Recognition: unknown
Reasoning Resides in Layers: Restoring Temporal Reasoning in Video-Language Models with Layer-Selective Merging
Pith reviewed 2026-05-10 15:39 UTC · model grok-4.3
The pith
Temporal reasoning lost during visual adaptation in video-language models can be restored by selectively merging layers from the model and its text-only backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
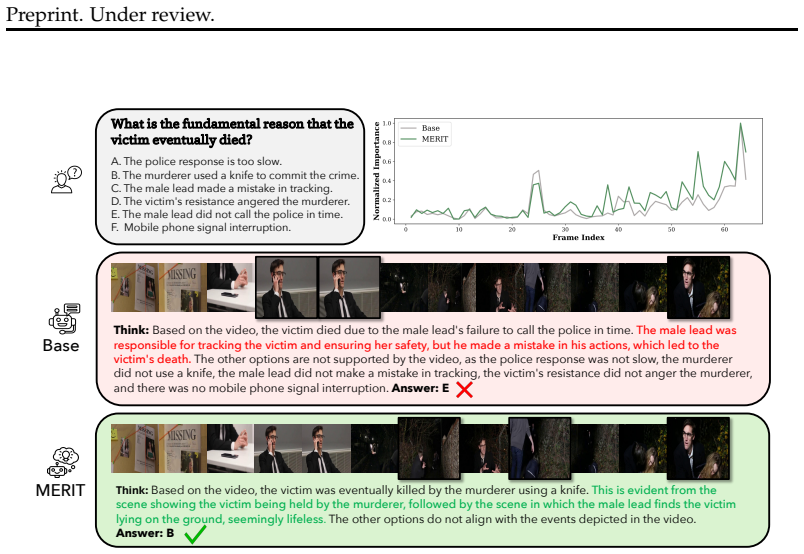
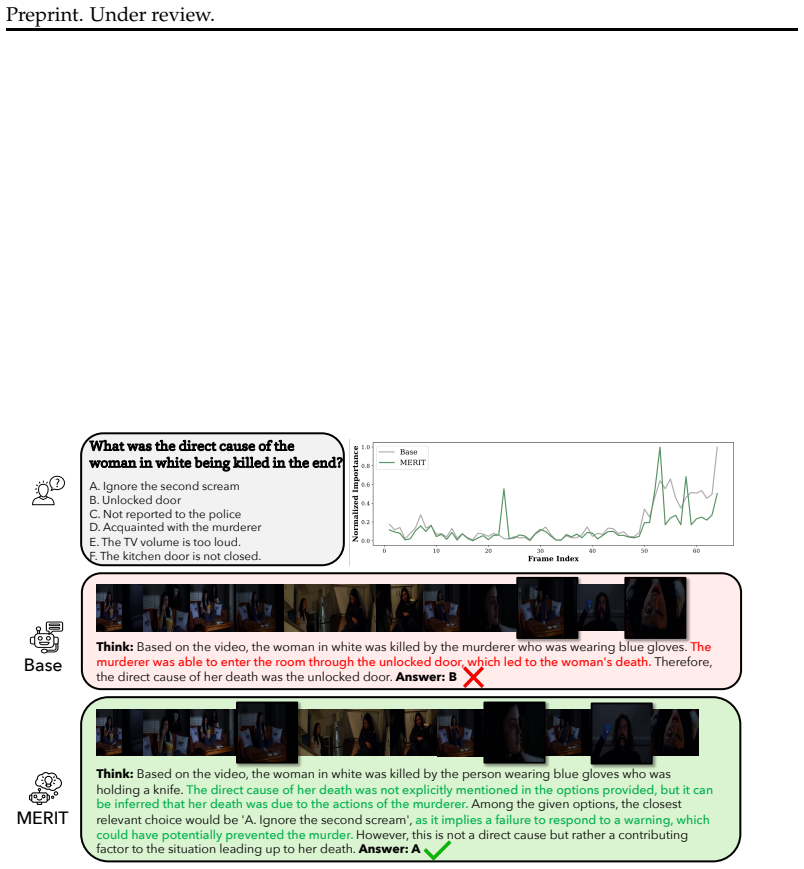
MERIT searches over layer-wise self-attention merging recipes between a VLM and its paired text-only backbone using an objective that improves TR while penalizing degradation in TP. Across three representative VLMs and multiple challenging video benchmarks, MERIT consistently improves TR, preserves or improves TP, and generalizes beyond the search set to four distinct benchmarks. It also outperforms uniform full-model merging and random layer selection. Interventional masking and frame-level attribution further show that the selected layers are disproportionately important for reasoning and shift model decisions toward temporally and causally relevant evidence.
