Recognition: unknown
Three Roles, One Model: Role Orchestration at Inference Time to Close the Performance Gap Between Small and Large Agents
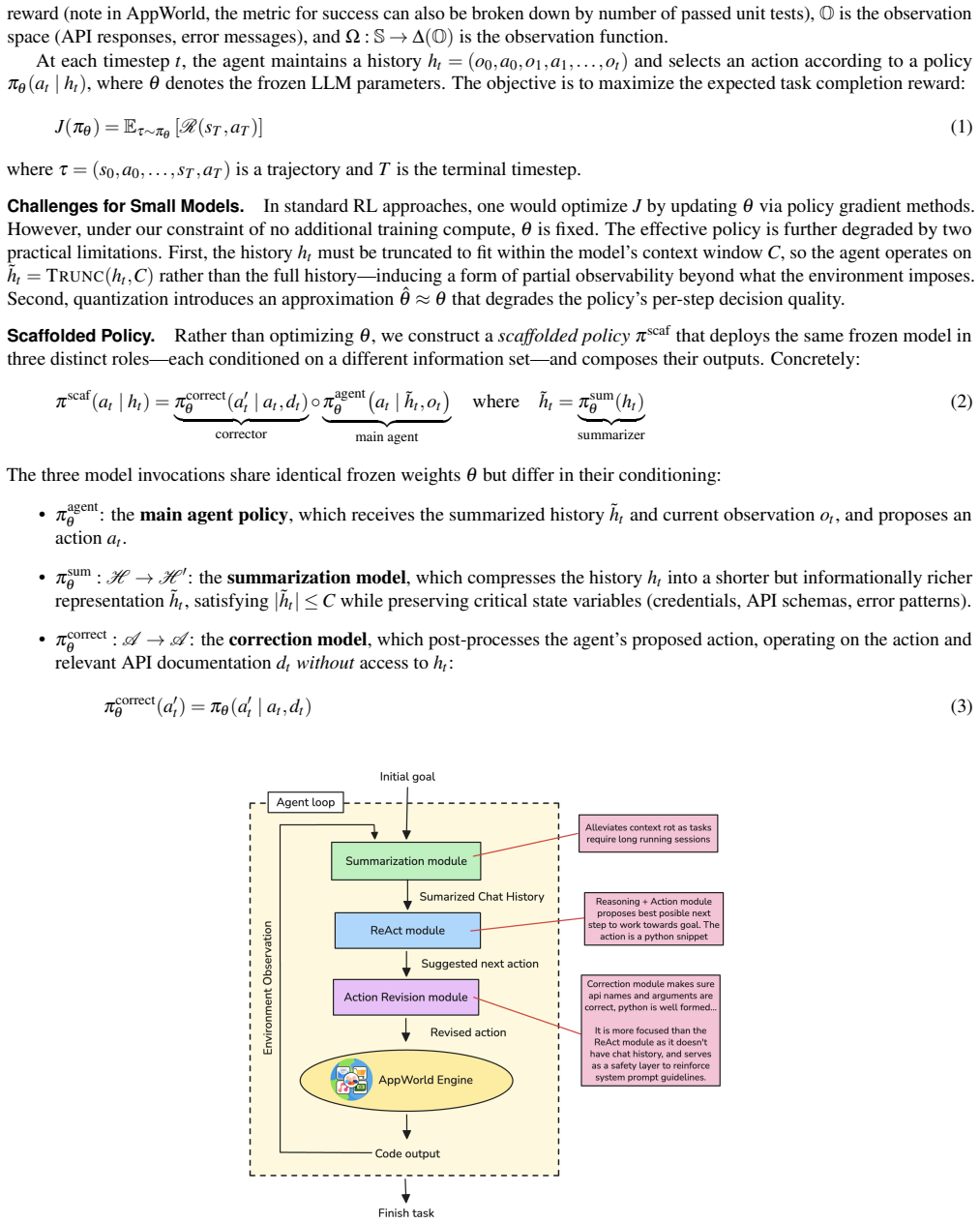
Pith reviewed 2026-05-10 15:00 UTC · model grok-4.3
The pith
Using one 8B model in three roles at inference time doubles its success on complex tool-use tasks and beats a 33B model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize the approach as a scaffolded policy over a frozen base model, three invocations of the same weights with different conditioning. A summarization model preserves critical artifacts while compressing dialogue history, the main agent reasons over the compressed context, and an isolated correction model reviews and revises the agent's code output without access to conversation history. Applied to the same unmodified Qwen3-8B model, this scaffolding yields 8.9% (FP16) and 5.9% (AWQ) task goal completion on AppWorld, roughly doubling baseline performance and surpassing DeepSeek-Coder 33B Instruct (7.1%) from the original evaluation.
