Recognition: unknown
One Scale at a Time: Scale-Autoregressive Modeling for Fluid Flow Distributions
Pith reviewed 2026-05-10 16:03 UTC · model grok-4.3
The pith
Scale-autoregressive modeling generates fluid flow distributions by sampling hierarchically from coarse to fine scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
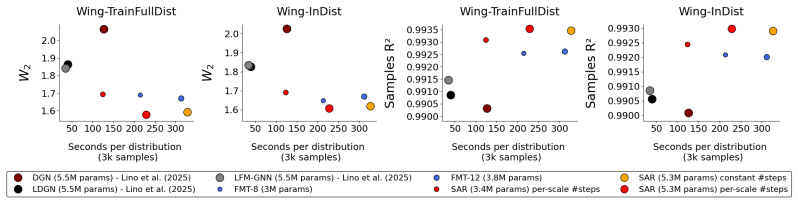
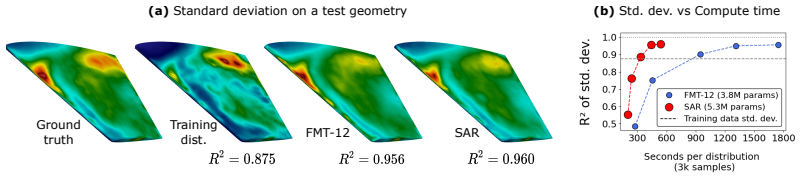
Scale-autoregressive modeling generates fluid flow fields by first producing a low-resolution version and then refining it progressively at higher resolutions, with each finer level conditioned on the coarser prediction. This factorization allows the model to focus computational resources where uncertainty is highest while using fewer operations at detailed scales. Across multiple unsteady flow benchmarks on unstructured meshes, this yields lower distributional error and higher sample accuracy than multi-scale graph neural network diffusion models, and matches or exceeds the performance of a flow-matching transformer solver at two to seven times the speed.
What carries the argument
The hierarchical coarse-to-fine autoregressive sampling process that generates flow distributions on unstructured meshes by conditioning each finer resolution on the preceding coarser output.
If this is right
- Statistical flow quantities such as turbulent kinetic energy and two-point correlations become feasible to estimate quickly and accurately without full PDE solves.
- Independent sampling of entire states avoids the compounding rollout error that limits learned time-stepping surrogates over long horizons.
- Most uncertainty is resolved at coarse scales, so computation is reduced at fine scales while still preserving mesh-level detail.
- The method outperforms diffusion models based on multi-scale GNNs in both error metrics and sample quality while delivering clear speed gains over flow-matching transformers.
Where Pith is reading between the lines
- The same coarse-to-fine conditioning structure could be tested on other multi-scale physical systems where uncertainty varies strongly with resolution.
- Adaptive choice of scale progression based on local flow features might further cut unnecessary computation on heterogeneous meshes.
- The efficiency profile suggests direct use in engineering workflows that require many independent realizations for uncertainty quantification.
Load-bearing premise
Conditioning each finer-scale sample only on the coarser-scale prediction recovers accurate fine-scale statistics and physical correlations without systematic bias or loss of important dependencies in complex unsteady flows.
What would settle it
A direct comparison on an unsteady flow benchmark showing that two-point correlations or energy spectra at the finest scale deviate systematically from ground-truth references when produced by the hierarchical model but remain consistent when produced by non-hierarchical baselines.
Figures









read the original abstract
Analyzing unsteady fluid flows often requires access to the full distribution of possible temporal states, yet conventional PDE solvers are computationally prohibitive and learned time-stepping surrogates quickly accumulate error over long rollouts. Generative models avoid compounding error by sampling states independently, but diffusion and flow-matching methods, while accurate, are limited by the cost of many evaluations over the entire mesh. We introduce scale-autoregressive modeling (SAR) for sampling flows on unstructured meshes hierarchically from coarse to fine: it first generates a low-resolution field, then refines it by progressively sampling higher resolutions conditioned on coarser predictions. This coarse-to-fine factorization improves efficiency by concentrating computation at coarser scales, where uncertainty is greatest, while requiring fewer steps at finer scales. Across unsteady-flow benchmarks of varying complexity, SAR attains substantially lower distributional error and higher per-sample accuracy than state-of-the-art diffusion models based on multi-scale GNNs, while matching or surpassing a flow-matching Transolver (a linear-time transformer) yet running 2-7x faster than this depending on the task. Overall, SAR provides a practical tool for fast and accurate estimation of statistical flow quantities (e.g., turbulent kinetic energy and two-point correlations) in real-world settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces scale-autoregressive modeling (SAR) for sampling distributions of unsteady fluid flows on unstructured meshes. It factorizes the joint distribution hierarchically as p(x_L | x_{L-1}) ... p(x_1), first generating a low-resolution field then progressively refining higher resolutions conditioned on coarser predictions. This is presented as improving efficiency by concentrating computation at coarser scales. Across unsteady-flow benchmarks, SAR is claimed to achieve substantially lower distributional error and higher per-sample accuracy than state-of-the-art multi-scale GNN diffusion models, while matching or surpassing a flow-matching Transolver yet running 2-7x faster.
