Recognition: unknown
Scalable Exact Hierarchical Agglomerative Clustering via Sparse Geographic Distance Graphs
Pith reviewed 2026-05-10 14:58 UTC · model grok-4.3
The pith
Sparse geographic distance graphs enable exact hierarchical agglomerative clustering on millions of points by replacing the full pairwise matrix with a bounded-neighbor graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GSHAC builds a sparse geographic distance graph containing only pairs inside a user-specified geodesic bound h_max, constructed via spatial indexing in O(n k) time. The connected components of this graph form independent subproblems whose exact HAC solutions can be computed and later recombined. The paper proves that these solutions coincide with the full-matrix dendrogram for all standard linkage methods at every height h ≤ h_max. For single linkage an MST on the sparse edges further reduces memory to O(n_k + m_k) per component. On a 261 000-point global mining inventory the method finishes in 12 seconds using 109 MiB, versus roughly 545 GiB for the dense baseline; on a two-million-pointGeo
What carries the argument
The sparse geographic distance graph whose connected components isolate exact subproblems while preserving all merges up to height h_max.
If this is right
- Exact cluster assignments are guaranteed for single, complete, average, and Ward linkage at every cut height below h_max.
- Peak memory for the clustering phase scales with the number of retained nearby pairs rather than n squared.
- Large geographic datasets decompose into independent subproblems that can be solved sequentially or in parallel.
- Single-linkage instances further reduce memory by replacing the sparse graph with its minimum spanning tree.
- The same workflow applies directly to any point set equipped with a distance oracle and a spatial index.
Where Pith is reading between the lines
- Choosing h_max too conservatively still yields correct results up to that height, but may leave the data as one large component.
- The method could be combined with streaming or out-of-core techniques to handle even larger point sets that exceed main memory.
- Because the proof relies only on the absence of edges longer than h_max, the same decomposition works for any distance that admits an efficient range query.
- Integration into existing GIS libraries would let analysts run exact hierarchical clustering as a standard preprocessing step on location data.
Load-bearing premise
The chosen h_max must be large enough to contain every merge distance that matters for the final clustering, and the spatial index must return every pair inside that bound.
What would settle it
Running both GSHAC and a full-matrix HAC on the same small dataset with h_max deliberately set below at least one true merge distance, then comparing the cluster assignments produced at height h_max, would show disagreement if the exactness claim fails.
Figures



read the original abstract
Exact hierarchical agglomerative clustering (HAC) of large spatial datasets is limited in practice by the $\mathcal{O}(n^2)$ time and memory required for the full pairwise distance matrix. We present GSHAC (Geographically Sparse Hierarchical Agglomerative Clustering), a system that makes exact HAC feasible at scales of millions of geographic features on a commodity workstation. GSHAC replaces the distance matrix with a sparse geographic distance graph containing only pairs within a user-specified geodesic bound~$h_{\max}$, constructed in $\mathcal{O}(n \cdot k)$ time via spatial indexing, where~$k$ is the mean number of neighbors within~$h_{\max}$. Connected components of this graph define independent subproblems, and we prove that the resulting assignments are exact for all standard linkage methods at any cut height $h \le h_{\max}$. For single linkage, an MST-based path keeps memory at $\mathcal{O}(n_k + m_k)$ per component. Applied to a global mining inventory ($n = 261{,}073$), the system completes in 12\,s (109\,MiB peak HAC memory) versus $\approx 545$\,GiB for the dense baseline. On a 2-million-point GeoNames sample, all tested thresholds completed in under 3\,minutes with peak memory under 3\,GiB. We provide a scikit-learn-compatible implementation for direct integration into GIS workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GSHAC, a system for exact hierarchical agglomerative clustering (HAC) on large spatial datasets. It replaces the dense O(n²) distance matrix with a sparse geographic distance graph containing only pairs at geodesic distance ≤ h_max (constructed via spatial indexing in O(n·k) time), decomposes into connected components, and runs standard HAC within components. The central claim is a proof that the resulting dendrogram and assignments are identical to full-matrix HAC for all standard linkages (single, complete, average, Ward) at any cut height h ≤ h_max. Empirical results report practical runtimes and memory (12 s / 109 MiB for n=261k mining points; <3 min / <3 GiB for 2M GeoNames points) together with a scikit-learn-compatible implementation.
