Recognition: unknown
R3-VAE: Reference Vector-Guided Rating Residual Quantization VAE for Generative Recommendation
Pith reviewed 2026-05-10 16:23 UTC · model grok-4.3
The pith
R3-VAE generates more stable and higher-quality semantic identifiers for items by anchoring features with a reference vector and rating residuals through dot products.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
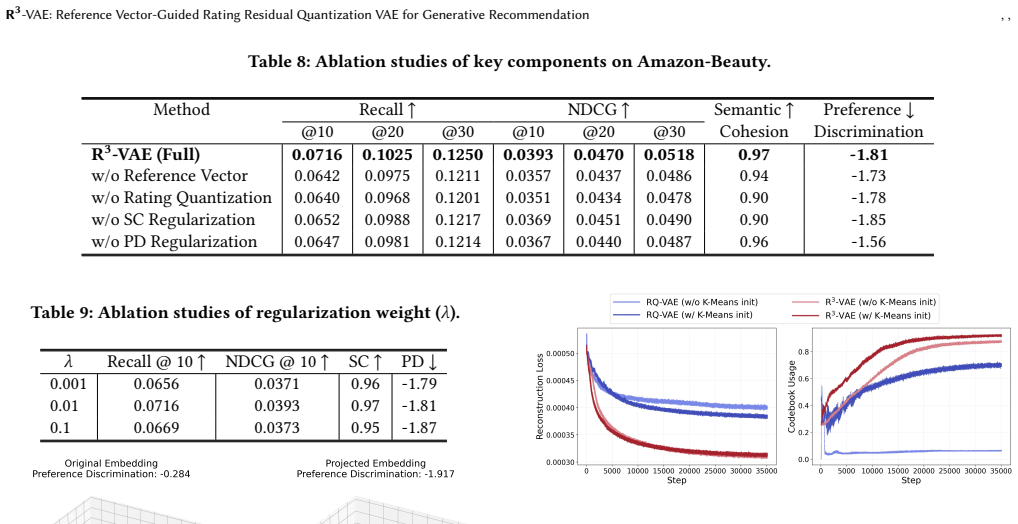
The authors claim that guiding residual quantization inside a VAE with a reference vector as semantic anchor, a dot-product rating mechanism to stabilize gradients and usage, and regularization by Semantic Cohesion and Preference Discrimination metrics produces semantic identifiers that outperform prior methods, shown by higher recall and NDCG on public datasets plus gains in live metrics and cold-start performance.
What carries the argument
The reference vector acting as a fixed semantic anchor together with a dot-product rating mechanism inside residual quantization VAE training, augmented by two new metrics used as regularization terms.
If this is right
- Average gains of 14.5 percent in Recall@10 and 15.5 percent in NDCG@10 across three public datasets.
- 1.62 percent higher MRR and 0.83 percent better StayTime per user in online A/B tests on an industrial platform.
- 15.36 percent lift in cold-start performance when the learned identifiers replace item IDs inside a CTR model.
- Faster SID quality checks during development because the two new metrics serve as cheap proxies for full generative training.
Where Pith is reading between the lines
- The same anchoring and rating ideas could be tried in other discrete representation tasks such as language model tokenization or image codebooks.
- The two evaluation metrics might transfer to measure quality of discrete codes in non-recommendation generative settings.
- Testing the approach on much larger catalogs would reveal whether the stability holds without any extra hyperparameter search.
Load-bearing premise
The reference vector and dot-product rating mechanism plus the two regularization metrics are sufficient to remove training instability and codebook collapse across datasets without creating new biases or forcing dataset-specific retuning.
What would settle it
Training runs of R3-VAE on a fresh recommendation dataset that still exhibit codebook collapse or unstable loss curves, or controlled experiments that show no lift in recommendation metrics over strong baselines.