Significance. If the empirical results hold under scrutiny, SAR offers a practical efficiency improvement for generative modeling in computational fluid dynamics, enabling faster estimation of statistical quantities such as turbulent kinetic energy and two-point correlations without the full cost of many-step diffusion or flow-matching on high-resolution meshes. The hierarchical approach could extend to other multi-scale physical simulation tasks.
major comments (2)
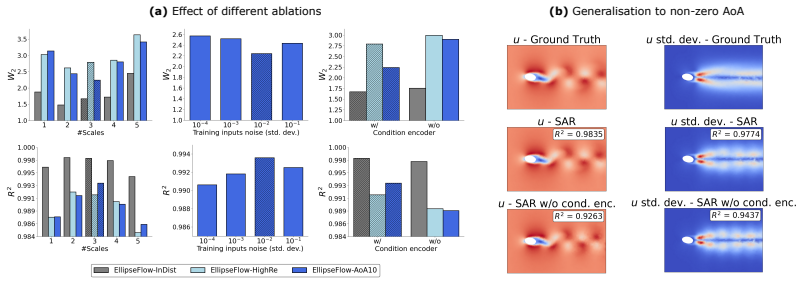
- [Abstract and §3] Abstract and §3 (Modeling Approach): The claim that the coarse-to-fine factorization recovers the full joint distribution without systematic bias is load-bearing for the performance claims. On unstructured meshes the coarse field is obtained via unspecified aggregation; if this discards high-wavenumber information that is statistically dependent on retained modes, conditioning finer-scale GNN/transformer samples on the coarse prediction cannot restore correct two-point statistics or energy spectra. The reported lower distributional error metric can be satisfied even with conditional under-dispersion at fine scales, so explicit validation (e.g., spectra or correlation comparisons on the benchmarks) is required.
- [§5] §5 (Experiments): The abstract reports 2-7x speedups and accuracy gains versus the flow-matching Transolver, but without access to the precise data splits, error bars, ablation studies on the number of scales, or the exact aggregation operator used for coarsening, the support for these quantitative claims cannot be fully verified. Reproducibility artifacts (code, seeds, mesh details) would be needed to confirm the gains are not sensitive to implementation choices.
minor comments (1)
- Notation for the scale indices (L, L-1, …, 1) and the precise definition of the conditioning mechanism should be introduced earlier and used consistently to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Modeling Approach): The claim that the coarse-to-fine factorization recovers the full joint distribution without systematic bias is load-bearing for the performance claims. On unstructured meshes the coarse field is obtained via unspecified aggregation; if this discards high-wavenumber information that is statistically dependent on retained modes, conditioning finer-scale GNN/transformer samples on the coarse prediction cannot restore correct two-point statistics or energy spectra. The reported lower distributional error metric can be satisfied even with conditional under-dispersion at fine scales, so explicit validation (e.g., spectra or correlation comparisons on the benchmarks) is required.
Authors: We appreciate the referee's emphasis on this foundational aspect. The SAR factorization is constructed as an exact decomposition p(x) = p(x_1) ∏_{l=2}^L p(x_l | x_{<l}), where x_1 denotes the coarsest scale; this guarantees that the marginal distribution at every scale is recovered without bias whenever the conditional models are accurate. On unstructured meshes we employ a conservative averaging aggregation that preserves integral invariants such as total momentum and kinetic energy. In the revised §3 we will explicitly define this operator together with a short proof sketch showing that the hierarchical conditioning does not introduce systematic bias in the two-point statistics. To directly validate fine-scale fidelity we will add, in the revised §5, side-by-side comparisons of kinetic-energy spectra and two-point correlation functions for all benchmarks, confirming that SAR reproduces the ground-truth distributions without conditional under-dispersion. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract reports 2-7x speedups and accuracy gains versus the flow-matching Transolver, but without access to the precise data splits, error bars, ablation studies on the number of scales, or the exact aggregation operator used for coarsening, the support for these quantitative claims cannot be fully verified. Reproducibility artifacts (code, seeds, mesh details) would be needed to confirm the gains are not sensitive to implementation choices.