Significance. If the exactness guarantee holds for all listed linkages, the work would remove a major practical barrier to exact HAC on million-scale geographic data, replacing heuristic approximations with a method whose memory scales with the number of neighbors inside h_max rather than n². The concrete performance numbers, open implementation, and explicit handling of connected-component decomposition are strengths that would make the result immediately usable in GIS pipelines.
major comments (1)
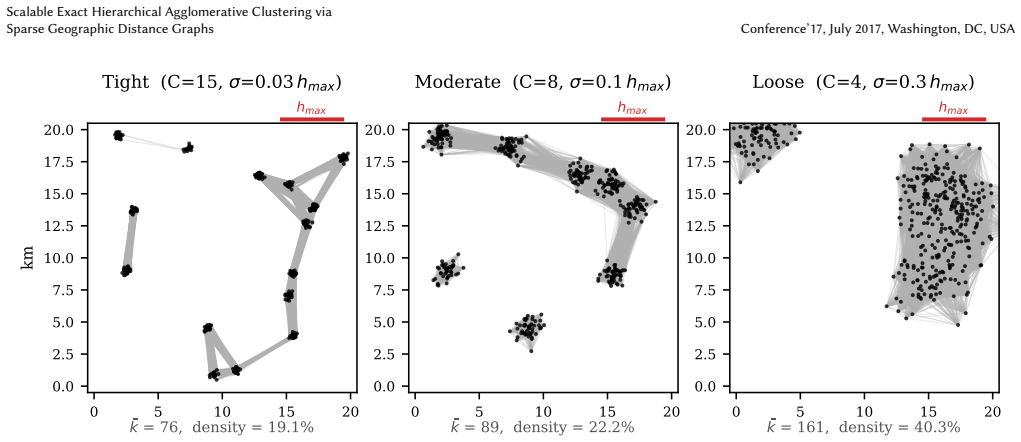
- [Proof of exactness (abstract and the section containing the linkage-case analysis)] The proof that the sparse graph yields exact results for average linkage (and Ward) at heights ≤ h_max is load-bearing for the central claim yet appears incomplete. In the 4-point counter-example with positions {0,4,6,10} and h_max=5, the true average-linkage merge of {0} with {4,6} occurs at height exactly 5 (mean of the four cross distances), but the sparse graph omits edges 0-6, 0-10 and 4-10. Any implementation that averages only present edges or treats missing distances as infinity produces a different partition at the h=5 cut. The manuscript must either (a) supply an auxiliary mechanism that recovers the missing distances when they affect an average ≤ h_max, (b) restrict the exactness claim to single and complete linkage, or (c) prove that no such configuration can arise under the geographic embedding. Cite the precise location of the average-linkage case in the proof.
minor comments (2)
- [Abstract] The notation “n_k + m_k” for per-component memory in the single-linkage MST case should be defined explicitly (presumably n_k = points in component k, m_k = edges).
- [Introduction or methods] The manuscript should state the precise definition of “standard linkage methods” (single, complete, average, Ward) and whether centroid or median linkage are also covered.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the concrete counter-example, which has helped us identify a gap in the scope of our exactness claim. We will revise the manuscript to address this directly.
