Recognition: unknown
GeomPrompt: Geometric Prompt Learning for RGB-D Semantic Segmentation Under Missing and Degraded Depth
Pith reviewed 2026-05-10 15:43 UTC · model grok-4.3
The pith
GeomPrompt creates a geometric prompt from RGB alone to serve as the depth channel for frozen RGB-D semantic segmentation models when depth is missing or degraded.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
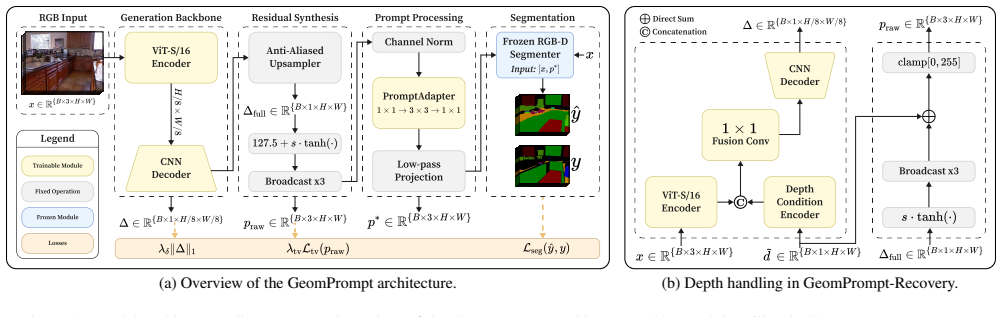
GeomPrompt synthesizes a task-driven geometric prompt from RGB alone for the fourth channel of a frozen RGB-D semantic segmentation model without depth supervision. On SUN RGB-D it raises performance over RGB-only inference by 6.1 mIoU on DFormer and 3.0 mIoU on GeminiFusion while staying competitive with monocular depth estimators yet running at 7.8 ms latency. GeomPrompt-Recovery extends the same idea by predicting a fourth-channel correction that improves robustness under depth corruptions, delivering gains up to 3.6 mIoU.
What carries the argument
GeomPrompt, a lightweight cross-modal adaptation module that generates a task-driven geometric prompt from RGB to populate the depth channel of a frozen segmenter.
If this is right
- Segmentation quality improves over RGB-only baselines under missing depth without needing depth ground truth.
- A parallel recovery module restores performance when depth is present but degraded.
- The approach runs substantially faster than pipelines that first compute monocular depth.
- Both modules are trained end-to-end with segmentation supervision alone.
Where Pith is reading between the lines
- Task-guided geometric features extracted from RGB may substitute for explicit depth maps in other RGB-D downstream tasks.
- The prompting technique could be applied to additional sensor-failure scenarios such as camera occlusion or lighting changes.
- Further tests on real-time robotic platforms would show whether the latency savings translate to practical reliability gains.
Load-bearing premise
A prompt optimized solely for segmentation accuracy on RGB images can recover geometric information that remains useful to the frozen model when depth is absent or corrupted.
What would settle it
Running the trained GeomPrompt on a new dataset containing scene types or depth failure patterns absent from SUN RGB-D training, then measuring whether the mIoU gains disappear or reverse.
Figures




read the original abstract
Multimodal perception systems for robotics and embodied AI often assume reliable RGB-D sensing, but in practice, depth is frequently missing, noisy, or corrupted. We thus present GeomPrompt, a lightweight cross-modal adaptation module that synthesizes a task-driven geometric prompt from RGB alone for the fourth channel of a frozen RGB-D semantic segmentation model, without depth supervision. We further introduce GeomPrompt-Recovery, an adaptation module that compensates for degraded depth by predicting the fourth channel correction relevant for the frozen segmenter. Both modules are trained solely with downstream segmentation supervision, enabling recovery of the geometric prior useful for segmentation, rather than estimating depth signals. On SUN RGB-D, GeomPrompt improves over RGB-only inference by +6.1 mIoU on DFormer and +3.0 mIoU on GeminiFusion, while remaining competitive with strong monocular depth estimators. For degraded depth, GeomPrompt-Recovery consistently improves robustness, yielding gains up to +3.6 mIoU under severe depth corruptions. GeomPrompt is also substantially more efficient than monocular depth baselines, reaching 7.8 ms latency versus 38.3 ms and 71.9 ms. These results suggest that task-driven geometric prompting is an efficient mechanism for cross-modal compensation under missing and degraded depth inputs in RGB-D perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GeomPrompt, a lightweight cross-modal adaptation module that synthesizes a task-driven geometric prompt from RGB alone to serve as the fourth (depth) channel input to a frozen RGB-D semantic segmentation model, without any depth supervision or explicit depth estimation. It also presents GeomPrompt-Recovery for compensating degraded depth inputs. Both modules are trained solely via the downstream segmentation loss. On SUN RGB-D, GeomPrompt yields +6.1 mIoU over RGB-only inference for DFormer and +3.0 mIoU for GeminiFusion, remains competitive with monocular depth estimators, and is substantially faster (7.8 ms latency); GeomPrompt-Recovery provides up to +3.6 mIoU robustness gains under depth corruptions.