What carries the argument
The scaffolded policy: three invocations of the identical frozen model weights under different conditioning for summarization that retains tokens and responses, main agent reasoning on the compressed context, and history-isolated correction to revise outputs and escape repetitive failure loops.
If this is right
- Small models can reach performance levels competitive with models four times larger on multi-step agent tasks through inference-time role orchestration alone.
- No additional training compute is required to achieve these gains; only multiple forward passes of the same weights are used.
- Isolating the correction role breaks repetitive failure loops that otherwise limit raw model performance.
- Capable agent behavior becomes feasible on modest hardware such as a single 24GB GPU.
Where Pith is reading between the lines
- The same role-division pattern could be tested on other agent benchmarks to check whether the doubling effect holds beyond AppWorld.
- Combining this orchestration with other forms of test-time compute might produce further improvements without retraining.
- The results suggest that external structuring of a model's outputs can substitute for some of the capability gained by increasing parameter count.
Load-bearing premise
The summarization step must preserve all critical artifacts such as tokens, credentials, and API responses without loss, and the isolated correction model must reliably improve outputs even when denied access to conversation history.
What would settle it
Running the scaffolded 8B model on the AppWorld benchmark and measuring task goal completion below the raw baseline of 5.4% FP16 or 3.0% AWQ, or failing to exceed the 7.1% reported for the 33B model under the same evaluation protocol.
Figures
read the original abstract
Large language model (LLM) agents show promise on realistic tool-use tasks, but deploying capable agents on modest hardware remains challenging. We study whether inference-time scaffolding alone, without any additional training compute, can improve the performance of a small model in complex multi-step environments. Operating on a single 24GB GPU, we evaluate Qwen3-8B on the AppWorld benchmark under both full-precision and 4-bit quantized configurations. Without any intervention, the raw model achieves just 5.4% (FP16) and 3.0% (AWQ) task goal completion. Guided by a systematic failure mode analysis, we introduce a three-tier inference scaffolding pipeline that deploys the same frozen model in three distinct roles: (1) a summarization model that preserves critical artifacts (tokens, credentials, API responses) while compressing dialogue history; (2) the main agent model that reasons over the compressed context; and (3) an isolated correction model that reviews and revises the agent's code output without access to conversation history, breaking repetitive failure loops. Applied to the same unmodified model, this scaffolding yields 8.9% (FP16) and 5.9% (AWQ) task goal completion, roughly doubling performance in both settings, with particularly strong gains on difficulty-1 tasks (15.8% to 26.3% FP16; 5.3% to 14.0% AWQ). On full-precision inference, our scaffolded 8B model surpasses DeepSeek-Coder 33B Instruct (7.1%) from the original AppWorld evaluation, demonstrating that structured inference-time interventions can make small models competitive with systems 4 times their size. We formalize the approach as a scaffolded policy over a frozen base model, three invocations of the same weights with different conditioning, drawing connections to test-time compute scaling and action-space shaping in reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that inference-time scaffolding using the same frozen Qwen3-8B model in three roles (summarizer preserving artifacts while compressing history, main agent reasoning over compressed context, and isolated corrector without history) roughly doubles task goal completion on AppWorld from 5.4% to 8.9% (FP16) and 3.0% to 5.9% (AWQ), allowing the scaffolded 8B model to surpass the original 33B baseline (7.1%), all without additional training and guided by failure-mode analysis.
Significance. If the gains prove robust, the work shows that structured role orchestration at inference time can meaningfully narrow the small-to-large model gap on complex tool-use tasks using only a single 24GB GPU and the unmodified base model. It provides a practical, training-free approach with explicit links to test-time compute scaling and action-space shaping, and the systematic failure-mode analysis is a methodological strength that could generalize.
major comments (2)
- [Results] The reported performance doublings (5.4% to 8.9% FP16; 3.0% to 5.9% AWQ) are given as single point estimates with no error bars, number of runs, random seeds, or statistical tests, making it impossible to determine whether the gains exceed benchmark variance.