read point-by-point responses
-
Referee: [Proof of exactness (abstract and the section containing the linkage-case analysis)] The proof that the sparse graph yields exact results for average linkage (and Ward) at heights ≤ h_max is load-bearing for the central claim yet appears incomplete. In the 4-point counter-example with positions {0,4,6,10} and h_max=5, the true average-linkage merge of {0} with {4,6} occurs at height exactly 5 (mean of the four cross distances), but the sparse graph omits edges 0-6, 0-10 and 4-10. Any implementation that averages only present edges or treats missing distances as infinity produces a different partition at the h=5 cut. The manuscript must either (a) supply an auxiliary mechanism that recovers the missing distances when they affect an average ≤ h_max, (b) restrict the exactness claim to single and complete linkage, or (c) prove that no such configuration can arise under the geographic emb
Authors: We agree that the counter-example is valid and shows the exactness claim cannot hold for average linkage (and Ward) as currently stated. When the average cross-distance equals h_max but some individual distances exceed h_max, the sparse graph omits edges, and averaging only present edges underestimates the true value (4 instead of 5 in the example), changing the dendrogram. We have no auxiliary recovery mechanism that preserves scalability, nor can we prove such cases are impossible under geographic embeddings, as the example is itself a valid 1-D geographic instance. We will therefore restrict the exactness guarantee to single and complete linkage, for which the arguments are correct: single linkage needs only the min cross-edge (present if merge height ≤ h_max), while complete linkage needs max cross-edge ≤ h_max (implying all cross-edges present). For average and Ward we will state that the method yields an approximation and recommend dense HAC inside components when exactness is required. The linkage analysis is in Section 4.2; we will expand it, update the abstract, and revise all claims. This will be incorporated in the revised manuscript. revision: yes
Circularity Check
No circularity; derivation is self-contained via explicit construction and stated proof
full rationale
The paper defines a sparse graph G using only pairs with d ≤ h_max (an explicit user parameter), then claims a proof that HAC on G yields identical merges to full-matrix HAC for all standard linkages at heights ≤ h_max. No equations reduce a result to itself by definition, no parameters are fitted then relabeled as predictions, and no load-bearing steps rely on self-citations or prior ansatzes from the same authors. The proof is presented as independent reasoning about connectivity, MST properties for single linkage, and cross-pair bounds for complete linkage; even if the proof is later shown incomplete for average/Ward linkage, that is a correctness issue rather than circularity. The construction remains non-tautological and externally verifiable against the full distance matrix.
Axiom & Free-Parameter Ledger
free parameters (1)
- h_max
axioms (1)
- standard math Geodesic distance on the sphere satisfies the triangle inequality
Reference graph
Works this paper leans on
-
[1]
Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, and Jörg Sander. 1999. OPTICS: ordering points to identify the clustering structure. InSIGMOD ’99: Proceedings of the 1999 ACM SIGMOD international conference on Management of data. doi:10.1145/304182.304187
-
[2]
J.L. Bentley. 1975. Multidimensional binary search trees used for associative searching.Commun. ACM18, 9 (1975), 509–517
1975
-
[3]
Marie Chavent, Vanessa Kuentz-Simonet, Amaury Labenne, and Jérôme Saracco
-
[4]
Comput Stat33 (2018), 1799–1822
ClustGeo: an R package for hierarchical clustering with spatial constraints. Comput Stat33 (2018), 1799–1822. doi:10.1007/s00180-018-0791-1
-
[5]
Marek Gagolewski, Maciej Bartoszuk, and Anna Cena. 2016. Genie: A new, fast, and outlier-resistant hierarchical clustering algorithm.Information Sciences363 (2016), 8–23. doi:10.1016/j.ins.2016.05.003
-
[6]
GeoNames. 2025. GeoNames Geographical Database. https://www.geonames. org/export/ CC BY 4.0.allCountriesdump, accessed 2025
2025
-
[7]
J. C. Gower and G. J. S. Ross. 1969. Minimum Spanning Trees and Single Linkage Cluster Analysis.Journal of the Royal Statistical Society. Series C (Applied Statistics) 18, 1 (1969), 54–64. doi:10.2307/2346439
-
[8]
Rastogi, and K
Sudipto Guha, R. Rastogi, and K. Shim. 1998. CURE: An Efficient Clustering Algorithm for Large Databases. InSIGMOD ’98
1998
-
[9]
Mostofa Ali Patwary, Ankit Agrawal, Wei- keng Liao, and Alok Choudhary
