Y. Dong. Vlms need words: Vision language models ignore visual detail in favor of semantic anchors.arXiv preprint arXiv:2604.02486, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Silver et al
D. Silver et al. Mastering the game of go with deep neural networks and tree search.Nature, 529(7587):484–489, 2016
2016
-
[18]
Snoek, H
J. Snoek, H. Larochelle, and R. Adams. Practi- cal bayesian optimization of machine learning algo- rithms. InNeurIPS, 2012
2012
-
[19]
Xiao et al
B. Xiao et al. Florence-2: Advancing a unified repre- sentation for a variety of vision tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
- [20]
-
[21]
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
X. Zhang et al. Inspatio-worldfm: An open-source real-time generative frame model.arXiv preprint arXiv:2603.11911, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Z. Zhou et al. Dino-wm: World models on pre- trained visual features enable zero-shot planning. arXiv preprint arXiv:2411.04983, 2024. 6
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.