Significance. If the central claim holds, the work offers an efficient mechanism for cross-modal compensation in RGB-D perception under unreliable depth, which is valuable for robotics and embodied AI. The reported latency advantage and lack of requirement for depth labels or separate depth estimators are clear practical strengths. Significance is reduced, however, by the absence of evidence that the learned prompt encodes a transferable geometric prior rather than dataset- or model-specific compensations.
major comments (3)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): All quantitative gains (+6.1 / +3.0 mIoU) are measured on the SUN RGB-D test split after training the prompt on the same SUN RGB-D training distribution; no cross-dataset transfer results (e.g., training on SUN RGB-D and evaluating on NYUv2 or ScanNet) are reported, leaving open whether the prompt recovers a generalizable geometric signal or merely fits dataset-specific RGB–label correlations.
- [§3 (Method)] §3 (Method): The geometric prompt is defined and optimized exclusively against the segmentation objective on the target data with no auxiliary geometric loss, depth supervision, or independent geometric benchmark; this makes the interpretation that the module “recovers the geometric prior useful for segmentation, rather than estimating depth signals” circular by construction and requires additional disambiguation.
- [§4 (Results)] §4 (Results): The abstract and results lack details on training procedure, number of runs, statistical significance of the reported mIoU deltas, and ablations on prompt formulation or injection mechanism; these omissions directly limit verification of the central claim that the synthesized prompt is geometrically meaningful to the frozen segmenter.
minor comments (2)
- [Figure 1 and §3.1] Figure 1 and §3.1: The diagram and text describing how the synthesized prompt is concatenated or injected as the fourth channel should explicitly state tensor shapes and whether any normalization or scaling is applied before feeding the frozen model.
- [Related Work] Related Work: Consider citing recent prompt-tuning and adapter methods for multimodal segmentation to better situate the novelty of the task-driven geometric formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment below, providing clarifications and indicating where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] All quantitative gains (+6.1 / +3.0 mIoU) are measured on the SUN RGB-D test split after training the prompt on the same SUN RGB-D training distribution; no cross-dataset transfer results (e.g., training on SUN RGB-D and evaluating on NYUv2 or ScanNet) are reported, leaving open whether the prompt recovers a generalizable geometric signal or merely fits dataset-specific RGB–label correlations.
Authors: We acknowledge that cross-dataset transfer experiments would provide stronger support for the generalizability of the learned prompt beyond dataset-specific correlations. Our primary focus was on SUN RGB-D as a standard, challenging benchmark for RGB-D segmentation. In the revised manuscript, we will add results training on SUN RGB-D and evaluating on NYUv2 to directly address this point and better substantiate the claim of a transferable geometric prior. revision: yes
-
Referee: [§3 (Method)] The geometric prompt is defined and optimized exclusively against the segmentation objective on the target data with no auxiliary geometric loss, depth supervision, or independent geometric benchmark; this makes the interpretation that the module “recovers the geometric prior useful for segmentation, rather than estimating depth signals” circular by construction and requires additional disambiguation.
Authors: The absence of auxiliary geometric losses or depth supervision is a deliberate design choice to learn a task-driven prompt that leverages the geometric capabilities already encoded in the frozen RGB-D model, rather than performing explicit depth estimation. The observed gains over RGB-only inference provide empirical support for the utility of the synthesized prompt. To further disambiguate and strengthen the geometric interpretation, we will include additional analysis such as prompt visualizations and comparisons against monocular depth outputs in the revision. revision: partial
-
Referee: [§4 (Results)] The abstract and results lack details on training procedure, number of runs, statistical significance of the reported mIoU deltas, and ablations on prompt formulation or injection mechanism; these omissions directly limit verification of the central claim that the synthesized prompt is geometrically meaningful to the frozen segmenter.
