Recognition: unknown
EdgeCIM: A Hardware-Software Co-Design for CIM-Based Acceleration of Small Language Models
Pith reviewed 2026-05-10 14:58 UTC · model grok-4.3
The pith
A 65nm compute-in-memory macro paired with tile-based mapping accelerates autoregressive decoding in small language models to reach average 336 tokens per second and 173 tokens per joule.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
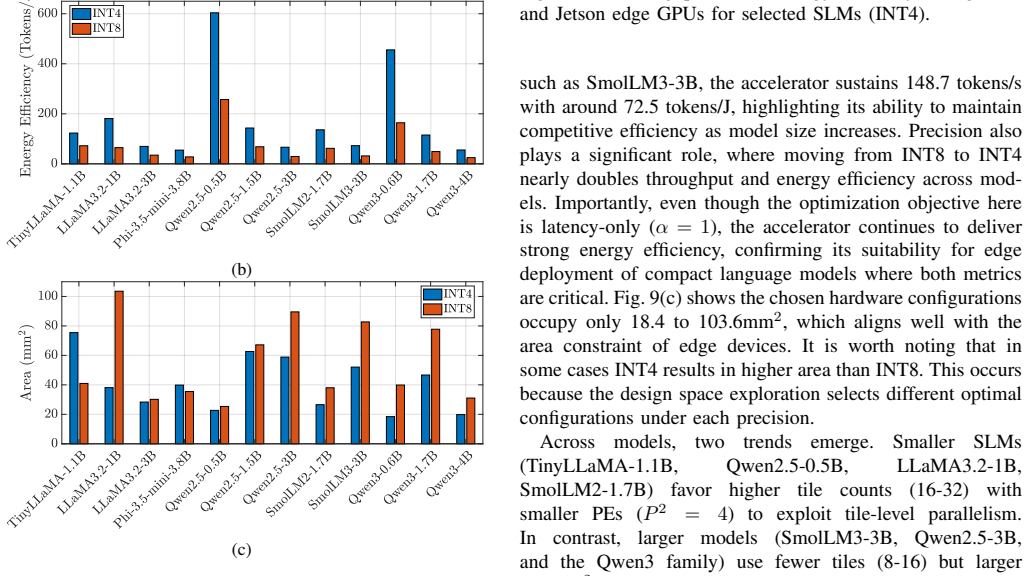
EdgeCIM shows that a hardware-software co-design built around a 65nm CIM macro and a tile-based mapping strategy that balances pipeline stages can deliver end-to-end inference for decoder-only SLMs, achieving up to 7.3x higher throughput and 49.59x better energy efficiency than an NVIDIA Orin Nano on LLaMA3.2-1B, 9.95x higher throughput than a Qualcomm SA8255P on LLaMA3.2-3B, and average performance of 336.42 tokens/s and 173.02 tokens/J under INT4 across tested models from 0.5B to 4B parameters.
What carries the argument
A 65nm CIM macro integrated with a tile-based mapping strategy that balances pipeline stages to reduce DRAM bandwidth demands during autoregressive decoding.
If this is right
- Design-space exploration becomes feasible for SLMs up to 4B parameters to identify latency-energy Pareto fronts.
- End-to-end acceleration covers both prefill and autoregressive phases without separate hardware paths.
- Average 336 tokens/s and 173 tokens/J under INT4 enables real-time local inference on laptops, phones, and embedded platforms.
- The same macro and mapping deliver consistent gains across TinyLLaMA-1.1B, LLaMA3.2 variants, Phi-3.5-mini, Qwen2.5 series, SmolLM models, and Qwen3 series.
Where Pith is reading between the lines
- Extending the tile mapping to support mixed-precision or sparse attention could further reduce energy for longer contexts.
- Lower per-token energy opens the possibility of always-on on-device agents that run for hours on a single charge.
- If the 65nm process is replaced by a more advanced node while keeping the mapping, throughput could scale without proportional power increase.
- The approach highlights a general route for memory-bound sequential workloads beyond language models, such as streaming audio or sensor fusion.
Load-bearing premise
The simulator of the 65nm CIM macro accurately captures real hardware behavior and the tile mapping fully balances stages without hidden overheads that would reduce the reported speed and efficiency gains.
