Recognition: unknown
To Learn or Not to Learn: A Litmus Test for Using Reinforcement Learning in Control
Pith reviewed 2026-05-10 15:25 UTC · model grok-4.3
The pith
A simulation-based test predicts when reinforcement learning will outperform model-based control without any agent training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that reachset-conformant model identification combined with simulation-based analysis of uncertainty impact, followed by correlation analysis of learnability, produces a reliable prediction of whether reinforcement learning control will be superior to model-based control, and that this prediction can be obtained entirely through simulation without ever training an RL agent or running closed-loop performance comparisons.
What carries the argument
reachset-conformant model identification paired with correlation analysis of uncertainty learnability, which quantifies the effect of model errors on control performance and assesses whether those errors can be overcome by learning.
If this is right
- Control engineers can avoid training reinforcement learning agents in cases where the test indicates model uncertainties will not severely degrade model-based performance.
- The method applies across a range of benchmark control problems, indicating it works for linear and nonlinear systems with different uncertainty structures.
- Resources spent on reinforcement learning are limited to problems where the test shows high uncertainty impact and low learnability.
- The two-part analysis supplies an explicit, quantitative criterion for choosing between the two control paradigms.
Where Pith is reading between the lines
- The test could be inserted into automated design pipelines to decide the control method before any optimization begins.
- Correlation analysis of uncertainties might be replaced or augmented by other statistical measures of learnability in future versions.
- Running the test on systems with sensor noise or partial observations would reveal whether the current uncertainty modeling still suffices.
Load-bearing premise
The combination of reachset-conformant identification and correlation-based learnability analysis will correctly flag cases where model-based control fails due to uncertainties without needing direct comparison to trained reinforcement learning controllers.
What would settle it
Apply the litmus test to a benchmark system, then fully train both an RL controller and a model-based controller on the same problem and check whether the test's prediction of superiority matches the actual closed-loop performance difference.
Figures




read the original abstract
Reinforcement learning (RL) can be a powerful alternative to classical control methods when standard model-based control is insufficient, e.g., when deriving a suitable model is intractable or impossible. In many cases, however, the choice between model-based and RL-based control is not obvious. Due to the high computational costs of training RL agents, RL-based control should be limited to cases where it is expected to yield superior results compared to model-based control. To the best of our knowledge, there exists no approach to quantify the benefit of RL-based control that does not require RL training. In this work, we present a computationally efficient, purely simulation-based litmus test predicting whether RL-based control is superior to model-based control. Our test evaluates the suitability of the given model for model-based control by analyzing the impact of model uncertainties on the control problem. For this, we use reachset-conformant model identification combined with simulation-based analysis. This is followed by a learnability evaluation of the uncertainties based on correlation analysis. This two-part analysis enables an informed decision on the suitability of RL for a control problem without training an RL agent. We apply our test to several benchmarks, demonstrating its applicability to a wide range of control problems and highlight the potential to save computational resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a computationally efficient, simulation-based litmus test to decide whether RL-based control will outperform model-based control for a given problem. The test has two stages: (1) reachset-conformant model identification followed by simulation-based analysis of how model uncertainties affect the control task, and (2) a correlation analysis that evaluates the learnability of those uncertainties. The method is claimed to predict RL superiority without ever training an RL agent or performing closed-loop comparisons, and is demonstrated on several benchmarks.
Significance. If the predictive power of the two-stage analysis is confirmed, the litmus test would allow practitioners to avoid the substantial computational cost of RL training in cases where model-based methods are already adequate. The approach is purely simulation-based and does not require RL training, which addresses a clear practical gap in control design.