Authors: We fully agree that reproducibility details are essential for verifying the reported speed-ups and accuracy gains. In the revised manuscript we will (i) report all metrics with error bars computed over at least five independent random seeds, (ii) include an ablation study on the number of scales, (iii) specify the exact data splits, mesh resolutions, and aggregation operator (as noted in the response to the first comment), and (iv) release the complete code base, trained checkpoints, random seeds, and mesh files upon acceptance. These additions will allow independent verification that the 2–7× speed-ups and distributional improvements are robust. revision: yes
Circularity Check
No circularity: architectural choice with external benchmark validation
full rationale
The provided abstract and description present SAR as an independent modeling architecture: a coarse-to-fine hierarchical factorization for sampling on unstructured meshes, with direct empirical comparisons to multi-scale GNN diffusion models and a flow-matching Transolver on unsteady-flow benchmarks. No equations, derivations, or claims are shown that reduce performance metrics, distributional error, or statistical quantities (e.g., TKE, correlations) to quantities defined or fitted within the paper itself. The factorization p(x_L | x_{L-1}) ... is introduced as a design decision for efficiency, not derived from self-referential inputs. External baselines and benchmark results supply independent content, satisfying the self-contained criterion for a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benedikt Alkin, Maurits Bleeker, Richard Kurle, Tobias Kronlachner, Reinhard Sonnleitner, Matthias Dorfer, and Johannes Brandstetter. Ab-upt: Scaling neural cfd surrogates for high- fidelity automotive aerodynamics simulations via anchored-branched universal physics transform- ers.arXiv preprint arXiv:2502.09692,
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Flow matching meets PDE s: A unified framework for physics-constrained generation
Giacomo Baldan, Qiang Liu, Alberto Guardone, and Nils Thuerey. Flow matching meets pdes: A unified framework for physics-constrained generation.arXiv preprint arXiv:2506.08604,
-
[4]
Relational inductive biases, deep learning, and graph networks
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks.arXiv:1806.01261,
work page internal anchor Pith review arXiv
-
[5]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman
doi: 10.2514/1.J061454. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11315–11325,
-
[6]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021a
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021a. Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat gans on image synthesis. InAdvances in Neural Information Processing Systems 34, pp. 8780–8794, 2021b. URL https: //proceedings.neu...
2021
-
[7]
Multiscale MeshGraphNets
Meire Fortunato, Tobias Pfaff, Peter Wirnsberger, Alexander Pritzel, and Peter Battaglia. Multiscale MeshGraphNets. InICML 2022 Workshop on AI for Science,
2022
-
[8]
Energy-based trans- formers are scalable learners and thinkers.arXiv preprint arXiv:2507.02092, 2025
Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, and Tariq Iqbal. Energy-Based Transformers are Scalable Learn- ers and Thinkers.arXiv preprint arXiv:2507.02092,
-
[9]
Kingma and Max Welling
11 Diederik P. Kingma and Max Welling. Auto-Encoding Variational Bayes. In2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings,
2014
-
[10]
Georg Kohl, Li-Wei Chen, and Nils Thuerey. Turbulent flow simulation using autoregressive condi- tional diffusion models.arXiv preprint arXiv:2309.01745,
-
[11]
Transformer for partial differential equations’ operator learning, 2023
Tianyi Li, Alessandra S Lanotte, Michele Buzzicotti, Fabio Bonaccorso, and Luca Biferale. Multi- scale reconstruction of turbulent rotating flows with generative diffusion models.Atmosphere, 15 (1):60, 2023b. Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning.arXiv:2205.13671,
-
[12]
Learning Distributions of Complex Fluid Simulations with Diffusion Graph Networks
Mario Lino, Tobias Pfaff, and Nils Thuerey. Learning Distributions of Complex Fluid Simulations with Diffusion Graph Networks. In13th International Conference on Learning Representations (ICLR 2025),
2025
-
[13]
Huakun Luo, Haixu Wu, Hang Zhou, Lanxiang Xing, Yichen Di, Jianmin Wang, and Mingsheng Long. Transolver++: An accurate neural solver for pdes on million-scale geometries.arXiv preprint arXiv:2502.02414,
-
[14]
Battaglia
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter W. Battaglia. Learning mesh- based simulation with graph networks. In9th International Conference on Learning Representa- tions (ICLR 2021),
2021
-
[15]
Battaglia
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter W. Battaglia. Learning to simulate complex physics with graph networks. InProceedings of the 37th International Conference on Machine Learning (ICML 2020), volume 119, pp. 8459–8468,
2020
-
[16]
arXiv preprint arXiv:2112.15275 , year=
Kimberly Stachenfeld, Drummond B Fielding, Dmitrii Kochkov, Miles Cranmer, Tobias Pfaff, Jonathan Godwin, Can Cui, Shirley Ho, Peter Battaglia, and Alvaro Sanchez-Gonzalez. Learned coarse models for efficient turbulence simulation.arXiv:2112.15275,
-
[17]
Shizheng Wen, Arsh Kumbhat, Levi Lingsch, Sepehr Mousavi, Yizhou Zhao, Praveen Chan- drashekar, and Siddhartha Mishra. Geometry aware operator transformer as an efficient and accurate neural surrogate for pdes on arbitrary domains.arXiv preprint arXiv:2505.18781,
-
[18]
A.2 ARCHITECTUREDETAILS The condition encoder, autoregressive module, and sampler components of our SAR model are all based on the Transolver architecture proposed in Wu et al
for a sample from theELLIPSEFLOW-INDISTdataset. A.2 ARCHITECTUREDETAILS The condition encoder, autoregressive module, and sampler components of our SAR model are all based on the Transolver architecture proposed in Wu et al. (2024), enhanced with adaptive temper- ature as introduced by Luo et al. (2025). This design provides a global receptive field effic...