What would settle it
Fabricate the 65nm CIM macro in silicon, implement the full EdgeCIM mapping on a test chip, and run LLaMA3.2-1B inference to measure actual tokens per second and joules per token against the simulator predictions.
Figures






read the original abstract
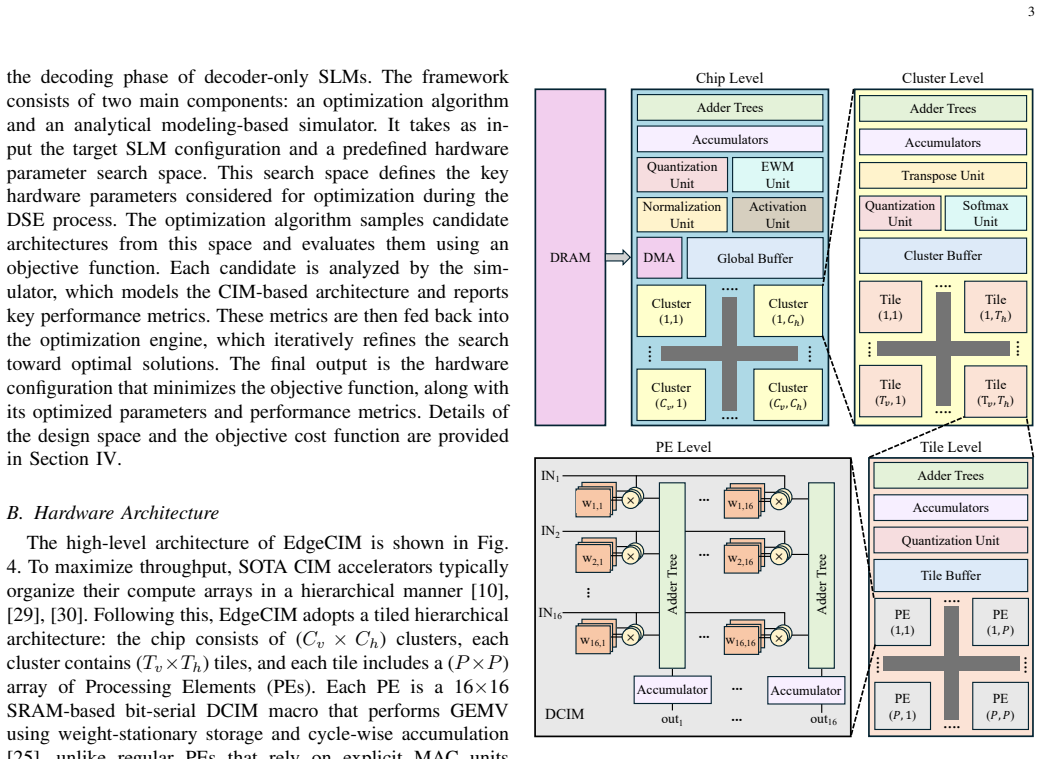
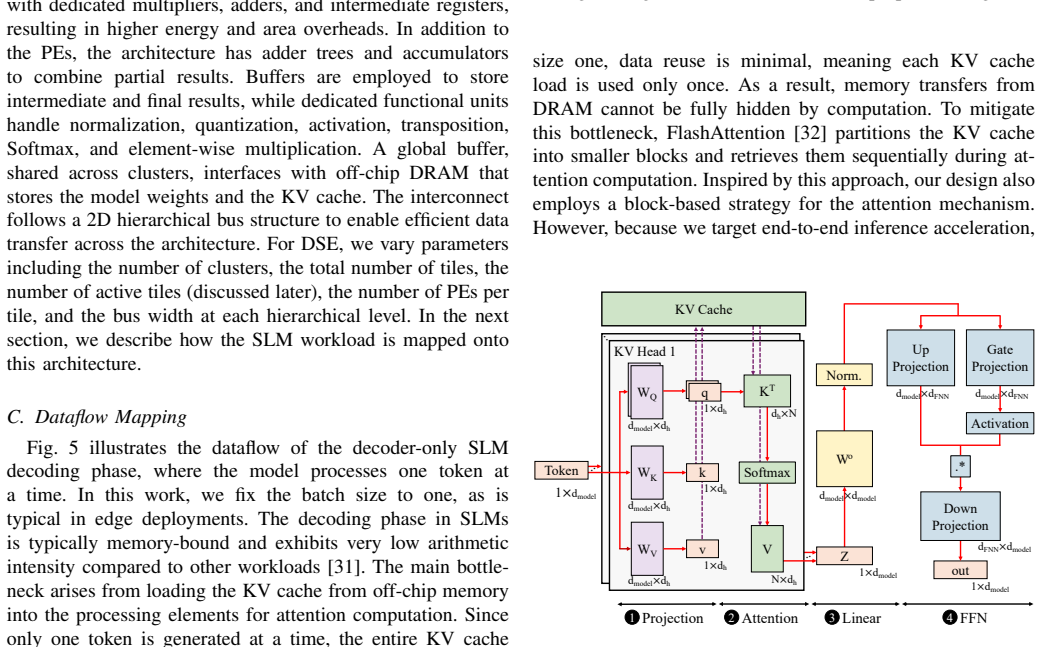
The growing demand for deploying Small Language Models (SLMs) on edge devices, including laptops, smartphones, and embedded platforms, has exposed fundamental inefficiencies in existing accelerators. While GPUs handle prefill workloads efficiently, the autoregressive decoding phase is dominated by GEMV operations that are inherently memory-bound, resulting in poor utilization and prohibitive energy costs at the edge. In this work, we present EdgeCIM, a hardware-software co-design framework that rethinks accelerator design for end-to-end decoder-only inference. At its core is a CIM macro, implemented in 65nm, coupled with a tile-based mapping strategy that balances pipeline stages, maximizing parallelism while alleviating DRAM bandwidth bottlenecks. Our simulator enables design space exploration of SLMs up to 4B parameters, identifying Pareto-optimal configurations in terms of latency and energy. Compared to an NVIDIA Orin Nano, EdgeCIM achieves up to 7.3x higher throughput and 49.59x better energy efficiency on LLaMA3.2-1B, and delivers 9.95x higher throughput than Qualcomm SA8255P on LLaMA3.2-3B. Extensive benchmarks on TinyLLaMA-1.1B, LLaMA3.2 (1B, 3B), Phi-3.5-mini-3.8B, Qwen2.5 (0.5B, 1.5B, 3B), SmolLM2-1.7B, SmolLM3-3B, and Qwen3 (0.6B, 1.7B, 4B) reveal that our accelerator, under INT4 precision, achieves on average 336.42 tokens/s and 173.02 tokens/J. These results establish EdgeCIM as a compelling solution towards real-time, energy-efficient edge-scale SLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EdgeCIM, a hardware-software co-design for CIM-based acceleration of small language models (SLMs) on edge devices. It centers on a 65nm CIM macro paired with a tile-based mapping strategy to optimize the memory-bound GEMV operations in autoregressive decoding of decoder-only models up to 4B parameters. A simulator is used for design-space exploration, yielding Pareto-optimal configurations; the authors report up to 7.3× throughput and 49.59× energy-efficiency gains versus NVIDIA Orin Nano on LLaMA3.2-1B, 9.95× throughput versus Qualcomm SA8255P on LLaMA3.2-3B, and average performance of 336.42 tokens/s and 173.02 tokens/J under INT4 across a suite of models including TinyLLaMA, Phi-3.5, Qwen2.5, and SmolLM variants.
Significance. If the simulator results hold under realistic silicon conditions, the work would be significant for edge AI deployment by demonstrating a concrete path to high-throughput, low-energy SLM inference that directly targets the decoding-phase bottleneck. The breadth of evaluated models and direct comparisons against commercial mobile SoCs provide useful reference points; the co-design emphasis on pipeline balancing and DRAM alleviation is a timely contribution to the CIM accelerator literature.
major comments (3)
- [§4 and §3.2] §4 (Evaluation Methodology) and §3.2 (CIM Macro Simulator): All headline metrics (7.3× throughput, 49.59× energy efficiency, 336.42 tokens/s average) rest exclusively on the 65nm CIM macro simulator; no SPICE-level validation, fabricated-chip measurements, or quantified sensitivity analysis to device variation, interconnect RC, or peripheral overheads is provided. This is load-bearing because optimistic assumptions in the simulator directly determine whether the reported Pareto fronts and cross-platform speedups translate to real hardware.