William Hendrix, Diana Palsetia, Md. Mostofa Ali Patwary, Ankit Agrawal, Wei- keng Liao, and Alok Choudhary. 2013. A Scalable Algorithm for Single-Linkage Hierarchical Clustering on Distributed-Memory Architectures. InIEEE Sympo- sium on Large Data Analysis and Visualization
2013
-
[10]
Mostofa Ali Patwary, Ankit Agrawal, William Hendrix, Wei-keng Liao, and Alok Choudhary
Chen Jin, Md. Mostofa Ali Patwary, Ankit Agrawal, William Hendrix, Wei-keng Liao, and Alok Choudhary. 2015. Incremental, Distributed Single-Linkage Hi- erarchical Clustering Algorithm Using MapReduce. In23rd High Performance Computing Symposium (HPC 2015)
2015
-
[11]
Yaniv Loewenstein, Elon Portugaly, Menachem Fromer, and Michal Linial. 2008. Efficient algorithms for accurate hierarchical clustering of huge datasets: tackling the entire protein space.Bioinformatics24, 13 (2008), i41–i49. doi:10.1093/ bioinformatics/btn174
2008
-
[12]
Victor Maus. 2026. A data-driven approach to mapping global commodity-specific mining land-use.Journal of Cleaner Production540 (2026), 147437. doi:10.1016/j. jclepro.2025.147437
work page doi:10.1016/j 2026
-
[13]
L. McInnes, J. Healy, and S. Astels. 2017. hdbscan: Hierarchical density based clustering.Journal of Open Source Software2, 11 (2017), 205. doi:10.21105/joss. 00205
-
[14]
Nicholas Monath, Kumar Avinava Dubey, Guru Guruganesh, Manzil Zaheer, Amr Ahmed, Andrew McCallum, Gokhan Mergen, Marc Najork, Mert Terzihan, Bryon Tjanaka, Yuan Wang, and Yuchen Wu. 2021. Scalable Hierarchical Agglomerative Clustering. InKDD ’21: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. doi:10.1145/3447548.3467404
-
[15]
Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks,
Nicholas Monath, Ari Kobren, Akshay Krishnamurthy, Michael R. Glass, and Andrew McCallum. 2019. Scalable Hierarchical Clustering with Tree Grafting. In KDD ’19: The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. doi:10.1145/3292500.3330929
-
[16]
Benjamin Moseley, Sergei Vassilvitskii, and Yuyan Wang. [n. d.]. Hierarchical Clustering in General Metric Spaces using Approximate Nearest Neighbors. ([n. d.])
-
[17]
Daniel Müllner. 2013. fastcluster: Fast Hierarchical, Agglomerative Clustering in R and Python.Journal of Statistical Software53, 9 (2013). doi:10.18637/jss.v053.i09
-
[18]
Thuy-Diem Nguyen, Bertil Schmidt, and Chee-Keong Kwoh. 2014. SparseHC: a memory-efficient online hierarchical clustering algorithm.Procedia Computer Science29 (2014), 8–19. doi:10.1016/j.procs.2014.05.001
-
[19]
1989.Five Balltree Construction Algorithms
Stephen M Omohundro. 1989.Five Balltree Construction Algorithms. Technical Report TR-89-063. International Computer Science Institute
1989
-
[20]
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. 2011. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Re...
2011
-
[21]
Rey and Luc Anselin
Sergio J. Rey and Luc Anselin. 2007. PySAL: A Python Library of Spatial Analytical Methods.The Review of Regional Studies37, 1 (2007), 5–27
2007
-
[23]
Behnam Sadeghi. 2025. K-Means and K-Medoids are among the most commonly used clustering methods in geo-data science (pyClusterWise).Ore Geology Re- views181 (2025), 106591. doi:10.1016/j.oregeorev.2025.106591
-
[24]
scikit-learn developers. 2022. Issue #23550: AgglomerativeClustering with distance_threshold and sparse connectivity gives incorrect results for com- plete and average linkage. https://github.com/scikit-learn/scikit-learn/issues/ 23550 GitHub issue, scikit-learn repository
2022
-
[25]
R. Sibson. 1973. SLINK: An optimally efficient algorithm for the single-link cluster method.Comput. J.16, 1 (1973), 30–34. doi:10.1093/comjnl/16.1.30
-
[26]
Waldo R Tobler. 1970. A computer movie simulating urban growth in the Detroit region.Economic geography46, sup1 (1970), 234–240
1970
-
[27]
Pauli Virtanen et al . 2020. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python.Nature Methods17 (2020), 261–272. doi:10.1038/s41592- 019-0686-2
-
[28]
Yiqiu Wang, Shangdi Yu, Yan Gu, and Julian Shun. 2021. Fast Parallel Algorithms for Euclidean Minimum Spanning Tree and Hierarchical Spatial Clustering. In SIGMOD ’21: Proceedings of the 2021 International Conference on Management of Data. doi:10.1145/3448016.3457296
-
[29]
Tian Zhang, Raghu Ramakrishnan, and Miron Livny. 1996. BIRCH: An Efficient Data Clustering Method for Very Large Databases. InSIGMOD. Scalable Exact Hierarchical Agglomerative Clustering via Sparse Geographic Distance Graphs Conference’17, July 2017, Washington, DC, USA 103 104 105 106 107 n 10 1 101 103 105 107 Wall time (s) n=261K n=2M O(n2 ) n1.1 Dense...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.