major comments (2)
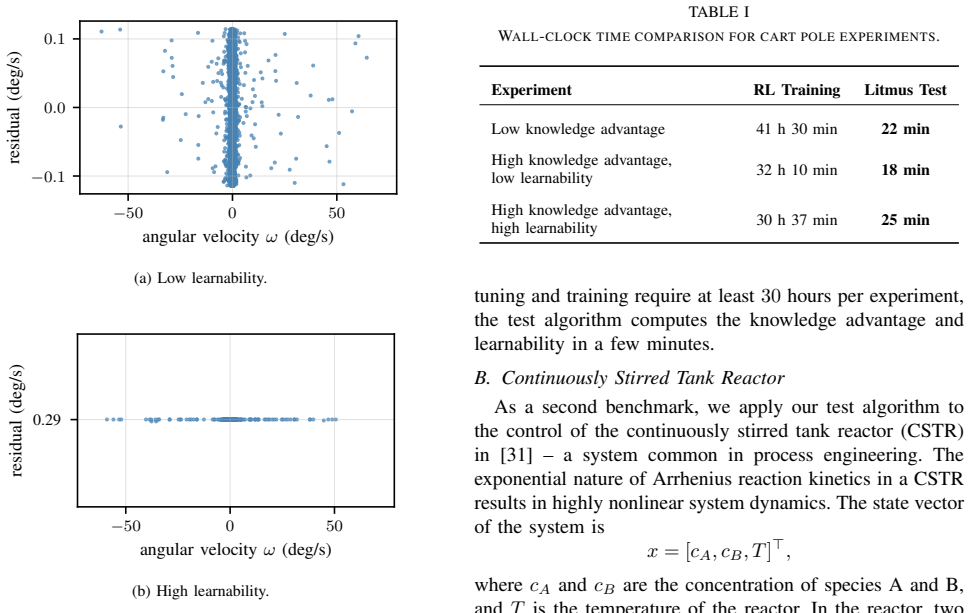
- [§4] §4 (Benchmark Results): The manuscript states that the litmus test is applied to several benchmarks to demonstrate applicability, yet provides no ground-truth experiments that train RL agents, measure closed-loop performance, and check whether the test's prediction matches observed RL superiority (or lack thereof). Without such validation, the central claim that the reachset-conformant identification plus correlation analysis accurately predicts RL benefit remains untested.
- [§3.2] §3.2 (Learnability Evaluation): The correlation analysis is presented as the key indicator of whether uncertainties are learnable by RL, but no theoretical or empirical link is established between the reported correlation coefficients and the sample complexity or policy improvement that an RL agent would actually achieve in closed loop.
minor comments (2)
- [§2] Notation for reachset-conformant identification is introduced without a compact summary of the underlying set-membership assumptions; a short paragraph or table would improve readability.
- [Abstract and §4] The abstract and introduction both claim the test is 'purely simulation-based,' but the precise simulation budget (number of trajectories, horizon length) used in the benchmarks is not tabulated.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments highlight important aspects of validation and theoretical grounding that we will address through revisions. Below we respond point by point.
read point-by-point responses
-
Referee: [§4] §4 (Benchmark Results): The manuscript states that the litmus test is applied to several benchmarks to demonstrate applicability, yet provides no ground-truth experiments that train RL agents, measure closed-loop performance, and check whether the test's prediction matches observed RL superiority (or lack thereof). Without such validation, the central claim that the reachset-conformant identification plus correlation analysis accurately predicts RL benefit remains untested.
Authors: We agree that direct empirical validation via RL training on the benchmarks would strengthen the central claim. The current manuscript focuses on the design of the simulation-based test itself and applies it to benchmarks chosen because their control-theoretic properties (e.g., high vs. low model uncertainty impact) make the expected outcome clear a priori. Nevertheless, the referee is correct that this does not constitute a full predictive validation. In the revision we will add a new subsection in §4 that trains RL agents (using standard algorithms such as SAC or PPO) on two of the benchmarks, measures closed-loop performance against the model-based baseline, and checks consistency with the litmus-test predictions. This will be presented as an initial validation study while preserving the test's core advantage of avoiding routine RL training. revision: yes
-
Referee: [§3.2] §3.2 (Learnability Evaluation): The correlation analysis is presented as the key indicator of whether uncertainties are learnable by RL, but no theoretical or empirical link is established between the reported correlation coefficients and the sample complexity or policy improvement that an RL agent would actually achieve in closed loop.
Authors: We acknowledge that the manuscript currently provides only a high-level motivation for the correlation step. The correlation coefficient is intended to quantify the extent to which model uncertainties are state-dependent and therefore potentially compensable by a state-feedback policy; RL agents can exploit such structure via function approximation. To make this link explicit we will revise §3.2 to include (i) a brief reference to RL theory on learning under structured disturbances (e.g., results showing reduced sample complexity when dynamics or rewards admit low-dimensional representations) and (ii) an additional empirical plot across the benchmarks that relates the observed correlation values to the magnitude of performance improvement reported in the literature for those same systems. These additions will clarify the connection to sample complexity and policy improvement without altering the test's computational efficiency. revision: yes
Circularity Check
No significant circularity in the proposed litmus test
full rationale
The paper defines a new simulation-based procedure that combines reachset-conformant model identification with correlation analysis of uncertainties to decide whether RL is likely to outperform model-based control. This procedure is constructed independently of any actual RL training outcomes or closed-loop performance metrics; the output is not defined in terms of the quantity it claims to predict, and no parameters are fitted to a subset of data and then relabeled as a prediction. No self-citation chains are invoked as the sole justification for the core claim, and the method is presented as a standalone test rather than a re-expression of its inputs. The derivation therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Simulation of reachsets under model uncertainties accurately reflects real-world control performance differences between RL and model-based methods.