- [§3.3] §3.3 (Tile-based Mapping Strategy): The claim that the tile mapping successfully balances pipeline stages and removes DRAM bandwidth bottlenecks during token-by-token autoregressive GEMV is stated without quantitative breakdown of stall cycles, control overhead, or data-movement energy for models ≥1B parameters. If these overheads are non-negligible, the 9.95× throughput advantage versus SA8255P and the 173.02 tokens/J figure would be overstated.
- [Table 2 / Figure 7] Table 2 / Figure 7 (Baseline Comparisons): The energy-efficiency and throughput numbers versus Orin Nano and SA8255P assume identical INT4 precision, batch-1 decoding, and identical model weights; any unstated differences in quantization scheme, KV-cache management, or platform power measurement methodology would invalidate the direct 49.59× and 9.95× ratios.
minor comments (3)
- [Abstract and §1] The abstract and §1 cite “up to 4B parameters” yet the largest evaluated model is Qwen3-4B; clarify whether the simulator was actually exercised at 4B or whether the claim is extrapolated.
- [Figures 5–8] Several figures lack error bars or sensitivity ranges on the simulator-derived metrics; adding these would strengthen the presentation of Pareto-optimal points.
- [§4.1] Notation for energy efficiency (tokens/J) is introduced without an explicit definition of the power measurement window (average vs. peak, including or excluding DRAM).
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment below with honest responses based on the manuscript's simulator-driven methodology. Where appropriate, we agree to revisions that add clarity and analysis without misrepresenting the work's scope.
read point-by-point responses
-
Referee: [§4 and §3.2] All headline metrics rest exclusively on the 65nm CIM macro simulator; no SPICE-level validation, fabricated-chip measurements, or quantified sensitivity analysis to device variation, interconnect RC, or peripheral overheads is provided.
Authors: We agree that the results depend on the simulator and that fabricated silicon would provide stronger validation. The simulator in §3.2 is built from calibrated 65nm device models and circuit-level characterizations drawn from prior published CIM work; however, we did not include explicit sensitivity sweeps. In revision we will add a dedicated subsection with quantified sensitivity analysis to device variation, interconnect RC, and peripheral overheads, including new figures showing impact on the reported Pareto fronts and tokens/s metrics. Fabrication of a test chip lies outside the scope of this co-design exploration paper. revision: partial
-
Referee: [§3.3] The claim that the tile mapping successfully balances pipeline stages and removes DRAM bandwidth bottlenecks is stated without quantitative breakdown of stall cycles, control overhead, or data-movement energy for models ≥1B parameters.
Authors: We accept this observation. The original §3.3 described the mapping at a high level. We will revise the section to include simulator-derived quantitative breakdowns: stall-cycle percentages, control overhead estimates, and energy split between data movement and computation for LLaMA3.2-1B and 3B under the proposed tile mapping. These data will confirm that the overheads remain small relative to the achieved throughput and energy gains. revision: yes
-
Referee: [Table 2 / Figure 7] The energy-efficiency and throughput numbers versus Orin Nano and SA8255P assume identical INT4 precision, batch-1 decoding, and identical model weights; any unstated differences in quantization scheme, KV-cache management, or platform power measurement methodology would invalidate the ratios.