Authors: We agree that additional experimental details are necessary for rigorous verification. In the revised manuscript, we will expand §4 to include complete training procedure and hyperparameter specifications, results over multiple runs with standard deviations to assess statistical significance of the mIoU improvements, and further ablations on prompt formulation and injection strategies. revision: yes
Circularity Check
No significant circularity; empirical adaptation trained on segmentation loss with explicit distinction from depth estimation
full rationale
The paper describes GeomPrompt as a lightweight module that generates a prompt for the depth channel of a frozen RGB-D segmenter, trained exclusively via downstream segmentation supervision on SUN RGB-D without any depth ground truth or geometric regularizer. The reported gains (+6.1 mIoU, +3.0 mIoU) are direct empirical measurements of the trained module's effect on the same task and dataset; no derivation chain, equation, or uniqueness claim reduces the prompt to a tautological re-expression of the segmentation loss or to a self-citation. The text explicitly contrasts the approach with depth estimation, and no load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results appear in the provided description. The method is therefore a standard supervised adapter whose validity rests on held-out test performance rather than on any definitional or fitted-input loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RGB images contain recoverable geometric cues sufficient for segmentation when depth is absent
invented entities (1)
-
task-driven geometric prompt
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Improving 3D Reconstruction Through RGB-D Sensor Noise Modeling.Sensors, 25(3):950, 2025
Fahira Afzal Maken, Sundaram Muthu, Chuong Nguyen, Changming Sun, Jinguang Tong, Shan Wang, Russell Tsuchida, David Howard, Simon Dunstall, and Lars Peters- son. Improving 3D Reconstruction Through RGB-D Sensor Noise Modeling.Sensors, 25(3):950, 2025. 6
2025
-
[2]
Improving Feature Stability During Upsampling – Spectral Artifacts and the Importance of Spatial Context
Shashank Agnihotri, Julia Grabinski, and Margret Keuper. Improving Feature Stability During Upsampling – Spectral Artifacts and the Importance of Spatial Context. InCom- puter Vision – ECCV 2024, pages 357–376. Springer Nature Switzerland, Cham, 2025. 3
2024
-
[3]
Barron and Jitendra Malik
Jonathan T. Barron and Jitendra Malik. Shape, albedo, and illumination from a single image of an unknown object. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 334–341, 2012. 7
2012
-
[4]
Diffusion-based RGB-D Semantic Segmentation with Deformable Attention Trans- former
Minh Bui and Kostas Alexis. Diffusion-based RGB-D Semantic Segmentation with Deformable Attention Trans- former. In2025 IEEE International Conference on Advanced Robotics (ICAR), pages 404–411, San Juan, Argentina, 2025. IEEE. 3
2025
-
[5]
A Computational Approach to Edge Detection
John Canny. A Computational Approach to Edge Detection. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, PAMI-8(6):679–698, 1986. 7
1986
-
[6]
Plugging Self- Supervised Monocular Depth into Unsupervised Domain Adaptation for Semantic Segmentation
Adriano Cardace, Luca De Luigi, Pierluigi Zama Ramirez, Samuele Salti, and Luigi Di Stefano. Plugging Self- Supervised Monocular Depth into Unsupervised Domain Adaptation for Semantic Segmentation. In2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1999–2009, Waikoloa, HI, USA, 2022. IEEE. 3
1999
-
[7]
Depth Matters: Ex- ploring Deep Interactions of RGB-D for Semantic Segmen- tation in Traffic Scenes