What carries the argument
MERIT, the training-free task-driven model merging framework that identifies and applies selective layer-wise self-attention merges guided by a TR-improvement versus TP-degradation objective.
If this is right
- MERIT improves temporal reasoning across three VLMs and generalizes to four held-out benchmarks without retraining.
- The method preserves or improves temporal perception on the same tasks.
- Layer-selective merging outperforms both full-model uniform merging and random layer selection.
- Masking experiments show the selected layers matter more for reasoning decisions than other layers.
- Frame-level attribution reveals the merges shift attention toward causally relevant temporal evidence.
Where Pith is reading between the lines
- Similar layer-selective merging could be tested on other lost capabilities such as spatial or causal reasoning in multimodal models.
- The results imply that different reasoning skills localize in distinct layers and can be mixed in without full retraining.
- Extending the search objective to multiple paired backbones might allow recovery of several abilities at once.
- The approach suggests video-language models retain text-layer reasoning that can be selectively restored rather than overwritten.
Load-bearing premise
An objective that balances gains in temporal reasoning against losses in temporal perception will identify layer merges that generalize to new tasks and that those layers are causally responsible for the observed improvements.
What would settle it
Applying the discovered merging recipes to a new video benchmark or VLM architecture and measuring no improvement in temporal reasoning accuracy while TP remains unchanged would falsify the generalization and layer-causality claims.
Figures





read the original abstract
Multimodal adaptation equips large language models (LLMs) with perceptual capabilities, but often weakens the reasoning ability inherited from language-only pretraining. This trade-off is especially pronounced in video-language models (VLMs), where visual alignment can impair temporal reasoning (TR) over sequential events. We propose MERIT, a training-free, task-driven model merging framework for restoring TR in VLMs. MERIT searches over layer-wise self-attention merging recipes between a VLM and its paired text-only backbone using an objective that improves TR while penalizing degradation in temporal perception (TP). Across three representative VLMs and multiple challenging video benchmarks, MERIT consistently improves TR, preserves or improves TP, and generalizes beyond the search set to four distinct benchmarks. It also outperforms uniform full-model merging and random layer selection, showing that effective recovery depends on selecting the right layers. Interventional masking and frame-level attribution further show that the selected layers are disproportionately important for reasoning and shift model decisions toward temporally and causally relevant evidence. These results show that targeted, perception-aware model merging can effectively restore TR in VLMs without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MERIT, a training-free, task-driven model merging framework that searches for layer-wise self-attention merging recipes between a video-language model (VLM) and its text-only backbone. The search uses an objective that improves temporal reasoning (TR) while penalizing degradation in temporal perception (TP). Across three VLMs and multiple video benchmarks, MERIT reports consistent TR gains, preserved or improved TP, generalization to four held-out benchmarks, outperformance versus uniform full-model merging and random layer selection, and interventional evidence (masking and frame-level attribution) that the selected layers disproportionately support reasoning and shift decisions toward temporally relevant evidence.
Significance. If the central claims hold, the work is significant for offering a practical, retraining-free method to mitigate reasoning degradation in multimodal VLMs by exploiting layer-specific specialization. It provides empirical support for the idea that temporal reasoning and perception can be disentangled at the layer level, with potential implications for efficient adaptation of large models. The inclusion of interventional tests is a strength that helps move beyond correlational claims about layer importance.
major comments (2)
- [Abstract and §3] Abstract and §3 (MERIT framework): the claim that an objective balancing TR improvement against TP degradation reliably identifies generalizable, causally responsible layer-wise merge recipes is load-bearing for the headline result. The manuscript reports outperformance over uniform and random baselines but does not provide the explicit mathematical form of the objective, its hyperparameter sensitivity, or ablation on alternative balancing schemes, making it difficult to assess whether the selected recipes are robust or inadvertently tuned to the search set.