- domain assumption Correlation analysis of uncertainties correctly measures their learnability by RL agents.
Reference graph
Works this paper leans on
-
[1]
Ogata,Modern Control Engineering, 5th ed
K. Ogata,Modern Control Engineering, 5th ed. Prentice Hall, 2022
2022
-
[2]
Emami-Naeini and J
A. Emami-Naeini and J. D. Powell, Eds.,Feedback Control of Dy- namic Systems, Global Edition, 8th ed. Harlow: Pearson Education, Limited, 2019
2019
-
[3]
Re- inforcement learning for control: Performance, stability, and deep approximators,
L. Bus ¸oniu, T. De Bruin, D. Toli ´c, J. Kober, and I. Palunko, “Re- inforcement learning for control: Performance, stability, and deep approximators,”Annual Reviews in Control, vol. 46, pp. 8–28, 2018
2018
-
[4]
A tour of reinforcement learning: The view from contin- uous control,
B. Recht, “A tour of reinforcement learning: The view from contin- uous control,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 2, no. 1, pp. 253–279, 2019
2019
-
[5]
Comparison of deep reinforcement learning and model predictive control for real-time depth optimization of a lifting surface controlled ocean current turbine,
A. Hasankhani, Y . Tang, J. VanZwieten, and C. Sultan, “Comparison of deep reinforcement learning and model predictive control for real-time depth optimization of a lifting surface controlled ocean current turbine,” in2021 IEEE Conference on Control Technology and Applications (CCTA), 2021, pp. 301–308
2021
-
[6]
An introduction to deep reinforcement learning,
V . Francois-Lavet, P. Henderson, R. Islam, M. G. Bellemare, and J. Pineau, “An introduction to deep reinforcement learning,”Founda- tions and Trends in Machine Learning, vol. 11, no. 3-4, pp. 219–354, 2018
2018
-
[7]
Learning to control linear systems can be hard,
A. Tsiamis, I. Ziemann, M. Morari, N. Matni, and G. J. Pappas, “Learning to control linear systems can be hard,”Proceedings of Machine Learning Research, vol. 178, pp. 3820–3857, 2022
2022
-
[8]
A survey of industrial model predictive control technology,
S. Qin and T. A. Badgwell, “A survey of industrial model predictive control technology,”Control Engineering Practice, vol. 11, no. 7, pp. 733–764, 2003
2003
-
[9]
Model predictive control of a vehicle using koopman operator,
V . Cibulka, T. Hani ˇs, M. Korda, and M. Hrom ˇc´ık, “Model predictive control of a vehicle using koopman operator,”IFAC-PapersOnLine, vol. 53, no. 2, pp. 4228–4233, 2020
2020
-
[10]
Reinforcement learning versus model predictive control on green- house climate control,
B. Morcego, W. Yin, S. Boersma, E. Van Henten, V . Puig, and C. Sun, “Reinforcement learning versus model predictive control on green- house climate control,”Computers and Electronics in Agriculture, vol. 215, 2023
2023
-
[11]
Comparison of reinforcement learning and model predictive control for building energy system optimization,
D. Wang, W. Zheng, Z. Wang, Y . Wang, X. Pang, and W. Wang, “Comparison of reinforcement learning and model predictive control for building energy system optimization,”Applied Thermal Engineer- ing, vol. 228, 2023
2023
-
[12]
Comparative analysis of optimal control and reinforcement learning methods for energy storage management under uncertainty,
E. Ginzburg-Ganz, I. Segev, Y . Levron, J. Belikov, D. Baimel, and S. Keren, “Comparative analysis of optimal control and reinforcement learning methods for energy storage management under uncertainty,” Energy Storage and Applications, vol. 2, no. 4, p. 14, 2025
2025
-
[13]
Comparison of reinforcement learning and model predictive control for a nonlinear continuous process,
V . Rajpoot, S. Munusamy, T. Joshi, D. Patil, and V . Pinnamaraju, “Comparison of reinforcement learning and model predictive control for a nonlinear continuous process,”IFAC-PapersOnLine, vol. 57, pp. 304–308, 2024
2024
-
[14]
Continuous control with deep reinforcement learning
T. P. Lillicrapet al., “Continuous control with deep reinforcement learning,”arXiv:1509.02971, 2019
work page internal anchor Pith review arXiv 2019
-
[15]
Benchmarking deep reinforcement learning for continuous control