Siyu Chen, Ting Han, Changshe Zhang, Weiquan Liu, Jinhe Su, Zongyue Wang, and Guorong Cai. Depth Matters: Ex- ploring Deep Interactions of RGB-D for Semantic Segmen- tation in Traffic Scenes. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7834–7841, Hangzhou, China, 2025. IEEE. 2, 3
2025
-
[8]
Learning Semantic Segmentation From Synthetic Data: A Geometrically Guided Input-Output Adaptation Approach
Yuhua Chen, Wen Li, Xiaoran Chen, and Luc Van Gool. Learning Semantic Segmentation From Synthetic Data: A Geometrically Guided Input-Output Adaptation Approach. In2019 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 1841–1850, Long Beach, CA, USA, 2019. IEEE. 3
2019
-
[9]
Statistical Analysis-Based Error Models for the Microsoft KinectTM Depth Sensor.Sensors, 14(9):17430– 17450, 2014
Benjamin Choo, Michael Landau, Michael DeV ore, and Pe- ter Beling. Statistical Analysis-Based Error Models for the Microsoft KinectTM Depth Sensor.Sensors, 14(9):17430– 17450, 2014. 6
2014
-
[10]
Learn- ing Depth Estimation for Transparent and Mirror Surfaces
Alex Costanzino, Pierluigi Zama Ramirez, Matteo Poggi, Fabio Tosi, Stefano Mattoccia, and Luigi Di Stefano. Learn- ing Depth Estimation for Transparent and Mirror Surfaces. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9210–9221, Paris, France, 2023. IEEE. 6
2023
-
[11]
Semantic Information for Robot Navigation: A Survey.Applied Sciences, 10(2):497, 2020
Jonathan Crespo, Jose Carlos Castillo, Oscar Martinez Mo- zos, and Ramon Barber. Semantic Information for Robot Navigation: A Survey.Applied Sciences, 10(2):497, 2020. 2
2020
-
[12]
ImageNet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical im- age database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, Miami, FL, 2009. IEEE. 3
2009
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, 2020
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, 2020. 3
2020
-
[14]
AsymFormer: Asymmetrical Cross- Modal Representation Learning for Mobile Platform Real- Time RGB-D Semantic Segmentation
Siqi Du, Weixi Wang, Renzhong Guo, Ruisheng Wang, and Shengjun Tang. AsymFormer: Asymmetrical Cross- Modal Representation Learning for Mobile Platform Real- Time RGB-D Semantic Segmentation. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 7608–7615, Seattle, W A, USA,
-
[15]
Pereira, Catarina Moreira, Jacinto C
Alexandre Duarte, Francisco Fernandes, Jo ˜ao M. Pereira, Catarina Moreira, Jacinto C. Nascimento, and Joaquim Jorge. Selfredepth: Self-supervised real-time depth restora- tion for consumer-grade sensors.Journal of Real-Time Im- age Processing, 21(4):124, 2024. 6
2024
-
[16]
Depth Removal Distillation for RGB-D Seman- tic Segmentation
Tiyu Fang, Zhen Liang, Xiuli Shao, Zihao Dong, and Jin- ping Li. Depth Removal Distillation for RGB-D Seman- tic Segmentation. InICASSP 2022 - 2022 IEEE Inter- national Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 2405–2409, Singapore, Singapore,
2022
-
[17]
Felzenszwalb and Daniel P
Pedro F. Felzenszwalb and Daniel P. Huttenlocher. Distance transforms of sampled functions.Theory of Computing, 8 (1):415–428, 2012. 7
2012
-
[18]
Wichmann
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Fe- lix A. Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020. 7
2020
-
[19]
Digging Into Self-Supervised Monocular Depth Estimation
Clement Godard, Oisin Mac Aodha, Michael Firman, and Gabriel Brostow. Digging Into Self-Supervised Monocular Depth Estimation. In2019 IEEE/CVF International Confer- ence on Computer Vision (ICCV), pages 3827–3837, Seoul, Korea (South), 2019. IEEE. 2, 3
2019
-
[20]
Hard Pixel Mining for Depth Privileged Semantic Segmen- tation.IEEE Transactions on Multimedia, 23:3738–3751,
Zhangxuan Gu, Li Niu, Haohua Zhao, and Liqing Zhang. Hard Pixel Mining for Depth Privileged Semantic Segmen- tation.IEEE Transactions on Multimedia, 23:3738–3751,
-
[21]