- [§4] §4 (Experiments) and generalization results: the assertion that MERIT generalizes beyond the search set to four distinct benchmarks and that effective recovery depends on selecting the right layers requires verification that the search set shares no hidden statistical structure with the held-out benchmarks and that the interventional masking/attribution isolates the effect of the merge coefficients rather than merely confirming layer importance in the unmerged VLM. Absence of error bars, multiple random seeds, and explicit exclusion criteria for benchmark selection weakens the support for these claims.
minor comments (2)
- [§2 and §3] Notation for the layer-wise merge coefficients and the precise definition of TR versus TP should be introduced earlier and used consistently to improve readability for readers outside the immediate subfield.
- [Figures in §4] Figure captions for the attribution and masking visualizations would benefit from additional detail on the exact procedure (e.g., how frames are masked and how attribution scores are aggregated) to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below with clarifications and commitments to revisions that improve transparency and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (MERIT framework): the claim that an objective balancing TR improvement against TP degradation reliably identifies generalizable, causally responsible layer-wise merge recipes is load-bearing for the headline result. The manuscript reports outperformance over uniform and random baselines but does not provide the explicit mathematical form of the objective, its hyperparameter sensitivity, or ablation on alternative balancing schemes, making it difficult to assess whether the selected recipes are robust or inadvertently tuned to the search set.
Authors: We agree that the explicit mathematical form, hyperparameter details, and alternative-scheme ablations are necessary for assessing robustness. While §3 describes the objective as improving TR while penalizing TP degradation and reports outperformance versus baselines, we will revise the section to present the precise formulation, add a sensitivity analysis over the balancing hyperparameter, and include ablations on alternatives such as different penalty structures. These additions will confirm the recipes are robust rather than tuned to the search set. revision: yes
-
Referee: [§4] §4 (Experiments) and generalization results: the assertion that MERIT generalizes beyond the search set to four distinct benchmarks and that effective recovery depends on selecting the right layers requires verification that the search set shares no hidden statistical structure with the held-out benchmarks and that the interventional masking/attribution isolates the effect of the merge coefficients rather than merely confirming layer importance in the unmerged VLM. Absence of error bars, multiple random seeds, and explicit exclusion criteria for benchmark selection weakens the support for these claims.
Authors: We appreciate the call for stronger verification. The search set uses temporal-reasoning QA tasks while held-out benchmarks are from distinct categories (action recognition, event localization) with no video overlap; we will add explicit selection criteria and dataset statistics to rule out hidden structure. The masking and attribution experiments are run on the merged model to isolate merge-coefficient effects, and we will clarify this distinction from unmerged baselines. We will also add error bars from multiple evaluation runs and results across random seeds for search and evaluation. These changes will strengthen the generalization evidence. revision: yes
Circularity Check
No significant circularity; empirical search over merging recipes with held-out evaluation.
