Recognition: unknown
Do LLMs Know Tool Irrelevance? Demystifying Structural Alignment Bias in Tool Invocations
Pith reviewed 2026-05-10 15:00 UTC · model grok-4.3
The pith
LLMs invoke tools whenever query attributes fit tool parameters, even if the tool cannot serve the query goal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
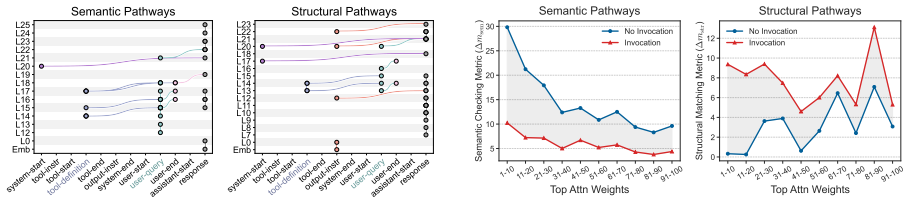
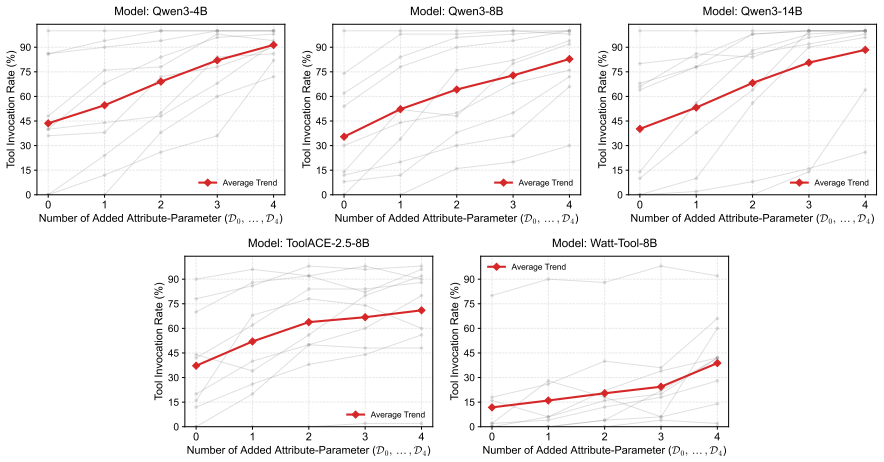
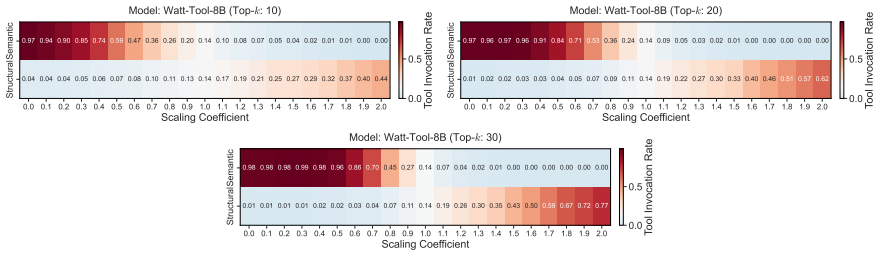
Structural alignment bias is the tendency of LLMs to invoke a tool as soon as its parameters can receive valid values from the query, regardless of whether the tool advances the user's goal. SABEval decouples this structural factor from semantic relevance and reveals that the bias drives most refusal failures. Contrastive Attention Attribution demonstrates that invocation decisions result from the relative strength of a semantic-checking pathway versus a structural-matching pathway. Rebalancing these pathways through targeted attention adjustment corrects the bias without harming performance on relevant tool calls.
What carries the argument
Structural alignment bias, the decision rule that triggers tool invocation on the basis of valid parameter assignment from the query rather than on goal relevance.
If this is right
- Standard tool-use benchmarks that do not control for structural similarity will systematically underestimate refusal errors.
- Rebalancing the relative strength of semantic and structural attention pathways reduces false invocations across tested models.
- The bias and its mitigation generalize without degrading performance on cases where tools are relevant.
- Contrastive attribution can be used to diagnose other decision biases that pit surface form against intent.
Where Pith is reading between the lines
- The same structural-matching shortcut may explain other LLM failures where surface patterns override intended meaning.
- Future tool benchmarks should routinely include structurally matched but semantically irrelevant distractors.
- Attention rebalancing techniques could apply to other internal conflicts between syntax and semantics in language models.
Load-bearing premise
That SABEval successfully isolates structural alignment from semantic relevance without other confounds and that the contrastive attribution method accurately identifies the two competing pathways.