Semantic segmentation of RGBD images based on deep depth regression.Pattern Recognition Letters, 109:55–64, 2018
Yanrong Guo and Tao Chen. Semantic segmentation of RGBD images based on deep depth regression.Pattern Recognition Letters, 109:55–64, 2018. 3
2018
-
[22]
What Can We Learn from Depth Camera Sensor Noise?Sensors, 22(14):5448, 2022
Azmi Haider and Hagit Hel-Or. What Can We Learn from Depth Camera Sensor Noise?Sensors, 22(14):5448, 2022. 2, 6
2022
-
[23]
Depth Errors Analysis and Correction for Time-of-Flight (ToF) Cameras.Sensors, 17(1):92, 2017
Ying He, Bin Liang, Yu Zou, Jin He, and Jun Yang. Depth Errors Analysis and Correction for Time-of-Flight (ToF) Cameras.Sensors, 17(1):92, 2017. 2, 6
2017
-
[24]
Improving Semi-Supervised and Domain- Adaptive Semantic Segmentation with Self-Supervised Depth Estimation.International Journal of Computer Vision, 131(8):2070–2096, 2023
Lukas Hoyer, Dengxin Dai, Qin Wang, Yuhua Chen, and Luc Van Gool. Improving Semi-Supervised and Domain- Adaptive Semantic Segmentation with Self-Supervised Depth Estimation.International Journal of Computer Vision, 131(8):2070–2096, 2023. 3 9
2070
-
[25]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3D v2: A Versatile Monocular Geomet- ric Foundation Model for Zero-Shot Metric Depth and Sur- face Normal Estimation.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 46(12):10579–10596, 2024. 2, 3, 5
2024
-
[26]
Chang-Hasnain
Xuanlun Huang, Chenyang Wu, Xiaolan Xu, Baishun Wang, Sui Zhang, Chihchiang Shen, Chiennan Yu, Jiaxing Wang, Nan Chi, Shaohua Yu, and Connie J. Chang-Hasnain. Po- larization structured light 3D depth image sensor for scenes with reflective surfaces.Nature Communications, 14(1): 6855, 2023. 2
2023
-
[27]
GeminiFusion: Efficient Pixel-wise Multimodal Fusion for Vision Transformer, 2024
Ding Jia, Jianyuan Guo, Kai Han, Han Wu, Chao Zhang, Chang Xu, and Xinghao Chen. GeminiFusion: Efficient Pixel-wise Multimodal Fusion for Vision Transformer, 2024. 2, 5
2024
-
[28]
Jianbo Jiao, Yunchao Wei, Zequn Jie, Honghui Shi, Ryn- son Lau, and Thomas S. Huang. Geometry-Aware Distilla- tion for Indoor Semantic Segmentation. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2864–2873, Long Beach, CA, USA, 2019. IEEE. 2, 3
2019
-
[29]
Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review.Sensors, 20(8):2272, 2020
Faisal Khan, Saqib Salahuddin, and Hossein Javidnia. Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review.Sensors, 20(8):2272, 2020. 2
2020
-
[30]
SemSegDepth: A Combined Model for Semantic Segmentation and Depth Completion
Juan Lagos and Esa Rahtu. SemSegDepth: A Combined Model for Semantic Segmentation and Depth Completion. InProceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, pages 155–165, Online Streaming, — Se- lect a Country —, 2022. SCITEPRESS - Science and Tech- nology Publications. 3
2022
-
[31]
On the Viabil- ity of Monocular Depth Pre-training for Semantic Segmen- tation
Dong Lao, Fengyu Yang, Daniel Wang, Hyoungseob Park, Samuel Lu, Alex Wong, and Stefano Soatto. On the Viabil- ity of Monocular Depth Pre-training for Semantic Segmen- tation. InComputer Vision – ECCV 2024, pages 340–357. Springer Nature Switzerland, Cham, 2025. 3
2024
-
[32]
SPIGAN: Privileged Adversarial Learning from Simulation,
Kuan-Hui Lee, German Ros, Jie Li, and Adrien Gaidon. SPIGAN: Privileged Adversarial Learning from Simulation,
-
[33]
Benchmarking Multi-Modal Semantic Segmen- tation Under Sensor Failures: Missing and Noisy Modality Robustness
Chenfei Liao, Kaiyu Lei, Xu Zheng, Junha Moon, Zhixiong Wang, Yixuan Wang, Danda Pani Paudel, Luc Van Gool, and Xuming Hu. Benchmarking Multi-Modal Semantic Segmen- tation Under Sensor Failures: Missing and Noisy Modality Robustness. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1567–1577, Nashville, TN, US...