Figures



read the original abstract
Generative Recommendation (GR) has gained traction for its merits of superior performance and cold-start capability. As the vital role in GR, Semantic Identifiers (SIDs) represent item semantics through discrete tokens. However, current techniques for SID generation based on vector quantization face two main challenges: (i) training instability, stemming from insufficient gradient propagation through the straight-through estimator and sensitivity to initialization; and (ii) inefficient SID quality assessment, where industrial practice still depends on costly GR training and A/B testing. To address these challenges, we propose Reference Vector-Guided Rating Residual Quantization VAE (R3-VAE). This framework incorporates three key innovations: (i) a reference vector that functions as a semantic anchor for the initial features, thereby mitigating sensitivity to initialization; (ii) a dot product-based rating mechanism designed to stabilize the training process and prevent codebook collapse; and (iii) two SID evaluation metrics, Semantic Cohesion and Preference Discrimination, serving as regularization terms during training. Empirical results on six benchmarks demonstrate that R3-VAE outperforms state-of-the-art methods, achieving an average improvement of 14.5% in Recall@10 and 15.5% in NDCG@10 across three public datasets (Beauty, Sports, and Toys). Furthermore, we perform GR training and online A/B tests on Toutiao. Our method achieves a 1.62% improvement in MRR and a 0.83% gain in StayTime/U versus baselines. Additionally, we employ R3-VAE to replace the item ID of CTR model, resulting in significant improvements in content cold start by 15.36%, corroborating the strong applicability and business value in industry-scale recommendation scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes R3-VAE, a reference vector-guided rating residual quantization VAE for generating semantic identifiers (SIDs) in generative recommendation. It targets two challenges in vector-quantized VAEs: training instability from straight-through estimators and initialization sensitivity, plus inefficient SID quality assessment. The three innovations are a reference vector as semantic anchor, a dot-product rating mechanism for stabilization and collapse prevention, and Semantic Cohesion plus Preference Discrimination metrics used as regularization terms. The central empirical claim is consistent outperformance over SOTA methods, with average gains of 14.5% Recall@10 and 15.5% NDCG@10 on three public datasets, plus positive GR training, online A/B results on Toutiao (1.62% MRR, 0.83% StayTime/U), and 15.36% cold-start CTR lift when replacing item IDs.
Significance. If the reported gains are attributable to the three proposed components rather than hyperparameter search or dataset artifacts, the work offers a concrete, deployable improvement to SID generation that directly impacts both academic GR benchmarks and industrial-scale recommendation. The inclusion of ablations, codebook utilization statistics, and real-world A/B tests strengthens the practical value; the new regularization metrics could also serve as reusable diagnostic tools for future VQ-based recommenders.
major comments (2)
- [Experiments] The central claim that the reference vector, dot-product rating, and two regularization terms jointly resolve instability and collapse rests on the experimental protocol. The manuscript should explicitly report (in the experimental section) the hyperparameter ranges searched for the reference vector, dot-product scale, and regularization coefficients, together with an ablation isolating each component's contribution to codebook utilization and final GR metrics; without this, it remains possible that gains arise from dataset-specific tuning rather than the architectural innovations.
- [Experiments] Table reporting public-dataset results: the average 14.5% Recall@10 and 15.5% NDCG@10 improvements are presented without per-dataset variance, statistical significance tests, or confirmation that all baselines were re-trained under identical data splits and negative-sampling protocols. This detail is load-bearing for the claim of consistent superiority across Beauty, Sports, and Toys.
minor comments (2)
- [Method] The notation for the reference vector and the exact formulation of the dot-product rating (including any scaling factor) should be introduced with a single equation block early in the method section to avoid forward references.
- [Experiments] The online A/B test description would benefit from a brief statement of the traffic split, duration, and any guardrail metrics monitored alongside MRR and StayTime/U.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We appreciate the recognition of our work's practical contributions to generative recommendation. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] The central claim that the reference vector, dot-product rating, and two regularization terms jointly resolve instability and collapse rests on the experimental protocol. The manuscript should explicitly report (in the experimental section) the hyperparameter ranges searched for the reference vector, dot-product scale, and regularization coefficients, together with an ablation isolating each component's contribution to codebook utilization and final GR metrics; without this, it remains possible that gains arise from dataset-specific tuning rather than the architectural innovations.