What would settle it
If models continue to show high rates of erroneous invocations on structurally aligned but semantically irrelevant cases even after the rebalancing intervention, the claim that the bias is both measurable and mitigable would be falsified.
Figures























read the original abstract
Large language models (LLMs) have demonstrated impressive capabilities in utilizing external tools. In practice, however, LLMs are often exposed to tools that are irrelevant to the user's query, in which case the desired behavior is to refrain from invocations. In this work, we identify a widespread yet overlooked mechanistic flaw in tool refusal, which we term structural alignment bias: Even when a tool fails to serve the user's goal, LLMs still tend to invoke it whenever query attributes can be validly assigned to tool parameters. To systematically study this bias, we introduce SABEval, a new dataset that decouples structural alignment from semantic relevance. Our analysis shows that structural alignment bias induces severe tool-invocation errors in LLMs, yet remains largely unaccounted for in existing evaluations. To investigate the internal mechanisms underlying this bias, we propose Contrastive Attention Attribution, which reveals two competing pathways for semantic checking and structural matching. The relative strength of these pathways drives LLMs' tool invocation decisions. Based on these findings, we further introduce a rebalancing strategy that effectively mitigates structural alignment bias, as demonstrated by extensive experiments, without degrading general tool-use capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit a structural alignment bias in tool invocation: they tend to call tools when query attributes can be mapped to tool parameters structurally, even if the tool is semantically irrelevant to the query goal. To study this, the authors introduce SABEval, a dataset that decouples structural alignment from semantic relevance. Analysis via a new Contrastive Attention Attribution technique identifies two competing pathways (semantic checking and structural matching) whose relative strengths determine invocation decisions. Based on this, they propose a rebalancing strategy that mitigates the bias in experiments while preserving general tool-use performance.
Significance. If the empirical findings and mechanistic account hold, the work is significant for highlighting an overlooked failure mode in LLM tool use that existing benchmarks miss. SABEval is a useful new resource for evaluating tool irrelevance. The attention-based pathway analysis and rebalancing mitigation offer both diagnostic insight and a practical fix. Credit is given for the systematic dataset construction and the extensive experiments demonstrating mitigation without capability degradation.
major comments (2)
- [§4.2] §4.2 (Contrastive Attention Attribution): The identification of two competing pathways rests on correlational attention patterns from contrastive pairs in SABEval. Without intervention experiments (e.g., ablating or patching the attributed attention heads/layers to measure changes in refusal rates), the account does not establish that these pathways causally drive invocation decisions. This directly underpins the motivation and design of the rebalancing strategy in §6.
- [§3] §3 (SABEval construction): The dataset is presented as successfully isolating structural alignment from semantic relevance, but the paper does not report controls or ablations for potential confounds such as lexical overlap between query and tool descriptions or parameter-type matching. This affects whether the reported error rates can be attributed specifically to structural alignment bias rather than other factors.
minor comments (2)
- [Figure 4] Figure 4: The attention attribution visualizations would benefit from quantitative summaries (e.g., average attribution scores per pathway) in addition to the qualitative examples.
- [Related Work] Related work section: The discussion of prior tool-use evaluations could more explicitly contrast SABEval with existing irrelevance benchmarks to clarify the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the significance of identifying structural alignment bias in LLM tool use. We address each major comment below, outlining our responses and planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Contrastive Attention Attribution): The identification of two competing pathways rests on correlational attention patterns from contrastive pairs in SABEval. Without intervention experiments (e.g., ablating or patching the attributed attention heads/layers to measure changes in refusal rates), the account does not establish that these pathways causally drive invocation decisions. This directly underpins the motivation and design of the rebalancing strategy in §6.
Authors: We agree that the Contrastive Attention Attribution analysis relies on correlational patterns observed in attention weights across SABEval contrastive pairs, and that this does not constitute direct causal evidence via interventions such as head ablation or patching. The rebalancing strategy in §6 is motivated by these patterns and functions as an indirect test by down-weighting the structural matching pathway, which empirically reduces invocation errors while preserving tool-use performance. In the revision, we will update §4.2 to explicitly discuss the correlational nature of the findings as a limitation and clarify the empirical support provided by the rebalancing experiments. We will also add a brief discussion of potential future causal interventions. revision: partial
-
Referee: [§3] §3 (SABEval construction): The dataset is presented as successfully isolating structural alignment from semantic relevance, but the paper does not report controls or ablations for potential confounds such as lexical overlap between query and tool descriptions or parameter-type matching. This affects whether the reported error rates can be attributed specifically to structural alignment bias rather than other factors.