2025
-
[34]
Transparent Depth Completion Using Segmentation Fea- tures.ACM Transactions on Multimedia Computing, Com- munications, and Applications, 20(12):1–19, 2024
Boqian Liu, Haojie Li, Zhihui Wang, and Tianfan Xue. Transparent Depth Completion Using Segmentation Fea- tures.ACM Transactions on Multimedia Computing, Com- munications, and Applications, 20(12):1–19, 2024. 6
2024
-
[35]
FCEGNet: Feature calibration and edge-guided MLP de- coder Network for RGB-D semantic segmentation.Com- puter Vision and Image Understanding, 260:104448, 2025
Yiming Lu, Bin Ge, Chenxing Xia, Xu Zhu, Mengge Zhang, Mengya Gao, Ningjie Chen, Jianjun Hu, and Junjie Zhi. FCEGNet: Feature calibration and edge-guided MLP de- coder Network for RGB-D semantic segmentation.Com- puter Vision and Image Understanding, 260:104448, 2025. 2
2025
-
[36]
Miss- ing Modality Robustness in Semi-Supervised Multi-Modal Semantic Segmentation
Harsh Maheshwari, Yen-Cheng Liu, and Zsolt Kira. Miss- ing Modality Robustness in Semi-Supervised Multi-Modal Semantic Segmentation. In2024 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 1009–1019, Waikoloa, HI, USA, 2024. IEEE. 3, 6
2024
-
[37]
Marr and E
D. Marr and E. Hildreth. Theory of edge detection.Pro- ceedings of the Royal Society of London. Series B. Biological Sciences, 207(1167):187–217, 1980. 7
1980
-
[38]
Deconvolution and Checkerboard Artifacts,
Augustus Odena, Vincent Dumoulin, and Chris Olah. De- convolution and Checkerboard Artifacts.Distill, 1(10): 10.23915/distill.00003, 2016. 3
-
[39]
UniDepthV2: Universal Monocular Metric Depth Estima- tion Made Simpler.IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(3):2354–2367, 2026
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. UniDepthV2: Universal Monocular Metric Depth Estima- tion Made Simpler.IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(3):2354–2367, 2026. 3
2026
-
[40]
StructScan3D v1: A First RGB-D Dataset for Indoor Building Elements Segmentation and BIM Modeling.Sen- sors, 25(11):3461, 2025
Ishraq Rached, Rafika Hajji, Tania Landes, and Rashid Haf- fadi. StructScan3D v1: A First RGB-D Dataset for Indoor Building Elements Segmentation and BIM Modeling.Sen- sors, 25(11):3461, 2025. 6
2025
-
[41]
Hamprecht, Yoshua Bengio, and Aaron Courville
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred A. Hamprecht, Yoshua Bengio, and Aaron Courville. On the Spectral Bias of Neural Networks
-
[42]
Vi- sion Transformers for Dense Prediction
Rene Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion Transformers for Dense Prediction. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 12159–12168, Montreal, QC, Canada, 2021. IEEE. 3
2021
-
[43]
Sonia Raychaudhuri and Angel X. Chang. Semantic Map- ping in Indoor Embodied AI – A Survey on Advances, Chal- lenges, and Future Directions, 2025. 2
2025
-
[44]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A Photorealistic Syn- thetic Dataset for Holistic Indoor Scene Understanding. In 2021 IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 10892–10902, Montreal, QC, Canada,
2021
-
[45]
Optimal Filters for Extended Optical Flow
Hanno Scharr. Optimal Filters for Extended Optical Flow. In Complex Motion, pages 14–29. Springer Berlin Heidelberg, Berlin, Heidelberg, 2007. 7
2007
-
[46]
Efficient attention vision trans- formers for monocular depth estimation on resource-limited hardware.Scientific Reports, 15(1):24001, 2025
Claudio Schiavella, Lorenzo Cirillo, Lorenzo Papa, Paolo Russo, and Irene Amerini. Efficient attention vision trans- formers for monocular depth estimation on resource-limited hardware.Scientific Reports, 15(1):24001, 2025. 6