Authors: We agree that transparent methodology is required. The manuscript already states INT4 precision and batch-1 autoregressive decoding for all platforms. We will expand the Table 2 caption and add a clarifying paragraph in §4 that details KV-cache placement (on-chip SRAM in EdgeCIM), the exact power figures used for the commercial SoCs (datasheet TDP and literature-reported averages), and any quantization assumptions. If minor discrepancies are identified, the speedup numbers will be adjusted accordingly. revision: yes
Circularity Check
No circularity: external hardware benchmarks and simulator-based design exploration remain independent
full rationale
The paper's derivation consists of a 65nm CIM macro simulator, tile-based mapping for decoder-only GEMV workloads, and design-space exploration up to 4B-parameter SLMs. All reported metrics (throughput, energy efficiency, tokens/s, tokens/J) are generated from this simulator and then compared directly to independent commercial platforms (NVIDIA Orin Nano, Qualcomm SA8255P). No equations, fitted parameters, or self-citations are shown to reduce the final claims to the inputs by construction. The comparisons are externally falsifiable against real silicon, satisfying the criteria for non-circular, self-contained evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiahet al., “Language models are few-shot learners,”Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
1901
-
[2]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inNAACL- HLT, 2019, pp. 4171–4186
2019
-
[3]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmaret al., “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998– 6008
2017
-
[4]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borcherset al., “In-datacenter performance analysis of a tensor processing unit,” inProceedings of the 44th annual international symposium on computer architecture, 2017, pp. 1–12
2017
-
[5]
Edgebert: Sentence-level energy optimiza- tions for latency-aware multi-task nlp inference,
T. Tambe, A. Haj-Aliet al., “Edgebert: Sentence-level energy optimiza- tions for latency-aware multi-task nlp inference,” inMICRO, 2021, pp. 830–844
2021
-
[6]
llama.cpp: A fast inference of llama models,
G. Gerganov and contributors, “llama.cpp: A fast inference of llama models,” https://github.com/ggerganov/llama.cpp, 2023
2023
-
[7]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, I. Sutskeveret al., “Improving language understanding by generative pre-training,” 2018. 8
2018
-
[8]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
In-memory computing: Advances and prospects,
N. Verma, A. Shafiee, and et al., “In-memory computing: Advances and prospects,”IEEE Solid-State Circuits Magazine, vol. 11, no. 3, pp. 43– 55, 2019
2019
-
[10]
Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,
A. Shafiee, A. Nag, N. Muralimanohar, R. Balasubramonian, J. P. Stra- chan, M. Hu, R. S. Williams, and V . Srikumar, “Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,” ACM SIGARCH Computer Architecture News, vol. 44, no. 3, pp. 14–26, 2016
2016
-
[11]
Bf-imna: A bit fluid in-memory neural architecture for neural network acceleration,
M. Rakka, R. Karami, A. M. Eltawil, M. E. Fouda, and F. Kurdahi, “Bf-imna: A bit fluid in-memory neural architecture for neural network acceleration,”arXiv preprint arXiv:2411.01417, 2024
-
[12]
Pipelayer: A pipelined reram- based accelerator for deep learning,
L. Song, X. Qian, H. Li, and Y . Chen, “Pipelayer: A pipelined reram- based accelerator for deep learning,” in2017 IEEE international sym- posium on high performance computer architecture (HPCA). IEEE, 2017, pp. 541–552
2017
-
[13]
X-former: In-memory acceleration of transformers,
S. Sridharan, J. R. Stevens, K. Roy, and A. Raghunathan, “X-former: In-memory acceleration of transformers,”IEEE Transactions on VLSI Systems, vol. 31, no. 8, pp. 1223–1233, 2023
2023
-
[14]
Retransformer: Reram-based processing-in-memory architecture for transformer acceleration,
X. Yang, B. Yan, H. Li, and Y . Chen, “Retransformer: Reram-based processing-in-memory architecture for transformer acceleration,” in Proceedings of the 39th International Conference on Computer-Aided Design, 2020, pp. 1–9
2020
-
[15]
Trancim: Full-digital bitline-transpose cim-based sparse transformer accelerator with pipeline/parallel reconfigurable modes,
F. Tu, Z. Wu, Y . Wang, L. Liang, L. Liu, Y . Ding, L. Liu, S. Wei, Y . Xie, and S. Yin, “Trancim: Full-digital bitline-transpose cim-based sparse transformer accelerator with pipeline/parallel reconfigurable modes,” IEEE Journal of Solid-State Circuits, vol. 58, no. 6, pp. 1798–1809, 2023
2023
-
[16]
Small language models: Survey, measurements, and insights.arXiv preprint arXiv:2409.15790, 2024
Z. Lu, X. Li, D. Cai, R. Yi, F. Liu, X. Zhang, N. D. Lane, and M. Xu, “Small language models: Survey, measurements, and insights,”arXiv preprint arXiv:2409.15790, 2024
-
[17]
Efficient inference for autoregressive models with dynamic batching,
Y . Kim and et al., “Efficient inference for autoregressive models with dynamic batching,”arXiv preprint arXiv:1909.01953, 2019
-
[18]
An 8- mb dc-current-free binary-to-8b precision reram nonvolatile computing- in-memory macro using time-space-readout with 1286.4-21.6 tops/w for edge-ai devices,
J.-M. Hung, Y .-H. Huang, S.-P. Huang, F.-C. Chang, T.-H. Wen, C.- I. Su, W.-S. Khwa, C.-C. Lo, R.-S. Liu, C.-C. Hsiehet al., “An 8- mb dc-current-free binary-to-8b precision reram nonvolatile computing- in-memory macro using time-space-readout with 1286.4-21.6 tops/w for edge-ai devices,” in2022 IEEE International Solid-State Circuits Conference (ISSCC),...