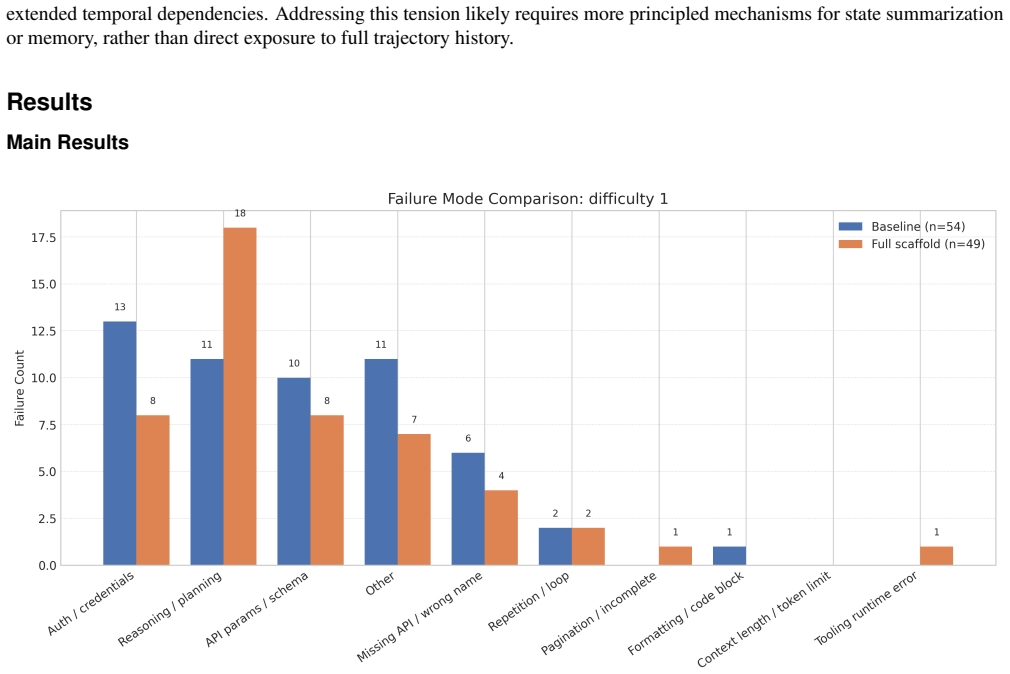
- [Method (three-tier pipeline and failure-mode analysis)] The headline result depends on two unverified mechanisms: summarization must retain every critical token/credential/API response without loss, and the correction model must diagnose/repair failures when given only the agent's code output and no conversation history. No quantitative audit of information loss or correction success rate is supplied despite the motivating failure-mode analysis.
minor comments (2)
- [Abstract] The formalization of the approach as a 'scaffolded policy' would be clearer with explicit pseudocode or a short mathematical description of the three conditioned invocations of the same weights.
- [Results] Table or figure captions for the difficulty-1 breakdowns (15.8% to 26.3% FP16) should explicitly state the number of tasks per difficulty bin.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for recognizing the potential significance of our inference-time scaffolding approach. We address the major comments below and commit to revisions that enhance the rigor of our empirical claims.
read point-by-point responses
-
Referee: [Results] The reported performance doublings (5.4% to 8.9% FP16; 3.0% to 5.9% AWQ) are given as single point estimates with no error bars, number of runs, random seeds, or statistical tests, making it impossible to determine whether the gains exceed benchmark variance.
Authors: We agree that presenting results as single point estimates limits the ability to assess statistical significance and robustness to variance in the benchmark. The AppWorld environment involves stochastic elements due to model sampling during generation. In the revised version, we will perform multiple independent runs (at least 3-5) with different random seeds for both the baseline and the scaffolded setups. We will report mean task completion rates along with standard deviations and conduct appropriate statistical tests (e.g., paired t-tests) to evaluate whether the observed improvements are significant. This will strengthen the evidence for the effectiveness of the role orchestration. revision: yes
-
Referee: [Method (three-tier pipeline and failure-mode analysis)] The headline result depends on two unverified mechanisms: summarization must retain every critical token/credential/API response without loss, and the correction model must diagnose/repair failures when given only the agent's code output and no conversation history. No quantitative audit of information loss or correction success rate is supplied despite the motivating failure-mode analysis.
Authors: The referee is correct that we have not provided quantitative verification of the summarizer's fidelity or the corrector's repair success rate. Our failure-mode analysis was qualitative, identifying patterns such as context overload and repetitive errors, which directly informed the three-role design. However, to address this, we will include in the revision a quantitative evaluation: we will sample a subset of trajectories and measure the proportion of critical information (e.g., API responses, credentials) preserved by the summarizer, and separately evaluate the corrector on isolated failure cases to report its success rate in diagnosing and fixing issues. These additions will provide direct evidence supporting the mechanisms underlying the performance gains. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation of inference scaffolding
full rationale
The paper reports measured task-completion rates on AppWorld for an unmodified Qwen3-8B model under three-role scaffolding versus baseline. All gains (5.4% to 8.9% FP16, 3.0% to 5.9% AWQ) are direct experimental outcomes, not outputs of any equation, fitted parameter, or self-referential definition. The brief formalization as a 'scaffolded policy' is descriptive and draws only loose conceptual links to test-time scaling; no derivations, uniqueness theorems, or self-citations are invoked to force the result. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A single frozen LLM can be effectively conditioned to perform three distinct roles (summarization, reasoning, isolated correction) via prompting alone.