full rationale
The paper presents MERIT as an empirical, training-free search procedure over layer-wise self-attention merge coefficients between a VLM and its text-only backbone. The search objective balances TR gains against TP degradation and is evaluated on external video benchmarks, with explicit generalization testing on four held-out sets plus comparisons to uniform and random baselines. Interventional masking and attribution are performed post-selection. No equations or claims reduce by construction to fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations or imported uniqueness theorems are invoked. The derivation chain consists of standard experimental steps whose outputs are not tautologically equivalent to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/abs/2511.21631. Jr-Jen Chen, Yu-Chien Liao, Hsi-Che Lin, Yu-Chu Yu, Yen-Chun Chen, and Yu-Chiang Frank Wang. Rextime: A benchmark suite for reasoning-across-time in videos.arXiv preprint arXiv:2406.19392,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Bring reason to vision: Understanding perception and reasoning through model merging
Shiqi Chen, Jinghan Zhang, Tongyao Zhu, Wei Liu, Siyang Gao, Miao Xiong, Manling Li, and Junxian He. Bring reason to vision: Understanding perception and reasoning through model merging.arXiv preprint arXiv:2505.05464,
-
[4]
Video-holmes: Can MLLM think like holmes for complex video reasoning?CoRR, abs/2505.21374, 2025
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-holmes: Can mllm think like holmes for complex video reasoning?arXiv preprint arXiv:2505.21374,
-
[5]
Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752,
Daniel Cores, Michael Dorkenwald, Manuel Mucientes, Cees GM Snoek, and Yuki M Asano. Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752,
-
[6]
Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, Meishan Zhang, Mong-Li Lee, and Wynne Hsu. Video-of-thought: Step-by-step video reasoning from perception to cognition. arXiv preprint arXiv:2501.03230,
-
[7]
Arcee’s MergeKit: A toolkit for merging large language models, 2024
Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vlad Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. Arcee’s mergekit: A toolkit for merging large language models.arXiv preprint arXiv:2403.13257,
-
[8]
How large language models encode context knowledge? a layer-wise probing study
Tianjie Ju, Weiwei Sun, Wei Du, Xinwei Yuan, Zhaochun Ren, and Gongshen Liu. How large language models encode context knowledge? a layer-wise probing study. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024),
2024
-
[9]
Temporal reasoning transfer from text to video.arXiv preprint arXiv:2410.06166, 2024a
Lei Li, Yuanxin Liu, Linli Yao, Peiyuan Zhang, Chenxin An, Lean Wang, Xu Sun, Ling- peng Kong, and Qi Liu. Temporal reasoning transfer from text to video.arXiv preprint arXiv:2410.06166, 2024a. Shengzhi Li, Rongyu Lin, and Shichao Pei. Multi-modal preference alignment reme- dies degradation of visual instruction tuning on language models.arXiv preprint ar...
-
[10]
Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pp
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pp. 8731–8772,
2024
-
[11]
URLhttps://arxiv.org/abs/2412.15115. Neale Ratzlaff, Man Luo, Xin Su, Vasudev Lal, and Phillip Howard. Training-free mitigation of language reasoning degradation after multimodal instruction tuning. InProceedings of the AAAI Symposium Series, volume 5, pp. 384–388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Tomato: Assessing visual temporal reasoning capabilities in multimodal foundation models,
Ziyao Shangguan, Chuhan Li, Yuxuan Ding, Yanan Zheng, Yilun Zhao, Tesca Fitzgerald, and Arman Cohan. Tomato: Assessing visual temporal reasoning capabilities in multimodal foundation models.arXiv preprint arXiv:2410.23266,
-
[13]
Haonan Wang, Weida Liang, Zihang Fu, Nie Zheng, Yifan Zhang, Yao Tong, Tongyao Zhu, Hao Jiang, Chuang Li, Jiaying Wu, and Kenji Kawaguchi. From harm to help: Turning reasoning in-context demos into assets for reasoning lms.arXiv preprint arXiv:2509.23196, 2025a. Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Sh...
-
[14]
URLhttps://arxiv.org/abs/2407.10671. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Clevrer: Collision events for video representation and reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning. arXiv preprint arXiv:1910.01442,
-
[16]
Vinoground: Scrutinizing lmms over dense temporal reasoning with short videos
Jianrui Zhang, Mu Cai, and Yong Jae Lee. Vinoground: Scrutinizing lmms over dense temporal reasoning with short videos.arXiv preprint arXiv:2410.02763, 2024a. Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large mult...
-
[17]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024b. 12 Preprint. Under review. Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie...
work page internal anchor Pith review arXiv
-
[18]
Unlocked door
13 Preprint. Under review. A Limitations and Future Work Our results show that targeted, perception-aware model merging can effectively restore tem- poral reasoning in VLMs without retraining. At the same time, they open several promising directions for future work. First,MERIT currently relies on benchmark-defined evaluation signals for temporal percepti...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.