2022
-
[19]
16.1 a 22nm 4mb 8b-precision reram computing-in-memory macro with 11.91 to 195.7 tops/w for tiny ai edge devices,
C.-X. Xue, J.-M. Hung, H.-Y . Kao, Y .-H. Huang, S.-P. Huang, F.-C. Chang, P. Chen, T.-W. Liu, C.-J. Jhang, C.-I. Suet al., “16.1 a 22nm 4mb 8b-precision reram computing-in-memory macro with 11.91 to 195.7 tops/w for tiny ai edge devices,” in2021 IEEE International Solid-State Circuits Conference (ISSCC), vol. 64. IEEE, 2021, pp. 245–247
2021
-
[20]
A 22nm 4mb stt- mram data-encrypted near-memory computation macro with a 192gb/s read-and-decryption bandwidth and 25.1-55.1 tops/w 8b mac for ai operations,
Y .-C. Chiu, C.-S. Yang, S.-H. Teng, H.-Y . Huang, F.-C. Chang, Y . Wu, Y .-A. Chien, F.-L. Hsieh, C.-Y . Li, G.-Y . Linet al., “A 22nm 4mb stt- mram data-encrypted near-memory computation macro with a 192gb/s read-and-decryption bandwidth and 25.1-55.1 tops/w 8b mac for ai operations,” in2022 IEEE International Solid-State Circuits Conference (ISSCC), vo...
2022
-
[21]
Mdcim: Mram-based digital computing-in-memory macro for floating-point computation with high energy efficiency and low area overhead,
L. Liu, L. Tan, J. Gan, B. Pan, J. Zhou, and Z. Li, “Mdcim: Mram-based digital computing-in-memory macro for floating-point computation with high energy efficiency and low area overhead,”Applied Sciences, vol. 13, no. 21, p. 11914, 2023
2023
-
[22]
Re- configurable precision sram-based analog in-memory-compute macro design,
J. Bazzi, R. Jamil, D. ElHajj, R. Kanj, M. E. Fouda, and A. Eltawil, “Re- configurable precision sram-based analog in-memory-compute macro design,” in2024 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2024, pp. 1–5
2024
-
[23]
Redcim: Reconfigurable digital computing-in- memory processor with unified fp/int pipeline for cloud ai acceleration,
F. Tu, Y . Wang, Z. Wu, L. Liang, Y . Ding, B. Kim, L. Liu, S. Wei, Y . Xie, and S. Yin, “Redcim: Reconfigurable digital computing-in- memory processor with unified fp/int pipeline for cloud ai acceleration,” IEEE Journal of Solid-State Circuits, vol. 58, no. 1, pp. 243–255, 2022
2022
-
[24]
Reconfigurable precision int4- 8/fp8 digital compute-in-memory macro for ai acceleration,
J. Bazzi, M. E. Fouda, and A. Eltawil, “Reconfigurable precision int4- 8/fp8 digital compute-in-memory macro for ai acceleration,” in2025 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2025, pp. 1–5
2025
-
[25]
16.4 an 89tops/w and 16.3 tops/mm 2 all-digital sram-based full-precision compute-in memory macro in 22nm for machine-learning edge applications,
Y .-D. Chih, P.-H. Lee, H. Fujiwara, Y .-C. Shih, C.-F. Lee, R. Naous, Y .-L. Chen, C.-P. Lo, C.-H. Lu, H. Moriet al., “16.4 an 89tops/w and 16.3 tops/mm 2 all-digital sram-based full-precision compute-in memory macro in 22nm for machine-learning edge applications,” in2021 IEEE International Solid-State Circuits Conference (ISSCC), vol. 64. IEEE, 2021, pp...
