Recognition: unknown
METER: Evaluating Multi-Level Contextual Causal Reasoning in Large Language Models
Pith reviewed 2026-05-10 14:55 UTC · model grok-4.3
The pith
Large language models decline in contextual causal reasoning ability as tasks move up the causal hierarchy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using the METER benchmark under unified contexts, the evaluation demonstrates that LLMs' proficiency decreases significantly as causal tasks ascend from association to intervention to counterfactual levels, with primary failure modes being susceptibility to distraction by causally irrelevant information at lower levels and degradation in context faithfulness at higher levels.
What carries the argument
The METER benchmark that systematically tests LLMs across the three levels of the causal ladder in a single consistent context, combined with error pattern analysis and internal information flow tracing.
If this is right
- Models will continue to underperform on tasks requiring counterfactual thinking unless the identified failure modes are addressed.
- Distraction by irrelevant information at lower levels suggests models need better filtering of relevant causal signals.
- Declining context faithfulness at higher levels implies that advanced causal reasoning depends on maintaining fidelity to provided information.
- Future model development can use the benchmark to specifically target and measure improvements in these areas.
Where Pith is reading between the lines
- These limitations may hinder LLMs in applications like scientific hypothesis generation or legal reasoning that rely on counterfactuals.
- Addressing the failure modes could involve new training objectives focused on causal isolation and context retention.
- The benchmark design might be extended to test causal reasoning in multimodal or interactive settings.
Load-bearing premise
The METER benchmark tasks accurately isolate the three causal ladder levels without unintended biases from context construction or question phrasing.
What would settle it
An experiment showing that LLMs maintain or improve performance as causal levels increase when tested on the METER benchmark or similar unified contexts.
Figures



read the original abstract
Contextual causal reasoning is a critical yet challenging capability for Large Language Models (LLMs). Existing benchmarks, however, often evaluate this skill in fragmented settings, failing to ensure context consistency or cover the full causal hierarchy. To address this, we pioneer METER to systematically benchmark LLMs across all three levels of the causal ladder under a unified context setting. Our extensive evaluation of various LLMs reveals a significant decline in proficiency as tasks ascend the causal hierarchy. To diagnose this degradation, we conduct a deep mechanistic analysis via both error pattern identification and internal information flow tracing. Our analysis reveals two primary failure modes: (1) LLMs are susceptible to distraction by causally irrelevant but factually correct information at lower level of causality; and (2) as tasks ascend the causal hierarchy, faithfulness to the provided context degrades, leading to a reduced performance. We belive our work advances our understanding of the mechanisms behind LLM contextual causal reasoning and establishes a critical foundation for future research. Our code and dataset are available at https://github.com/SCUNLP/METER .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces METER, a benchmark for evaluating LLMs on contextual causal reasoning across the full causal ladder (association, intervention, counterfactual) under unified contexts. Extensive evaluations across multiple LLMs report a significant performance decline with ascending causal levels; mechanistic analysis via error patterns and information-flow tracing identifies two failure modes—distraction by causally irrelevant but factually correct information at lower levels, and progressive loss of faithfulness to provided context at higher levels.
Significance. If the benchmark tasks cleanly isolate the three causal operations, the work supplies a valuable unified testbed and mechanistic diagnostics that could guide improvements in LLM causal reasoning. Public release of code and dataset is a clear strength that enables follow-up research.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: The paper does not provide explicit controls, ablations, or quantitative comparisons demonstrating that the three task families differ only in the demanded causal operation. Without evidence that context length, question phrasing complexity, lexical cues, and world-knowledge demands are matched across levels, the reported performance decline and the two diagnosed failure modes could be artifacts of general difficulty or prompt sensitivity rather than specific deficits in the causal hierarchy.
- [Mechanistic Analysis] Mechanistic Analysis section: Both the error-pattern identification and the internal information-flow tracing are conditioned on the same task partition. If that partition is confounded by non-causal factors, the attribution of failure mode (1) to lower-level distraction and failure mode (2) to higher-level faithfulness loss is not yet load-bearing; an independent validation (e.g., difficulty-matched controls or human difficulty ratings) is required.
minor comments (2)
- [Abstract] Abstract: 'We belive' should read 'We believe'.
- [Dataset Construction] Dataset and task examples: Providing one or two concrete context-question triples for each causal level in the main text (or a clearly referenced appendix table) would allow readers to directly inspect potential confounds in phrasing and context construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concerns about potential confounds in benchmark construction and mechanistic analysis are well-taken, and we will strengthen the paper by adding the requested controls and validations. We respond point by point to the major comments below.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The paper does not provide explicit controls, ablations, or quantitative comparisons demonstrating that the three task families differ only in the demanded causal operation. Without evidence that context length, question phrasing complexity, lexical cues, and world-knowledge demands are matched across levels, the reported performance decline and the two diagnosed failure modes could be artifacts of general difficulty or prompt sensitivity rather than specific deficits in the causal hierarchy.
Authors: We agree that the manuscript would be strengthened by explicit quantitative controls and ablations. Although the benchmark was constructed with unified contexts and questions that vary primarily in the required causal operation, we did not include direct comparisons of non-causal factors such as context length, question length, or lexical complexity. In the revised version, we will add tables reporting these statistics across the three levels and perform ablations on difficulty-matched subsets to re-evaluate the performance trends. This will provide clearer evidence that the decline is driven by the causal hierarchy rather than confounding variables. revision: yes
-
Referee: [Mechanistic Analysis] Mechanistic Analysis section: Both the error-pattern identification and the internal information-flow tracing are conditioned on the same task partition. If that partition is confounded by non-causal factors, the attribution of failure mode (1) to lower-level distraction and failure mode (2) to higher-level faithfulness loss is not yet load-bearing; an independent validation (e.g., difficulty-matched controls or human difficulty ratings) is required.