2025
-
[47]
Efficient Multi-Task RGB-D Scene Analysis for Indoor Environments
Daniel Seichter, Sohnke Benedikt Fischedick, Mona Kohler, and Horst-Michael Grob. Efficient Multi-Task RGB-D Scene Analysis for Indoor Environments. In2022 International Joint Conference on Neural Networks (IJCNN), pages 1–10, Padua, Italy, 2022. IEEE. 2
2022
-
[48]
Unsupervised Semantic Segmentation Through Depth-Guided Feature Correlation and Sampling
Leon Sick, Dominik Engel, Pedro Hermosilla, and Timo Ropinski. Unsupervised Semantic Segmentation Through Depth-Guided Feature Correlation and Sampling. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3637–3646, Seattle, W A, USA,
-
[49]
Lichtenberg, and Jianxiong Xiao
Shuran Song, Samuel P. Lichtenberg, and Jianxiong Xiao. SUN RGB-D: A RGB-D scene understanding benchmark 10 suite. In2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 567–576, Boston, MA, USA, 2015. IEEE. 5
2015
-
[50]
Inpaint- ing of Missing Values in the Kinect Sensor’s Depth Maps Based on Background Estimates.IEEE Sensors Journal, 14 (4):1107–1116, 2014
Martin Stommel, Michael Beetz, and Weiliang Xu. Inpaint- ing of Missing Values in the Kinect Sensor’s Depth Maps Based on Background Estimates.IEEE Sensors Journal, 14 (4):1107–1116, 2014. 2
2014
-
[51]
A Survey of Object Goal Navigation.IEEE Transactions on Automation Science and Engineering, 22:2292–2308, 2025
Jingwen Sun, Jing Wu, Ze Ji, and Yu-Kun Lai. A Survey of Object Goal Navigation.IEEE Transactions on Automation Science and Engineering, 22:2292–2308, 2025. 2
2025
-
[52]
Semantic Segmentation Leveraging Simultaneous Depth Estimation.Sensors, 21(3):690, 2021
Wenbo Sun, Zhi Gao, Jinqiang Cui, Bharath Ramesh, Bin Zhang, and Ziyao Li. Semantic Segmentation Leveraging Simultaneous Depth Estimation.Sensors, 21(3):690, 2021. 3
2021
-
[53]
DADA: Depth-Aware Domain Adaptation in Semantic Segmentation
Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Perez. DADA: Depth-Aware Domain Adaptation in Semantic Segmentation. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 7363–7372, Seoul, Korea (South), 2019. IEEE. 3
2019
-
[54]
Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
Zifu Wan, Pingping Zhang, Yuhao Wang, Silong Yong, Si- mon Stepputtis, Katia Sycara, and Yaqi Xie. Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1734–1744, Tucson, AZ, USA, 2025. IEEE. 2
2025
-
[55]
A brief survey on RGB-D semantic segmentation us- ing deep learning.Displays, 70:102080, 2021
Changshuo Wang, Chen Wang, Weijun Li, and Haining Wang. A brief survey on RGB-D semantic segmentation us- ing deep learning.Displays, 70:102080, 2021. 2
2021
-
[56]
Deep Multimodal Fusion by Channel Exchanging, 2020
Yikai Wang, Wenbing Huang, Fuchun Sun, Tingyang Xu, Yu Rong, and Junzhou Huang. Deep Multimodal Fusion by Channel Exchanging, 2020. 2
2020
-
[57]
Multimodal Token Fusion for Vision Transformers, 2022
Yikai Wang, Xinghao Chen, Lele Cao, Wenbing Huang, Fuchun Sun, and Yunhe Wang. Multimodal Token Fusion for Vision Transformers, 2022. 2
2022
-
[58]
One-stage Modality Distillation for Incomplete Multimodal Learning, 2023
Shicai Wei, Yang Luo, and Chunbo Luo. One-stage Modality Distillation for Incomplete Multimodal Learning, 2023. 6
2023
-
[59]
Suhan Woo, Junhyuk Hyun, Suhyeon Lee, and Euntai Kim. Real-time RGB-D Semantic Segmentation With Scale- invariant Depth Encoding and Noise-robust Fusion.Interna- tional Journal of Control, Automation and Systems, 23(12): 3649–3661, 2025. 2, 3
2025
-
[60]