2024
-
[19]
It is conditioned on each node’s spatial locationx j, scale one-hot vector γj, and latent representationsy j andz j
applied, at autoregressive stepk, to nodesj∈ S k. It is conditioned on each node’s spatial locationx j, scale one-hot vector γj, and latent representationsy j andz j. The input feature vectors to the Transolver are defined as vj ←[MLP([s j,r,z j,MLP([x j,γ j]) +MLP(y j)]),r],∀j∈ S k,(19) wheres j,r is the intermediate solution at denoising timer, andr∈R F...
2016
-
[20]
Diffusion GNNs apply the same number of denoising steps across all scales using local message passing and local unpooling
and our SAR model both partition the node setVinto resolution scales but differ in their processing approach. Diffusion GNNs apply the same number of denoising steps across all scales using local message passing and local unpooling. In contrast, SAR allows fewer denoising steps at finer scales, making it feasible to use otherwise expensive attention. Upsa...
2022
-
[21]
2025)0.31 ± 0.18 0.24 ± 0.18 0.46 ± 0.22 0.14 ± 0.03 0.68 ± 0.17 0.64 ± 0.09 10 LFM-GNN (Lino et al
0.23 ± 0.12 0.17 ± 0.08 0.42 ± 0.180.10 ± 0.020.57 ± 0.15 0.59 ± 0.11 50 FM-GNN (Lino et al. 2025)0.31 ± 0.18 0.24 ± 0.18 0.46 ± 0.22 0.14 ± 0.03 0.68 ± 0.17 0.64 ± 0.09 10 LFM-GNN (Lino et al. 2025)0.26 ± 0.14 0.19 ± 0.09 0.44 ± 0.18 0.12 ± 0.02 0.63 ± 0.17 0.61 ± 0.11 10 FMT-4 0.29 ± 0.23 0.19 ± 0.15 0.44 ± 0.23 0.11 ± 0.03 0.67 ± 0.21 0.79 ± 0.14 20 SA...
2025
-
[22]
2025)0.995 ± 0.0070.998 ± 0.0020.986 ± 0.0190.997 ± 0.0010.991 ± 0.0090.966 ± 0.028 50 FM-GNN (Lino et al
0.994 ± 0.0060.997 ± 0.0010.988 ± 0.0150.994 ± 0.0020.992 ± 0.0070.968 ± 0.026 50 LDGN (Lino et al. 2025)0.995 ± 0.0070.998 ± 0.0020.986 ± 0.0190.997 ± 0.0010.991 ± 0.0090.966 ± 0.028 50 FM-GNN (Lino et al. 2025)0.995 ± 0.0070.997 ± 0.0020.987 ± 0.0150.996 ± 0.0030.991 ± 0.0090.966 ± 0.029 10 LFM-GNN (Lino et al. 2025)0.995 ± 0.0080.998 ± 0.0020.985 ± 0.0...
2025
-
[23]
SAR produces the most accurate samples across both settings
19 (a) OOD test case with Re = 1083 (b) OOD test case with AoA = 10 deg FMT-8LDGN SARFMT-8LDGN SAR Figure 9: Samples from LDGN (Lino et al., 2025), FMT-8, and SAR for (a) a simulation from the ELLIPSEFLOW-HIGHREdataset, and (b) a simulation from theELLIPSEFLOW-AOA10dataset. SAR produces the most accurate samples across both settings. Reynols shear stress ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.