2021
-
[26]
Towards fully 8-bit integer inference for the transformer model,
Y . Lin, Y . Liet al., “Towards fully 8-bit integer inference for the transformer model,”IJCAI, pp. 3759–3765, 2020
2020
-
[27]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkbooset al., “Gptq: Accurate post-training quantization for generative pre-trained transformers,”arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review arXiv 2022
-
[28]
Qat: Quantization-aware training for efficient transformer inference,
Y . Wang, S. Liuet al., “Qat: Quantization-aware training for efficient transformer inference,”IEEE Transactions on Neural Networks and Learning Systems, 2023
2023
-
[29]
Puma: A programmable ultra-efficient memristor-based accelerator for machine learning inference,
A. Ankit, I. E. Hajj, S. R. Chalamalasetti, G. Ndu, M. Foltin, R. S. Williams, P. Faraboschi, W.-m. W. Hwu, J. P. Strachan, K. Royet al., “Puma: A programmable ultra-efficient memristor-based accelerator for machine learning inference,” inProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Opera...
2019
-
[30]
Hastily: Hardware-software co- design for accelerating transformer inference leveraging compute-in- memory,
D. E. Kim, T. Sharma, and K. Roy, “Hastily: Hardware-software co- design for accelerating transformer inference leveraging compute-in- memory,”IEEE Transactions on Circuits and Systems for Artificial Intelligence, 2025
2025
-
[31]
Full stack optimization of transformer inference: a survey,
S. Kim, C. Hooper, T. Wattanawong, M. Kang, R. Yan, H. Genc, G. Dinh, Q. Huang, K. Keutzer, M. W. Mahoneyet al., “Full stack optimization of transformer inference: a survey,”arXiv preprint arXiv:2302.14017, 2023
-
[32]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in neural information processing systems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[33]
Optimizing nuca organizations and wiring alternatives for large caches with cacti 6.0,
N. Muralimanohar, R. Balasubramonian, and N. Jouppi, “Optimizing nuca organizations and wiring alternatives for large caches with cacti 6.0,” in40th Annual IEEE/ACM International Symposium on Microar- chitecture (MICRO 2007). IEEE, 2007, pp. 3–14
2007
-
[34]
Domain-specific hardware accelerators,
W. J. Dally, Y . Turakhia, and S. Han, “Domain-specific hardware accelerators,”Communications of the ACM, vol. 63, no. 7, pp. 48–57, 2020
2020
-
[35]
TinyLlama: An Open-Source Small Language Model
P. Zhang, G. Zeng, T. Wang, and W. Lu, “Tinyllama: An open-source small language model,”arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review arXiv 2024
-
[36]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models,
Meta AI, “Llama 3.2: Revolutionizing edge ai and vision with open, customizable models,” https://ai.meta.com/blog/ llama-3-2-connect-2024-vision-edge-mobile-devices/, Sep. 2024
2024
-
[37]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. Awan, and et al., “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review arXiv 2024
-
[38]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, and et al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
L. B. Allal, A. Lozhkov, E. Bakouch, G. M. Bl ´azquez, G. Penedo, L. Tunstall, A. Marafioti, H. Kydl ´ıˇcek, A. P. Lajar ´ın, V . Srivastav et al., “Smollm2: When smol goes big–data-centric training of a small language model,”arXiv preprint arXiv:2502.02737, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
Smollm3: smol, mul- tilingual, long-context reasoner,
E. Bakouch, L. B. Allal, A. Lozhkov, and et al., “Smollm3: smol, mul- tilingual, long-context reasoner,” https://huggingface.co/blog/smollm3, Jul. 2025
2025
-
[41]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, and et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Nvidia jetson ai lab,
NVIDIA, “Nvidia jetson ai lab,” https://www.jetson-ai-lab.com/ benchmarks.html
-
[43]
Llama-v3.2-3B-Instruct,
Qualcomm AI Hub, “Llama-v3.2-3B-Instruct,” https://aihub.qualcomm. com/models/llama v3 2 3b instruct?searchTerm=llama-v3
-
[44]
Hardware-software co-design of an in-memory transformer network accelerator,
A. F. Laguna, M. M. Sharifi, A. Kazemi, X. Yin, M. Niemier, and X. S. Hu, “Hardware-software co-design of an in-memory transformer network accelerator,”Frontiers in Electronics, vol. 3, p. 847069, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.