Transformer fu- sion for indoor RGB-D semantic segmentation.Computer Vision and Image Understanding, 249:104174, 2024
Zongwei Wu, Zhuyun Zhou, Guillaume Allibert, Christophe Stolz, C´edric Demonceaux, and Chao Ma. Transformer fu- sion for indoor RGB-D semantic segmentation.Computer Vision and Image Understanding, 249:104174, 2024. 2
2024
-
[61]
Alvarez, and Ping Luo
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. SegFormer: Simple and Effi- cient Design for Semantic Segmentation with Transformers,
-
[62]
Interactive Efficient Multi-Task Network for RGB-D Semantic Segmentation
Xinhua Xu, Jinfu Liu, and Hong Liu. Interactive Efficient Multi-Task Network for RGB-D Semantic Segmentation. Electronics, 12(18):3943, 2023. 2
2023
-
[63]
Xinhua Xu, Hong Liu, Jianbing Wu, and Jinfu Liu. PDDM: Pseudo Depth Diffusion Model for RGB-PD Semantic Seg- mentation Based in Complex Indoor Scenes.Proceedings of the AAAI Conference on Artificial Intelligence, 39(9):8969– 8977, 2025. 3
2025
-
[64]
Depth Any- thing V2, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth Any- thing V2, 2024. 2, 3, 5
2024
-
[65]
DFormer: Rethinking RGBD Rep- resentation Learning for Semantic Segmentation, 2023
Bowen Yin, Xuying Zhang, Zhongyu Li, Li Liu, Ming-Ming Cheng, and Qibin Hou. DFormer: Rethinking RGBD Rep- resentation Learning for Semantic Segmentation, 2023. 2, 5
2023
-
[66]
DFormerv2: Geometry Self-Attention for RGBD Se- mantic Segmentation
Bo-Wen Yin, Jiao-Long Cao, Ming-Ming Cheng, and Qibin Hou. DFormerv2: Geometry Self-Attention for RGBD Se- mantic Segmentation. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19345–19355, Nashville, TN, USA, 2025. IEEE. 2
2025
-
[67]
CMX: Cross-Modal Fu- sion for RGB-X Semantic Segmentation With Transformers
Jiaming Zhang, Huayao Liu, Kailun Yang, Xinxin Hu, Ruip- ing Liu, and Rainer Stiefelhagen. CMX: Cross-Modal Fu- sion for RGB-X Semantic Segmentation With Transformers. IEEE Transactions on Intelligent Transportation Systems, 24 (12):14679–14694, 2023. 2
2023
-
[68]
Delivering Arbitrary-Modal Semantic Segmentation
Jiaming Zhang, Ruiping Liu, Hao Shi, Kailun Yang, Si- mon Reiß, Kunyu Peng, Haodong Fu, Kaiwei Wang, and Rainer Stiefelhagen. Delivering Arbitrary-Modal Semantic Segmentation. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1136–1147, Vancouver, BC, Canada, 2023. IEEE. 3
2023
-
[69]
Survey on monocular metric depth estimation.Computers, 14(11),
Jiuling Zhang, Yurong Wu, and Huilong Jiang. Survey on monocular metric depth estimation.Computers, 14(11),
-
[70]
https: //arxiv.org/abs/1904.11486
Richard Zhang. Making convolutional networks shift- invariant again.CoRR, abs/1904.11486, 2019. 4
-
[71]
Centering the Value of Every Modality: Towards Efficient and Resilient Modality-Agnostic Semantic Segmentation
Xu Zheng, Yuanhuiyi Lyu, Jiazhou Zhou, and Lin Wang. Centering the Value of Every Modality: Towards Efficient and Resilient Modality-Agnostic Semantic Segmentation. In Computer Vision – ECCV 2024, pages 192–212. Springer Nature Switzerland, Cham, 2025. 3
2024
-
[72]
Attention- based fusion network for RGB-D semantic segmentation
Li Zhong, Chi Guo, Jiao Zhan, and JingYi Deng. Attention- based fusion network for RGB-D semantic segmentation. Neurocomputing, 608:128371, 2024. 2, 3
2024
-
[73]
RGB-D Local Implicit Function for Depth Completion of Transparent Objects, 2021
Luyang Zhu, Arsalan Mousavian, Yu Xiang, Hammad Mazhar, Jozef van Eenbergen, Shoubhik Debnath, and Dieter Fox. RGB-D Local Implicit Function for Depth Completion of Transparent Objects, 2021. arXiv:2104.00622. 6 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.