Authors: We acknowledge that the mechanistic analyses rely on the same causal-level partitions and would benefit from independent validation. In the revision, we will incorporate human difficulty ratings collected from annotators on a subset of questions across levels, controlling for surface features. We will also report results on difficulty-matched controls and discuss how the information-flow tracing offers complementary internal evidence. These additions will make the attribution of the two failure modes more robust. revision: yes
Circularity Check
Empirical benchmarking study with no derivations or self-referential reductions
full rationale
The paper introduces the METER benchmark and reports direct empirical measurements of LLM performance across causal hierarchy levels, along with error pattern and information flow analyses. No equations, fitted parameters, or derivations are present that could reduce to inputs by construction. All claims rest on task definitions and observed metrics rather than any self-citation chain or ansatz. This is a standard empirical evaluation whose central results are falsifiable against the released dataset and code.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8420–8436, Bangkok, Thailand
Competition of mechanisms: Tracing how language models handle facts and counterfactuals. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8420–8436, Bangkok, Thailand. Association for Computational Linguistics. Judea Pearl and Dana Mackenzie. 2018.The book of why: the new science of c...
2018
-
[2]
Angelika Romanou, Syrielle Montariol, Debjit Paul, Leo Laugier, Karl Aberer, and Antoine Bosselut
Improving the accuracy of medical diagnosis with causal machine learning.Nature communica- tions, 11(1):3923. Angelika Romanou, Syrielle Montariol, Debjit Paul, Leo Laugier, Karl Aberer, and Antoine Bosselut
-
[3]
Can Large Language Models Infer Causal Relationships from Real-World Text?
CRAB: Assessing the strength of causal rela- tionships between real-world events. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15198–15216, Singapore. Association for Computational Linguis- tics. Ryan Saklad, Aman Chadha, Oleg Pavlov, and Raha Moraffah. 2025. Can large language models infer causal relatio...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Causal inference in the medical domain: A survey.Applied Intelligence, 54(6):4911–4934. Yongjie Xiao, Hongru Liang, Peixin Qin, Yao Zhang, and Wenqiang Lei. 2025. SCOP: Evaluating the com- prehension process of large language models from a cognitive view. InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (Volume 1...
-
[5]
Define Variables:X=Husband,Y=Alarm
-
[6]
Identify structure:X→Yand X→Wife→Y
-
[7]
Apply Total Probability Theorem for P(Y= 1): P(Y) =P(Y|X)P(X) +P(Y|¬X)P(¬X) = 0.76(0.77) + 0.26(1−0.77) = 0.5852 + 0.0598≈0.645
-
[8]
Answer:Yes
Compare with random chance (0.5): 0.645>0.5, so ringing is more likely. Answer:Yes. Table 7: Comparison of causal reasoning paradigms. essary conditions). We exclusively filter for rela- tions labeled asCAUSE, mapping the head event to the cause trigger and the tail event to the effect trig- ger. MECI establishes a multilingual benchmark based on Wikipedi...
2023
-
[9]
ForCausal Discovery, the templates consist of two categories: those inquiring about causes and those inquiring about effects
Finally, all generated questions are paraphrased by Gemini-2.5-pro to ensure natural, unambiguous phrasing. ForCausal Discovery, the templates consist of two categories: those inquiring about causes and those inquiring about effects. We instantiate these templates directly using the annotated cause or ef- fect events, and use the corresponding effect or c...
-
[10]
The final result is chosen by voting from all three annotators
Manual Editing.Given each instance, two annotators are required to perform manual editing of the generated question, answer, and distractors, and to resolve any errors identified by a third annotator. The final result is chosen by voting from all three annotators
-
[11]
Let’s think step by step
Manual Filtering.We applied a strict qual- ity control procedure by filtering each edited instance. Three annotators independently in- spected each entry against the verification standards. Any sample failing to meet these standards was discarded. The final decision to retain or reject a sample was reached through a majority vote among the three annotator...
2025
-
[12]
precise about the immediate officiating action
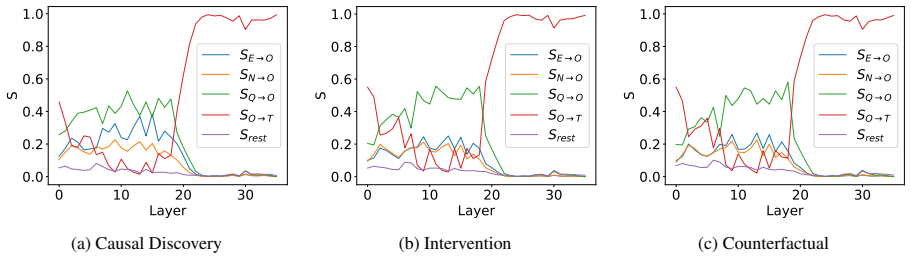
These declines confirm that evidence acts as a rigid constraint, effectively grounding the model’s generation to the provided context and minimizing hallucinations. However, we observed a counter-intuitive side effect: a consistent rise inCausal Reversalerrors. For instance,Qwen3-4Bsaw an increase in reversal errors from 22 to 35 in the Intervention task,...
2066
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.