Authors: We agree that explicit hyperparameter reporting and component-isolated ablations are necessary to rule out tuning artifacts. The manuscript already includes ablations and codebook utilization statistics, but we will revise the experimental section to list the searched ranges for the reference vector, dot-product scale, and regularization coefficients. We will further expand the ablation analysis to quantify each component's individual contribution to codebook utilization and downstream GR metrics, thereby confirming that the reported gains derive from the proposed innovations. revision: yes
-
Referee: [Experiments] Table reporting public-dataset results: the average 14.5% Recall@10 and 15.5% NDCG@10 improvements are presented without per-dataset variance, statistical significance tests, or confirmation that all baselines were re-trained under identical data splits and negative-sampling protocols. This detail is load-bearing for the claim of consistent superiority across Beauty, Sports, and Toys.
Authors: We acknowledge the value of detailed statistical reporting for validating consistent superiority. In the revised manuscript we will augment the results tables with per-dataset performance figures including means and standard deviations across multiple runs, include statistical significance tests (e.g., paired t-tests), and add explicit confirmation that all baselines were re-trained under identical data splits and negative-sampling protocols. These changes will strengthen the empirical claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a new VAE architecture (reference vector anchor, dot-product rating mechanism, and Semantic Cohesion + Preference Discrimination regularizers) from explicit architectural choices and loss terms, then trains it end-to-end on standard recommendation datasets. All reported gains are measured via independent downstream metrics (Recall@10, NDCG@10, MRR, StayTime, cold-start CTR) and online A/B tests rather than being forced by construction from fitted inputs or prior self-citations. No load-bearing step reduces a claimed prediction or uniqueness result to the model's own parameters or to an unverified self-citation chain; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- reference vector
- dot-product rating scale
- regularization coefficients for Semantic Cohesion and Preference Discrimination
axioms (2)
- standard math Standard variational autoencoder assumptions on latent distribution and evidence lower bound.
- domain assumption Vector quantization can be stabilized by an external reference vector and dot-product rating without distorting the learned semantics.
invented entities (2)
-
Reference vector
no independent evidence
-
Dot product-based rating mechanism
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Beyond Long Tail POIs: Transition-Centered Generalization for Human Mobility Prediction
RECAP improves next-POI prediction by reconstructing sparse transitions via multi-hop graph transitivity and user revisit signals, yielding gains on tail transitions across real datasets.
Reference graph
Works this paper leans on
-
[1]
Constrained k-means clustering.Microsoft Research, Redmond, 2000
Paul S Bradley, Kristin P Bennett, and Ayhan Demiriz. Constrained k-means clustering.Microsoft Research, Redmond, 2000
2000
-
[2]
Unisearch: Rethinking search system with a unified generative architecture.arXiv preprint, 2025
Jiahui Chen, Xiaoze Jiang, Zhibo Wang, Quanzhi Zhu, Junyao Zhao, Feng Hu, Kang Pan, Ao Xie, Maohua Pei, Zhiheng Qin, et al. Unisearch: Rethinking search system with a unified generative architecture.arXiv preprint, 2025
2025
-
[3]
Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint, 2025
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint, 2025
2025
-
[4]
Forge: Forming semantic identifiers for generative retrieval in industrial datasets.arXiv preprint, 2025
Kairui Fu, Tao Zhang, Shuwen Xiao, Ziyang Wang, Xinming Zhang, Chenchi Zhang, Yuliang Yan, Junjun Zheng, Yu Li, Zhihong Chen, et al. Forge: Forming semantic identifiers for generative retrieval in industrial datasets.arXiv preprint, 2025
2025
-
[5]
Optimized product quantization