Y . Duan, X. Chen, R. Houthooft, J. Schulman, and P. Abbeel, “Benchmarking deep reinforcement learning for continuous control,” arXiv:1604.06778, 2016
-
[16]
PC-gym: Benchmark environments for process control problems,
M. Blooret al., “PC-gym: Benchmark environments for process control problems,”Computers & Chemical Engineering, vol. 204, p. 109363, 2026
2026
-
[17]
A data-driven method for fast AC optimal power flow solutions via deep reinforcement learning,
Y . Zhouet al., “A data-driven method for fast AC optimal power flow solutions via deep reinforcement learning,”Journal of Modern Power Systems and Clean Energy, vol. 8, no. 6, pp. 1128–1139, 2020
2020
-
[18]
Aleatoric and epistemic uncer- tainty in machine learning: An introduction to concepts and methods,
E. H ¨ullermeier and W. Waegeman, “Aleatoric and epistemic uncer- tainty in machine learning: An introduction to concepts and methods,” Machine Learning, vol. 110, no. 3, pp. 457–506, 2021
2021
-
[19]
Model con- formance for cyber-physical systems: A survey,
H. Roehm, J. Oehlerking, M. Woehrle, and M. Althoff, “Model con- formance for cyber-physical systems: A survey,”ACM Transactions on Cyber-Physical Systems, vol. 3, no. 3, pp. 1–26, 2019
2019
-
[20]
Scalable reachset-conformant identifica- tion of linear systems,
L. L ¨utzow and M. Althoff, “Scalable reachset-conformant identifica- tion of linear systems,”IEEE Control Systems Letters, vol. 8, pp. 520– 525, 2024
2024
-
[21]
Reachset-conformant system identifica- tion,
L. L ¨utzow and M. Althoff, “Reachset-conformant system identifica- tion,”arXiv:2407.11692, 2025
-
[22]
A comparative study of statistical methods used to identify dependencies between gene expression signals,
S. De Siqueira Santos, D. Y . Takahashi, A. Nakata, and A. Fujita, “A comparative study of statistical methods used to identify dependencies between gene expression signals,”Briefings in Bioinformatics, vol. 15, no. 6, pp. 906–918, 2014
2014
-
[23]
The randomized depen- dence coefficient,
D. Lopez-Paz, P. Hennig, and B. Sch ¨olkopf, “The randomized depen- dence coefficient,” inProceedings of the 27th International Conference on Neural Information Processing Systems, vol. 1, 2013
2013
-
[24]
J. M. Wooldridge,Introductory Econometrics: A Modern Approach, 4th ed. Mason, Ohio: South-Western, 2009
2009
-
[25]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Addressing Function Approximation Error in Actor-Critic Methods
S. Fujimoto, H. van Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,”arXiv:1802.09477, 2018
work page Pith review arXiv 2018
-
[27]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,”arXiv:1801.01290, 2018
work page internal anchor Pith review arXiv 2018
-
[28]
Comparison of deep rein- forcement learning and model predictive control for adaptive cruise control,
Y . Lin, J. McPhee, and N. L. Azad, “Comparison of deep rein- forcement learning and model predictive control for adaptive cruise control,”IEEE Transactions on Intelligent Vehicles, vol. 6, no. 2, pp. 221–231, 2021
2021
-
[29]
Optuna: A next-generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hyperparameter optimization framework,” inPro- ceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 2623–2631
2019
-
[30]
Neuronlike adaptive elements that can solve difficult learning control problems,
A. G. Barto, R. S. Sutton, and C. W. Anderson, “Neuronlike adaptive elements that can solve difficult learning control problems,”IEEE Transactions on Systems, Man, and Cybernetics, vol. SMC-13, no. 5, pp. 834–846, 1983
1983
-
[31]
Dynamic economic optimization of a continuously stirred tank reactor using reinforcement learning,
D. Machalek, T. Quah, and K. M. Powell, “Dynamic economic optimization of a continuously stirred tank reactor using reinforcement learning,” inAmerican Control Conference (ACC), 2020, pp. 2955– 2960
2020
-
[32]
Z. Yuanet al., “safe-control-gym: A unified benchmark suite for safe learning-based control and reinforcement learning in robotics,” arXiv:2109.06325, 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.