- ad hoc to paper Summarization preserves critical artifacts without loss of information needed for downstream reasoning.
Reference graph
Works this paper leans on
-
[1]
Li, X. A review of prominent paradigms for llm-based agents: Tool use (including rag), planning, and feedback learning (2024). 2406.05804
-
[2]
InInternational Conference on Learning Representations(2023)
Yao, S.et al.React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations(2023)
2023
-
[3]
InAdvances in Neural Information Processing Systems(2023)
Schick, T.et al.Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems(2023)
2023
-
[4]
In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics(2024)
Trivedi, H.et al.Appworld: A controllable world of apps and people for benchmarking interactive coding agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics(2024)
2024
-
[5]
InAdvances in Neural Information Processing Systems(2022)
Wei, J.et al.Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems(2022)
2022
-
[6]
InInternational Conference on Learning Representations(2023)
Wang, X.et al.Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations(2023)
2023
-
[7]
InAdvances in Neural Information Processing Systems(2023)
Yao, S.et al.Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems(2023). 8.Team, Q. Qwen3 technical report.arXiv preprint(2025)
2023
-
[8]
Lin, J.et al.Awq: Activation-aware weight quantization for llm compression and acceleration.arXiv preprint arXiv:2306.00978(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Li, M.et al.API-bank: A comprehensive benchmark for tool-augmented LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 3102–3116, DOI: 10.18653/v1/2023.emnlp-main.187 (Association for Computational Linguistics, Singapore, 2023)
-
[10]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Patil, S. G., Zhang, T., Wang, X. & Gonzalez, J. E. Gorilla: Large language model connected with massive APIs. In Advances in Neural Information Processing Systems, vol. 37, DOI: 10.52202/079017-4020 (2024). 12.Chen, K.et al.Reinforcement learning for long-horizon interactive llm agents.arXiv preprint(2025). 13.Wang, J.et al.Reinforcement learning for sel...
-
[11]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K. & Kumar, A. Scaling LLM test-time compute optimally can be more effective than scaling model parameters (2024). 2408.03314. 15.Chen, B.et al.Fireact: Toward language agent fine-tuning, DOI: 10.48550/arXiv.2310.05915 (2023). 2310.05915. 16.Zhai, Y .et al.Agentevolver: Towards efficient self-evolving agent system (2025). 2511.1039...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.05915 2024
-
[12]
& Brbi´c, M
Jiang, Y ., Jiang, L., Teney, D., Moor, M. & Brbi´c, M. Meta-rl induces exploration in language agents.arXiv preprint (2025). 19.Bohnet, B.et al.Enhancing llm planning capabilities through intrinsic self-critique.arXiv preprint(2025)
2025
-
[13]
InAdvances in Neural Information Processing Systems, vol
Madaan, A.et al.Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems, vol. 36 (2023). 21.Gou, Z.et al.CRITIC: Large language models can self-correct with tool-interactive critiquing. InICLR 2024(2024)
2023
-
[14]
Reflexion: Language Agents with Verbal Reinforcement Learning
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K. & Yao, S. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, vol. 36 (2023). 2303.11366. 23.Chen, X., Lin, M., Schärli, N. & Zhou, D. Teaching large language models to self-debug. InICLR 2024(2024). 12/13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
MemGPT: Towards LLMs as Operating Systems
Zhong, L., Wang, Z. & Shang, J. Debug like a human: A large language model debugger via verifying runtime execution step by step. InFindings of the Association for Computational Linguistics: ACL 2024, 851–870, DOI: 10.18653/v1/2024.findings-acl.49 (Association for Computational Linguistics, Bangkok, Thailand, 2024). 25.Zhang, Y .et al.Spiral: Symbolic llm...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.findings-acl.49 2024
-
[16]
Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory , journal =
Suzgun, M., Yuksekgonul, M., Bianchi, F., Jurafsky, D. & Zou, J. Dynamic cheatsheet: Test-time learning with adaptive memory (2025). 2504.07952
-
[17]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Zhang, Q.et al.Agentic context engineering: Evolving contexts for self-improving language models (2026). 2510.04618. 31.Xu, W.et al.A-mem: Agentic memory for llm agents (2025). 2502.12110
work page internal anchor Pith review arXiv 2026
-
[18]
arXiv preprint(2025)
Cao, Z.et al.Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution. arXiv preprint(2025)
2025
-
[19]
Jiang, H.et al.LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 1658–1677, DOI: 10.18653/v1/2024.acl-long.91 (Association for Computational Linguistics, Bangkok, Thailand, 2024). 34.Zhang, K.et...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.