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. Optimized product quantization. InIEEE TPAMI, 2013
2013
-
[6]
Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5)
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InRecSys, 2022
2022
-
[7]
Learning vector-quantized item representation for transferable sequential recommenders
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. Learning vector-quantized item representation for transferable sequential recommenders. InWWW, 2023
2023
-
[8]
Bridging language and items for retrieval and recommendation.arXiv preprint, 2024
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint, 2024
2024
-
[9]
Generating long semantic ids in parallel for recommendation
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. Generating long semantic ids in parallel for recommendation. InKDD, 2025
2025
-
[10]
Generative recommendation models: Progress and directions
Yupeng Hou, An Zhang, Leheng Sheng, Zhengyi Yang, Xiang Wang, Tat-Seng Chua, and Julian McAuley. Generative recommendation models: Progress and directions. InWWW, 2025
2025
-
[11]
Product quantization for nearest neighbor search.TPAMI, 2010
Herve Jegou, Matthijs Douze, and Cordelia Schmid. Product quantization for nearest neighbor search.TPAMI, 2010
2010
-
[12]
Genrec: Large language model for generative recommendation
Jianchao Ji, Zelong Li, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Juntao Tan, and Yongfeng Zhang. Genrec: Large language model for generative recommendation. InECIR. Springer, 2024
2024
-
[13]
Llm-aligned geographic item tokenization for local-life recommendation.arXiv preprint, 2025
Hao Jiang, Guoquan Wang, Donglin Zhou, Sheng Yu, Yang Zeng, Wencong Zeng, Kun Gai, and Guorui Zhou. Llm-aligned geographic item tokenization for local-life recommendation.arXiv preprint, 2025
2025
-
[14]
Generative recommendation with semantic ids: A practitioner’s handbook.arXiv preprint, 2025
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. Generative recommendation with semantic ids: A practitioner’s handbook.arXiv preprint, 2025
2025
-
[15]
Au- toregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Au- toregressive image generation using residual quantization. InCVPR, 2022
2022
-
[16]
Semantic convergence: Harmonizing recommender systems via two-stage align- ment and behavioral semantic tokenization
Guanghan Li, Xun Zhang, Yufei Zhang, Yifan Yin, Guojun Yin, and Wei Lin. Semantic convergence: Harmonizing recommender systems via two-stage align- ment and behavioral semantic tokenization. InAAAI, 2025
2025
-
[17]
Order-agnostic identifier for large language model-based generative recommendation
Xinyu Lin, Haihan Shi, Wenjie Wang, Fuli Feng, Qifan Wang, See-Kiong Ng, and Tat-Seng Chua. Order-agnostic identifier for large language model-based generative recommendation. InSIGIR, 2025
2025
-
[18]
Generative recommender with end-to-end learnable item tokenization
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao. Generative recommender with end-to-end learnable item tokenization. InSIGIR, 2025
2025
-
[19]
Bridging textual- collaborative gap through semantic codes for sequential recommendation
Enze Liu, Bowen Zheng, Wayne Xin Zhao, and Ji-Rong Wen. Bridging textual- collaborative gap through semantic codes for sequential recommendation. In KDD, 2025
2025
-
[20]
Discrete semantic tokenization for deep ctr prediction
Qijiong Liu, Hengchang Hu, Jiahao Wu, Jieming Zhu, Min-Yen Kan, and Xiao- Ming Wu. Discrete semantic tokenization for deep ctr prediction. InWWW, 2024
2024
-
[21]
Onerec-think: In-text reasoning for generative recommendation.arXiv preprint, 2025
Zhanyu Liu, Shiyao Wang, Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, et al. Onerec-think: In-text reasoning for generative recommendation.arXiv preprint, 2025
2025
-
[22]
Multi-behavior generative recom- mendation
Zihan Liu, Yupeng Hou, and Julian McAuley. Multi-behavior generative recom- mendation. InCIKM, pages 1575–1585, 2024
2024
-
[23]
Qarm: Quantitative alignment multi-modal recommendation at kuaishou.arXiv preprint, 2024