Authors: We thank the referee for highlighting these potential confounds. SABEval was constructed to isolate structural alignment (parameter compatibility) from semantic relevance (query-tool goal mismatch), but we did not include explicit ablations for lexical overlap or parameter-type matching in the reported results. In the revised manuscript, we will add controls and ablations in §3 (or a new appendix) that systematically vary lexical similarity and parameter-type consistency while holding other factors fixed, to better attribute the error rates to structural alignment bias specifically. revision: yes
Circularity Check
No circularity detected; derivation is empirically grounded in new dataset and methods
full rationale
The paper defines structural alignment bias from observed LLM behavior with irrelevant tools, introduces the independent SABEval dataset to decouple structural alignment from semantic relevance, proposes Contrastive Attention Attribution as an analysis technique to identify competing pathways, and derives the rebalancing strategy from those experimental findings. No steps reduce by construction to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. All central claims rest on new empirical measurements rather than tautological or self-referential reductions.
Axiom & Free-Parameter Ledger
invented entities (1)
-
structural alignment bias
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2501.12851 , year=
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083. Chen Chen, Xinlong Hao, Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Yuefeng Huang, and 1 others. 2025. Acebench: Who wins the match point in tool usage? arXiv preprint arXiv:2501.12851. Zili...
-
[2]
InProceedings of the 47th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pages 719–729
The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, pages 719–729. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024....
2024
-
[3]
Sam Houliston, Ambroise Odonnat, Charles Arnal, and Vivien Cabannes
How does gpt-2 compute greater-than?: In- terpreting mathematical abilities in a pre-trained lan- guage model.Advances in Neural Information Pro- cessing Systems, 36:76033–76060. Sam Houliston, Ambroise Odonnat, Charles Arnal, and Vivien Cabannes. 2025. Provable benefits of in-tool learning for large language models.arXiv preprint arXiv:2508.20755. Yue Hu...
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Yuxiang Zhang, Jing Chen, Junjie Wang, Yaxin Liu, Cheng Yang, Chufan Shi, Xinyu Zhu, Zihao Lin, Hanwen Wan, Yujiu Yang, Tetsuya Sakai, Tian Feng, and Hayato Yamana. 2024. ToolBeHonest: A multi- level hallucination diagnostic benchmark for tool- augmented large language models. InProceedings of the 20...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Derived Class Inclusion: Every generated query must contain the exact derived class name provided
-
[6]
- The expected parameter values must be specific and realistic
Parameter Constraints: - Each query must explicitly contain information for all and only the parameters of the tool. - The expected parameter values must be specific and realistic. Avoid vague values
-
[7]
No Attachments: Do not assume or pretend that files, images, audio clips, videos, or any other attachments are being provided
-
[8]
Quality: Generated queries must be solvable with the tool without requiring further clarification
-
[9]
query":
Diversity: - You should generate at least 5 distinct queries. - The queries should have varied sentence structures (e.g., imperative commands, interrogative queries). - The parameter values across different queries should also be diverse, covering a wide range of realistic scenarios, if applicable. Output Format: Return a single JSON array as follows: [ {...
-
[10]
Tool Template: An tool schema that uses'<class>'as a placeholder for a specific derived class
-
[11]
List of Derived Classes: A list of the specific derived class names that will eventually replace'<class>'
-
[12]
Design Principles: - The tool's purpose must remain clear and unambiguous after adding new parameters
Base Class Description: A brief explanation of the base class corresponding to the tool template. Design Principles: - The tool's purpose must remain clear and unambiguous after adding new parameters. - All parameter values would be provided by the user when invoke the tool, not generated or assumed by the LLM assistant. The LLM acts as a bridge to execut...
-
[13]
Universally Applicable: Each proposed parameter must be universally applicable and make sense for all derived classes provided
-
[14]
They cannot duplicate the functionality or name of any parameters already present in the tool template
Uniqueness: The proposed parameters must be entirely new. They cannot duplicate the functionality or name of any parameters already present in the tool template
-
[15]
Parameter description, however, should contain the'<class>'placeholder if it is contextually appropriate when replaced with a specific subclass
Placeholder Usage: Parameter names must be generic and must not contain the'<class>' placeholder. Parameter description, however, should contain the'<class>'placeholder if it is contextually appropriate when replaced with a specific subclass
-
[16]
Quantity: Generate at least four distinct and meaningful parameters
-
[17]
parameter_name_1
Type: New parameters should be simple types: string, integer, number, boolean or array of simple types. Do not propose complex nested structures. Output Format: Return a single JSON object as follows: {{"parameter_name_1": {{"type": "string", "description": "Description for param 1."}}, " parameter_name_2": {{"type": "integer", "description": "Description...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.