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, et al. Qarm: Quantitative alignment multi-modal recommendation at kuaishou.arXiv preprint, 2024
2024
-
[24]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects
Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InEMNLP, 2019
2019
-
[25]
Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InCIKM, 2020
2020
-
[26]
Tokenrec: Learning to tokenize id for llm-based generative recommendations
Haohao Qu, Wenqi Fan, Zihuai Zhao, and Qing Li. Tokenrec: Learning to tokenize id for llm-based generative recommendations. InTKDE, 2025
2025
-
[27]
Recommender systems with generative retrieval
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al. Recommender systems with generative retrieval. InNeurIPS, 2023
2023
-
[28]
Generative retrieval with semantic tree-structured identifiers and contrastive learning
Zihua Si, Zhongxiang Sun, Jiale Chen, Guozhang Chen, Xiaoxue Zang, Kai Zheng, Yang Song, Xiao Zhang, Jun Xu, and Kun Gai. Generative retrieval with semantic tree-structured identifiers and contrastive learning. InSIGIR, 2024
2024
-
[29]
Pcr-ca: Parallel codebook representations with contrastive alignment for multiple- category app recommendation.arXiv preprint, 2025
Bin Tan, Wangyao Ge, Yidi Wang, Xin Liu, Jeff Burtoft, Hao Fan, and Hui Wang. Pcr-ca: Parallel codebook representations with contrastive alignment for multiple- category app recommendation.arXiv preprint, 2025
2025
-
[30]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InNeurIPS, 2017
2017
-
[31]
Generative next poi recommendation with semantic id
Dongsheng Wang, Yuxi Huang, Shen Gao, Yifan Wang, Chengrui Huang, and Shuo Shang. Generative next poi recommendation with semantic id. InKDD, 2025
2025
-
[32]
Genera- tive recommendation: Towards next-generation recommender paradigm.arXiv preprint, 2023
Wenjie Wang, Xinyu Lin, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Genera- tive recommendation: Towards next-generation recommender paradigm.arXiv preprint, 2023
2023
-
[33]
Learnable item tokenization for generative rec- ommendation
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. Learnable item tokenization for generative rec- ommendation. InCIKM, 2024
2024
-
[34]
Empowering large language model for sequen- tial recommendation via multimodal embeddings and semantic ids
Yuhao Wang, Junwei Pan, Xinhang Li, Maolin Wang, Yuan Wang, Yue Liu, Dapeng Liu, Jie Jiang, and Xiangyu Zhao. Empowering large language model for sequen- tial recommendation via multimodal embeddings and semantic ids. InCIKM, 2025
2025
-
[35]
Das: Dual-aligned semantic ids empowered industrial recommender system
Wencai Ye, Mingjie Sun, Shaoyun Shi, Peng Wang, Wenjin Wu, and Peng Jiang. Das: Dual-aligned semantic ids empowered industrial recommender system. In CIKM, 2025
2025
-
[36]
Soundstream: An end-to-end neural audio codec
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec. InTASLP, 2021
2021
-
[37]
Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations. In ICML, 2024
2024
-
[38]
Adapting large language models by integrating collaborative semantics for recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. Adapting large language models by integrating collaborative semantics for recommendation. InICDE, 2024
2024
-
[39]
Ega-v2: An end-to-end generative framework for industrial advertising.arXiv preprint, 2025
Zuowu Zheng, Ze Wang, Fan Yang, Jiangke Fan, Teng Zhang, Yongkang Wang, and Xingxing Wang. Ega-v2: An end-to-end generative framework for industrial advertising.arXiv preprint, 2025
2025
-
[40]
Deep interest network for click-through rate prediction
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. InKDD, 2018
2018
-
[41]
Rankmixer: Scaling up ranking models in industrial recommenders
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. Rankmixer: Scaling up ranking models in industrial recommenders. InCIKM, 2025
2025
-
[42]
Cost: Contrastive quantization based semantic tokenization for generative recommendation
Jieming Zhu, Mengqun Jin, Qijiong Liu, Zexuan Qiu, Zhenhua Dong, and Xiu Li. Cost: Contrastive quantization based semantic tokenization for generative recommendation. InRecSys, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.